 多模态大模型统一表征全景
多模态大模型统一表征全景





1 绪论
当下的大模型已经从“只会聊天的文本模型”快速演变为“能够看图、看视频、理解文档、生成三维场景的通用智能体”。从 OpenAI 的 GPT-4o 到各类开源多模态大模型,它们背后的核心思想,都可以压缩成一句话:构建一个尽可能统一的表征空间,让文本、图像、音频、视频乃至 3D 场景在同一空间中“说话”。(Towards AI)
这一趋势在开源世界尤为明显:从 CLIP 式的文本-图像对比学习,到 LLaVA 为代表的视觉语言助手,再到 Meta 的 ImageBind 尝试一次性绑定六种模态,直至 Janus、UGen、Emu2、Show-o2、WeGen 等统一“理解+生成”的 Any-to-Any 模型,社区已经形成一个以“统一表征”为主线的演化谱系。(arXiv)
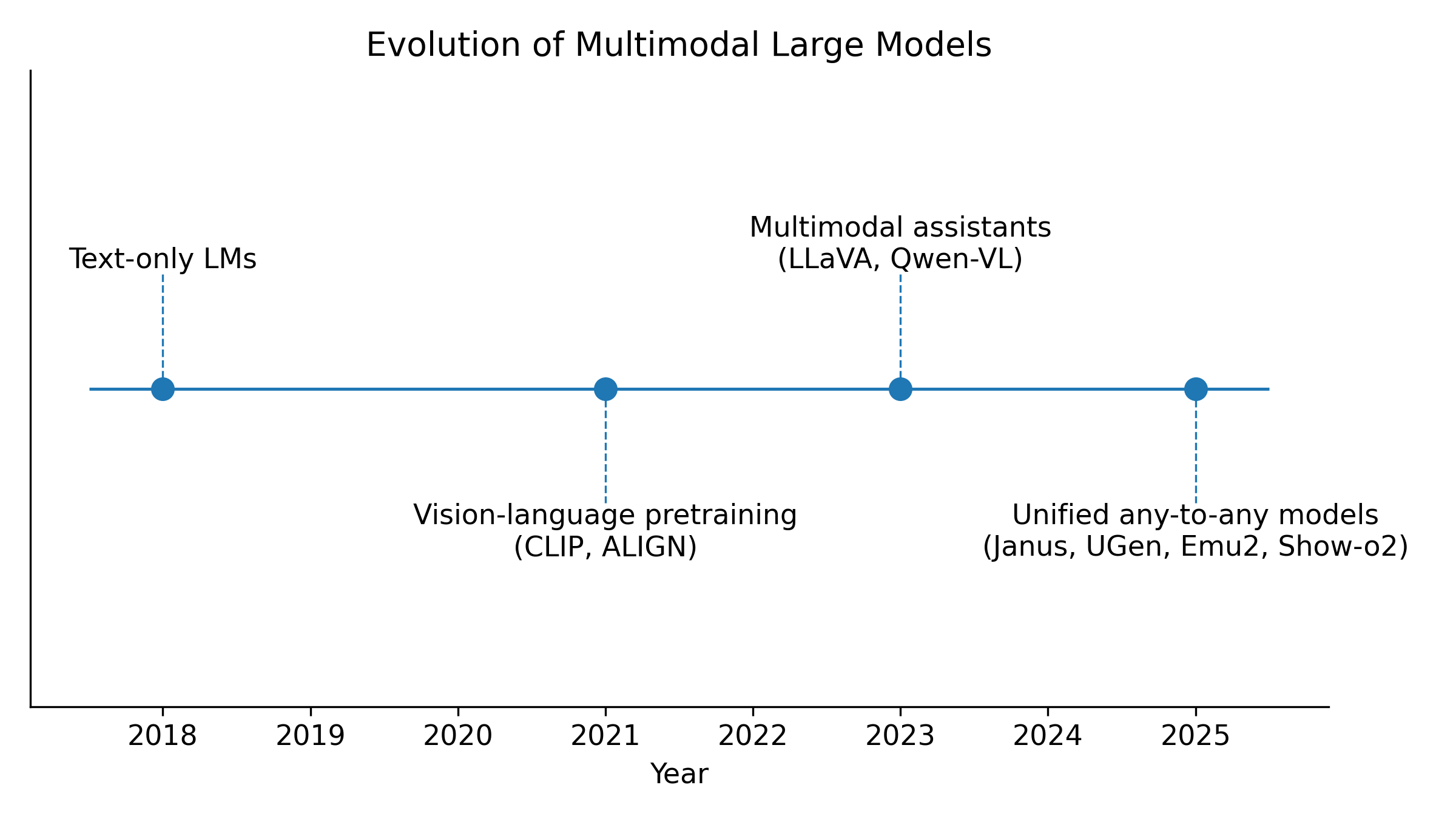
图1:多模态大模型技术演进时间轴:从文本-only 到 文本-图像,再到 视频/3D 统一模型
在工业应用层面,多模态统一表征让很多以前需要“堆系统”的场景变得自然:一个模型既能读 PDF 文档,又能看嵌在里面的表格和图片,还能根据视频截图推断 3D 结构,并用自然语言解释整个流程。这种“端到端多模态智能体”的出现,让传统的模块化 CV+NLP 系统逐渐被统一的多模态大模型替代。(ACL Anthology)
在这篇文章中,我们将沿着“统一表征”这条主线,从理论与工程两个视角,系统梳理从文本-图像到视频-3D 的多模态大模型体系,重点聚焦开源模型与最新文献,并给出若干面向工程实践的分析与建议。
2 多模态统一表征的理论基础
2.1 统一表征空间与模态对齐
多模态统一表征最朴素的目标,是把不同模态的数据映射到同一个向量空间,使得“语义相近”的样本在空间中靠得更近。早期的 CLIP / ALIGN 就采用了双塔结构,通过大规模图文配对数据进行对比学习,让文本和图像在同一表征空间中对齐,这是后来几乎所有视觉-语言大模型的共同起点。(Encord)
在更高维度上,ImageBind 进一步证明:并不需要所有模态两两配对,只要有“图像-文本”、“图像-音频”、“图像-深度”等部分配对,就可以通过图像这一“枢纽模态”把六种模态绑定到统一的嵌入空间中,包括图像/视频、文本、音频、深度、热成像和 IMU。(arXiv) 这种“图像作桥”的思想,为后续将视频、3D 等模态纳入统一表征提供了重要启发。
统一表征空间的设计通常涉及三个关键问题。第一,选择什么结构作为 backbone:经典做法是使用 Transformer 作为统一的序列建模器,用 ViT 或视觉 VAE 将图像/视频离散化成 token,再让文本 tokenizer 产生的 token 与之在同一序列中共存。第二,用什么目标函数进行对齐:对比学习、互信息最大化、多任务联合、甚至直接统一自回归生成目标,都是常见选择。第三,如何处理模态不对齐与缺失:现实世界里,某些样本只有图像没有文本,或者只有视频和字幕但没有语音标签,此时就需要通过掩码建模、伪标签或弱监督等方式,让模型学会“在缺失模态下依然自洽”。(arXiv)
2.2 自回归、扩散与混合范式
在生成建模走向多模态的过程中,自回归 Transformer 与扩散模型逐渐形成两大阵营。Emu / Emu2 代表的一条路线,是把文本、图像甚至视频统统离散化成 token,再用一个统一的自回归大模型按序列生成,从而在一个统一的 token 空间内同时做理解与生成。(arXiv)
另一条路线则是以扩散为核心的“连续空间生成”,例如文本到图像、文本到视频、文本到 3D 等任务,通常在扩散模型中进行;为了统一表征,很多工作采用“离散 token + 扩散 decoder”混合结构,即用自回归 Transformer 生成语义 token,再交给扩散模型在像素或 3D 空间中解码,从而兼顾语言空间的灵活推理与视觉空间的高质量生成。(Emergent Mind)
在最新一批统一多模态模型中,Janus、UGen、WeGen、Show-o2 等都更偏向统一自回归 Transformer,将理解与生成都投射为“下一 token 预测”,只是在视觉 token 的表示与训练策略上不断做改进,使得模型既能对图像/视频进行细粒度理解,又能生成高质量图像甚至视频。(arXiv)
