



🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
论文链接:https://arxiv.org/pdf/2503.19824
开源代码:https://guanjz20.github.io/projects/AudCast

导读
如今,音频驱动的虚拟人在各种场景中发挥着重要作用,可作为虚拟主持人、讲师和销售人员。特别是随着大语言模型的应用,虚拟人通过提供交互式视觉形象,在提升人机交互体验方面至关重要。尽管在音频驱动人体动画领域已经付出了巨大努力,但大多数先前的研究仅专注于控制嘴唇或躯干区域。虽然唇形同步方法旨在将嘴唇动作无缝融入视频,但它们无法修改身体动作,导致身体节奏与语音不一致。此外,仅展示会说话的头部无法满足大多数场景的需求。生成具有精确唇形同步和有节奏手势且与音频连贯的虚拟形象至关重要。
简介
尽管音频驱动视频生成技术最近取得了进展,但现有方法大多专注于驱动面部动作,导致头部和身体动态不协调。进一步而言,生成与给定音频精确唇形同步且具有细腻伴随语音手势的整体人体视频是理想的,但也具有挑战性。在这项工作中,我们提出了AudCast,这是一个采用级联扩散变压器(DiTs)范式的通用音频驱动人体视频生成框架,它基于参考图像和给定音频合成整体人体视频。1) 首先,我们提出了一种基于音频条件的整体人体DiT架构,以直接驱动任何人体的动作,并呈现出生动的手势动态。2) 然后,为了增强众所周知难以处理的手部和面部细节,区域细化DiT利用区域 拟合作为桥梁来重构信号,从而产生最终结果。大量实验表明,我们的框架能够生成具有时间连贯性以及精细面部和手部细节的高保真音频驱动整体人体视频。
方法与模型
这项工作旨在应对以逼真风格进行整体音频驱动的人体视频生成这一挑战。给定经过处理的音频特征 (作为驱动信号)以及提供外观信息的单张参考帧 ,我们的目标是生成生动的人体视频,其动作自然且与驱动音频相匹配,同时在视觉上与参考帧保持一致。这里, 和 表示相应的时间戳。
在这项工作中,我们利用预训练的 3D 因果变分自编码器(3D Causal VAE)[62] 进行视频压缩,其中编码器和解码器分别用 和 表示。给定目标视频片段 ,我们的方法对压缩后的视觉潜在特征 进行操作。在训练过程中,我们的模型经过优化,从通过预定义扩散过程 [24] 产生的加噪潜在特征 中恢复视频潜在特征 。然后对恢复后的潜在特征进行解码,以在像素空间中重建视频 。
1. 整体人体扩散变压器(Holistic Human DiT)
所提出的整体人体扩散变压器(Holistic Human DiT DiT)的概述如图 2 所示。我们首先分两个阶段对我们的方法进行总体解释:特征编码和视频生成。在特征编码阶段,我们集成了几个专门的模块,以有效地对输入特征进行编码,并纳入补充信息,以确保生成帧之间的一致性。在视频生成阶段,我们使用堆叠的变压器(Transformer)层构建模型,这些层处理经过分词的特征并迭代执行去噪步骤。
