 Seedream 2.0文生图技术报告详解
Seedream 2.0文生图技术报告详解





🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
论文链接:https://arxiv.org/pdf/2503.07703
开源代码:https://team.doubao.com/tech/seedream
导读
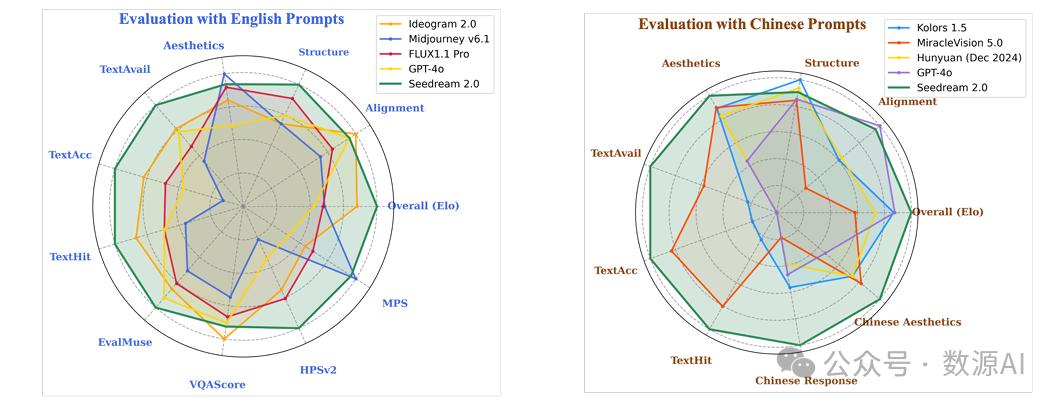
随着扩散模型的显著进步,图像生成领域经历了快速扩张。最近出现的强大模型,如 Flux、SD3.5 、表意文字 2.0(Ideogram 2.0)和 Midjourney 6.1 引发了广泛的商业应用浪潮。然而,尽管现有基础模型取得了显著进展,但它们仍面临一些挑战。
-
模型偏差:现有模型倾向于特定方面,例如 Midjourney 注重美学,却牺牲了其他方面的性能,如遵循提示或结构正确性。
-
文本渲染能力不足:在长内容或多语言(尤其是中文)中进行准确文本渲染的能力相当有限,而文本渲染是一些重要场景(如图形设计和海报设计等设计场景)的关键能力。
-
对中文特色理解不足:缺乏对当地文化(如中国文化)独特特征的深入理解,而这对当地设计师至关重要。
简介
为解决这些局限性,我们推出了Seedream 2.0,这是一款原生中英双语图像生成基础模型,在多个维度表现出色,能够熟练处理中文和英文文本提示,支持双语图像生成和文本渲染。我们开发了一个强大的数据系统以促进知识整合,以及一个兼顾图像描述准确性和丰富性的字幕系统。特别地,Seedream集成了自研的双语大语言模型(LLM)作为文本编码器,使其能够直接从海量数据中学习原生知识。这使得它能够生成具有准确文化内涵和美学表达的高保真图像,无论是用中文还是英文描述。此外,应用了字形对齐的ByT5进行灵活的字符级文本渲染,同时缩放旋转位置编码(Scaled ROPE)在未训练的分辨率上也有良好的泛化能力。多阶段的后训练优化,包括有监督微调(SFT)和基于人类反馈的强化学习(RLHF)迭代,进一步提升了整体性能。通过大量实验,我们证明了Seedream 2.0在多个方面达到了最先进的性能,包括遵循提示、美学效果、文本渲染和结构正确性。此外,Seedream 2.0经过多次RLHF迭代优化,其输出与人类偏好高度一致,这从其出色的ELO得分中可见一斑。此外,它可以轻松适配基于指令的图像编辑模型,如SeedEdit [28],具有强大的编辑能力,能够兼顾遵循指令和图像一致性。

数据预处理
本节详细介绍我们用于预训练的数据处理流程,包括数据构成、数据清洗和过滤、主动学习、添加字幕以及文本渲染数据等各种预处理步骤。这些过程确保最终的预训练数据集具有高质量、大规模和多样性。
1. 数据构成
我们的预训练数据精心选自四个主要部分,确保数据集平衡且全面,如图3所示。
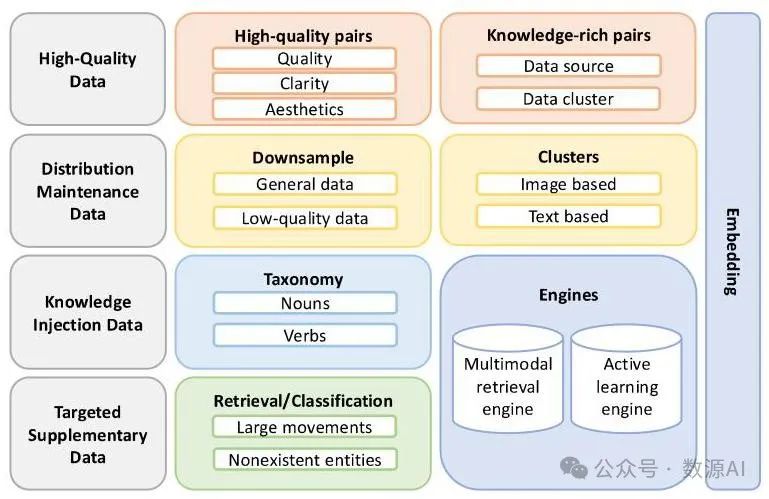
图3 预训练数据系统。
