引言
随着人工智能(Artificial Intelligence,AI)大
潮流的不断推进,越来越多的领域利用AI来助推产
业升级,提升产品或者项目的效率。在工业控制的
应用中,对自动化的要求也越来越高,不少场景下也
迫切希望AI技术的引入能够带来产品性能的提升。
尤其是在工厂制造流水线,工业机器人等领域,往
往需要借助AI技术来提升图像识别、故障分析的效
率[1~3]。另一方面,工业控制讲究产品的稳定性,以及
产品编程应用的便捷性,如何能同时满足两方面的
应用需求是目前业内都在努力的方向。
目前常见的模式主要有两种:
(1)直接在AI计算机上进行AI算法的开发、AI
运算和工业控制的逻辑编程。
采用该模式主要存在3个问题:
1)整个系统比较庞大,成本比较高。
2)AI计算机毕竟不像嵌入式系统,其系统的
稳定性无法保证,这对工业的可靠性要求来说是致
命的。
3)有一个不能忽视的问题是在计算机上进行
工业控制的编程,有较高的开发门槛,且功能的调
整和变更都很麻烦,无法满足现场应用工程师的
需求。
(2)采用有AI算力的嵌入式系统配合PLC进行
功能开发[4],这种方式能够解决稳定性问题,但是总
体成本比较高,而且两个系统的组合,需要进行数据
通信和指令交互,这当中的开发和适配工作门槛较
高,投入也大。
针对上述问题,本文提出一种新型PLC控制器,
能够支持AI功能的同时,也能降低AI技术应用带来
的技术门槛,又能满足电气工程师擅长的组态编程
开发方式。
1 PLC功能总体架构
本文提出的PLC控制器是AI计算核心和PLC
控制一体化设计方式。其编程使用方式与通用PLC
完全一致,提供组态编程环境,支持IEC 61131-3标
准的5种编程语言,包括ST、LD、IL、FBD和SFC语
言,支持常用的数字量、模拟量输入输出,内置的
Modbus RTU/TCP、CANopen协议也适用于大部分
的工业控制场景下。针对AI功能,该PLC提供了多路
摄像头输入接口,通过功能块的配置,实现AI图像
处理。整体系统功能框图如图1所示。
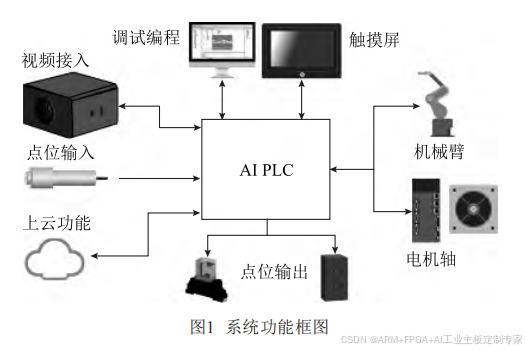
图1中,AI PLC(即本方案提出的带AI功能的
PLC),与一般PLC不同的是,本方案的PLC能够直
接接入多路摄像头视频信号,根据内置的深度学习
框架对视频信号进行处理。可应用于需要接入工业
摄像头进行产品缺陷检测或者模板匹配定位的智能
设备上,如智能裁床、流水线物品抓取识别等[5~6]。
另外,也可用于工业现场的人员安全检测,如头盔的
佩戴检测、危险区域的视觉围栏识别检测等。
除视频信号接入外,该PLC也支持采用4G或者
5G的方式将检测数据[7]、PLC状态数据上传到工业
云平台,实现远程的监视和管理。
另外,本方案PLC同样支持数字量和模拟量的
输入输出,可外接诸如限位开关、指示灯、中间继电
器、传感器等配件,满足一般控制场景的要求。
外接的触摸屏,可通过Modbus TCP/RTU总线
方式访问PLC内部的数据,进行本地化的人机交互。
PLC组态程序的编写、下载、调试则可通过网口或者
串口与PC相连实现,除了组态程序的通信调试外,当
内置的AI模型无法满足现场应用要求时,也可以通
过PC对其中的AI框架、参数进行调整以适用于不同
的场景。
本方案PLC也同样支持运动控制功能,依托于
CMC芯片强大的性能,可实现4轴3联动的运动控
制,直接控制伺服或者步进驱动器,进行独立多轴
控制,也可以用来控制多种类型的工业机械臂,如
SCARA机械臂、龙门机械臂等。
总体而言,不论是AI性能还是工业应用便携
