



Datawhale干货
作者:鱼佬,2019、2020腾讯广告算法大赛冠军
过去十年,广告推荐系统构筑了互联网商业的核心引擎。每天,数以百亿次的推荐决策在“召回-粗排-精排”的多阶段流水线中完成,这套成熟体系支撑着万亿规模的数字广告市场,却也逐渐显露出其内在局限。
近日,腾讯广告联合清华大学发布的论文《GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation》提出了一个大胆的解法:拆掉流水线,用生成式AI重构一切。

论文地址:https://arxiv.org/pdf/2511.10138
这不仅仅是一项技术创新,更意味着广告推荐技术范式的一次根本性转变,从分阶段的“检索匹配”逻辑,逐步转向端到端的“内容生成”逻辑。
一、范式革命:告别传统推荐系统的“接力困境”
传统广告推荐系统的架构,像一场精心设计的接力赛。召回阶段负责从海量候选池中筛选出数千个相关广告,粗排阶段进一步精简到数百个,最后由精排模型基于CTR、CVR等复杂目标做出最终排序。
这种多阶段架构存在三个根本性缺陷:
目标割裂:不同阶段优化目标不同,召回追求覆盖率,精排追求转化率,导致系统难以实现全局最优。
误差累积:前序阶段的错误筛选无法在后序阶段被纠正,形成“一步错,步步错”的连锁反应。
工程复杂:多套模型独立训练部署,特征对齐、实时更新、系统维护成本极高,严重制约迭代速度。
而微信视频号等场景下,广告与自然内容高度交织,用户行为呈现极度异构性,传统架构的不足被进一步放大。
GPR的提出,正是对这一困局的系统性回应。它不再试图优化接力赛中的每一棒,而是重新设计了整场比赛,用单一模型直接完成从理解用户到生成推荐的全过程。
二、解析GPR核心技术:如何让模型“懂”用户?
GPR之所以能做到“一个模型搞定所有”,依靠的是三大核心技术支柱,每一支柱都对应着广告推荐场景下的核心挑战。
1. 统一表示:四类Token构建全景用户画像
传统推荐系统需要为不同类型的特征(用户属性、行为序列、上下文信息)设计复杂的交叉网络。GPR创新性地提出了四类Token的统一表示框架:
U-Token:编码用户静态属性与长期偏好
O-Token:表示用户消费的自然内容(短视频、文章等)
E-Token:捕捉广告请求的实时上下文环境
I-Token:代表用户历史交互过的广告项目
这四类Token按时间顺序排列,形成一个连续的序列,彻底统一了异构数据的表示方式。更重要的是,GPR提出的RQ-Kmeans+算法,将广告和自然内容映射到统一的语义ID空间。
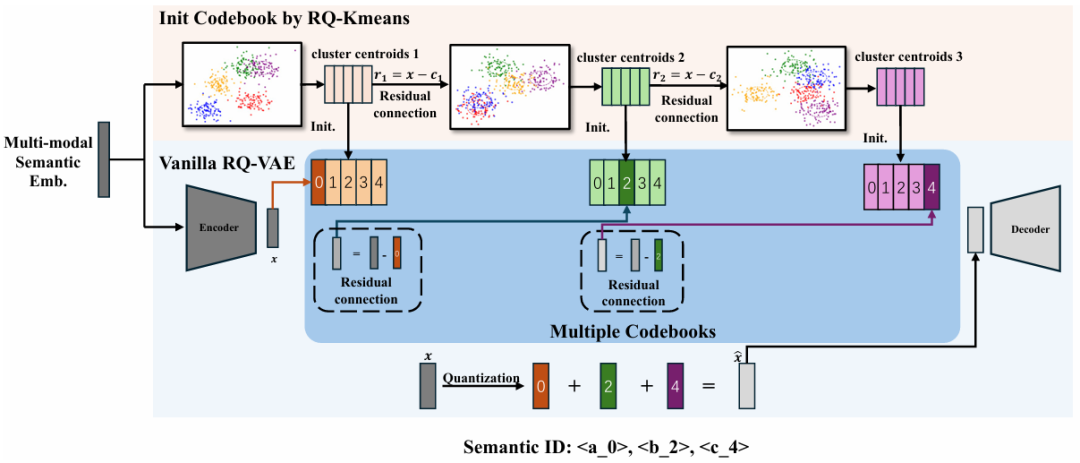
RQ-Kmeans+算法结构
这个算法缓解了传统方法的“码本坍塌”问题。具体地,先用传统的RQ-Kmeans获得一个高质量初始码本,再基于此进行可微分的量化训练。这种方法的精妙之处在于平衡了码本质量与训练稳定性,纯聚类方法能获得分布均匀的码本但无法端到端优化,纯梯度方法容易坍塌但有更好的表示能力。最终将码本利用率提升至99.36%,语义一致性达到99.2%。这些结果表明,被 RQ-KMeans+ 归入同一语义ID下的项目更有可能属于相同类别且具有更高的相似性,从而产生了更合理的代码碰撞。
2. 异构分层解码:理解、思考、精炼的三段式生成
如果说统一表示是GPR的“骨骼”,那么异构分层解码器(HHD)就是其“大脑”。HHD采用双解码器架构,将用户理解与项目生成解耦。
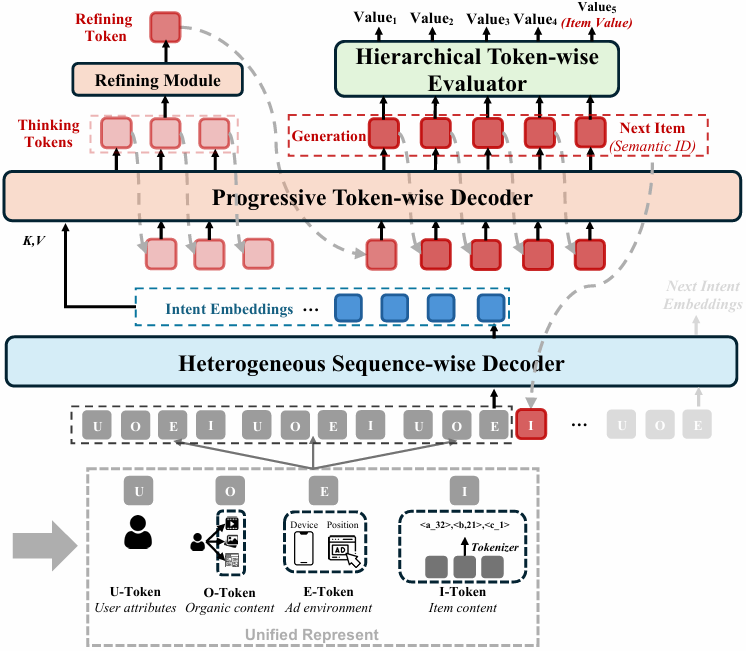