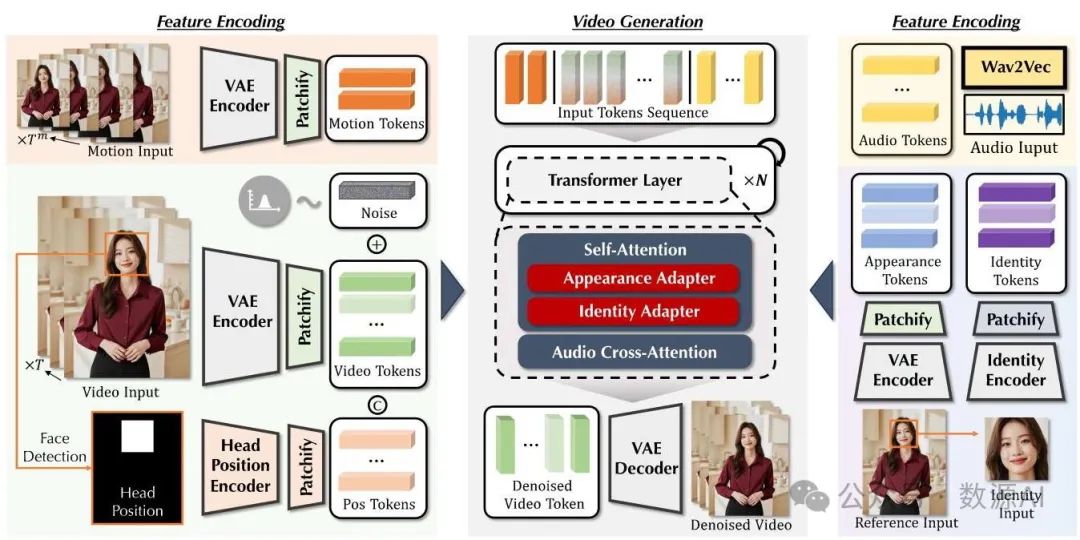
图 2. 整体人体扩散变压器(Holistic Human DiT)。我们在图中从特征编码和视频生成两个阶段展示了该模型。在第一阶段,我们采用几个模块提取丰富的特征并将其分词为顺序输入。在生成过程中,我们基于扩散变压器(DiT)的模型处理这些输入并执行迭代去噪以获得最终视频。
从视频潜在特征 开始,我们首先将特征划分为多个块。然后对这些块进行线性嵌入,以形成视频令牌序列 ,其中 表示序列长度, 表示变压器层中的嵌入维度。随后,添加随机采样的噪声以生成加噪视频令牌序列 。
头部位置引导。仅以音频为条件驱动人体手势存在一个众所周知的具有挑战性的多对多映射问题 [11, 75],即使是在简化的稀疏参数化 3D 表示中也是如此。而在视频生成的背景下,由于高度的自由度和增加的复杂性,这一挑战进一步加剧。考虑到在人体视频中头部运动通常较小这一特定任务因素,我们提议引入一个头部位置编码器,它由几个下采样 3D 卷积层组成,以提供弱控制,因为类似的设计已被证明在说话头部生成 [47] 和定制图像生成 [54, 68] 中是有效的。具体来说,我们首先检测面部区域,并创建一个掩码 ,该掩码覆盖所有帧中的头部运动。接下来,通过头部位置编码器处理该掩码,然后通过一个块嵌入层将特征分割成块 。然后,通过通道拼接和一个多层感知机(MLP)层(表示为 )将该控制信息与视频令牌进行整合,从而创建一个统一的视频令牌序列。
运动条件。我们的目标是生成能够在整个驾驶音频时长内无缝延续的扩展视频序列。然而,大多数基于DiT(扩散变压器,Diffusion Transformer)的视频生成框架在这方面受到限制,原因是GPU内存的约束,这限制了它们直接支持长时间视频生成的能力。受会说话的头部生成 的启发,即结合来自前一帧的额外视觉线索可以增强时间连贯性,我们采用了类似的方法来衔接两个独立的推理过程。具体来说,我们使用与视频输入相同的变分自编码器(VAE)和线性块嵌入,将视频输入的前 帧 编码为一种表示,作为运动令牌 。然后,这些嵌入的运动令牌会沿着时间维度与视频令牌连接起来,用于去噪处理。这样,模型就学会了以运动令牌为初始点来预测一致的外观和动作。
请注意,在推理的初始前向传播过程中,前一帧是不可用的。我们通过在训练期间对 应用0.5的丢弃率来解决这个问题。这鼓励模型在没有前一帧的情况下有效地进行泛化,增强推理的鲁棒性。此外,应用相对较高的丢弃率可以有效解决信息泄露的问题。由于外观信息也保存在运动令牌中,过度依赖前一帧的细节会在长视频生成过程中导致显著的误差累积。我们通过实验发现,0.5的丢弃率可以大大缓解这个问题,促进从参考帧进行更稳定的外观恢复,这将在后面详细介绍。
