




 本文探讨了在数字信号处理中统计学与概率学的应用差异,重点解析了样本与随机变量的区别及其对信号处理技术的影响,并介绍了如何针对不平稳过程进行有效分析。
本文探讨了在数字信号处理中统计学与概率学的应用差异,重点解析了样本与随机变量的区别及其对信号处理技术的影响,并介绍了如何针对不平稳过程进行有效分析。
对于我们采集到的信号或者其他数字化数据,往往使用统计学进行解释。而对于产生信号的过程,往往使用概率学来进行解释。前者对应的概念是样本,后者对应的概念是随机变量。许多DSP技术的关键就在于将样本与随机变量区分开来。
例如,每次抛硬币这个过程可以用随机变量来表示,正面和反面的概率都为0.5。但是当抛硬币这个事件发生之后,我们就得到一个个结果,即样本。抛1000次硬币,往往不会出现500次正面500次反面,我们通过这些样本计算出的正反面概率会偏离0.5,这就是样本和随机变量之间的本质区别。这种数据偏离往往呈现出随机不规律性,其被称为统计波动、统计起伏或统计噪声。
所以,当我们在文献或者书籍中看到平均值或者标准偏差时,一定要分清楚作者讲的对象是样本还是随机变量。
我们从前文:数字信号处理技术–平均值和标准偏差也可以看到,样本方差(标准偏差的平方)的公式中分母为N-1,这就是统计噪声所致:对于随机信号,N点的平均值和随机变量的平均值之间的典型偏差,为:
典
型
误
差
=
σ
N
典型误差=\frac{\sigma }{\sqrt{N}}
典型误差=Nσ
当N较小时,典型偏差就大,即统计噪声就大。当N较大时,典型偏差可以趋近于0。
所以,在N较小时,样本方差的计算公式分母如果使用N,则会导致我们对随机变量的标准偏差的估计较小。而当我们使用N-1代替N时,则会获得更为准确的估计。
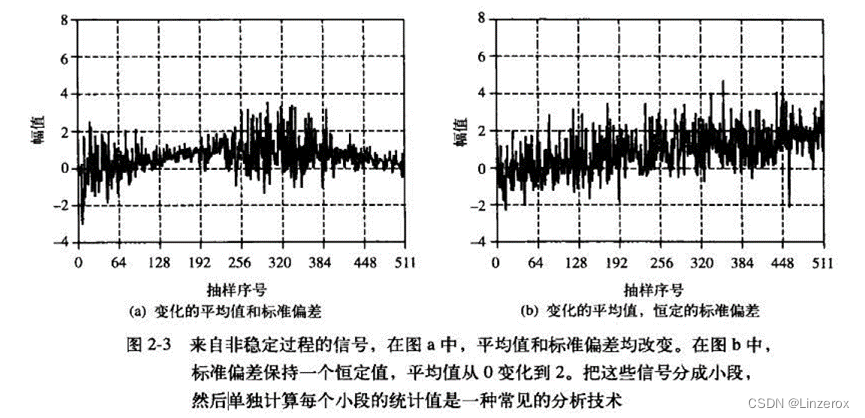
前面的这些论述都基于一点,所有时刻,随机信号都可以看成一个相同的随机变量。如果,一个随机信号在不同时刻是完全不同的随机变量,如下图所示。此时,在不同时刻,信号的平均值和方差都发生了变化,如果再使用前文:数字信号处理技术–平均值和标准偏差所述的估计方法显然会出现较大的误差,这些误差不来源于统计噪声,而是来自于随机信号本身。对于这一类信号,我们称其处于不稳定态,它们是一种不平稳过程。
对于此类信号,常见的分析方法就是讲信号分成多个小段,分别计算各个小段的统计值来消除误差。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