GPR的训练策略同样分层递进,形成完整的能力构建路径:
第一层:异构序列解码器(HSD,Heterogeneous Sequence-wise Decoder)——深度理解用户意图。
HSD如同系统的“感知与理解层”,专门负责从用户超长行为序列中提取意图。这里的技术创新点在于混合注意力机制的设计,在U/O/E-Token组成的用户画像部分使用双向注意力,允许模型充分挖掘用户特征间的内在联系,而在处理历史行为序列时切换回标准的因果注意力。
这种设计巧妙平衡了表示能力与生成约束。同时,HSD还为不同类型的Token配备独立的归一化层和前馈网络,让每种信息都能在最适合的语义子空间中被处理。
第二层:渐进令牌解码器(PTD, Progressive Token-wise Decoder)——执行“思考-精炼-生成”的推理过程。
这种设计直接回应了传统生成模型的一个关键缺陷“单次解码缺乏自我校准能力”,这也是GPR最具创新性的部分。PTD并不直接生成广告,而是先生成K个“思考Token”,这些Token不直接对应具体广告,而是对用户意图的抽象提炼。接着通过一个基于扩散模型的“精炼模块”,对思考结果进行去噪和优化。
最终,结合思考与精炼结果,PTD才生成代表目标广告的语义ID序列。这个过程模拟了人类的决策逻辑,先理解情境,再分析权衡,最后做出选择。
价值评估一体化:HHD中还集成了分层令牌评估器(HTE,Hierarchical Token-wise Evaluator),在生成广告的同时预测其CTR、CVR、eCPM等业务指标,并将它们聚合为统一的“最终价值”,为后续的竞价排序提供直接依据。
三、多阶段训练,从“博学”到“专精”
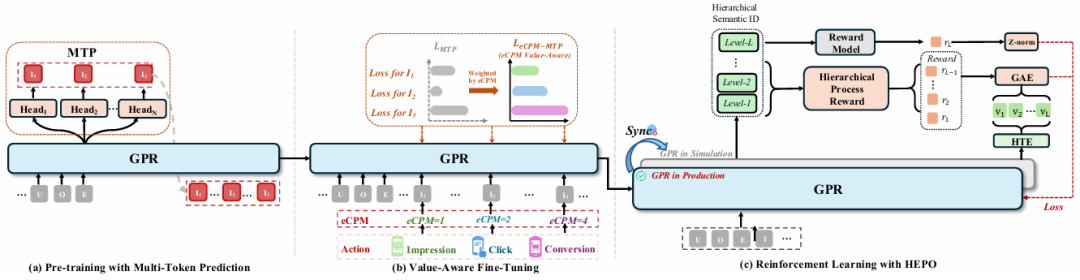
GPR的训练策略同样分层递进,形成了一条从兴趣建模到价值对齐的完整能力构建路径。
第一阶段:预训练阶段采用多令牌预测(MTP)——捕获全局、多兴趣用户模式
使用多个Head并行预测多个兴趣路径,显式建模用户可能存在的多个并行兴趣,避免传统单一路径预测对多样性的抑制。通过掩码广告token、用户行为token的方式,让模型在无监督场景下学习异构数据的语义关联,这种预训练方式使得模型的基础理解能力明显提升。
第二阶段:对齐微调阶段引入价值感知损失(VAFT)——高价值广告优先
根据广告的实际价值(曝光、点击、转化)和eCPM动态调整损失权重,创新引入动态权重机制(转化>点击>曝光),让模型学会优先关注高价值项目。这种损失权重公式的设计看似简单,实则蕴含精巧平衡:
对于曝光,权重与eCPM成正比
对于点击,权重与eCPM/pCTR成正比(奖励高点击质量的广告)
对于转化,权重与eCPM/(pCTR×pCVR)成正比(奖励真正驱动转化的广告)
这个设计确保了模型不会为了短期点击而牺牲长期价值。另外,这三个系数的校准也是相当麻烦的一件事,微小的调整都会导致模型行为显著变化。
第三阶段:强化学习阶段采用分层增强策略优化(HEPO)——解决“层次过程奖励”问题
针对广告"展现→点击→转化→复购"的决策树特性,设计分层奖励机制,通过为每个层次构建直接监督信号,使模型不仅关注短期转化,更能优化长期商业价值。HEPO算法解决了"层次过程奖励"问题,避免了传统强化学习中粗粒度决策的信用分配问题。
四、个性化索引树:大规模推理的工程智慧
生成式推荐最怕的是“慢”。
在实际部署中,GPR面临着一个所有生成式推荐系统都会遇到的难题:如何从数千万候选广告中高效生成Top-K结果?