音频嵌入。遵循多模态动画领域的一系列研究 [19, 57, 58],预训练的wav2vec [2] 模型应该是音频特征编码的一个可靠选择。我们也采用了这个模型,并将音频嵌入的最后12层投影到顺序音频令牌中,记为 。这些令牌随后会与有噪声的视频令牌连接起来,提供节奏信息,引导去噪过程生成整体的人体动作。
Transformer层。我们按照MM - DiT [16] 的方式构建了一个单一的Transformer层,但用我们的音频令牌替换了文本令牌。剩下的一个问题是如何在参考输入的外观基础上有效地进行去噪。受用于概念注入的适配器 [63] 的启发,我们在MM - DiT块的自注意力层中引入了两个类似的模块,即外观适配器和身份适配器。因此,将修改后的自注意力表示为:
其中 和 分别表示外观令牌和身份令牌。具体来说, 来自参考输入,在经过视频令牌的编码过程后被编码并分割成块。同时, 是通过对预训练的Arc - Face [14] 提取的特征进行分块得到的; 是为 和 获取键(Key)和值(Value)而引入的四个矩阵, 表示从先前应用的头部掩码 导出的顺序掩码。它使注意力能够专门聚焦于面部区域,从而使其能够有效地关注 所提供的与身份相关的特征。
此外,音频作为唯一的驱动信号有两个目的:1)引导人体手势;2)控制面部表情,特别是嘴唇动作。虽然自注意力层有效地处理了第一个方面,但面部表情与音频的对齐至关重要,因为嘴唇的动态需要与语音的时间精确匹配。为了增强这种对齐,我们通过引入一个额外的音频交叉注意力层来明确建立这种对应关系。这可以从以下公式中学习得到:
其中 表示在DiT前向传播过程中处理的令牌化特征, 指定了头部区域的交叉注意力。
2. 区域细化DiT
生成人脸和手部的精细细节是出了名的具有挑战性,在我们的任务中涉及跨模态生成时,这就成了一个更为关键的问题。为了增强我们音频驱动结果中的细节,我们训练了一个级联区域细化扩散变压器(Regional Refinement DiT, -DiT)。这受到了近期研究的启发,该研究表明结构先验可以提高生成质量。
如图3所示,我们首先使用成熟的方法估计人脸和手部的三维表示。然后,这些三维先验信息通过一个网格编码器(Mesh Encoder)进行编码和标记化处理,该编码器与之前介绍的头部位置编码器具有相同的架构。接下来,我们将标记化后的特征(网格标记)与从 -DiT生成的视频中提取的表示(标记)进行拼接,并选择性地对人脸和手部对应的区域进行掩码处理,以进行图像修复。这种设计使模型能够利用上下文信息细化和完善这些区域。随后,我们将这些标记化特征与噪声标记进行拼接,这些噪声标记是按照与 -DiT相同的扩散过程生成的。拼接后的标记再由一个类似于 -DiT的基于Transformer的架构进行处理,以合成最终的视频输出。值得注意的是,由于人体运动已经由 -DiT合成,因此在 -DiT中不再需要音频信号。因此,模型中移除了音频标记和音频交叉注意力层。
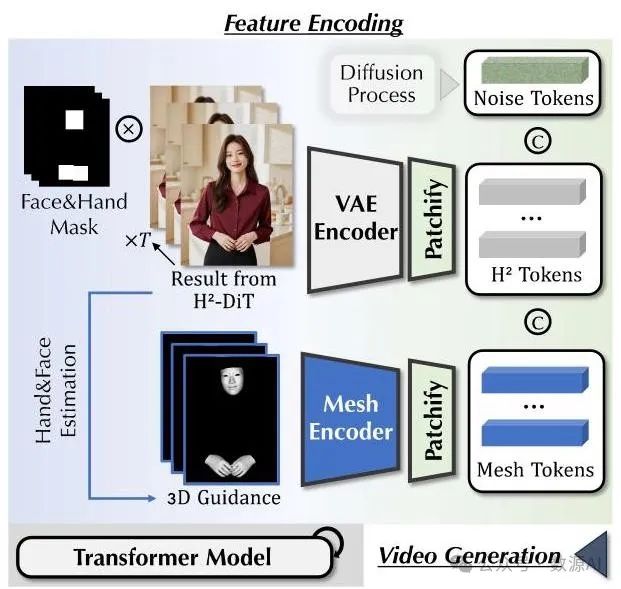
图3. 区域细化扩散变压器(Regional Refinement DiT)。利用三维结构先验信息,以条件图像修复的方式细化人脸和手部的细节。
