




作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
构建神经网络的流程
- 数据的导入
- 数据预处理
- 模型框架构建
- 循环训练
- 可视化损失曲线
- 模型评估
未封装版本
不进行代码拆分,将所有步骤合成在一块:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.optim as optim # 优化器
from tqdm import tqdm # 进度条
import time
# 1-数据导入
data = pd.read_csv('data.csv')
data.info()
# 2-数据预处理
# 2.1-离散特征编码
mapping_dict = {
'Home Ownership':{
'Own Home':0,
'Rent':1,
'Home Mortgage':2,
'Have Mortgage':3
},
'Years in current job ':{
'< 1 year': 0,
'1 year': 1,
'2 years': 2,
'3 years': 3,
'4 years': 4,
'5 years': 5,
'6 years': 6,
'7 years': 7,
'8 years': 8,
'9 years': 9,
'10+ years': 10
},
'Term':{
'Short Term':0,
'Long Term':1
}
} # 映射字典
data['Home Ownership'] = data['Home Ownership'].map(mapping_dict['Home Ownership'])
data['Years in current job'] = data['Years in current job'].map(mapping_dict['Years in current job'])
data['Term'] = data['Term'].map(mapping_dict['Term']) # 0-1映射
data.rename(columns={'Term':'Long Term'},inplace=True) # 重命名列
df = pd.get_dummies(data,columns=['Purpose']) # 独热编码
new_features = [] # 编码后的新特征
for i in df.columns:
if i not in data.columns:
new_features.append(i)
for j in new_features:
df[j] = df[j].astype(int) # 将bool型转换为int型
# 2.2-缺失值填充
for col in df.coulumns.tolist():
mode_value = df[col].mode()[0]
df[col] = df[col].fillna(mode_value)
# 设置设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('使用的设备:{}'.format(device))
# 2.3-归一化
X = df.drop(columns=['Credit Default'],axis=1)
y = df['Credit Default']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 2.4-张量转换
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.to_numpy()).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.to_numpy()).to(device)
# 3-模型框架
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.fc1 = nn.Linear(31,15)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.3) # 添加dropout防止过拟合