2.3 模态不平衡与信息瓶颈
多模态训练中一个经常被忽略但非常关键的问题,是模态不平衡与学习动态失衡。近年来的研究通过自适应 loss、模态加权等方法,试图让模型在不同模态间保持更均衡的学习进度,从而避免“强模态拖拽弱模态”的现象。(ResearchGate)
随着模型规模的不断增大,统一表征也面临新的信息瓶颈:一方面,统一 token 空间会导致视觉信息被过度压缩,影响精细生成质量;另一方面,过于细粒度的视觉 token 则会拖慢训练与推理,尤其是在长视频、3D 场景等任务中。因此,如何在统一表征与模态特化之间取得平衡,是接下来一段时间内多模态模型设计的核心议题之一。(GitHub)
3 文本-图像统一表征:从 CLIP 到视觉语言助手
3.1 对比学习到指令对齐
文本-图像多模态是统一表征的起点。CLIP/ALIGN 类模型通过图文对比学习获得了一个强大的联合嵌入空间,能够在零样本条件下完成分类、检索等任务。这个空间从数学上看只是一个高维向量空间,但从工程上看,它像是一个“跨模态词典”,用统一的“语义坐标”刻画图文内容。(Encord)
在此基础上,视觉语言模型(VLM)通过在 CLIP 之类的视觉 backbone 上叠加大语言模型,构建起了图像条件下的自然语言推理能力。LLaVA 是其中最有代表性的开源工作之一,它采用 CLIP ViT-L/14 作为视觉编码器,将图像特征通过一个线性投影层映射到语言 token 空间,再用 Vicuna / LLaMA 作为 decoder,通过 GPT-4 生成的视觉指令数据进行对齐,从而实现“像 GPT-4V 那样聊图”的能力。(LLaVA)
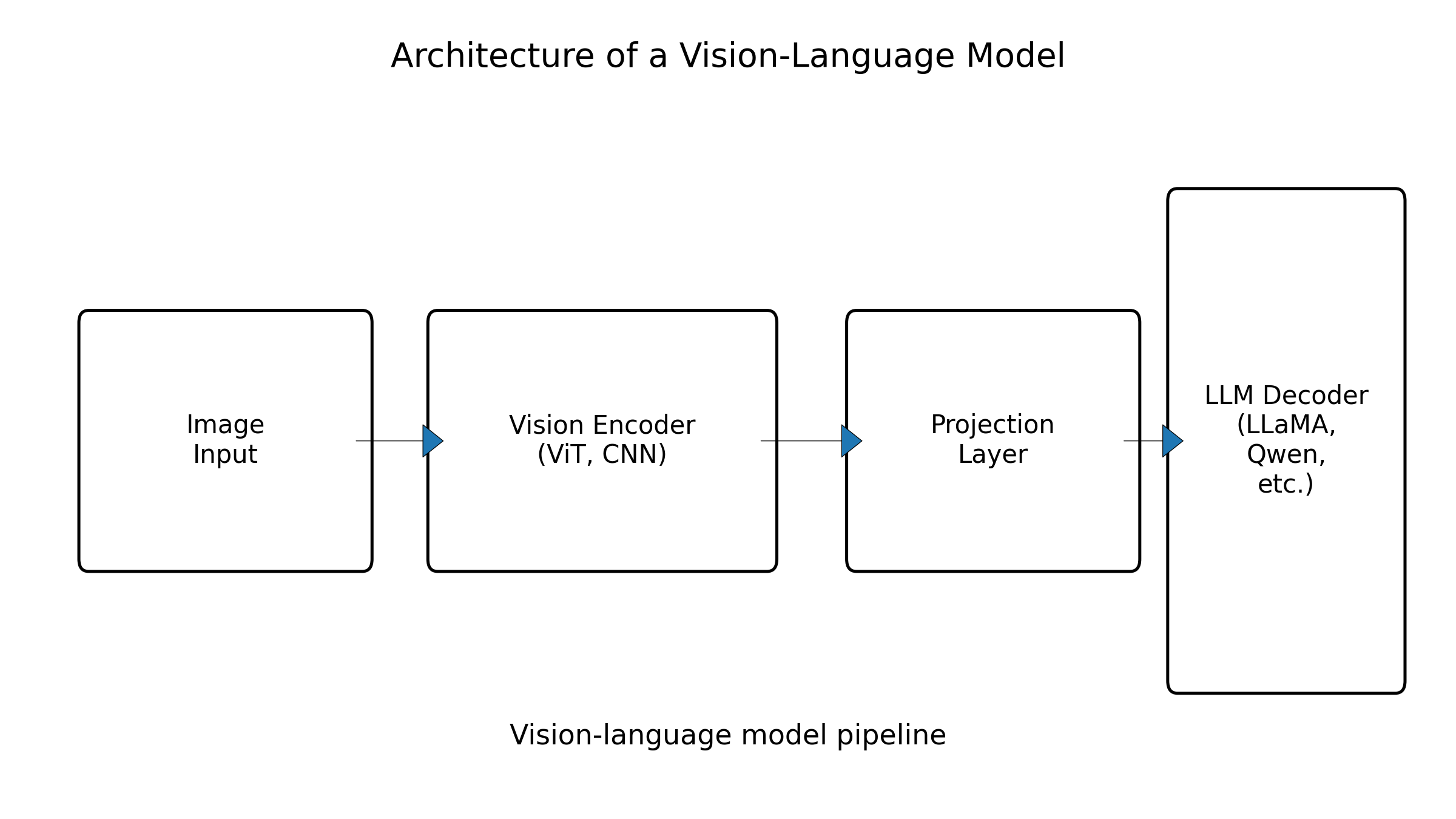
图2:典型 VLM 架构示意:视觉编码器 + 投影层 + LLM】、
为了更直观对比典型文本-图像模型,我们可以用一个表格来概括它们在表征与训练上的差异。
表1 典型文本-图像多模态模型概览
| 模型 | 机构 / 团队 | 核心表征方式 | 主要能力侧重 | 开源情况与时间 |
|---|---|---|---|---|
| CLIP | OpenAI | 图文对比学习共享嵌入空间 | 零样本分类、检索 | 权重部分开放,2021 |
| ALIGN | 噪声鲁棒的大规模图文对比学习 | web 规模弱标注图文理解 | 论文开放 | |
| BLIP-2 | Salesforce 等 | 冻结视觉 backbone + LLM Q-Former | 文本引导的图像理解与生成 | 开源,2023 |
| LLaVA 系列 | UW–MSR–Columbia 等 | ViT + LLaMA,视觉指令微调 | 图像对话、视觉推理 | 完全开源,2023 起(LLaVA) |
| Qwen2-VL 等 | 阿里、腾讯、字节等多方团队 | 多尺度视觉编码 + 中文 LLM | 更强多语言、多任务视觉理解 | 多数开源,2024–2025(ACL Anthology) |
可以看到,这一阶段的主线是:先通过对比学习构建统一嵌入空间,再通过指令微调让模型学会用自然语言表达视觉信息。统一表征在这里主要还停留在“文本+图像”两模态范围内,但已经为后续扩展到视频与 3D 打下了坚实基础。
3.2 视觉语言助手与多任务统一
LLaVA 之后,开源社区在“视觉语言助手”方向快速迭代,出现了 InternVL、IDEFICS、DeepSeek-VL、Qwen-VL 等大量模型,并在文档理解、代码图表、网页 UI 等垂直场景中衍生出 DocLLM、Chart-LLM、LayoutLLM 等专门模型。(ACL Anthology)
这些模型在表征层面的关键进展有三点。第一,统一视觉 token 设计:从最早直接用 ViT patch token,到加入高分辨率 token、自适应裁剪、动态关注等机制,使得统一表征既能覆盖全局,又能兼顾细节。第二,多任务联合训练:通过混合 VQA、caption、OCR、文档理解、网页解析等任务的数据,让同一个表征空间天然带有“任务感知”的属性。第三,更紧密的语言对齐:通过指令微调,使模型在统一表征之上学会遵循复杂指令、调用工具,对接真实应用。(NeurIPS Proceedings)
