









论文链接:https://arxiv.org/pdf/2408.11475
项目链接:https://zhtjtcz.github.io/TrackGo-Page/
★亮点直击
本文引入了一种新颖的运动可控视频生成方法,称为TrackGo。该方法为用户提供了一种灵活的运动控制机制,通过结合 masks 和箭头,实现了在复杂场景中的精确操控,包括涉及多个对象、细粒度对象部件和复杂运动轨迹的场景。
本文开发了一个新组件,称为TrackAdapter,用于有效且高效地将运动控制信息集成到时间自注意力层中。
本文进行了广泛的实验来验证本文的方法。实验结果表明,本文的模型在视频质量(FVD)、图像质量(FID)和运动真实性(ObjMC)方面优于现有模型。
近年来,基于扩散的可控视频生成领域取得了显著进展。然而,在复杂场景中实现精确控制仍然是一个挑战,包括对细粒度的物体部分、复杂的运动轨迹以及连贯的背景运动的控制。在本文中,本文介绍了TrackGo,这是一种利用自由形式的masks和箭头进行条件视频生成的新方法。该方法为用户提供了一种灵活且精确的机制来操控视频内容。本文还提出了用于控制实现的TrackAdapter,这是一种高效轻量的适配器,旨在无缝集成到预训练视频生成模型的时间自注意力层中。该设计利用了本文的观察,即这些层的注意力图可以准确激活与视频中运动对应的区域。本文的实验结果表明,借助TrackAdapter增强的新方法在关键指标如FVD、FID和ObjMC得分上实现了最先进的性能。
方法
概览
本文的任务是运动可控的视频生成。对于输入图像 和从箭头中提取的点轨迹 ,描述了轨迹信息,生成与轨迹一致的视频 ,其中 表示视频的长度。
我们使用SVD模型(Stable Video Diffusion Model, SVD)作为本文的基础架构。SVD模型类似于大多数视频潜在扩散模型,在图像扩散的U-Net上添加了一系列时间层以形成3D U-Net。在此基础上,本文通过一个可训练的编码器 将点轨迹 转化为压缩表示 。然后将该表示注入到每个时间自注意力模块中,使用下采样来处理并适应到合适的分辨率。本文引入了TrackAdapter,并在SVD的每个时间自注意力中添加一个TrackAdapter来注入 ,如下图3所示。
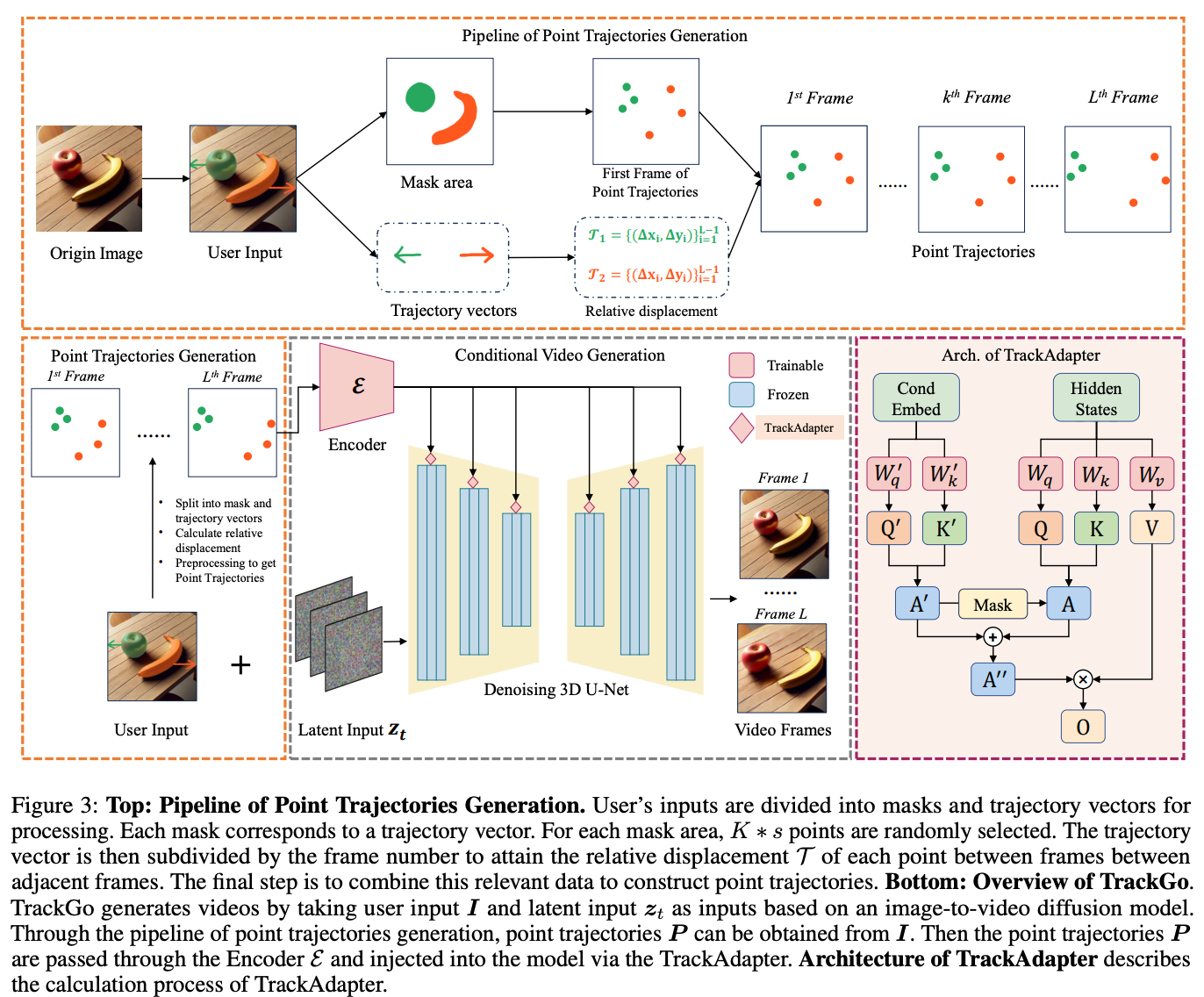
在接下来的部分中,本文将讨论三个主要主题:
-
点轨迹的优势以及本文如何获取和使用它们。
-
TrackAdapter的结构以及它如何帮助SVD理解复杂的运动模式并完成复杂动作的生成。
-
我们模型的训练和推理过程。
点轨迹生成
在推理过程中,当用户提供第一帧图像、编辑区域的masks以及相应的箭头时,本文的方法可以通过预处理将用户输入的masks和箭头转换为点轨迹,如上图3所示。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









