 心脏病数据预处理与可视化
心脏病数据预处理与可视化





今日任务:
- 以心脏数据集为data,回顾前6天所学的知识。
- 了解绘制子图subplot的方法
- 明确不同图表的适用类型
- 通过对数据集的初步分析,得到简单的结论
心脏病数据集的变量名说明:
| 变量名 | 详细说明 |
| target | 是否患有心脏病:0=否,1=是 |
| age | 年龄 |
| sex | 性别:1=男,0=女 |
| cp | 胸痛经历:1=典型心绞痛,2=非典型性心绞痛,3=非心绞痛,4=无症状 |
| trestbps | 静息血压(毫米汞柱) |
| chol | 血清中的胆固醇含量(毫克/分升) |
| fbs | 空腹血糖:> 120 mg/dl 为 1, 否则为 0 |
| restecg | 静息心电图测量:0=正常,1=有ST-T波异常,2=显示可能或明确的左心室肥厚 |
| thalach | 最大心率 |
| exang | 运动诱发心绞痛:1=是,0=否 |
| oldpeak | 相对于休息的旧峰 ST 抑制 |
| slope | 峰值运动ST段的斜率:1=上升,2=平坦,3=下降 |
| ca | 主要血管数量(0-3) |
| thal | 地中海贫血的血液疾病:1=正常,2=固定缺陷,3=可逆缺陷 |
读取数据
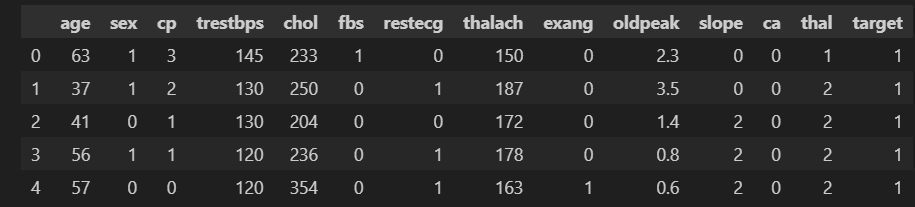
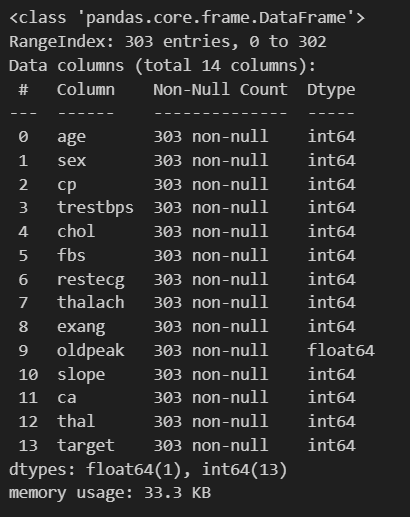
导入pandas库,读取数据的前5行。此过程主要复习读取的数据时属性和方法的调用从而了解基本的数据信息,如列名、尺寸、数据类型、统计性信息等等。
import pandas as pd
#读取数据