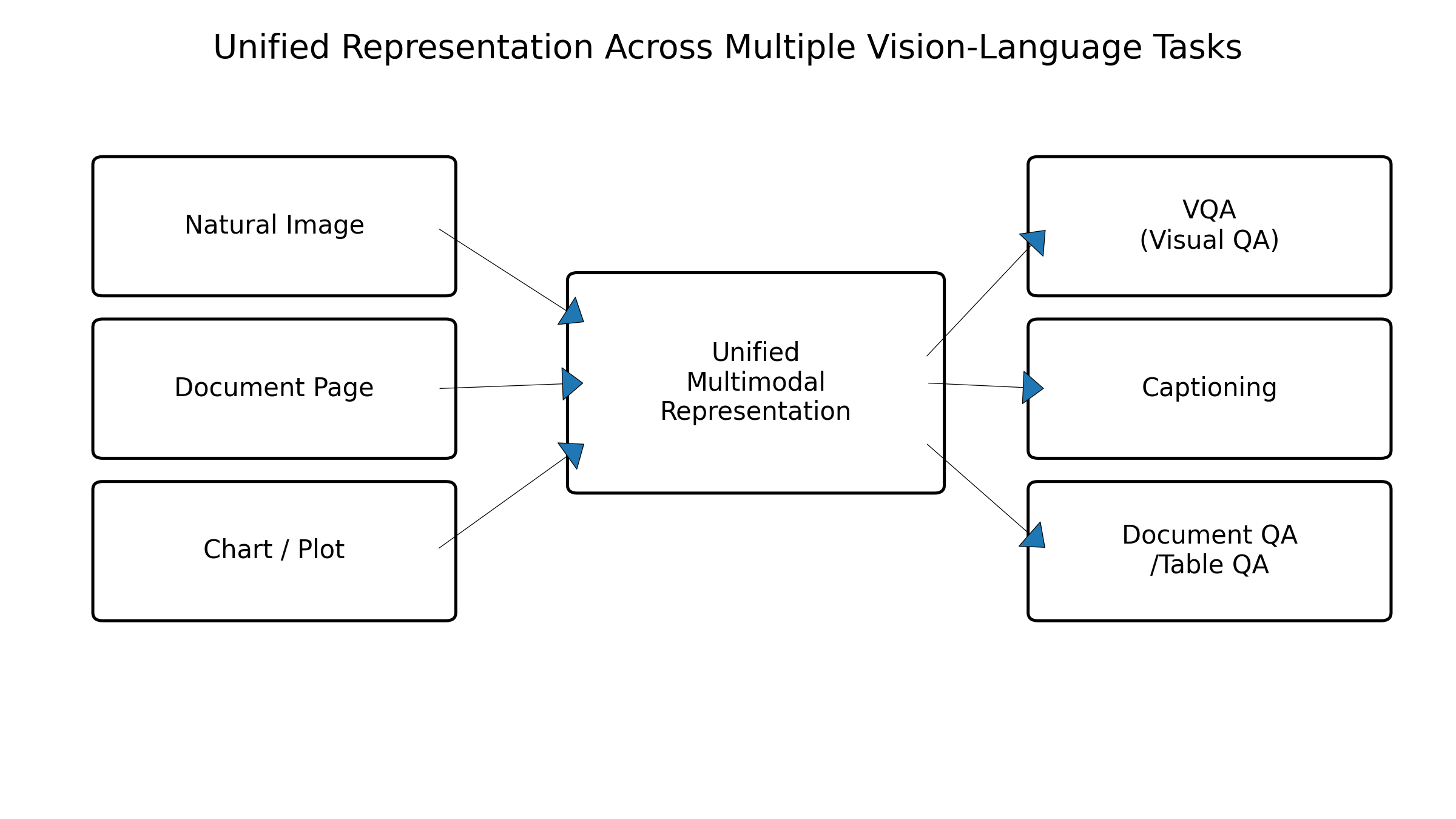
图3:文本-图像多模态在不同下游任务上的统一输入输出示意
3.3 文本丰富图像与结构化视觉
文本丰富图像(Text-rich Image,TRI),如票据、表格、报告、幻灯片等,是检验多模态统一表征能力的“试金石”。近年的系统性综述指出,TRI 场景下的多模态大模型,需要同时处理自然图像、排版结构与嵌入文本,并在统一表征空间中维护结构与语义的一致性,这对视觉 tokenizer 和跨模态融合提出了更高要求。(ACL Anthology)
在工程实践上,很多系统会在统一视觉表征之外,引入基于 layout 的结构编码,或者将 OCR 文本显式拼接回语言序列中,但整体趋势仍然是向“真正 end-to-end 的统一表征”演进,即尽可能少依赖外部 OCR 模块,而在视觉-语言联合空间中直接完成识别与理解。
4 跨模态多路联合:ImageBind 与统一嵌入空间
4.1 ImageBind:以图像为枢纽的六模态绑定
ImageBind 是目前最具影响力的“多模态统一嵌入”工作之一,它在 CLIP 的基础上,把文本-图像嵌入扩展到包括音频、深度、热成像和 IMU 在内的六种模态,并且只依赖“图像+X”的配对数据,而不需要任意两模态都显式配对。(arXiv)
ImageBind 的核心思想可以概括为“图像作桥”:只要每一种新模态都能和图像建立足够好的对齐,那么所有模态都可以通过图像这一共享中介被“绑定”到同一个向量空间中。这种设计,不仅简化了数据需求,也使得模型可以在推理阶段实现跨模态组合,比如用音频检索图像、用热成像检索文本、用 IMU 轨迹检索相关环境视频等。
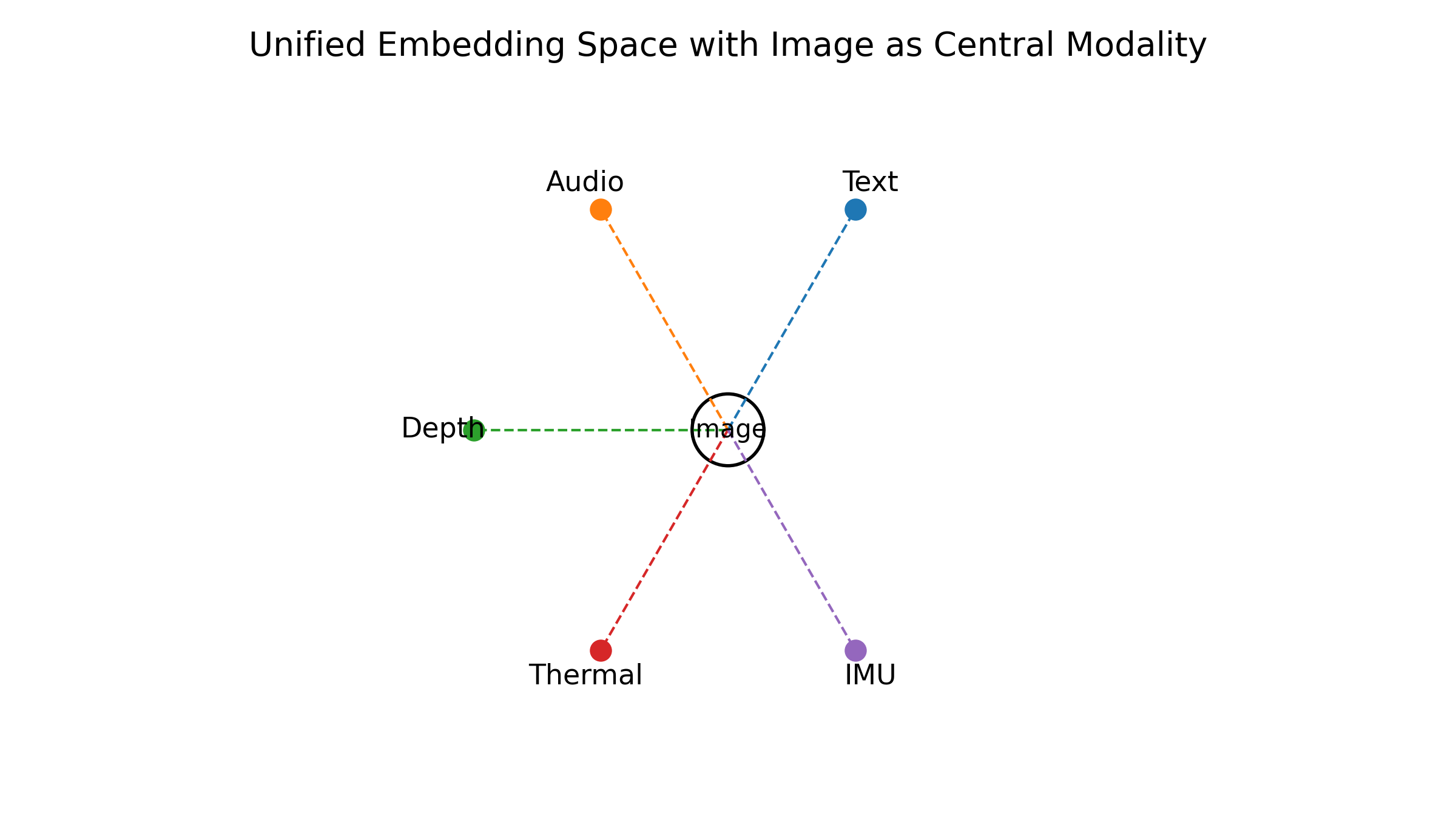
图4:ImageBind 六模态统一嵌入空间示意
4.2 统一嵌入在工业中的价值
从系统视角看,统一多模态嵌入空间带来的最直接价值,是一个“通用特征层”。在具有大量模态输入的复杂系统中(如智能监控、智能驾驶、AR/VR、机器人等),每个业务子模块都可以基于统一嵌入进行简单线性或小模型适配,而不必各自训练模态特定的深网络,大幅降低了工程复杂度。(OpenVINO 文档)
此外,统一嵌入天然适合检索增强生成(RAG)场景:当知识库中同时包含文本说明、产品图片、语音客服录音、说明视频甚至 CAD/3D 数据时,系统可以把所有信息统一映射到共享空间,在用户任意模态的查询下进行近邻检索,再将结果注入生成模型,从而打造真正多模态的 RAG 系统。
4.3 局限与后续工作
尽管 ImageBind 展示了统一嵌入的强大潜力,但它仍然强调“理解”而非“生成”,在图像/视频/音频/3D 生成能力上更多依赖外挂模型或后续工作。另外,随着模态数量增多,统一嵌入空间中不同模态的分布差异也更复杂,如何在保持跨模态对齐的同时,避免牺牲某些模态的表示能力,是近期很多工作关注的方向。(GitHub)
后续的统一多模态模型,如 Janus 系列、Show-o2 等,在架构上进一步把“统一嵌入”推进到“统一 Transformer + 多头解码”的阶段,试图在同一主干上同时承担理解和生成任务,并逐渐支持视频乃至 3D 内容。(CVF Open Access)
5 统一“理解+生成”的多模态模型:Any-to-Any 时代
5.1 统一自回归 Transformer:Janus、UGen、WeGen、Show-o2
近年来,一个非常清晰的趋势,是从“理解模型 + 生成模型拼接”的流水线,转向单一 Transformer 统一处理所有模态输入输出。Janus 便是这一趋势的代表之一,它通过解耦视觉编码路径(理解 vs 生成),同时又在统一的自回归 Transformer 上进行多模态 token 序列建模,从而在理解和生成之间取得较好平衡。(arXiv)