高质量数据。这部分数据包括图像质量极高且知识内容丰富的数据,评估依据为清晰度、美感和来源分布。
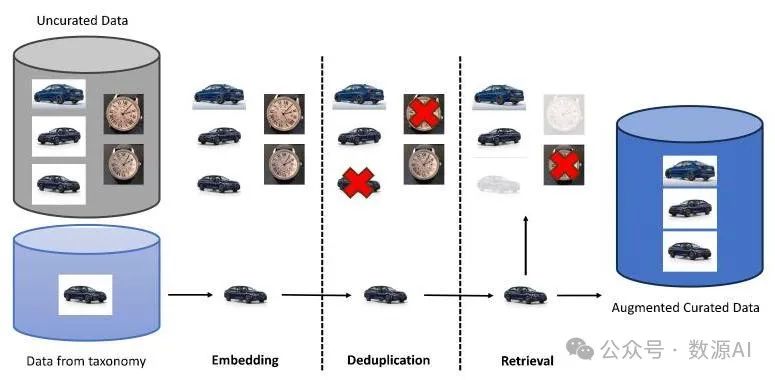
图4 我们的知识注入过程概述。
分布维护数据。这部分数据通过以下方式在减少低质量数据的同时保持原始数据的有用分布:
-
按数据源降采样:减少过度代表的数据源的比例,同时保留它们的相对大小关系。
-
基于聚类的采样:基于多个层次的聚类对数据进行采样,从代表更广泛语义(如视觉设计)的聚类到代表更精细语义的聚类,例如CD/书籍封面和海报。
知识注入数据。这部分使用已开发的分类法和多模态检索引擎进行知识注入,如图4所示。它包括具有独特中文语境的数据,以提高模型在特定中文场景下的性能。
此外,我们还手动收集了一小批具有独特中文语境的数据。该数据集包括与特定中文人物、动植物、美食、场景、建筑和民俗文化相关的图像 - 文本对。我们使用多模态检索引擎来扩充这些中文知识并将其融入我们的生成模型。
定向补充数据。我们用在文本到图像任务中表现欠佳的数据来补充数据集,例如面向动作的数据和反事实数据(如“脖子是气球的男人”)。我们的主动学习引擎对这些具有挑战性的数据点进行分类,并将其整合到最终的训练集中。
2. 数据清理流程
如图5所示,数据清理程序通过逐步精细的数据过滤方法来确保数据集的质量和相关性。
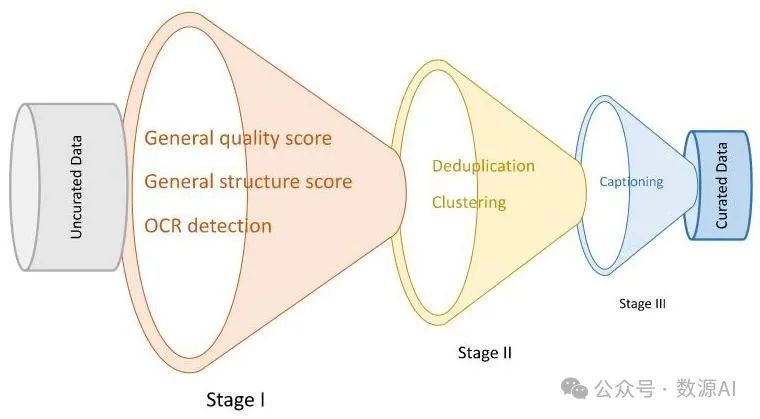
图5 我们的数据清理流程概述。
第一阶段:总体质量评估。我们使用以下标准对整个数据库进行标注:
-
总体质量得分:评估图像清晰度、运动模糊和无意义内容。
-
总体结构得分:评估水印、文本覆盖、贴纸和标志等元素。
-
光学字符识别(OCR)检测:识别并分类图像中的文本。
不符合质量标准的样本将被剔除。
第二阶段:详细质量评估。此阶段包括专业美学评分、特征嵌入提取、去重和聚类。聚类采用多层次结构,代表不同的语义类别。为每个数据点分配一个语义类别标签,以便后续调整分布。
第三阶段:添加说明和重新添加说明。我们对剩余数据进行分层,并添加说明或重新添加说明。较高级别的数据通常会获得更丰富的新说明,从不同角度进行描述。添加说明过程的详细信息见2.4节。
3. 主动学习引擎
如图6所示,我们开发了一个主动学习系统来改进我们的图像分类器。这是一个迭代过程,逐步优化我们的分类器,确保为训练提供高质量的数据集。
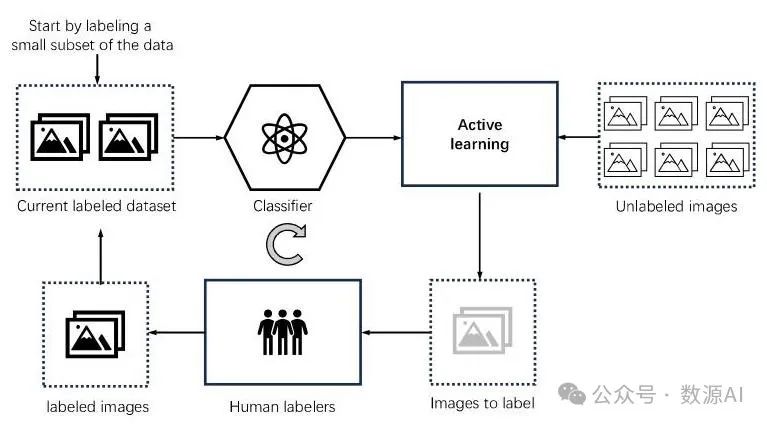
图6 主动学习生命周期流程图。
4. 图像说明添加
添加说明的过程为每张图像提供有意义且上下文准确的描述,生成通用说明和专业说明。
4.1. 通用说明文字
我们用中文和英文编写了简短和详细的说明文字,以确保描述准确且详尽:
-
简短说明文字:准确描述图像的主要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4866
4866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