data = pd.read_csv(r'heart.csv')
data.head() #读取前5行data.info() #获取概览信息结果如图:
数据预处理
根据概览信息可以得到,数据列没有缺失值存在,以及所有列均为数值型数据,以目前的知识来说,暂时不需要进行编码等预处理操作。
回顾之前所学,主要学习了缺失值填充以及编码两个工作。
缺失值填充的主要步骤为:(1)明确缺失值的情况(2)选择填充方法,如使用均值填充,需要计算填充值(3)使用fillna()函数进行填充(4)检查。在这一过程也使用了循环的方法,高效地完成了多列缺失值的填充。
编码(独热编码,无序离散特征)的主要步骤为:(1)寻找离散特征(2)使用get_dummies()函数进行编码(3)寻找新特征列(4)数值转换,便于后续操作。在这一过程中也掌握了离散特征与连续特征的判断方法,但值得注意的是简单根据是否为数值型数据来判断是不准确的,要结合实际情况进行具体分析。
描述性统计
这一步骤主要是使用matplotlib和seaborn库进行绘图,进而对数据的关系进行初步可视化。
单变量分布
数值型变量分布
采用直方图,对单个数值型变量的分布进行可视化。由于变量的数据类型均为数值型,根据实际意义采取手动提取变量存放在列表中。然后创建子图,分布为3行2列。使用enumerate()函数进行遍历、画图,最后调整子图、显示。
#单个连续变量分布的直方图
continous_features = ['age','trestbps','chol','thalach','oldpeak','ca']
#创建子图
fig,axes = plt.subplots(3,2,figsize=(12,10)) #创建图形和坐标轴对象