UGen 则提出“统一自回归多模态模型+渐进式词汇学习”,将文本和图像都转换成离散 token,由单一 Transformer 自回归生成。它通过逐步激活视觉 token 词表,让模型先学会文本,再逐渐引入图像,提高训练稳定性和统一表征质量。(arXiv)
WeGen 进一步面向“交互式多模态生成”,在统一框架下实现文本到图像/视频、多轮编辑等操作,把统一表征与交互式控制结合起来。(CVF Open Access) Show-o2 系列则在 3D Causal VAE 空间上统一学习文本、图像与视频,从而从表征层对 3D / 视频进行统一建模。(Hugging Face)
表2 代表性统一多模态“理解+生成”模型比较
| 模型 | 统一方式 | 支持模态 | 代表特性 | 核心技巧与贡献 |
|---|---|---|---|---|
| Janus / Pro | 统一自回归 Transformer + 解耦视觉编码 | 文本、图像(理解+生成) | 同一骨干兼顾 VQA 与高质量图像生成 | 解耦特征路径缓解理解/生成冲突(CVF Open Access) |
| UGen | 统一自回归 + 渐进式词汇学习 | 文本、图像 | 同时在文本、图像理解与生成上表现强 | 渐进激活视觉 token,提升稳定性(arXiv) |
| Emu2 | 统一序列建模 + 扩散解码 | 文本、图像、视频 | 生成式多模态 in-context 学习 | 将多模态视作统一序列,强调上下文学习(arXiv) |
| WeGen | 统一理解 + 交互式生成 | 文本、图像/视频 | 支持多轮交互、重绘、多模态编辑 | 将交互式 prompt 重写与生成过程结合(CVF Open Access) |
| Show-o2 | 文本 token + 3D Causal VAE 空间 | 文本、图像、视频、3D 表征 | 原生统一多模态(含视频/3D) | 基于 3D 潜空间统一理解与生成(Hugging Face) |
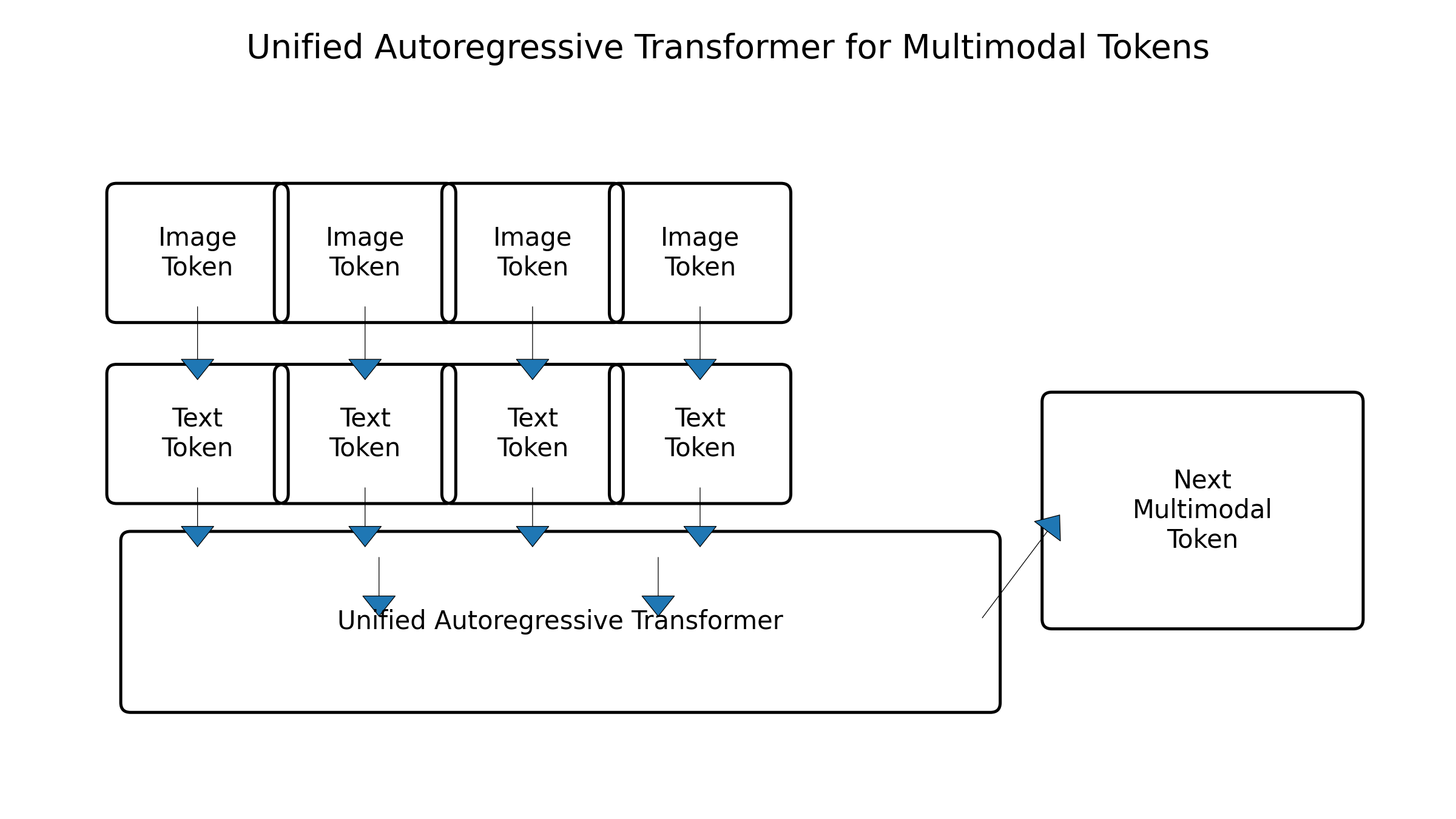
图5:统一自回归 Transformer 处理多模态 token 序列的示意
这些模型共同指向一个未来图景:无论是文本、图片、视频还是 3D 场景,都被视作同一种“离散 token 序列”,通过统一的 Transformer 进行生成与理解。表征上的统一,使得模型可以在任务间灵活迁移,例如:用视觉 in-context 示例来帮助文本任务,或者用语言描述引导视频生成。
5.2 Emu2:生成式多模态模型即 In-Context Learner
Emu2 的观点很有代表性:多模态生成模型不仅仅是“画图工具”,而是强大的 in-context learner。它通过统一自回归序列建模,让模型在同一上下文里看到文本描述、图像示例乃至视频片段,然后在下一个 token 处完成复杂的多模态推理与生成。实验表明,Emu2 在少样本学习、视觉 prompt、对象级生成等方面具有显著优势。(arXiv)
这种视角对“统一表征”的理解非常关键:统一表征不仅是为了方便拼接模态,更是为了在同一上下文中共享推理轨迹,让模型能够跨模态地利用示例、模式和偏好。这也为未来“多模态 Chain-of-Thought”、“视频/3D CoT”等研究打开了空间。
5.3 统一视频理解与生成
视频作为“图像+时间”的模态,其统一表征需要处理更长的序列、更复杂的运动模式与语义结构。最新的工作如 WeGen 和部分统一视频理解与生成框架,尝试在统一 Transformer 中同时建模文本-图像-视频的 token 序列,通过时空 token 的设计与分层建模,兼顾效率与效果。(CVF Open Access)
另一条路线是“视频优先”的统一框架,例如面向视频的统一模型把图像视作单帧视频,文本视作特殊 token,通过统一的视频 Transformer 同时完成时序理解与跨模态生成,从而形成真正意义上的“视频中心”统一表征。这类工作尚在快速演化,但其共同目标都是:让视频不再只是“挂在文本/图像之后的特殊分支”,而是统一表征的第一公民。
6 从图像到视频再到 3D:统一表征的时空扩展
6.1 视频多模态:长视频与细粒度语义
