




《FPGA基础知识》系列导航
本专栏专为FPGA新手打造的Xilinx平台入门指南。旨在手把手带你走通从代码、仿真、约束到生成比特流并烧录的全过程。
本篇是该系列的第一篇内容
下一篇:FPGA基础知识(二):深入理解时钟与复位
————————————————
一 引言
在数字电路设计领域,FPGA(现场可编程门阵列)之所以能够实现惊人的性能突破,其核心奥秘就在于并行执行模式。这种模式彻底颠覆了传统处理器的顺序执行思维,为高性能计算打开了全新的大门。
二 顺序执行 vs 并行执行:根本性的思维转变
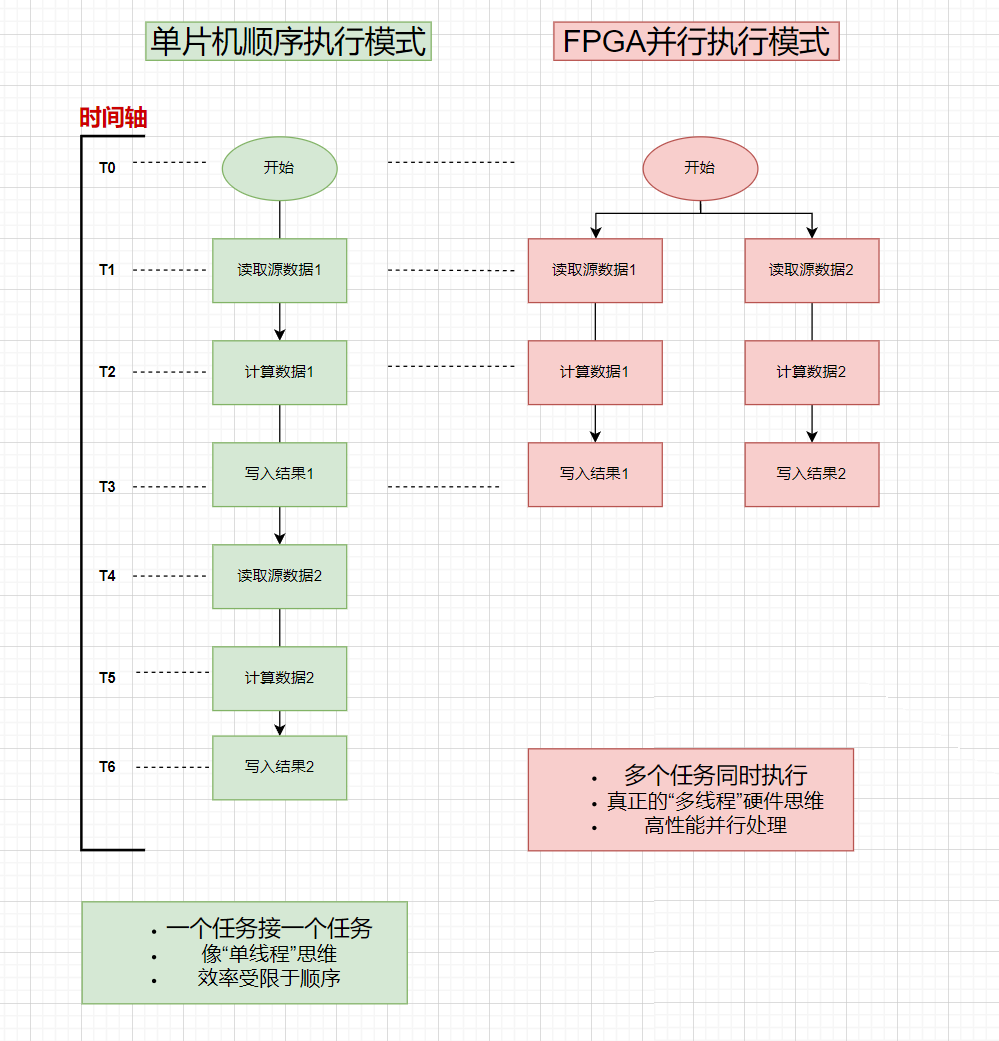
传统处理器(如CPU、MCU)的顺序执行模式:
-
指令逐条执行,形成指令流水线
-
共享计算资源(ALU、寄存器等)
-
依赖程序计数器控制执行流程
-
性能受限于时钟频率和指令级并行
FPGA的并行执行模式:
-
所有逻辑单元同时工作
-
每个功能都有专属的硬件资源
-
数据流驱动,无集中控制
-
性能与资源规模正相关
三 硬件描述语言中的并行性体现
在Verilog或VHDL中,这种并行性通过几种基本结构得以实现:
// 示例1:多个always块的并行执行
module parallel_example(
input clk,
input [7:0] data_in,
output reg [7:0] result1,
output reg [7:0] result2,
output reg [7:0] result3
);
// 三个always块并行执行
always @(posedge clk) begin
result1 <= data_in + 1; // 流水线A:数据加1
end
always @(posedge clk) begin
result2 <= data_in * 2; // 流水线B:数据乘2
end
always @(posedge clk) begin
result3 <= ~data_in; // 流水线C:数据取反
end
endmodule在这个例子中,三个处理操作在同一个时钟周期内同时完成,彼此之间没有任何依赖或等待。
四 并行架构的实际应用优势
1. 数据流处理的高效性
在图像处理、信号处理等应用中,FPGA可以构建真正的流水线架构:
// 图像处理流水线示例
module image_pipeline(
input clk,
input [23:0] pixel_in,
output [23:0] pixel_out
);
reg [23:0] stage1, stage2, stage3;
// 三级处理流水线
always @(posedge clk) begin
// 第一级:颜色空间转换
stage1 <= rgb_to_grayscale(pixel_in);