实验与结果
在本节中,我们首先概述实验设置,包括实现细节和用于比较的基线。接下来,我们全面展示定量和定性结果,以展示我们方法的性能。最后,我们进行消融研究,以评估我们设计中的每个组件。
实现细节。我们的模型基于通用视频生成的成功经验构建,包含30个堆叠的类似MM - DiT的Transformer层。我们使用来自CogVideoX - 2B [62]的预训练权重初始化模型的部分参数。我们的模型在精心策划的约300小时视频数据集上进行训练,这些视频专门收集,以画面中央有说话的人为特征。训练过程在8个A100 GPU上进行,大约持续14天,学习率为。我们在零样本协议下评估我们的方法,这意味着测试输入(包括驱动音频和参考帧)在训练期间完全未见过,并且训练数据和测试数据中的主体没有重叠。测试集包括各种不同的视频片段和帧 - 音频对:我们收集的视频中来自10个主体的50个片段,来自PATs [1]的4个主体的20个片段,以及从Vlogger [13]主页收集的10个帧 - 音频对(Vlogger演示集)。每个视频或音频片段持续秒。
比较方法。在现有研究中,广义的音频驱动人体视频生成很少被探索,因此我们主要结合两个方面的方法作为基线。对于音频驱动的人体手势生成,我们采用了包括TALKSHOW [64]和ProbTalk [36]在内的方法,这些方法基于音频输入合成人体手势。然后将生成的输出从3D参数格式转换为人体骨骼,与姿态驱动的人体视频重演方法中使用的驱动表示方式保持一致。在第二个方面,我们纳入了两个开源模型:ControlNext [41]和MimicMotion [69]。这两个模型都在大量的人体视频上进行了训练,能够实现零样本重演。基于这些模型,我们有四个组合基线,可用于我们进行广义的音频驱动人体视频生成比较。我们分别将它们表示为Prob - CNxt、Prob - Mimic、Talk - CNxt、Talk - Mimic。在我们的实验中还展示了与Vlogger [13]的比较。为了进行公平比较,我们从其主页下载了带有参考图像和驱动音频的结果。
我们还包括与一种共语音生成方法 [21]的比较,该方法针对捕捉特定主体的运动模式进行了优化。我们使用其模型的官方实现,对主体Oliver [1]进行了评估。需要注意的是,在整个比较过程中,我们的方法始终处于零样本设置,没有针对该主体进行专门调整。
1. 定量比较
我们从四个方面评估生成的人体手势视频:1) 视觉质量,2) 时间连贯性,3) 动画质量,4) 身份保真度。对于视觉质量,我们使用SSIM [56]、LPIPS [67]和FID [23]评估静态帧,这些指标分别捕捉图像质量的结构、感知和分布方面。对于时间连贯性,我们遵循[55]中的方法,报告FID - VID [4]和FVD [49]。为了评估动画质量,我们使用OpenPose [9]测量身体和手部区域的地标检测置信度,分别表示为Body - C和Hand - C。此外,我们报告手部地标的方差以反映手部动作的表现力和多样性(表示为Hand - V)。遵循[21],我们还报告反映音频 - 手势连贯性的节拍对齐分数(BAS)。最后,通过使用人脸识别模型计算参考帧中的面部与每个生成帧之间的余弦相似度(CosSim)来评估身份保真度。