视频引入时间轴后,统一表征面临两个突出挑战。其一是长序列:一段几分钟的视频在逐帧编码后,token 数量会远超文本和图片,直接喂给 Transformer 会严重拖慢推理。其二是层次语义:视频中同时存在镜头级、场景级、动作级乃至物体轨迹级信息,需要在统一表征中以不同粒度表示。(arXiv)
当前的主流做法,是通过分层表征与稀疏采样减少 token 数量,同时在对比学习、掩码建模与指令微调中混合使用视频任务,如视频问答、时序定位、长视频摘要等,从而在统一空间中融入时间信息。与文本/图像的统一表征相比,视频统一表征更强调全局上下文,这也是长视频理解中多模态大模型的核心竞争力。
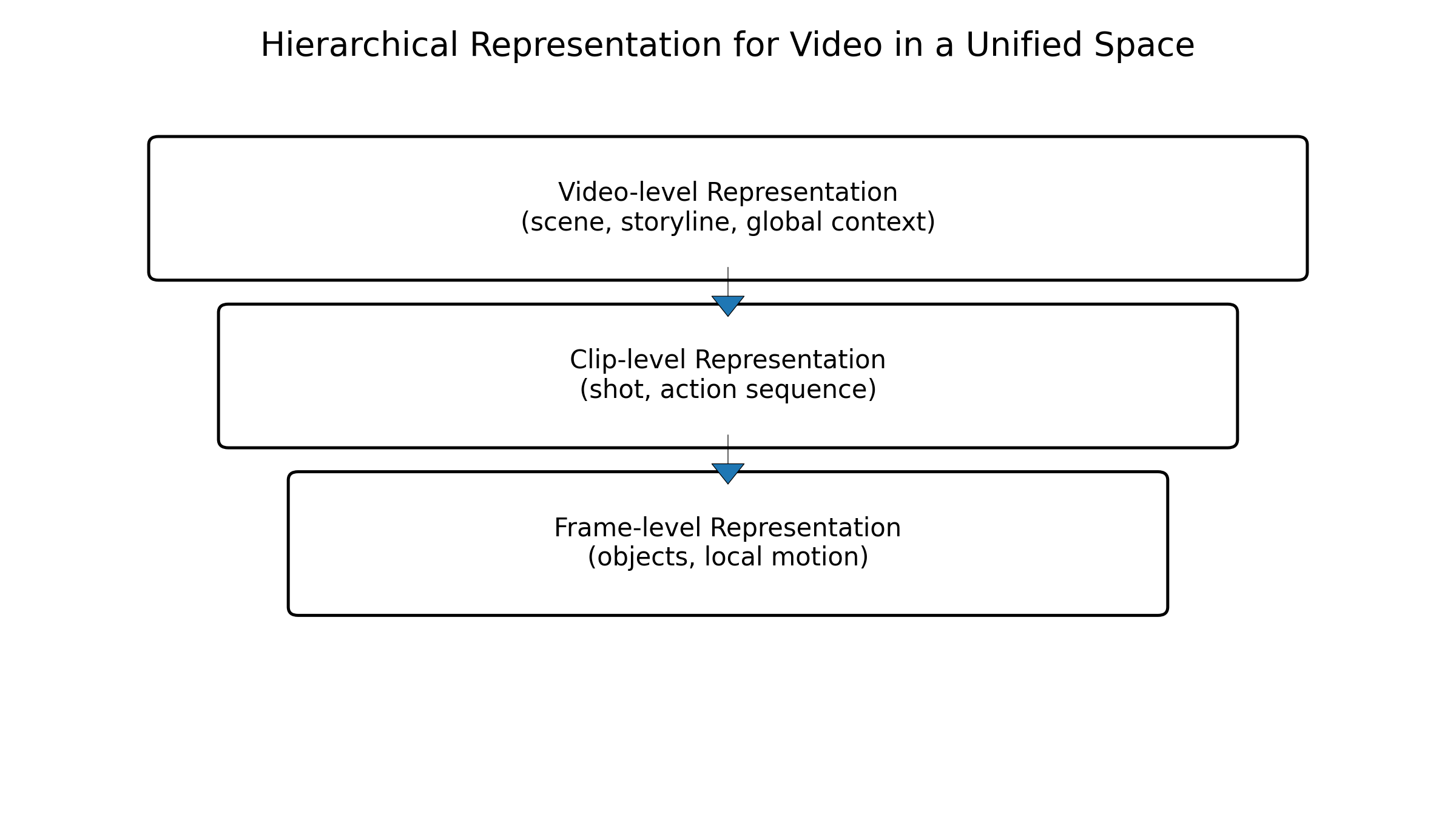
图6:视频多层级表征(帧级、片段级、全局级)的统一示意
6.2 3D 表征:NeRF、Gaussian Splatting 与 Token 化
3D 是统一表征向空间维度扩展的关键领域。近年来,基于 3D Gaussian Splatting 的方法迅速发展,成为高质量、可实时渲染的 3D 表征主流之一。在此基础上,越来越多工作尝试把 3D 表征离散化为“3D token”,以便与文本、图像、视频在统一 Transformer 中联合建模。(GitHub)
例如 Repaint123、Cycle3D、DreamGaussian 等工作,围绕“单图/文本到 3D”的任务设计两阶段框架:先通过 3D Gaussian 或 NeRF 进行几何与粗纹理建立,再通过二维扩散模型在 UV 空间进行纹理细化,以此在质量与速度之间取得平衡。(欧洲计算机视觉协会)
表3 代表性图像/文本到 3D 方法概览
| 方法 | 核心表征 | 任务类型 | 统一表征相关特性 | 发表与开源情况 |
|---|---|---|---|---|
| DreamGaussian | 3D Gaussian + 扩散 | 文本/图像到 3D | 以高斯为统一 3D 表征,可扩展为 3D token | ICLR 2024,代码开放(ICLR 会议录) |
| Repaint123 | 两阶段高斯 + 2D 重绘 | 单图到 3D | 利用 2D 扩散加强 3D 纹理,支持快速生成 | ECCV 2024,代码开放(欧洲计算机视觉协会) |
| Cycle3D | 生成-重建循环框架 | 单图到 3D | 通过循环一致性提升 3D 一致性,利于统一表征 | AAAI 2025(AAAI Journal) |
| 大规模 Point-to-Gaussian | 点云到高斯 | 图像到 3D | 用点云作为几何先验,便于统一进几何 token 空间 | 2024 ACM 论文(ACM Digital Library) |
| 高斯融入扩散去噪 | 高斯 + 扩散 | 文本/图像到 3D 加速 | 将 3D 表征融入扩散去噪,提高统一生成效率 | 2025 ICLR 工作(Department of Computer Science) |
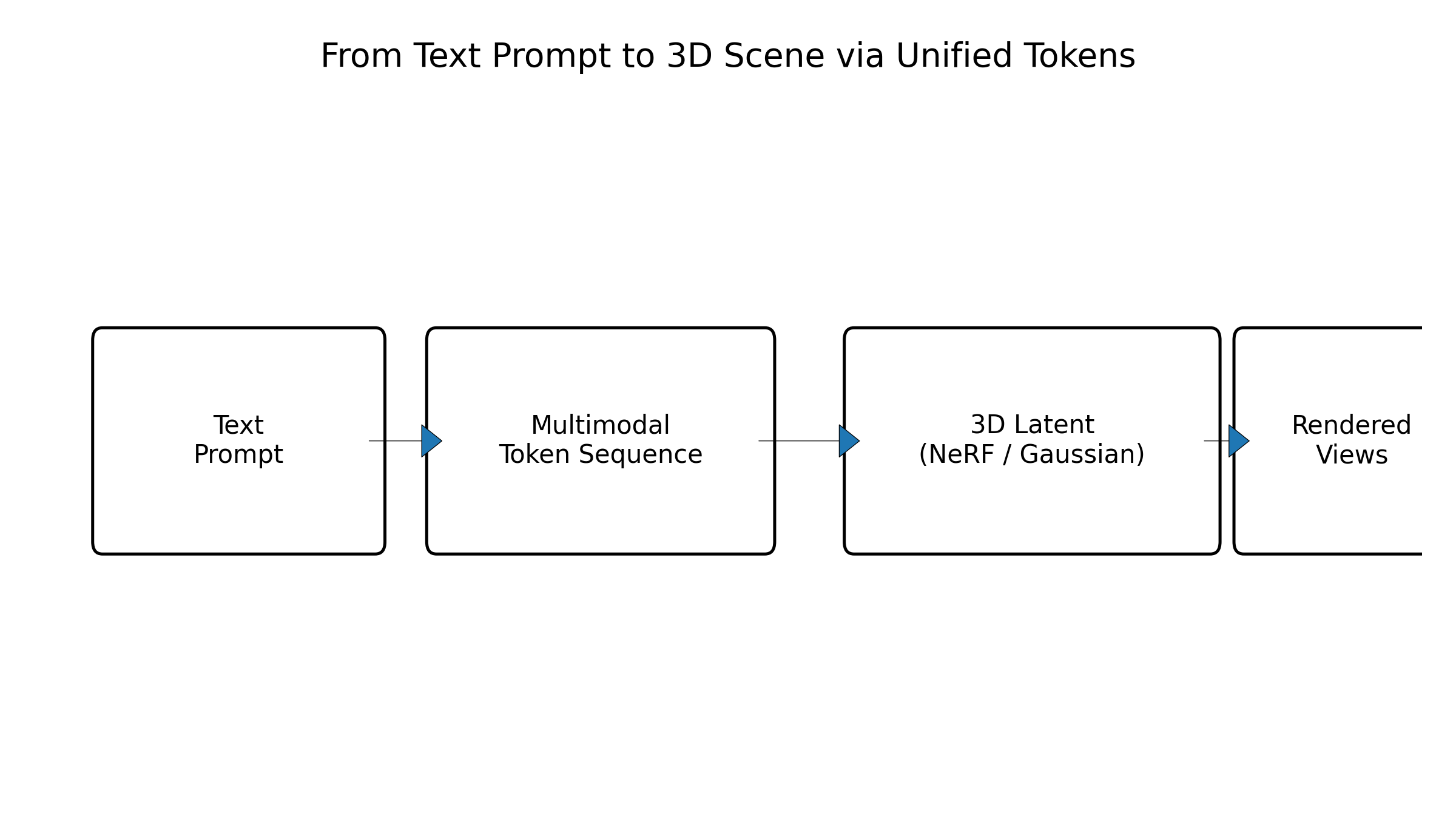
图7:从文本到 3D 场景的统一序列示意:文本 token → 视觉 token → 3D Gaussian token
这些工作虽然多是围绕 3D 本身展开,但为未来构建“文本-图像-视频-3D”统一表征提供了重要组件:一旦 3D 也被离散化为 token,并能在统一 Transformer 中按序列建模,那么多模态大模型就可以在同一空间中理解和生成三维世界。
6.3 单图到 3D 与文本到 3D 中的统一表示
单图到 3D 的场景尤其适合作为统一表征的测试台。模型需要从一张图片中推断 occlusion 后面的结构,并在统一表征中维护几何一致性,这对视觉 token 的设计和几何先验的引入提出高要求。增强型单图到 3D 方法通过将 3D 高斯、点云和 2D 扩散模型组合到一个统一 pipeline 中,逐步逼近真实三维场景,将“2D 观测”映射到“3D 表征空间”。(arXiv)
文本到 3D 则更像“文本到图像到 3D”的组合任务,在统一表征框架下,可以将文本-图像生成与图像-3D 生成串联在统一 token 空间中:先在视觉 token 空间中生成多个视角的图像 token,再通过 3D token 解码器构建场景。这种方式为未来的“语言驱动 3D 世界编辑”提供基础。