// 第二级:高斯滤波
stage2 <= gaussian_filter(stage1);
// 第三级:边缘检测
stage3 <= edge_detect(stage2);
end
assign pixel_out = stage3;
endmodule每个像素在每个时钟周期都会流经整个处理链,实现极高的吞吐量。
2. 多通道并行处理
FPGA可以轻松实现多个相同处理单元的并行工作:
// 8通道并行FIR滤波器
module multi_channel_fir(
input clk,
input [7:0][15:0] channels_in,
output [7:0][15:0] channels_out
);
genvar i;
generate
for (i = 0; i < 8; i = i + 1) begin : channel_gen
fir_filter #(.COEFFS('{1,2,3,2,1}))
fir_inst (
.clk(clk),
.data_in(channels_in[i]),
.data_out(channels_out[i])
);
end
endgenerate
endmodule五 并行设计的挑战与考量
1. 资源权衡
-
更多并行单元 → 更高性能
-
更多并行单元 → 更大资源消耗
-
需要在性能与资源间找到平衡点
2. 时序收敛
-
并行路径必须满足时序约束
-
关键路径决定最大工作频率
-
需要合理的流水线设计
3. 数据同步
-
并行单元间的数据交换需要同步机制
-
跨时钟域处理需要特殊设计
-
避免竞争条件和数据冲突
六 实际应用场景分析
案例:实时视频处理系统
-
1080p@60fps视频流:每帧约200万像素
-
处理要求:色彩转换、降噪、锐化、目标识别
-
FPGA方案:四级流水线 + 四个并行处理引擎
-
性能结果:处理延迟 < 1ms,完全实时
相比之下,同等成本的CPU方案难以满足实时性要求。
七 最佳实践指南
-
模块化设计:将系统分解为独立的并行单元
-
合理流水:通过流水线提高时序性能
-
资源复用:在资源紧张时适时复用硬件
-
接口标准化:使用标准接口(如AXI-Stream)连接模块
总结
FPGA的并行执行模式不仅是技术特性,更是一种设计哲学的革新。它让工程师能够:
-
用空间换时间,突破频率瓶颈
-
为特定应用定制最优架构
-
在功耗、性能、成本间找到最佳平衡
掌握并行设计思维,是释放FPGA真正潜力的关键。随着人工智能、5G通信、自动驾驶等领域的快速发展,这种能够提供确定性和高效率的并行处理能力,正变得越来越重要。


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