self.fc2 = nn.Linear(15,2)
def forward(self,x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = MLP().to(device)
# 4-模型训练
criterion = nn.CrossEntropyLoss()
optimiser = optim.Adam(model.parameters(),lr=0.001)
epoch_num = 20500
losses = [] #存储损失值
epochs = [] #存储Loss对应的epoch
#加入训练时间
start_time = time.time()
# 加入进度条
with tqdm(total=epoch_num,desc='计算进度',unit='epoch') as pbar:
for epoch in range(epoch_num):
# 基本流程
output = model(X_train) # 完成前向传播
loss = criterion(output,y_train) # 计算损失值
optimiser.zero_grad() # 反向传播优化前,先清零梯度
loss.backward() #反向传播
optimiser.step() #更新
#记录 epoch 和 loss
if (epoch + 1) % 200 == 0:
loss_value = loss.item() #转换为标量,便于后续可视化
losses.append(loss_value)
epochs.append(epoch + 1)
pbar.set_postfix({'Loss': f'{loss_value:.4f}'}) # 不用额外打印,跟随进度条显示Loss值
# 更新进度条
if (epoch + 1) % 1000 == 0: # 每1000次epoch,更新一次进度条
pbar.update(1000) # 手动更新
# 手动补全进度条达到100%,增强代码的鲁棒性
if pbar.n < epoch_num:
pbar.update(epoch_num - pbar.n) # 比如epoch_num = 20010
end_time = time.time()
print('Training TIme:{:.2f}s'.format(end_time-start_time))
# 5-可视化损失曲线
plt.plot(epochs,losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()
# 6-模型评估
model.eval() # 进入评估模式
with torch.no_grad():
out = model(X_test) # 输入测试集,得到预测结果
_,predictions = torch.max(out,dim=1) # 获取概率最大值的索引,即预测的标签
# 计算准确率
correct_num = (predictions == y_test).sum().item() #转换int
accuracy = correct_num / y_test.size(0)
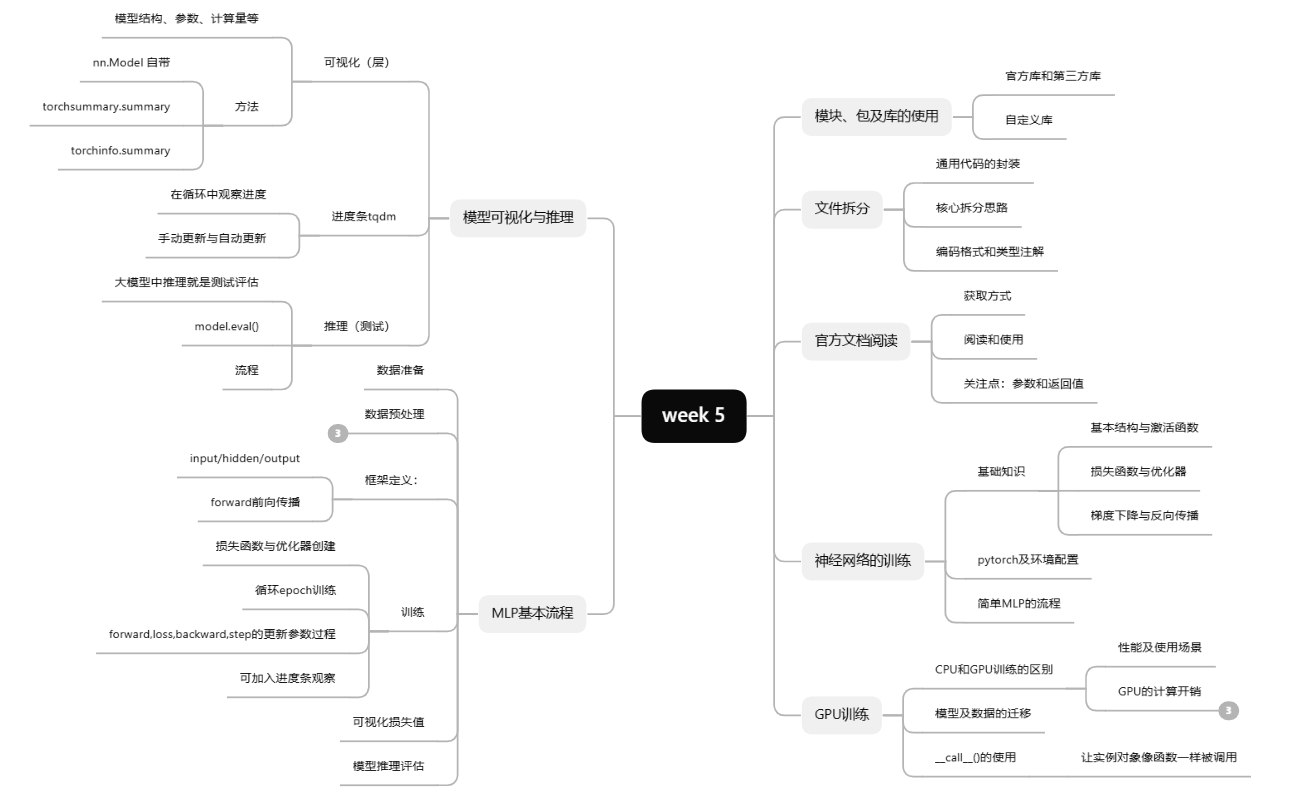
print('Accuracy:{:.2f}%'.format(accuracy*100)) 隐藏层大小为62,epoch数值为20500,优化器为Adam,用时13.34 s,准确率:73.87%
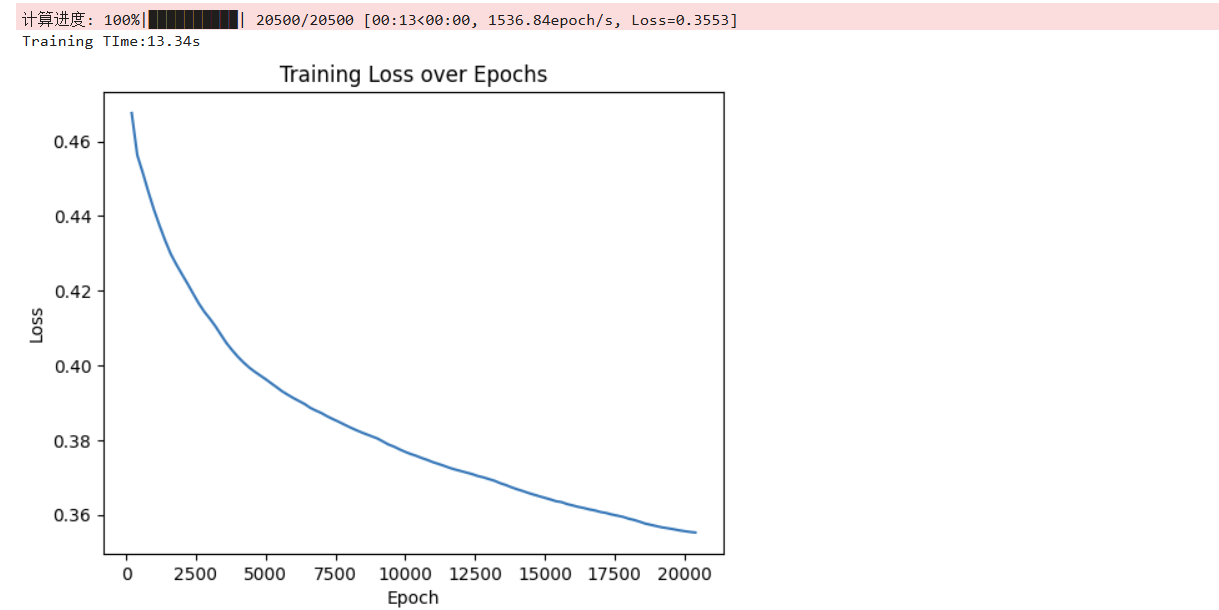
隐藏层大小为62,epoch数值为20500,优化器为SGD,用时10.32 s,准确率:76.93%
封装版本
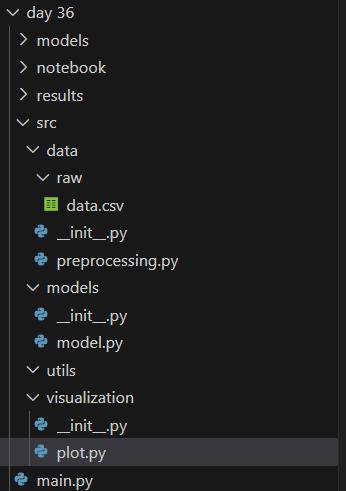
仿照day 31 拆分文件:
(1)主代码main.py
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim # 优化器
from tqdm import tqdm # 进度条
import time
from src.data.preprocessing import load_data,encode,scaler,tensor_convert,fill_null
