




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:MMGDreamer: Mixed-Modality Graph for Geometry-Controllable 3D Indoor Scene Generation
论文链接:https://arxiv.org/pdf/2502.05874
开源代码:https://yangzhifeio.github.io/project/MMGDreamer
导读
可控场景生成是指根据输入提示生成逼真的3D场景,并允许对这些场景中的特定物体进行精确控制和调整。它广泛应用于虚拟现实、室内设计和具身智能,提供沉浸式体验并增强决策过程。在这些应用中,场景图作为一种强大的工具,通过简洁地抽象场景上下文和物体之间的相互关系,实现直观的场景操作和生成。
简介
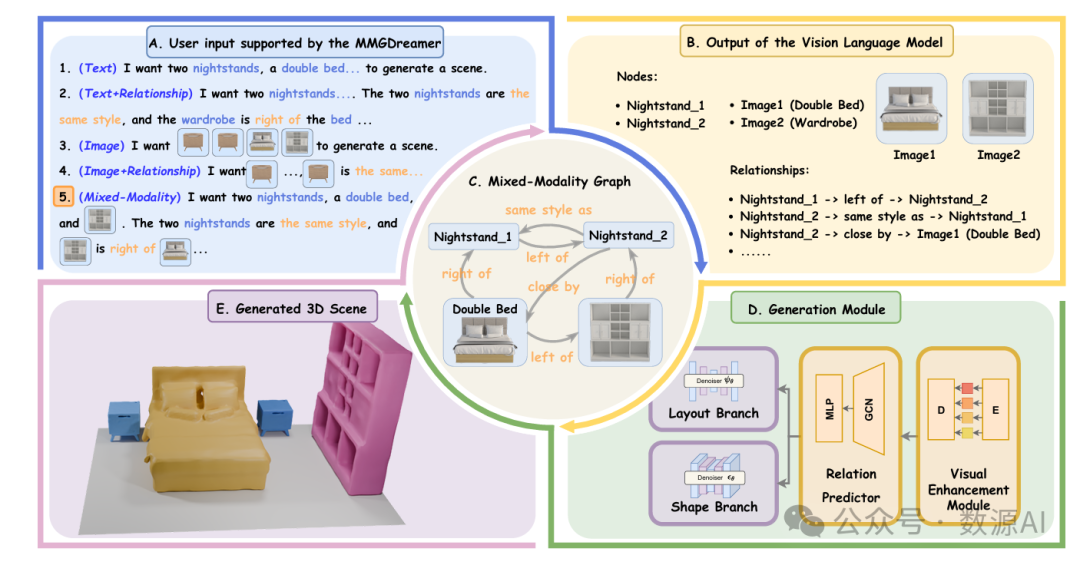
可控的3D场景生成在虚拟现实和室内设计中有着广泛的应用,生成的场景应在几何方面表现出高度的真实感和可控性。场景图提供了一种合适的数据表示方式,便于这些应用的实现。然而,当前基于图的场景生成方法局限于基于文本的输入,对灵活的用户输入适应性不足,阻碍了对物体几何形状的精确控制能力。为解决这一问题,我们提出了MMGDreamer,这是一种用于场景生成的双分支扩散模型,它结合了一种新颖的混合模态图、视觉增强模块和关系预测器。混合模态图允许物体节点整合文本和视觉模态,节点之间存在可选关系。它增强了对灵活用户输入的适应性,并能够对生成场景中物体的几何形状进行精细控制。视觉增强模块通过使用文本嵌入构建视觉表示,丰富了仅含文本节点的视觉保真度。此外,我们的关系预测器利用节点表示来推断节点之间缺失的关系,从而产生更连贯的场景布局。大量实验结果表明,MMGDreamer在物体几何形状控制方面表现出色,实现了最先进的场景生成性能。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1470
1470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