axes = axes.flatten() # 将3x2的二维axes数组展平为1维,便于循环访问
#遍历变量并绘制直方图
for i,var in enumerate(continous_features): #使用enumerate()同时获取索引i和值var
sns.histplot(data=data,x=var,ax=axes[i]) #ax=axes[i]指定在哪个子图上绘制
axes[i].set_xlabel(var)
axes[i].set_title(f'Histogram of {var}')
plt.tight_layout() #自动调整子图间距,避免标签重叠
plt.show()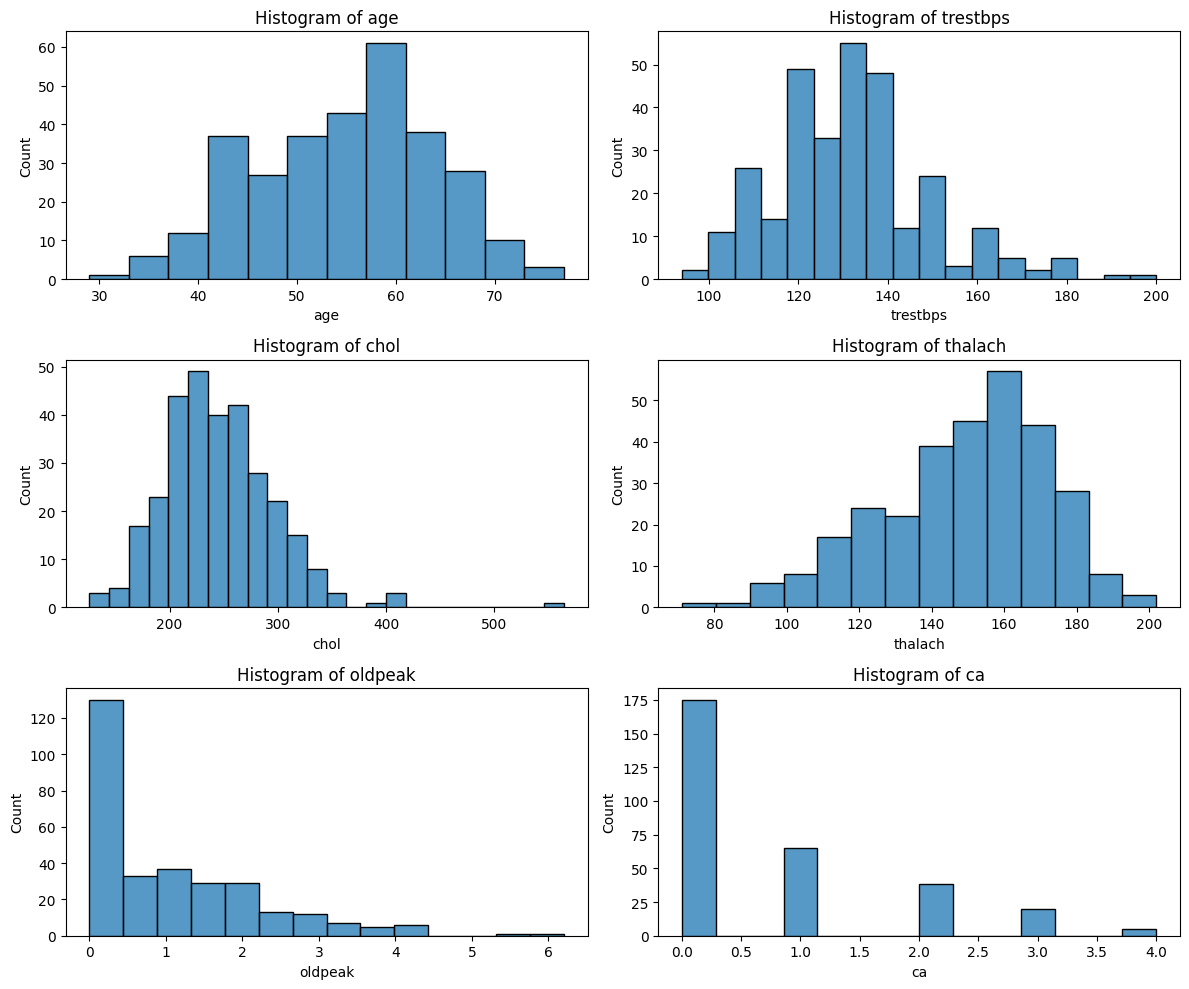
分类变量分布
对于分类,采用了计数图对其进行可视化,具体的实现步骤与数值型可视化类似。
discrete_features = ['sex','cp','fbs','restecg','exang','slope','thal',]
#创建子图
fig,axes = plt.subplots(3,3,figsize=(10,8))
axes = axes.flatten() # 将3x3的axes数组展平为1维
#遍历变量并绘制直方图
for i,var in enumerate(discrete_features):
sns.countplot(data=data,x=var,ax=axes[i])
axes[i].set_xlabel(var)
axes[i].set_title(f'Barplot of {var}')
plt.tight_layout()
plt.show()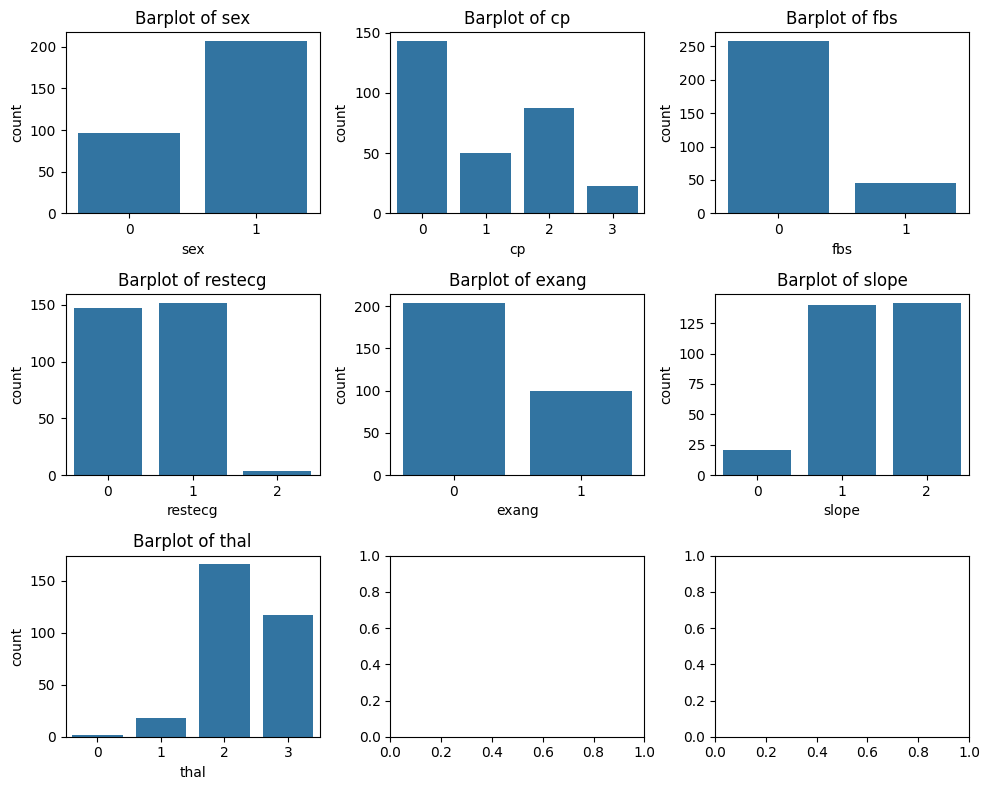