from src.models.model import MLP,train,evaluate
from src.visualization.plot import loss_plot
# 数据处理
def data_process(mapping_dict,device):
# 数据导入
data = load_data('data.csv')
print("原始数据是否读取成功:", data is not None) # 检查是否为None
data_labeled = encode(origin_data=data,method='label',mapping_dict=mapping_dict)
data.rename(columns={'Term':'Long Term'},inplace=True) # 重命名列
data_encoded = encode(origin_data=data_labeled,method='one_hot',col_names=['Purpose'])
data_filled = fill_null(data_encoded)
X = data_filled.drop(columns=['Credit Default'],axis=1)
y = data_filled['Credit Default']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
X_train,X_test = scaler(X_train,X_test) # 归一化
X_train,y_train,X_test,y_test = tensor_convert(X_train,X_test,y_train,y_test,device) # 张量转换
return X_train,X_test,y_train,y_test
# 加入进度条
def tqdm_train(epoch_num,model,X_train,y_train,criterion,optimiser):
losses = [] #存储损失值
epochs = [] #存储Loss对应的epoch
with tqdm(total=epoch_num,desc='计算进度',unit='epoch') as pbar:
for epoch in range(epoch_num):
loss = train(model,X_train,y_train,criterion,optimiser)
#记录 epoch 和 loss
if (epoch + 1) % 200 == 0:
losses.append(loss.item())
epochs.append(epoch + 1)
pbar.set_postfix({'Loss': f'{loss.item():.4f}'}) # 不用额外打印,跟随进度条显示Loss值
# 更新进度条
if (epoch + 1) % 1000 == 0: # 每1000次epoch,更新一次进度条
pbar.update(1000) # 手动更新
# 手动补全进度条达到100%,增强代码的鲁棒性
if pbar.n < epoch_num:
pbar.update(epoch_num - pbar.n) # 比如epoch_num = 20010
return losses,epochs
mapping_dict = {
'Home Ownership':{
'Own Home':0,
'Rent':1,
'Home Mortgage':2,
'Have Mortgage':3
},
'Years in current job':{
'< 1 year': 0,
'1 year': 1,
'2 years': 2,
'3 years': 3,
'4 years': 4,
'5 years': 5,
'6 years': 6,
'7 years': 7,
'8 years': 8,
'9 years': 9,
'10+ years': 10
},
'Term':{
'Short Term':0,
'Long Term':1
}
} # 映射字典
