




今日任务:
- 字典的简单操作
- 标签编码
- 连续特征的处理:归一化与标准化
- 对心脏数据集实践数据预处理全过程
字典
字典可用来存储任意类型对象,内部元素由一个个键值对组成。其中键是唯一的且为不可变类型,值是可重复的。
关于字典的详细用法参考:Python字典的用法(定义、增加、删除、修改、查询、遍历)
# 使用花括号创建字典
dict = {'name': 'Alice', 'age': 25, 'city': 'New York'}
dict #{'name': 'Alice', 'age': 25, 'city': 'New York'}
# 访问字典中的值
dict['name'] #'Alice'标签编码
在day 5 中学习了对无序离散特征进行独热编码的操作。而对于存在顺序和大小关系的离散特征,一般使用的是标签编码。对于标签编码的实现,可采取:
- dataframe中的map()映射函数:先创建映射字典,然后映射。适合简单的标签编码
- sklearn中的LabelEncoder():实例化后,训练即可。适合机器学习项目,自动化程度高
import pandas as pd
data = pd.read_csv(r"D:\机器学习\Python训练营代码【2025.7.30版本】\data.csv")
data.head()采用map()函数进行标签编码时的具体步骤如下:
- 提取离散变量,根据实际意义和value_counts()判断是否为有序特征,选择编码方法
- 定义映射字典,确定编码前后的对应关系。若针对多个列编码,可使用嵌套的方法实现
- 调用data[].map(mapping_dict)进行编码
- 检查,对比编码前后
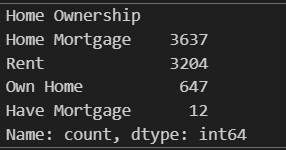
data['Home Ownership'].value_counts()#定义映射字典
mapping_dict = {
'Home Ownership':{
'Own Home':0,
'Rent':1,
'Have Mortgage':2,
'Home Mortgage':3
}
'Term':{
'Short Term':1,
'Long Term':0
}
}
#使用map映射函数
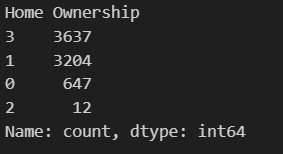
data['Home Ownership'] = data['Home Ownership'].map(mapping_dict['Home Ownership'])
data['Home Ownership'].value_counts() #检查对于“Home Ownership”这一列,选择用标签编码(有序)或者独热编码(无序)都可以。选择的编码方式,看自己的理解。在这里,如果结合实际及个人理解,按照信贷违约风险等级(从小到大)可排序为:Own Home(有自有住房) < Rent(租房) < Have Mortgage(有贷款) < Home Mortgage(有房贷),此时就是一个有序的特征了。从这个例子也可以看出,编码方式的选择并没有那么死板,需根据实际和自己的理解选择合适的方法。
编码前后对比:
注:对于字符串类型,为便于数据处理,也需要映射成整数类型,但这与常规的编码有所不同,是一种特殊的映射方式。此外,对于二分类问题,本质上只有一个自由度,采用标签编码足已。三分类以上问题需要独热编码。
归一化与标准化
对于连续变量的处理,可以采用归一化和标准化:
- 归一化(Normalization):通常是将数据缩放到[0,1]内,常用方法为最小-最大缩放(Min-Max)
- 标准化(Standardization):原始数据减均值之后,再除以标准差。将数据变换为均值为0,标准差为1的分布
对于归一化和标准化可根据公式定义手写函数实现,也可调用sklearn库中的StandardScaler和 MinMaxScaler函数进行处理。在实际情况中,对连续特征是否处理以及选择什么样的处理方式,可以根据对比实验查看训练结果,来选择合适的方法。
#连续特征处理--归一化
#手写函数
def Min_Max(data):
minium = data.min()
maxium = data.max()
normalized = (data - minium)/(maxium-minium)
return normalized
norm = Min_Max(data['Annual Income'])
print(norm.head())
在归一化的过程中,发现fit_transform()函数中的参数为双中括号(选中单列或多列),处理的是二维的DataFrame,返回的是二维的numpy数组。因此还需要注意,训练完成后要么赋值回原dataframe(Pandas自动将numpy数组转化为Series),要么手动转化为series,否则是无法调用head()等方法(数据类型不匹配)。