性、稳定性上都有着广泛的应用场景。下面针对该
PLC的软硬件方案进行详细说明。
2 硬件方案设计
本方案PLC总体采用双核协同的设计方案,AI
部分采用的是瑞芯微电子的RK3588作为核心,而工
业控制部分则以中控微电子的CMC芯片为核心实
现。两者再通过SPI通信实现数据交互和指令协同,
其具体的硬件框架如图2所示。
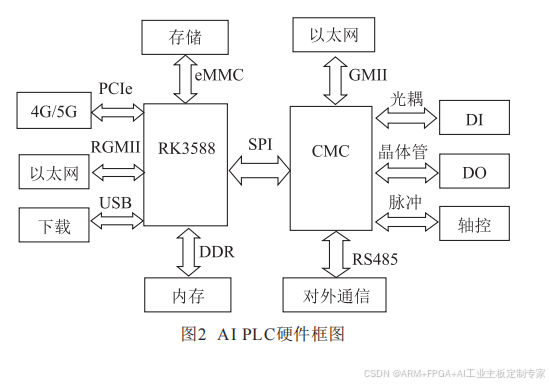
其中,RK3588是一款8核64位高性能处理器,
有独立的GPU和NPU模块,拥有6TOPS算力,有
很强的影像处理能力,最多可接入超过6路摄像
头信号。同时拥有丰富的通信接口,如PCIe3.0、
SATA3.0、RGMII、USB3.1等高速接口,也有SPI、
I2C、UART等低速通信接口。
RK3588可通过DDR接口外接不同容量的内存
器件。一般8G内存能够应对大多数场景,也可通过
eMMC或者SATA接口外接不同的存储器件,以此形
成一个最小系统。
RK3588的千兆以太网接口,一方面可用于有线
网络传输,另外也可用于工业摄像头的接入。而其丰
富的USB接口和PCIe接口可接入多路视频信号和外
扩4G/5G模块,不同于用普通串口扩展网络模块,采
用PCIe接口直接扩展的4G/5G模块,其无线传输速
率高,能够直接传输视频流信号,保证工业互联网
接入视频的流畅性。本方案采用移远RM500U模块
进行无线数据的传输。
CMC芯片是一款内置了逻辑控制和运动控制内
核的工业控制芯片。该芯片可根据芯片功能配置,设
计成各种不同功能的PLC,通过在组态软件上的设
备导入,快速实现组态编程,CMC芯片面向工业控
制设计,性能稳定。通过与RK3588的协同处理,能
够发挥各自性能上的优势。
RK3588和CMC之间主要进行参数配置数据、
AI模式选择数据和AI计算结果数据的传输,不存
在大数据的通信,所以两者之间通过SPI即可满足要
求,SPI通信采用1MHz波特率。其中CMC芯片作为
主机,RK3588作为从机,其执行的工作内容受控于
CMC的指令。
工业控制常用的点位控制,由CMC芯片引出,
通过继电器、光耦进行隔离设计保证系统内部电源
的稳定。同时,CMC自带丰富的接口资源,其中以太
网口用于组态程序的下载和调试,RS485接口则通
过Modbus RTU协议对外进行通信,实现与HMI或
者其他传感器的通信。
CMC内置的运动控制内核,输出脉冲+方向、
CW/CCW、AB相等信号,可用来控制多轴伺服电
机,实现各种梯形/S型曲线加减速运动。此外支持
的3轴直线插补、2轴圆弧插补,则用于各类机械臂
控制。
3 软件方案设计
本方案PLC的软件方案设计主要包含两个方
面:一个是RK3588上的AI模型导入以及关键参数
的接口定义;另一个是CMC上的组态功能开发。其
中又以两者之间的数据通信最为关键,直接关系到
现场应用开发的便捷度。
CMC上点位控制和对外通信功能使用较为
简便,直接在组态软件中进行调用即可实现,对
于运动控制的功能,本方案的组态软件提供满足
PLCopen标准的功能块,包括单轴和轴组功能均可
便捷实现,本文不再赘述。
RK3588支持多种AI框架,比如TensorFlow、
Caffe、pyTorch等一系列框架。同时在RK3588中,
导入了多种目标检测的深度学习模型,如YOLO、
RetinaNet、Mask R-CNN等,它们各自有不同的训
练参数,并针对这几个模型各自适用的场景进行了
基本参数的匹配,且留出部分接口供CMC主控进行
设置和读取。在目标检测应用中,可以通过不同模型
的调用,挑选出最适合的模型应用到实际环境中,