# 设置设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('使用的设备:{}'.format(device))
model = MLP(input_size=31,hidden_size=62,output_size=2).to(device)
criterion = nn.CrossEntropyLoss()
optimiser = optim.Adam(model.parameters(),lr=0.001)
if __name__ == '__main__':
X_train,X_test,y_train,y_test = data_process(mapping_dict,device)
epoch_num = 20500
#加入训练时间
start_time = time.time()
losses,epochs = tqdm_train(epoch_num,model,X_train,y_train,criterion,optimiser)
end_time = time.time()
print('Training TIme:{:.2f}s'.format(end_time-start_time))
#可视化
loss_plot(x=epochs,y=losses,x_label='epoch',y_label='loss',title='Training Loss over Epochs')
# 评估
accuracy = evaluate(model,X_test,y_test)
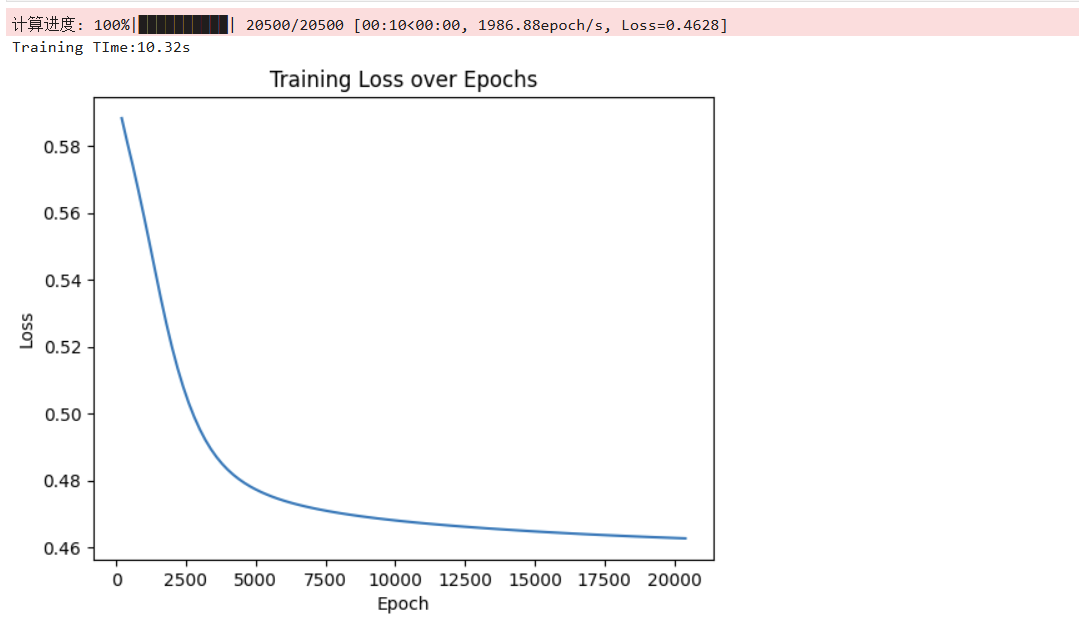
print('Accuracy:{:.2f}%'.format(accuracy*100)) 结果:
- SGD:loss = 0.4626, time = 8.84 s, accuracy = 76.87 %
- Adam:loss = 0.3521, time = 13.72 s, accuracy = 73.47 %


(2)另外三个文件,分别是数据预处理、模型框架与训练评估、绘图可视化。只是简单地封装(内部无类型标注),但是通用性还不够,以及并没有考虑多种情况(输入错误的参数,填充缺失值仅局限于众数等等)
# preprocessing.py
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch
# 加载数据
def load_data(file_path):
data = pd.read_csv(file_path)
return data
# 编码
def encode(origin_data,method='label',mapping_dict=None,col_names=None):
if method == 'one_hot':
new_data = pd.get_dummies(origin_data,columns=col_names)
new_features = [i for i in new_data.columns if i not in origin_data.columns] # 编码后的新特征
for j in new_features:
new_data[j] = new_data[j].astype(int) # 将bool型转换为int型
return new_data
elif method == 'label':
data = origin_data.copy()
for key,value in mapping_dict.items():
data[key] = data[key].map(value)
return data
else:
return origin_data
# 缺失值填充
def fill_null(data):
for col in data.columns.tolist():
mode_value = data[col].mode()[0]
data[col] = data[col].fillna(mode_value)
return data
# 归一化
def scaler(X_train,X_test):
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