7 工程实现视角:数据、训练与系统架构
7.1 统一 token 空间与 tokenizer 设计
从工程角度看,统一表征最终要落到 tokenizer 和序列建模上。文本 tokenizer 相对成熟,而视觉/video/3D tokenizer 的设计则直接决定统一表征的质量与效率。当前主流做法包括:VQ-VAE/VQGAN 类型的离散 codebook、基于 patch 的视觉 token、3D Causal VAE 等。(Hugging Face)
UGen 的渐进式词汇学习是一个非常实用的工程技巧:先只对文本 token 进行训练,让模型快速收敛到一个良好的语言基线;然后逐步开启视觉 token,避免一开始就被庞大的视觉词表扰动,从而提高训练稳定性与最终性能。(arXiv)
Show-o2 基于 3D Causal VAE 的设计则说明:如果能够在 3D/视频空间中找到一个足够表达力的潜在离散空间,那么统一多模态理解与生成就可以在较小的 token 序列上完成,大幅减轻训练负担。(Hugging Face)
7.2 训练范式:阶段式 vs 端到端
绝大多数统一多模态模型采用“阶段式训练”:先训练视觉/3D 等感知 backbone,再与语言模型进行对齐,最后进行多任务联合或指令微调。这种方式工程上可控、资源需求可拆分,但从理论上看会留下“局部最优”的痕迹,即早期阶段的设计会强烈约束后续统一表征的上限。(arXiv)
随着算力与数据集的不断扩展,端到端统一训练正变得越来越可行。例如一些新一代统一 multimodal 模型,尝试直接用统一自回归目标在混合数据上训练,把“预训练+对齐+指令微调”折叠为一个长程训练过程,只在很后期进行少量任务特定微调。相比之下,这种方式更有利于形成真正“模态无关”的统一表征。(arXiv)
7.3 推理与服务:多模态 Agent 与工具调用
统一表征在推理端的最大价值,在于多模态 Agent 的系统设计。一个典型的多模态 Agent,往往需要同时处理文字问题、附带图片/截图、链接视频甚至 3D 场景。通过统一表征,Agent 可以在内部把这些内容转成统一的向量/序列,再结合工具调用、检索与规划模块进行复杂推理。(NeurIPS Proceedings)
在服务形态上,业界实践越来越倾向于“单大模型 + 多个轻量工具/适配器”的架构:统一多模态大模型承担核心理解与推理,周边的小模型负责 OCR、ASR、视频帧抽取、3D 渲染等特定任务,统一表征在中间充当 glue,把整个系统连成一个整体。这种架构在开源生态中尤为常见,很多项目通过一个主 MLLM 调用一系列 Python 工具与外部模型,构建起类似 GPT-4o 的通用多模态助手。(Towards AI)
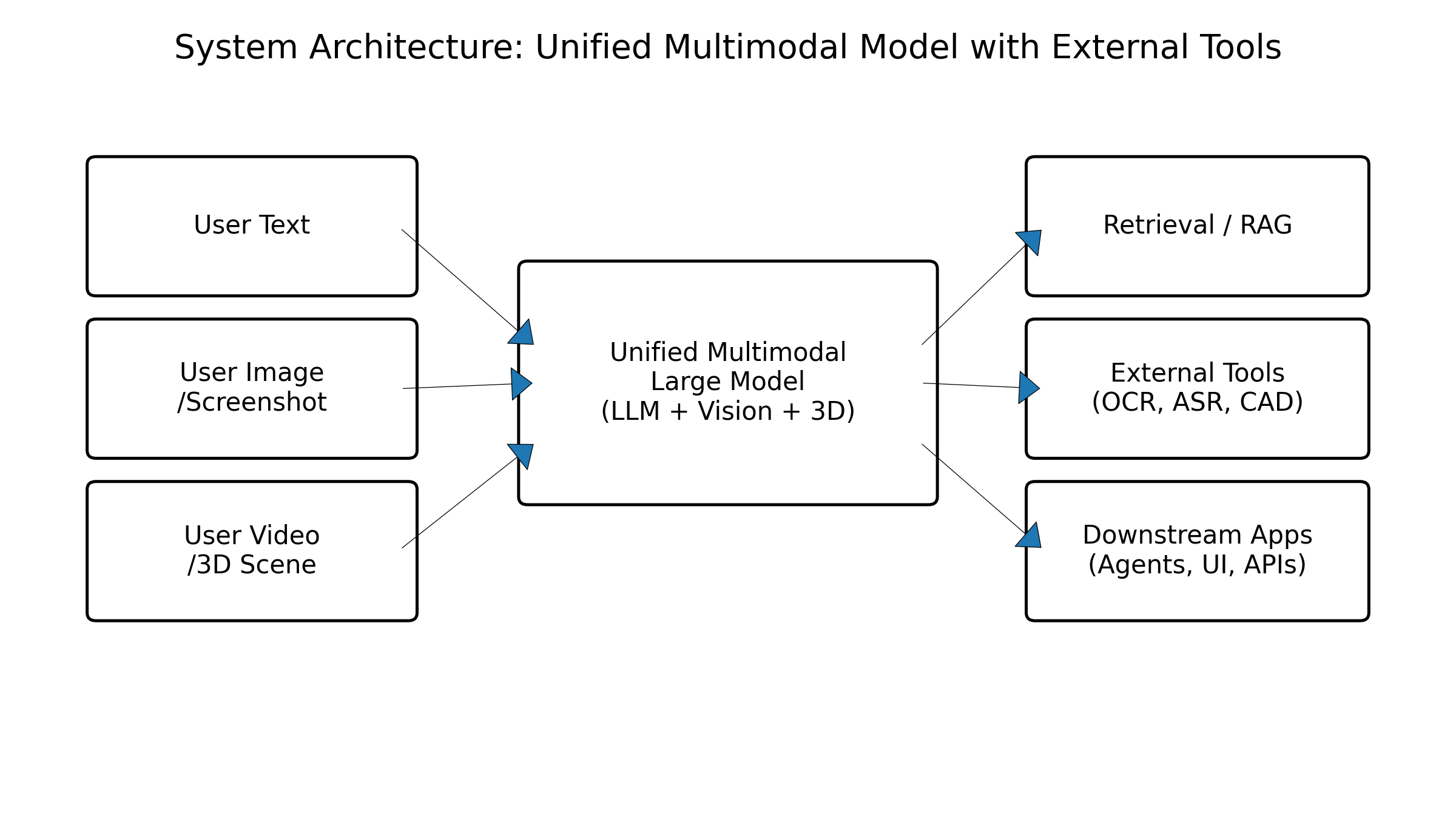
图8:统一多模态大模型 + 工具链的系统架构示意
8 面向文本-图像-视频-3D 统一表征的未来趋势
8.1 GPT-4o 与新一代统一多模态助手的启示
从 GPT-4V 到 GPT-4o,人们逐渐意识到:真正强大的多模态模型,并不是简单叠加一个视觉前端,而是从架构上把多模态视作第一等公民,将音视频输入输出与文本同等对待。公开资料表明,GPT-4o 已经是一个端到端统一的多模态模型,能够同时处理文本、图像、音频等,并以极低延迟完成推理。(Towards AI)
对开源社区而言,这一方向的启示在于:如果不在表征层真正“统一”,而只是做松散的模块拼接,很难在体验上追上 GPT-4o 这类产品级系统。因此,未来开源多模态模型更有可能围绕两个方向持续迭代:一是进一步统一模态(加入音频、视频、3D),二是在统一架构下显著优化延迟与吞吐。
8.2 开源生态:模型、评测与工具链
Github 上的 Awesome-Unified-Multimodal-Models 等资源,已经系统整理了统一多模态理解与生成的模型谱系,包括 Janus-Pro、UGen、OmniMamba、Show-o2 等,并随着 2025 年的新工作不断更新,逐渐形成一张清晰的技术地图。(GitHub)