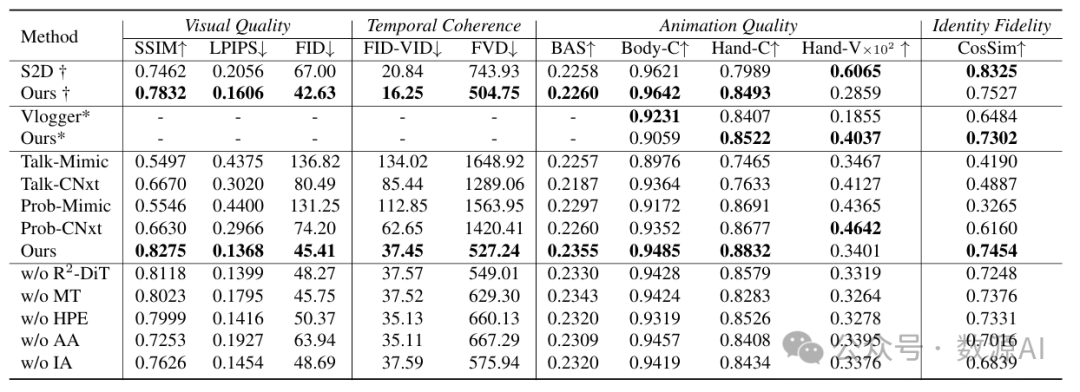
实验结果列于表1。与共语音生成方法S2D相比,我们的方法在视频质量方面表现出明显更好的结果。S2D通过针对特定人物的训练在手部动态和身份保留方面取得了更好的性能。对主体Oliver [1]的高度动态风格进行优化导致手部多样性相对较大。相比之下,我们的方法提供了更稳定的输出,在音频和手势之间实现了更好的协调,更高的BAS分数证明了这一点。Vlogger演示集上的结果进一步验证了我们方法的优越性能。在动画质量方面,两种方法都展示了逼真的身体,并且我们的方法在手部动作的多样性方面超过了Vlogger。在我们收集的视频和PATs视频的混合测试集上比较四个组合基线时,我们的生成框架取得了明显更优的结果。虽然音频驱动的手势生成方法提供了更多样化的手部手势,但其生成缺乏对参考帧的理解,导致动作感觉脱节或不协调。此外,当这些方法与姿态驱动方法级联时,两个阶段的误差累积会加剧,导致整体性能下降。
2. 定性结果
鉴于我们的任务涉及视频序列中的多模态生成,仅对静态帧进行评估无法提供全面的评估。我们强烈建议读者观看我们的补充视频,它能让您更清晰、更直观地了解生成结果,特别是考虑到音频线索和运动动态之间的协调性。

图4. 定性比较。用作参考的帧用红色框标记,而基于音频和相应参考帧的视觉外观生成的帧用黄色圆圈中的数字标记。此上下文中的比较应关注包括图像质量、姿态的真实感以及相对于参考帧的外观一致性等因素。
在这里,我们首先在图4中展示几个与我们的基线模型对比的样本。在标有①的第一组图中,我们比较了四种组合基线模型的结果。一个关键区别在于,我们的方法与提供的参考帧在外观一致性方面表现得更为出色。在第一阶段的基线模型中,TALKSHOW(脱口秀)比ProbTalk(概率谈话)生成的手势范围更广,而ProbTalk往往能产生更稳定的身体动作。这两种方法都能生成看似合理的人体手势;然而,当渲染到像素空间时,它们会出现明显的身份信息丢失和视觉伪影,导致在保真度和清晰度方面的结果明显不如我们的方法。在标有②的第二组图中,我们与一种协同语音生成方法进行了比较。尽管他们的方法是专门针对该主题进行训练的,但我们的方法在生成丰富手势方面表现出了相当的性能。此外,我们的方法在视觉质量上明显更优,尤其在捕捉面部和手部的精细细节方面。在图的右侧,我们展示了使用Vlogger演示集生成的结果。与组合基线模型相比,我们的方法和Vlogger都取得了明显更好的结果。然而,与Vlogger直接比较时,我们的方法在身份信息保留方面始终表现更优。以参考帧为基准,可以明显看出我们的方法生成的人体手势比Vlogger生成的更丰富、更具表现力。