return X_train_scaled,X_test_scaled
# 张量转换
def tensor_convert(X_train,X_test,y_train,y_test,device,feature_dtype=torch.float32, label_dtype=torch.int64):
X_train_tensored = torch.tensor(X_train,dtype=feature_dtype).to(device) # X_train 为数组
y_train_tensored = torch.tensor(y_train.to_numpy(),dtype=label_dtype).to(device) # series不能直接转换为tensor,先转换为Numpy数组
X_test_tensored = torch.tensor(X_test,dtype=feature_dtype).to(device) # X_test 为数组
y_test_tensored = torch.tensor(y_test.to_numpy(),dtype=label_dtype).to(device) # series不能直接转换为tensor,先转换为Numpy数组
return X_train_tensored,y_train_tensored,X_test_tensored,y_test_tensored# model.py
import torch.nn as nn
import torch.optim as optim
import torch
# 模型框架
class MLP(nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super(MLP,self).__init__()
self.fc1 = nn.Linear(input_size,hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size,output_size)
def forward(self,x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
def train(model,X_train,y_train,criterion,optimiser):
output = model(X_train) # 完成前向传播
loss = criterion(output,y_train) # 计算损失值
optimiser.zero_grad() # 反向传播优化前,先清零梯度
loss.backward() #反向传播
optimiser.step() #更新
return loss
def evaluate(model,X_test,y_test):
model.eval() # 进入评估模式
with torch.no_grad():
out = model(X_test) # 输入测试集,得到预测结果
_,predictions = torch.max(out,dim=1) # 获取概率最大值的索引,即预测的标签
# 计算准确率
correct_num = (predictions == y_test).sum().item() #转换int
accuracy = correct_num / y_test.size(0)
return accuracy # plot.py
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体为黑体
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
def loss_plot(x,y,x_label,y_label,title):
plt.plot(x,y)
plt.xlabel(f'{x_label.title()}')
plt.ylabel(f'{y_label.title()}')
plt.title(title.title())
plt.show()

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









