




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:YOLOE:Real-Time Seeing Anything
论文链接:https://arxiv.org/pdf/2503.07465
开源代码:https://github.com/THU-MIG/yoloe
导读
目标检测和分割是计算机视觉中的基础任务,广泛应用于自动驾驶、医学分析和机器人技术等领域。像YOLO系列这样的传统方法利用卷积神经网络实现了卓越的实时性能。然而,它们对预定义目标类别的依赖限制了在实际开放场景中的灵活性。此类场景越来越需要能够在文本、视觉线索等多种提示机制引导下,甚至无需提示就能检测和分割任意目标的模型。
简介
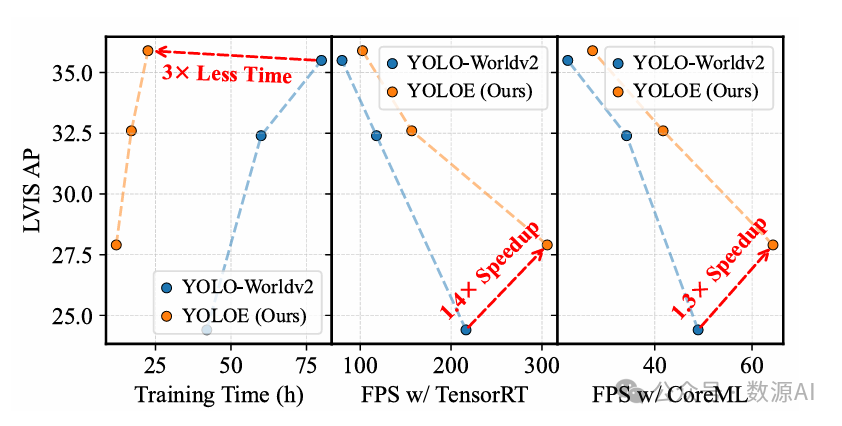
目标检测和分割在计算机视觉应用中被广泛采用,然而像YOLO系列这样的传统模型虽然高效且准确,但受限于预定义的类别,在开放场景中的适应性受到阻碍。近期的开放集方法利用文本提示、视觉线索或无提示范式来克服这一问题,但由于高计算需求或部署复杂性,往往在性能和效率之间进行折衷。在这项工作中,我们推出了YOLOE,它在一个高效的单一模型中集成了跨多种开放提示机制的检测和分割功能,实现了实时识别任何物体。对于文本提示,我们提出了可重参数化区域 - 文本对齐(Re - parameterizable Region - Text Alignment,RepRTA)策略。该策略通过一个可重参数化的轻量级辅助网络优化预训练的文本嵌入,并以零推理和迁移开销增强视觉 - 文本对齐。对于视觉提示,我们提出了语义激活视觉提示编码器(Semantic - Activated Visual Prompt Encoder,SAVPE)。它采用解耦的语义和激活分支,以最小的复杂度带来改进的视觉嵌入和准确性。对于无提示场景,我们引入了惰性区域 - 提示对比(Lazy Region - Prompt Contrast,LRPC)策略。它利用内置的大词汇表和专门的嵌入来识别所有物体,避免了对高成本语言模型的依赖。大量实验表明,YOLOE具有卓越的零样本性能和可迁移性,推理效率高且训练成本低。值得注意的是,在LVIS数据集上,YOLOE - v8 - S以更低的训练成本和的推理加速,比YOLO - Worldv2 - S的平均精度(AP)高出3.5。当迁移到时,与封闭集的YOLOv8 - L相比,在训练时间减少近的情况下,实现了的提升和0.4的提升。
方法与模型
在本节中,我们详细介绍YOLOE的设计。基于YOLO系列(3.1节),YOLOE通过RepRTA(3.2节)支持文本提示,通过SAVPE(3.3节)支持视觉提示,并通过LRPC(3.4节)支持无提示场景。
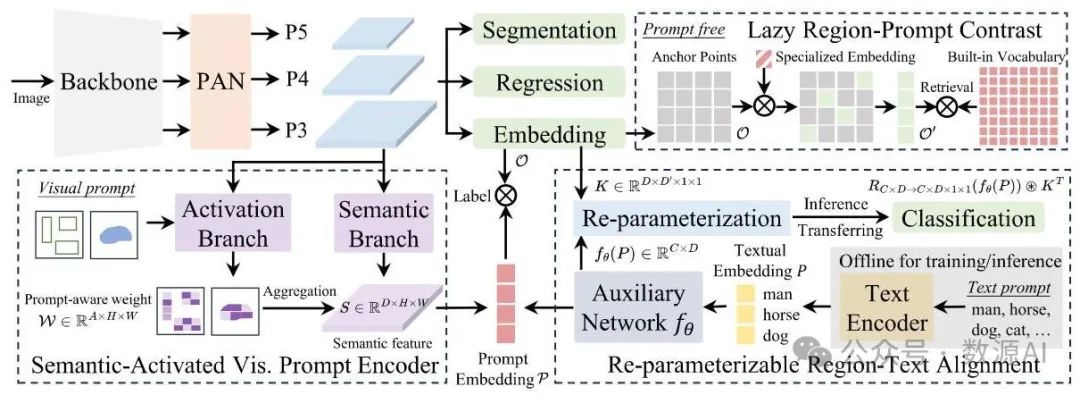
图2. YOLOE(一种目标检测和分割模型)概述,它支持多种开放提示机制下的检测和分割任务。对于文本提示,我们设计了一种可重新参数化的区域 - 文本对齐策略,以在零推理和迁移开销的情况下提高性能。对于视觉提示,采用SAVPE(一种视觉提示编码方法)以最小的成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6059
6059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