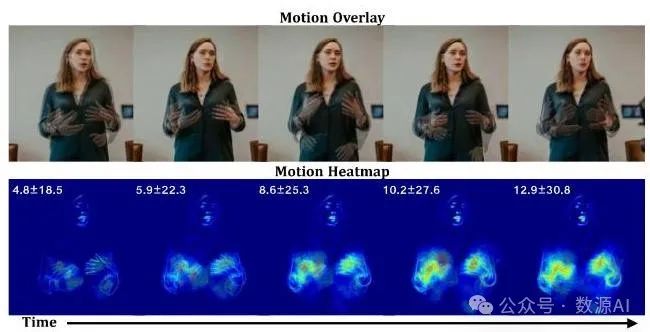
图5。顶行展示了三个生成视频的叠加视图。底行展示了累积运动叠加图,说明了整体的运动模式。左上角的值表示运动的缩放均值和标准差,为生成运动的可变性提供了定量分析。
动画多样性。我们的方法建立了从音频信号到人体动作的多对多映射。在图5中,我们直观地展示了所实现的运动多样性。我们将由同一参考 - 音频对生成的三个视频进行叠加,并呈现一个累积运动热图,其缩放范围在内。左上角显示了均值和标准差的值以供参考。静态背景表明我们的模型准确地识别了音频到动作映射的相关区域。不同样本中手部手势的变化进一步验证了我们方法的多样性。
3. 消融研究
我们将我们的方法与我们模型的几个修改版本进行评估,具体如下:1) “无 - DiT(w/o - DiT)”:此变体仅保留提出的 - DiT,而不利用先验进行细节精炼。它也作为与所有后续变体进行比较的基线。2) “无运动令牌(w/o MT,w/o Motion Token)”:我们从输入序列中排除运动令牌,仅将噪声视频令牌和音频令牌作为输入。3) “无头位置编码器(w/o HPE,w/o Head Position Encoder)”:在此,移除了头位置编码器。4) “无外观适配器(w/o AA,w/o Appearance Adapter)”:移除了Transformer层内的外观适配器,使模型仅能通过先前帧访问外观信息。5) “无身份适配器(w/o IA,w/o Identity Adapter)”:此版本移除了身份适配器。
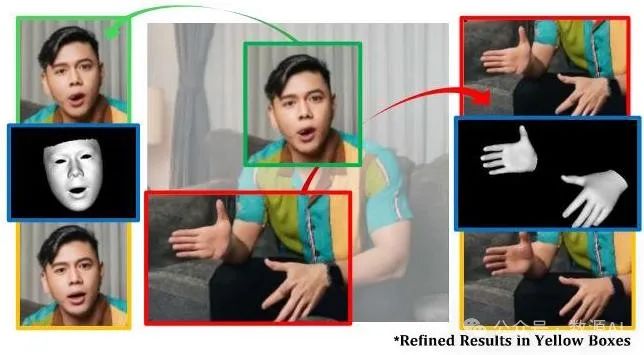
图6。融入结构化3D先验信息有助于捕捉精细细节,从而提高视觉质量。
从表1的结果来看,当弃用 - DiT时,手部置信度的下降最为明显。如果没有3D结构先验信息,生成的结果在面部和手部细节上会出现明显的伪影,如图6中的定性比较所示。移除运动令牌不会影响单次前向传播;然而,它会显著阻碍模型生成较长视频序列的能力。排除头位置编码器会导致视频输出稳定性降低,从而降低身体区域的检测置信度。此外,集成到我们Transformer层中的两个适配器对于准确恢复参考帧中的细节至关重要。没有这些适配器,我们会观察到整体视觉质量显著下降,身份信息保留能力大幅降低。
结论
在本文中,我们提出了一个新颖的框架AudCast,旨在解决音频驱动的人体视频生成这一具有挑战性的任务。我们的方法在生成高质量人体视频方面表现出色,这些视频具有同步的唇部动作以及与音频输入相匹配的自然、有节奏的身体动作。与现有方法的广泛比较证明了我们的级联DiT架构的有效性,为未来在更复杂场景下的条件人体视频生成研究提供了有价值的见解并奠定了基础。

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