标签与特征的关系
采用箱线图展示标签与数值型特征的关系,可以看到患有心脏病和健康人群的该特征中位数、分布范围的差异以及异常值的情况。
#创建子图
fig,axes = plt.subplots(3,2,figsize=(9,7.5)) #创建图形和坐标轴对象
axes = axes.flatten() # 将3x2的二维axes数组展平为1维,便于循环访问
#遍历变量并绘制直方图
for i,var in enumerate(continous_features): #使用enumerate()同时获取索引i和值var
sns.boxplot(data=data,x='target',y=var,ax=axes[i]) #ax=axes[i]指定在哪个子图上绘制
axes[i].set_ylabel(var)
axes[i].set_xlabel('target')
axes[i].set_title(f'Boxplot of {var} & target')
plt.tight_layout() #自动调整子图间距,避免标签重叠
plt.show()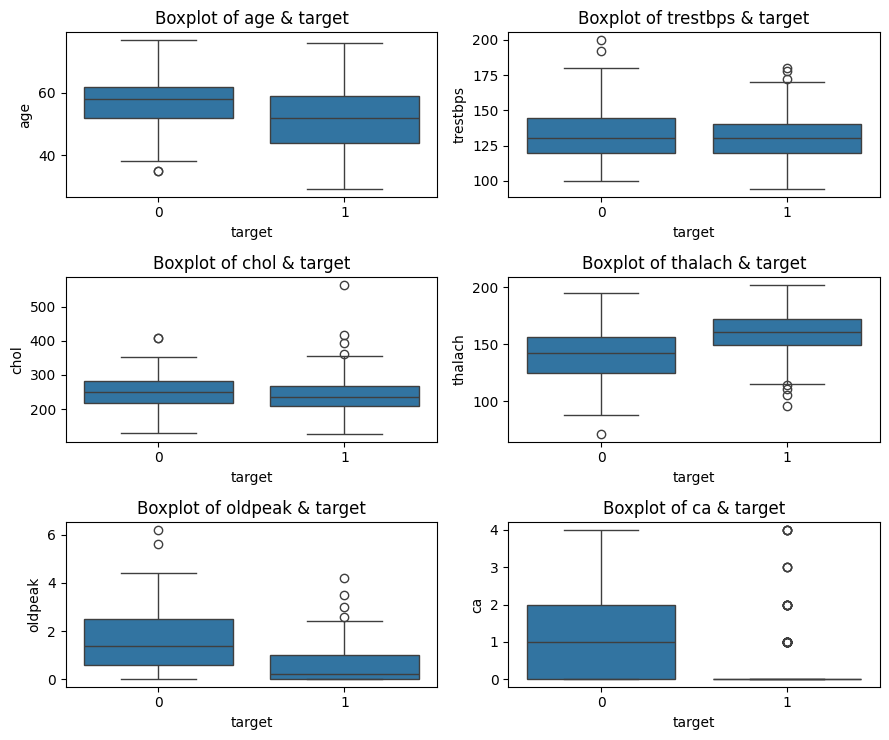
同理,分类变量与标签的关系:
#创建子图
fig,axes = plt.subplots(4,2,figsize=(12,10)) #创建图形和坐标轴对象
axes = axes.flatten() # 将4x2的二维axes数组展平为1维,便于循环访问
#遍历变量并绘制直方图
for i,var in enumerate(discrete_features): #使用enumerate()同时获取索引i和值var