另一方面,多模态评测也在快速发展。除了传统的 VQA、caption、检索等指标外,越来越多的 benchmark 开始关注“真实任务”,例如长文档多模态理解、图文代码推理、图表问题、视频多轮对话等,这些任务天然需要统一表征和统一推理能力。(NeurIPS Proceedings)
在工具链层面,多模态数据标注与合成工具、统一 tokenizer 框架、可扩展的训练与推理框架(如支持 interleaved 多模态数据的 data loader、统一的 evaluation suite)正在逐渐成熟,降低了研究者与工程师搭建统一多模态系统的门槛。
8.3 研究挑战与可能方向
展望未来,从文本-图像到视频-3D 的统一表征仍有若干关键挑战。第一,真正意义上的“全模态 Any-to-Any”:现有模型大多在少数模态上做到统一,未来的目标是构建能够在文本、图像、音频、视频、3D、动作等任意模态间互转的通用系统。第二,模态可控与安全:统一表征也意味着错误可能跨模态传播,例如文本中的 hallucination 通过图像/视频被放大,如何在统一表征空间上实现跨模态一致的安全约束,是一个开放问题。(Emergent Mind)
第三,效率与隐私:多模态数据往往敏感且体积庞大,统一表征带来强大的上下文表达力,但也意味着更高的运算与存储开销。如何在统一架构下实现模型压缩、边缘推理、隐私保护与联邦学习,将决定多模态大模型能否真正走向终端侧与行业纵深。(BOND)
9 结语
多模态大模型的发展历程,本质上是一条不断“统一表征”的路线:从最早的文本-图像对比学习,到视觉语言助手,再到跨音频、视频、3D 的统一嵌入和统一自回归模型,人类正在用一个又一个高维向量空间,把世界的多种感知形式折叠在一起。在这个过程中,ImageBind 让我们看到“图像作桥”的威力,LLaVA 等开源 VLM 将视觉对话带到大众面前,Emu2 等生成式多模态模型展示出强大的 in-context 学习能力,而 Janus、UGen、WeGen、Show-o2 等统一 Any-to-Any 模型,则把我们推向一个“真正多模态的通用智能体”时代。(CVF Open Access)
从文本-图像到视频-3D 的统一表征,不只是为了“多几个模态”,而是在重新塑造模型对世界的感知方式。未来,当一个模型能在统一表征空间中同时“看到”场景、理解文字、听到声音、感知三维结构,甚至预测与回放交互过程时,它所呈现的将不再只是“回答问题的聊天机器人”,而是一个真正意义上能够感知、记忆和行动的多模态智能体。
在工程实践中,如何结合业务场景选择合适的统一表征架构、如何在算力约束下落地多模态大模型、如何构建安全可靠的多模态 Agent,将是每一位开发者不可回避的现实问题。希望本文从系统性视角梳理的这些模型与思路,能够为你在设计和实现下一代多模态系统时,提供一个可参考的知识框架与技术地图。
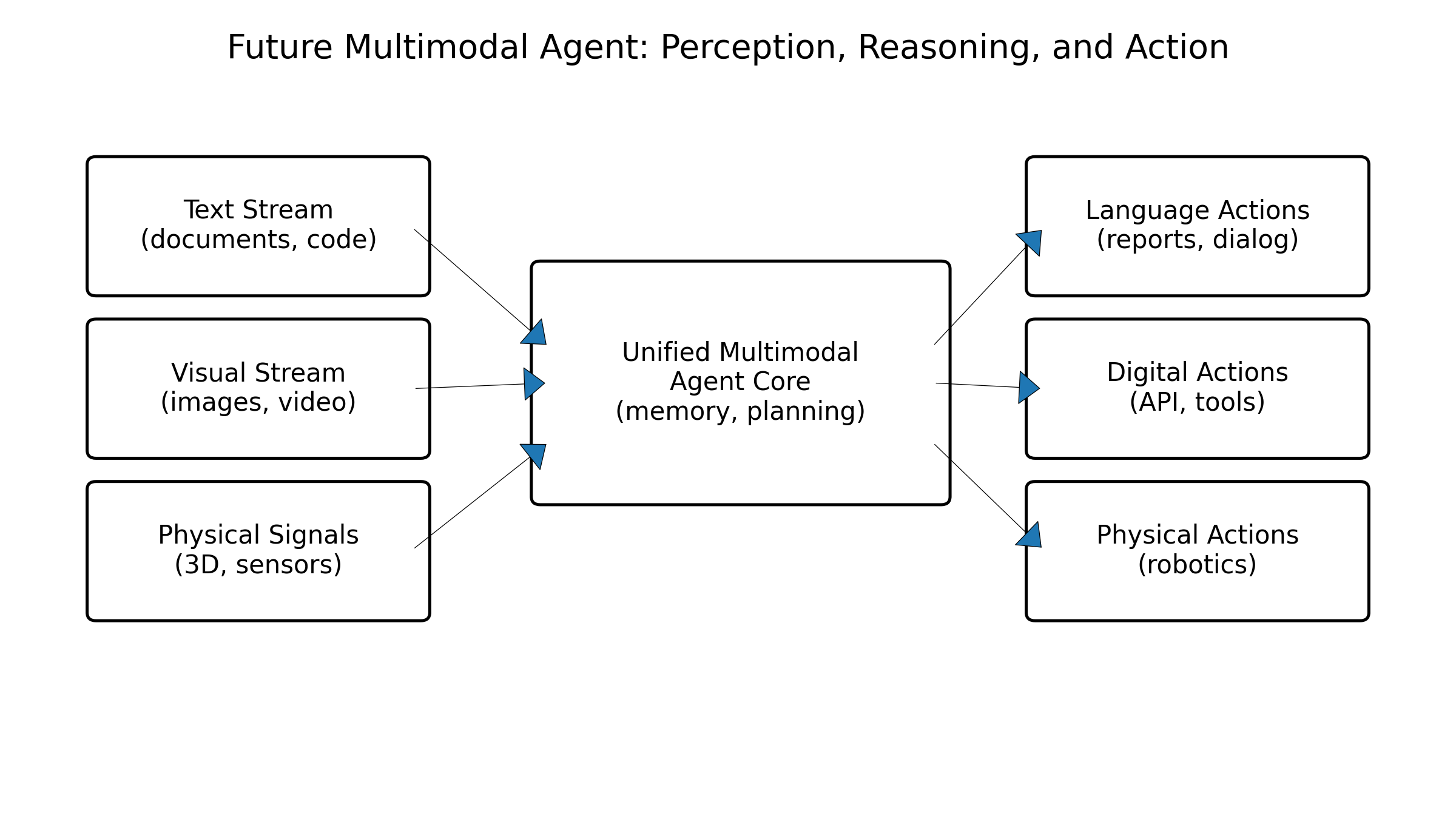
图9:面向未来的统一多模态智能体示意图:文本、图像、视频、3D、音频在统一表征空间中交织
参考资料(部分开源与综述资料)
[1] Rohit Girdhar et al. ImageBind: One Embedding Space To Bind Them All. CVPR 2023. (arXiv)
[2] Haotian Liu et al. Visual Instruction Tuning & LLaVA: Large Language and Vision Assistant. 2023. (LLaVA)
[3] X. Zhang et al. Unified Multimodal Understanding and Generation Models. 2025 survey. (arXiv)
[4] Q. Sun et al. Generative Multimodal Models are In-Context Learners (Emu2). 2023–2025. (arXiv)
[5] P. Tong et al. A Fully Open, Vision-Centric Exploration of Multimodal LLMs (Cambrian-1). NeurIPS 2024. (NeurIPS Proceedings)