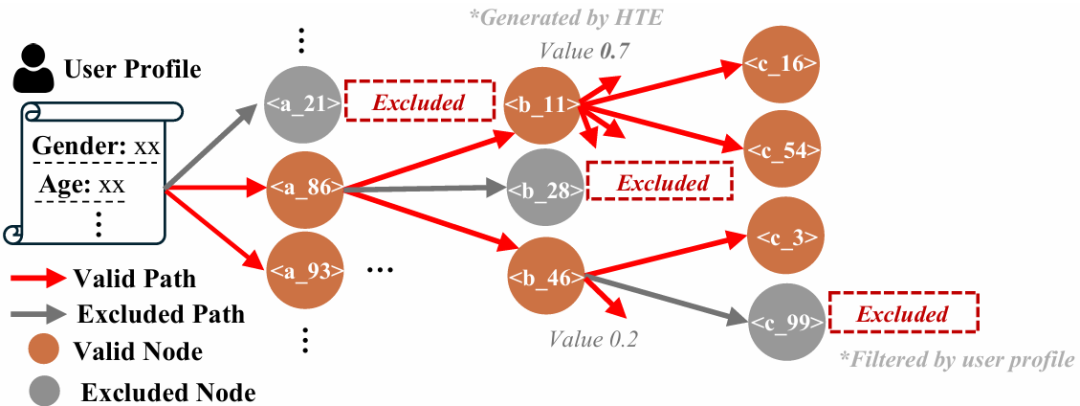
传统方法通常依赖近似最近邻搜索,但这对生成式模型并不适用。GPR团队的解决方案是构建动态个性化索引树,针对每个用户的每次请求,实时构建一个树状检索结构。
这棵树的构建巧妙融合了多种信息:
用户画像约束:基于地域、兴趣标签等过滤不符合条件的广告
实时业务规则:排除预算耗尽的广告、频控已达上限的广告
语义聚类结构:利用RQ-Kmeans+生成的多层次语义ID,天然形成树状组织
在束搜索过程中,这棵树不仅提供剪枝约束,还与HTE模块的价值预测深度结合。当模型生成到语义ID的某一层级时,系统会参考该节点下所有子节点的预估价值,动态调整束搜索宽度,价值越高的分支获得越多的探索机会。
五、展望未来,超越广告的生成式推荐生态
站在技术演进的角度看,GPR代表了推荐系统发展的新阶段。从早期的协同过滤,到深度学习推荐模型,再到今天的生成式推荐,每一次范式变革都带来了能力的阶跃式提升。
GPR论文中提到的“思考-精炼-生成”范式,与大型语言模型的推理过程高度相似。这提示我们,推荐系统与生成式AI的技术路线正在深度融合。未来,我们或许会看到更通用的“生成式理解模型”,能够同时处理推荐、搜索、对话等多种任务。
从单点突破到生态重构,GPR带来的不仅是更高效的广告匹配,更是一种全新的内容分发理念。在这个理念下,系统不再被动响应用户的历史行为,而是主动理解用户的潜在意图;不再机械地拼接特征交叉,而是生成符合情境的完整体验。
正如论文作者所言,GPR推动广告推荐系统“从分阶段优化向端到端智能决策演进”。这场演进才刚刚开始,但方向已经清晰,未来的推荐系统,将是一个能够真正理解用户、创造价值的智能伙伴,而不仅仅是一个高效的匹配引擎。
当技术能够跨越“推荐”与“生成”的界限,或许我们终将迎来一个人机理解无缝衔接的数字生态。而GPR,正是通向那个未来的重要一步。

一起“点赞”三连↓

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