并通过功能块配置识别间隔时间等参数,达到最佳
效果。
下面重点是对RK3588和CMC的通信进行设
计说明。两者采用SPI进行通信,所有SPI通信均由
CMC主机发起,双方采用一问一答的方式进行。在
组态软件中可对SPI通信的超时进行设置,本方案
提供了4种读写方式,如表1所示。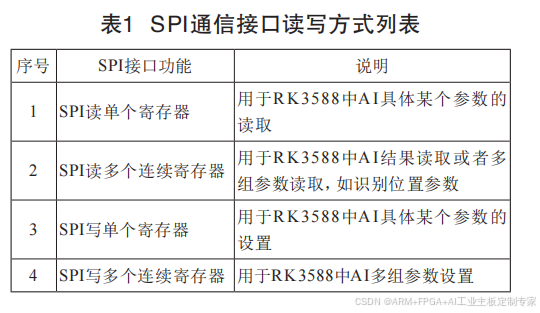
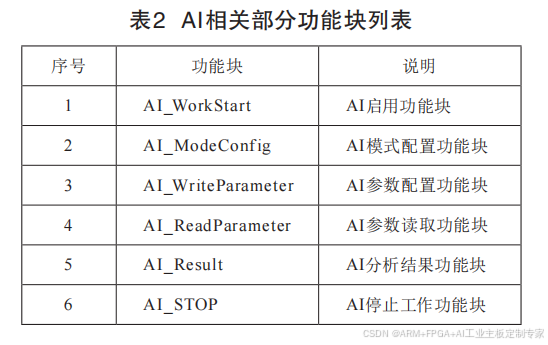
针对AI的应用,结合设计的SPI通信接口和协
议,本方案封装了多种默认功能块,能够实现常规的
AI使用配置,大大降低了开发的难度。此外,在组态
软件中也支持用户自定义功能块,如果当前默认功
能块无法满足要求,可以通过提供的SPI接口,编写
新功能块,目前已有的部分功能块如表2所示。功能
块效果如图3所示。
辑功能的编写。
当然,本方案仍然保留了RK3588的开发接口。
当需要增加新的AI网络、重新制定训练参数、增加
新的功能时,可以通过USB方式对其内核和应用做
修改。
=================RK3576+FPGA+AI=================
搭载新一代八核 AIOT RK3576,采用先进工艺制程,内置 ARM Mali G52 MC3 GPU,集成 6 TOPS 算力 NPU,支持主流大模型的私有化部署。具备强大的高清高帧率显示能力,支持外部看门狗,拥有工业级的稳定性,广泛适用于 AI 本地部署应用场景。

八核 64 位 AIOT 处理器 RK3576
新一代八核 64 位高性能 AIOT 处理器 RK3576,采用大小核构架(4×A72 +4×A53),先进工艺制程,主频高达 2.2GHz,为高性能计算和多任务处理提供了强大支持。搭载 Mali - G52 MC3 GPU,145G FLOPS 的 GPU 可以支持有效的异构计算,满足图形密集型应用的需求。
更多的工业新特性
相对上一代芯片,RK3576更新多种工业新特性,包括:实时网络、信号输入、MCU、DSMC、Flexbus、资源隔离。
全面的AI私有化部署
内置强劲 NPU,算力可达 6 TOPS;能够进行更智能的数据处理、语音识别、图像分析,满足大多数终端设备边缘计算 AI 应用需求。支持 Transformer 架构下大规模参数模型,如 Gemma-2B、Qwen1.5-1.8B、Llama2-7B、ChatGLM3-6B 等大模型的私有化部署。
4K@120 fps 高帧率视频解码
支持 8K@30fps / 4K@120fps 解码(H.265 / HEVC、VP9、AVS2、AV1 ) 和 4K@60fps 解码(H.264 / AVC),4K@60fps 编码(H.265 / HEVC、H.264 / AVC)。支持 HDMI2.1(4K@120fps)、DP1.4(4K@120fps0)

丰富的扩展接口
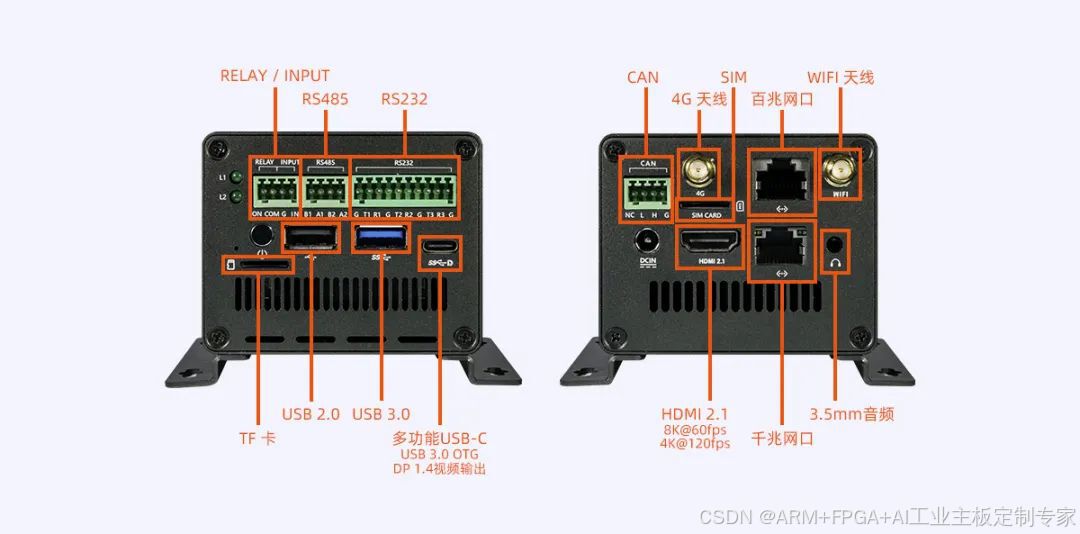
拥有 HDMI2.1、千兆以太网、百兆以太网、USB 3.0、USB2.0 、type-c(OTG / DP1.4)RS232、RS485、CAN、光耦隔离输入、继电器输出等接口,配置工业级全金属外壳,高效散热。
广泛的应用场景
RK3576可广泛适用于:边缘计算、大模型本地化、智慧商显、云终端产品、工控主机、汽车电子等行业领域。

























 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