[6] P. Fu et al. Multimodal Large Language Models for Text-Rich Image Understanding: A Survey. Findings of ACL 2025. (ACL Anthology)
[7] C. Wu et al. Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation. CVPR 2025. (arXiv)
[8] H. Tang et al. UGen: Unified Autoregressive Multimodal Model with Progressive Vocabulary Learning. arXiv 2025. (arXiv)
[9] Z. Huang et al. WeGen: A Unified Model for Interactive Multimodal Generation as We Prompt. CVPR 2025. (CVF Open Access)
[10] showlab. Show-o2: Improved Native Unified Multimodal Models. GitHub & arXiv 2025. (Hugging Face)
[11] Heshuting et al. Awesome-3DGS-Applications & MrNeRF's Awesome 3D Gaussian Splatting Paper List. GitHub 2024–2025. (GitHub)
[12] DreamGaussian: Generative Gaussian Splatting for Efficient 3D Generation. ICLR 2024. (ICLR 会议录)
[13] J. Zhang et al. Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting. ECCV 2024. (欧洲计算机视觉协会)
[14] Z. Tang et al. Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle. AAAI 2025. (AAAI Journal)
[15] Large Point-to-Gaussian Model for Image-to-3D Generation. ACM MM 2024. (ACM Digital Library)
[16] Y. Cai et al. Baking Gaussian Splatting into Diffusion Denoiser for Fast and High-quality 3D Generation. 2025. (Department of Computer Science)
[17] AIDC-AI & showlab. Awesome-Unified-Multimodal-Models. GitHub curated list. (GitHub)
[18] Rohan Mistry. Multimodal AI: The New Era of AI that Understands Text, Images, Audio, and More. 2025. (Towards AI)
[19] Aya Data. Multimodal AI: Breaking Down Barriers Between Text, Image, Audio, and Video. 2025. (Ayadata)
[20] Bond Capital. Trends – Artificial Intelligence (AI). 2025 report. (BOND)


















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