#连续特征处理--归一化
#调用sklearn库
from sklearn.preprocessing import StandardScaler,MinMaxScaler
min_max_scaler = MinMaxScaler()#实例化
data['Annual Income'] = min_max_scaler.fit_transform(data[['Annual Income']]) #训练
data['Annual Income'].head() #检查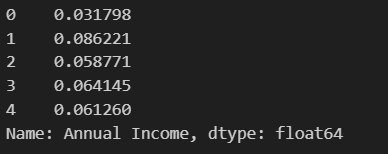
#处理同一列,重读数据
data = pd.read_csv(r"D:\机器学习\Python训练营代码【2025.7.30版本】\data.csv")
#标准化
standard_scaler = StandardScaler() #实例化
data['Annual Income'] = standard_scaler.fit_transform(data[['Annual Income']]) #学习+转换
data['Annual Income'].head() #检查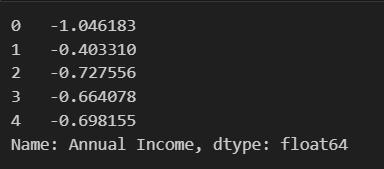
数据预处理全过程实践
使用心脏数据集实践预处理全流程,结合之前所学,步骤如下:
读取&查看数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#读取数据
data = pd.read_csv(r'heart.csv')
data.head() #读取前5行缺失值&异常值
此处暂时讨论缺失值的情况,原则上还需要分析异常值,基于现在所学知识,暂不讨论异常值。
data.info()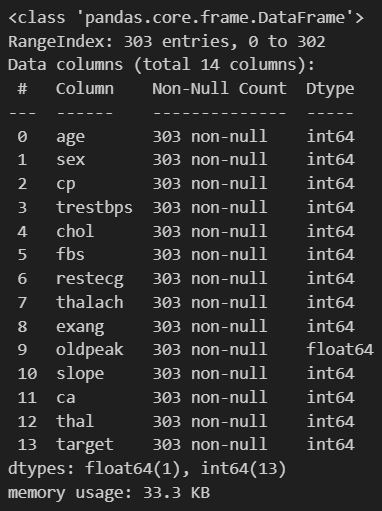
离散特征编码
可以看到数据全为数值型,故根据列的实际意义,手动区分连续特征与离散特征。对于多分类的特征,采用独热编码进行处理,理由如下:
- 避免错误的数值关系,cp=2 大于cp=1
- 大多数机器学习算法(线性回归、逻辑回归、SVM、神经网络等)需要数值输入,且不能理解类别之间的顺序关系。
- 让模型能够正确理解这些特征是分类变量,而不是有数学意义的连续数值。
此处,回顾get_dummies()的用法:
- data:指定数据,必选
- columns:指定编码列,列表形式;若data为Series形式则不选
- drop_first:是否删除第一个类别,默认False
- prefix:为创建的新列添加前缀,默认为None;若不使用,编码后的列名将直接使用原始值:cp_1,cp_2\1,2,避免含义模糊
-
pd.get_dummies() 返回的DataFrame包含所有原始列 + 新创建的独热编码列
#对于多分类特征进行独热编码
continous_features = ['age','trestbps','chol','thalach','oldpeak']
discrete_features = ['sex','cp','fbs','restecg','exang','slope','thal']
multi_features = ['cp','restecg','slope','thal']
data = pd.get_dummies(data=data,columns=multi_features,prefix=multi_features) #返回的是新的dataframe+编码列
data.head()连续特征标准化
进行标准化的原因如下:
- 公平对待所有特征:避免胆固醇等大范围特征主导模型(特征尺度的影响)
- 提高算法性能:特别是距离-based和梯度-based算法
- 加速收敛:减少训练时间,提高稳定性
- 改善正则化效果:使L1/L2正则化更有效
#对连续特征进行标准化
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler() #实例化
data[continous_features] = standard_scaler.fit_transform(data[continous_features])
data[continous_features].head()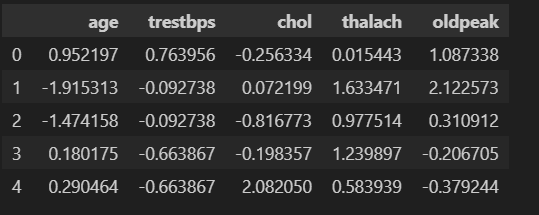

















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









