



 本文详细介绍了XGBoost模型及其优势,包括其背后的原理、参数设置与调优策略。通过贝叶斯优化等方法实现高效参数选择,助力读者掌握这一强大的机器学习工具。
本文详细介绍了XGBoost模型及其优势,包括其背后的原理、参数设置与调优策略。通过贝叶斯优化等方法实现高效参数选择,助力读者掌握这一强大的机器学习工具。
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:王茂霖,华中科技大学,Datawhale成员
内容概括
XGBoost模型及调参总结
XGBoost原理
XGBoost优势总结
XGBoost参数详解
XGBoost快速使用
XGBoost调参方法
PPT下载:后台回复“210502”可获取
XGBoost模型介绍

一、XGBoost原理
 XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度。
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度。
二、XGBoost优势总结

XGBoost模型调参
一、XGBoost参数详解
1.一般参数



2.学习目标参数

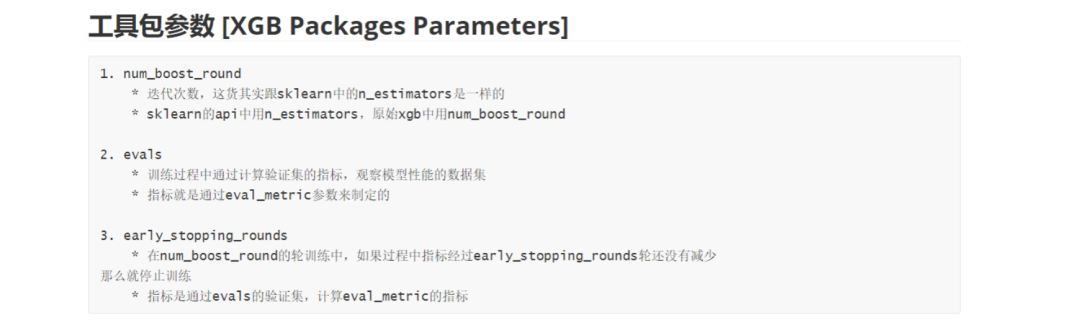
3.工具包参数
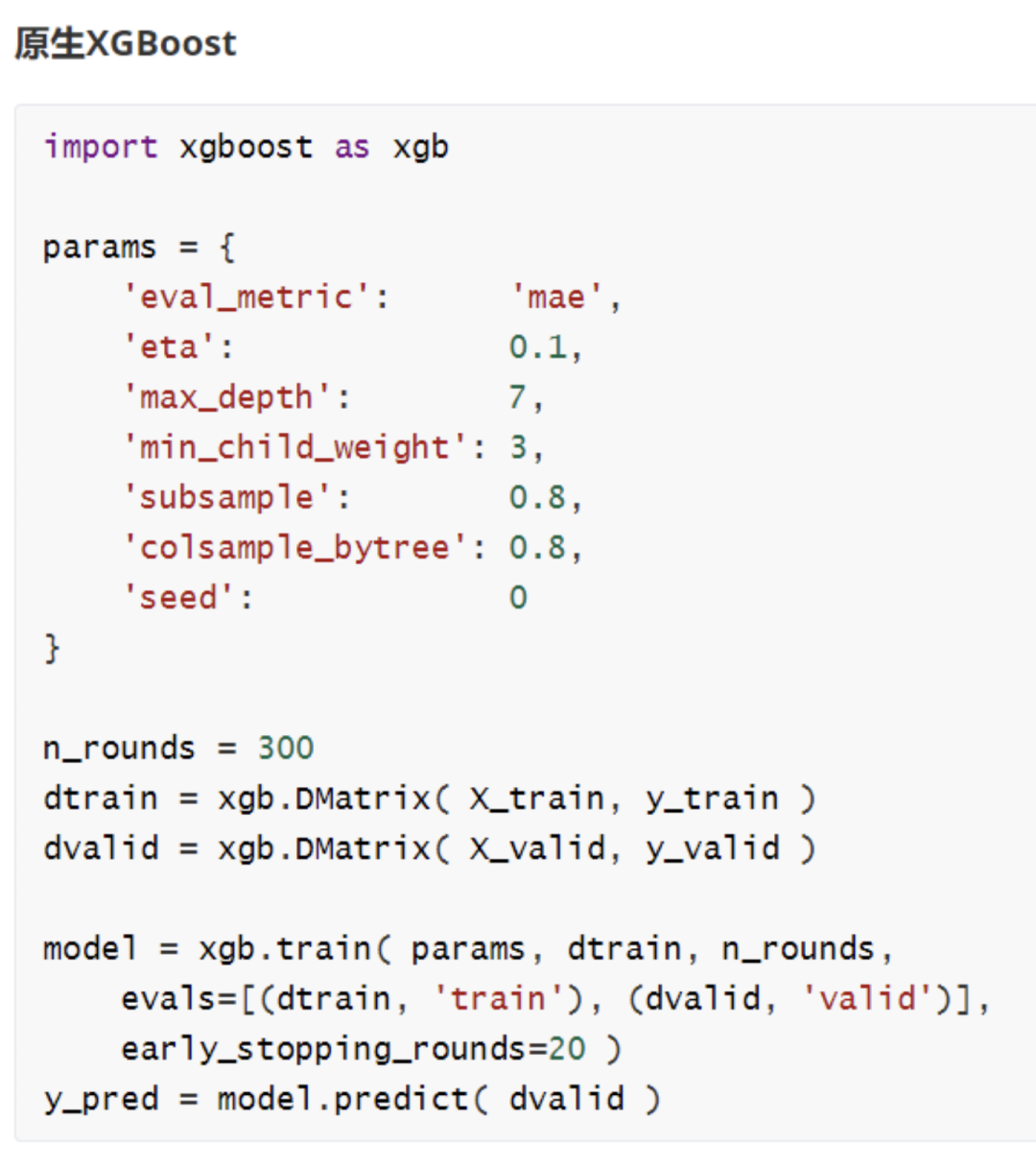
二、XGBoost快速使用