sns.countplot(data=data,x=var,hue='target',ax=axes[i]) #ax=axes[i]指定在哪个子图上绘制
axes[i].set_xlabel(var)
axes[i].set_title(f'Boxplot of {var} & target')
plt.tight_layout() #自动调整子图间距,避免标签重叠
plt.show()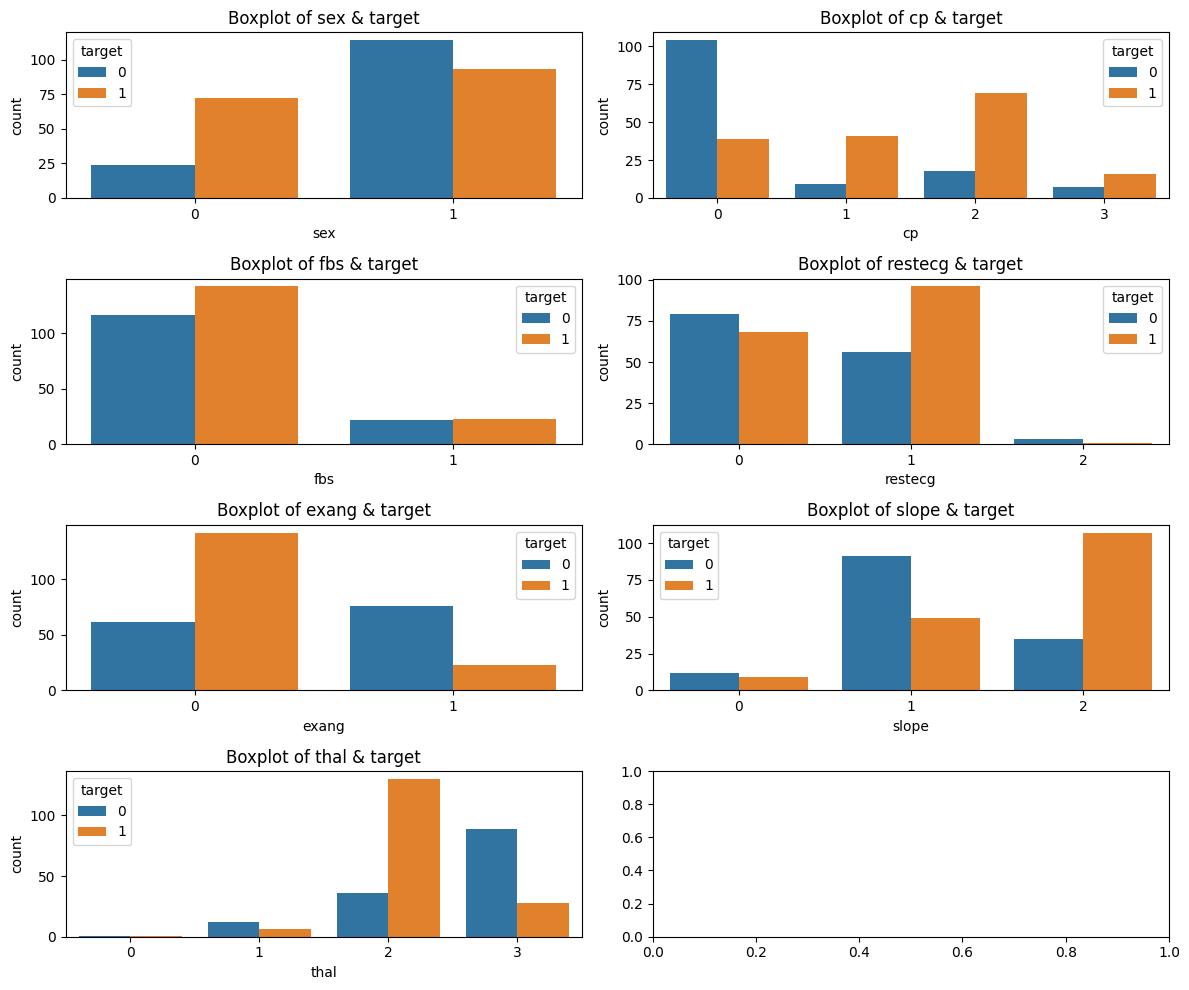
特征间的关系
使用热力图展示变量间的关系,绘制热图前先计算相关性矩阵。heatmap():
-
correlation_matrix: 要可视化的相关系数矩阵 -
annot=True: 在每个单元格中显示具体的数值 -
cmap='coolwarm': 颜色映射方案。蓝色系:负相关,白色:弱相关或无关,红色系:正相关 -
fmt='.2f': 数值显示格式,保留2位小数 -
linewidths=0.5: 单元格之间的边框线宽度
plt.figure(figsize=(12, 10))
# 计算相关性矩阵
correlation_matrix = data.corr(numeric_only=True) #只计算数值型列的相关性
# 绘制热力图,用颜色深浅表示相关性大小
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5)
plt.title('Correlation Matrix of Features')
plt.show()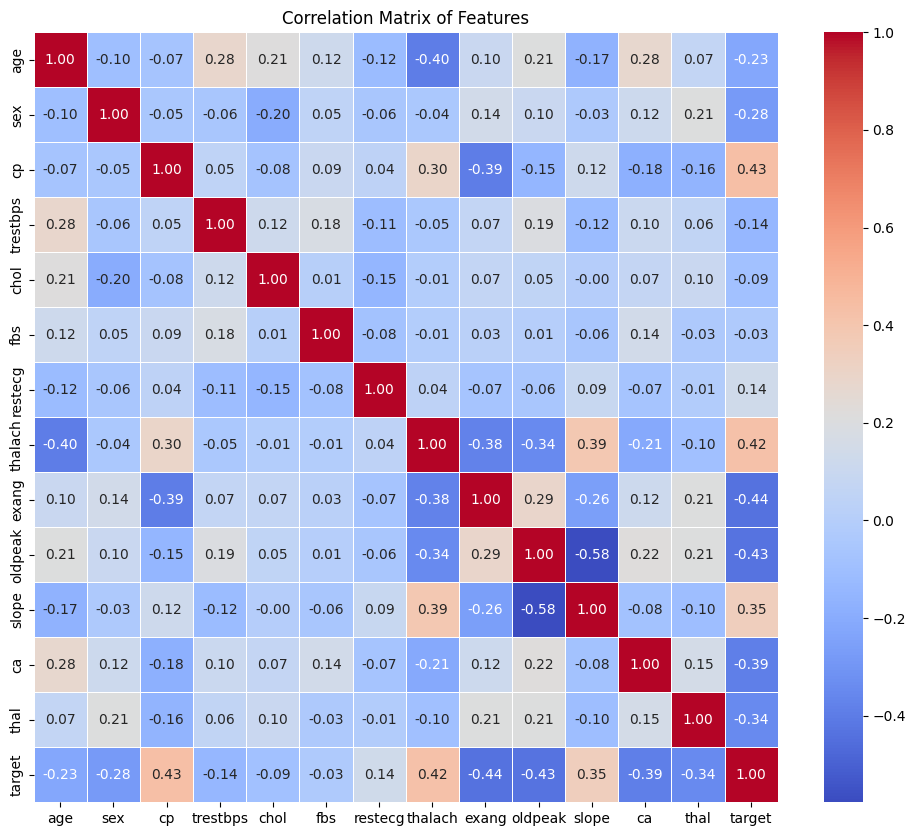

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