三、XGBoost调参方法(贝叶斯优化)
Hyperopt是一个sklearn的python库,在搜索空间上进行串行和并行优化,搜索空间可以是实值,离散和条件维度。
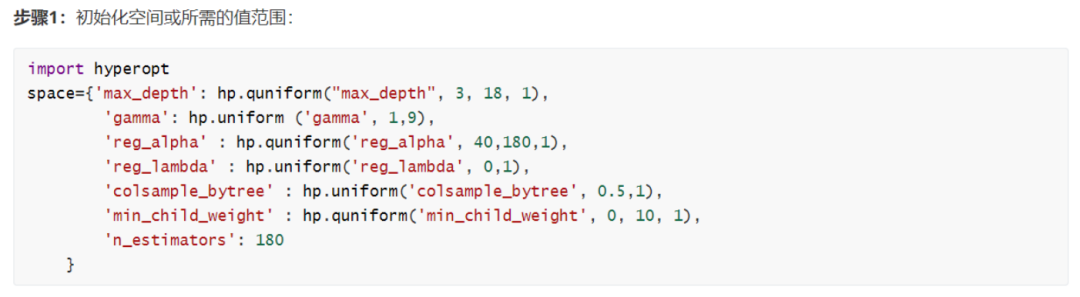
1.初始化空间所需的值范围
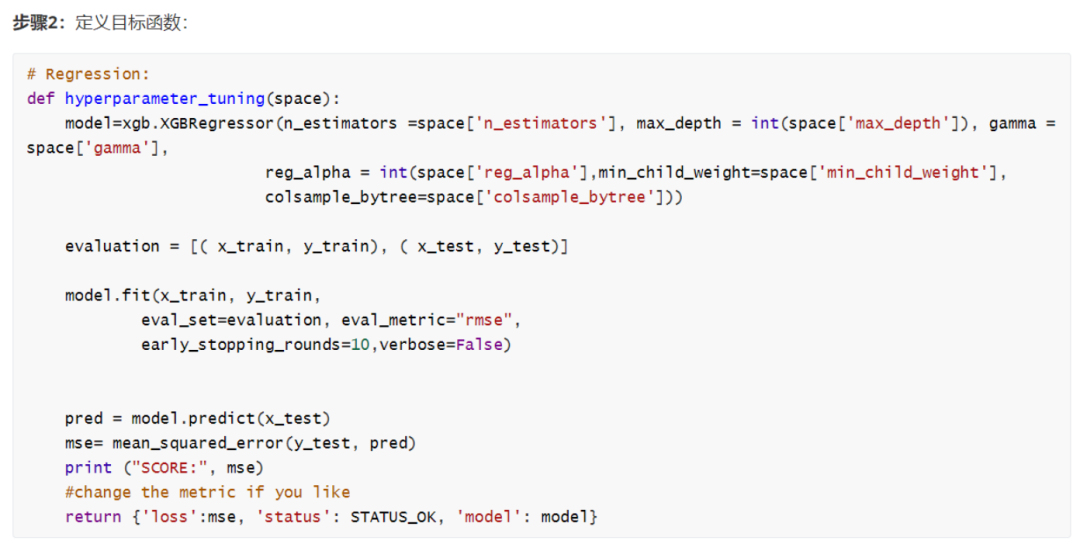
2.定义目标函数
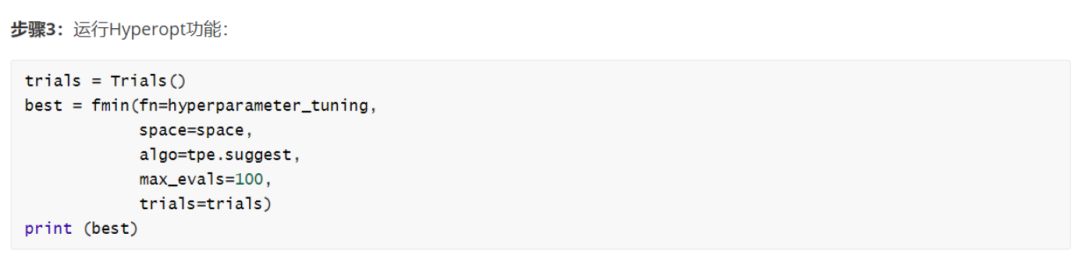
3.运行hyperopt功能
本文作者
王茂霖,Datawhale重要贡献成员,Datawhale&天池数据挖掘学习赛开源内容贡献者,阅读超10w。
参赛30余次,获得DCIC-数字中国创新创业大赛亚军,全球城市计算AI挑战赛,Alibaba Cloud German AI Challenge等多项Top10。

整理不易,点赞三连↓

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









