



1 总结
- 何谓重构:在不改变软件可观察行为的前提下,提高其可理解性。重构是为了让代码“更容易理解, 更易于修改。
- 识别两顶帽子:添加新功能与进行重构独立。添加新功能时,我不应该修改既有代码,只管添加新功能。重构时我就不能再添加功能,只管调整代码的结构。无论何时我都清楚自己戴的是哪一顶帽子,并且明白不同的帽子对编程状态提出的不同要求。
- 为什么重构:
- 可以改进软件的设计:一个重要方向就是消除重复代码
- 使得代码更容易理解:对于任何能够立刻查阅的东西,都不去记它,避免脑子爆炸。
- 可以提高编程速度:重构之后可以很容易地构造与其领域相关的新功能。
- 什么时候重构:
- 三次法则:第三次再做类似的事,你就应该重构。
- 预备性重构:当添加性功能时进行重构,重构让添加新功能更容易
- 代码不易懂和需要改进设计:
- 当代码不易理解时,重构使代码更易懂。如果花了几分钟才明白函数是什么意思,就需要扪心自问,能不能重构这段代码,令其一目了然?
- 当代码变得更清晰一些时,我就会看见之前看不见的设计问题。如果不做前面的重构,我可能永远都看不见这些设计问题,因为我不够聪明,无法在脑海中推演所有这些变化。
- 捡垃圾式重构:每次读代码都会发现一些垃圾,如果我发现的垃圾很容易重构,我会马上重构它; 如果重构需要花一些精力,我可能会拿一张便笺纸 把它记下来, 完成当下的任务再回来重构它。至少要让营地比你到达时更干净。
- 有计划的重构和见机行事的重构:重构不是与编程割裂的行为。有计划的重构应该很少,大部分重构应该是不起眼的、见机行事的。
- 长期重构:每当有人靠近“重构区”的代码,就把它朝想要改进的方向推动一点。
- 复审代码时重构:复审代码时许多建议能够立刻实现。
- 如何对经历说重构:他们不理解代码库的健康对 生产率的影响。这种情况下我会给团队一个较有争议的建议:不要告诉经理! 受进度驱动的经理要我尽可能快速完成任 务,至于怎么完成,那就是我的事了。我领这份工资,是因为我擅长快速实现新功能;我认为最快的方式就是重构,所以我就重构。
- 何时不应该重构:只有当我需要理解其工作原理时(需要对其进行修改时),对其进行重构才有价值。如果重写比重构还容易,就别重构了。
- 重构的挑战:
- 延缓功能开发:有时会看到一个(大规模的)重构很有必要进行,而马上要添加的功能非常小,这时我会更愿意先把新功能加上,然后再做这次大规模重构。做这个决定需要判断力。重构的意义不在于把代码库打磨得闪闪发光,而是纯粹经济角度出发的考量。重构应该总是由经济利益驱动。
- 代码所有权:为了给一个函数改名,我需要使用函数改名(124),但同时也得保留原来的函数声明,使其把调用传递给新的函数。
- 分支:分支合并比较复杂,可以使用CI(持续集成)或者快速集成。
- 测试:如果想要重构,我得先有可以自测试的代码。
- 针对大规模遗留代码:面对一个庞大而又缺乏测试的遗留系统,很难安全地重构清理它。最好建议就是买一本《修改代码 的艺术》[Feathers],照书里的指导来做。
- 数据库:借助数据迁移脚本,将数据库结构的修改与代码相结合,使大规模的、涉及数据库的修改可以比较容易地开展。确定没有bug之后,我再删除已经没人使用的旧字段。
- 重构、架构和YGNI:为了未来的预期场景,需要添加十几个参数来灵活应对,怎么办?只有当未来重构会很困难时,我才考虑现在就添加灵活性机制。我发现这是一个很有用的决策方法。”这种设计方法有很多名字:简单设计、增量式设计或者YAGNI[mf-yagni] ——“你不会需要它”(you arenʼt going to need it)的缩写。
- 重构与软件开发过程:自测试代码、持续集成、重构——彼此之间有着很强的协同效应。
- 重构与性能:先写出可调优的软件,然 后调优它以求获得足够的速度。
- 重构后,我能够更快速地添加功能,也就有更多时间用在性能问题上
- 面对构造良好的程序,我在进行性能分析时便有较细的粒度。
2 何谓重构:在不改变软件可观察行为的前提下,提高其可理解性
“重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行 为的前提下,提高其可理解性,降低其修改成本。”
“如果有人说他们的代码在重构过程中有一两天时间不可用,基本上可 以确定,他们在做的事不是重构。”
““结构调整”(restructuring)来泛指对代码库进行的各种形式的重新组 织或清理,重构则是特定的一类结构调整。”
“整个过程 中我不会花任何时间来调试。”
“重构与性能优化有很多相似之处:两者都需要修改代码,并且两者都不会改 变程序的整体功能。两者的差别在于其目的:重构是为了让代码“更容易理解, 更易于修改”。这可能使程序运行得更快,也可能使程序运行得更慢。在性能优 化时,我只关心让程序运行得更快,最终得到的代码有可能更难理解和维护,对 此我有心理准备。”
3 两顶帽子:添加新功能与进行重构独立
Kent Beck提出了“两顶帽子”的比喻。使用重构技术开发软件时,我把自己的 时间分配给两种截然不同的行为:添加新功能和重构。**添加新功能时,我不应该修改既有代码,只管添加新功能。**通过添加测试并让测试正常运行,我可以衡量自己的工作进度。**重构时我就不能再添加功能,只管调整代码的结构。**此时我不应该添加任何测试(除非发现有先前遗漏的东西),只在绝对必要(用以处理接 口变化)时才修改测试。
软件开发过程中,我可能会发现自己经常变换帽子。首先我会尝试添加新功能,然后会意识到:如果把程序结构改一下,功能的添加会容易得多。于是我换 一顶帽子,做一会儿重构工作。程序结构调整好后,我又换上原先的帽子,继续 添加新功能。新功能正常工作后,我又发现自己的编码造成程序难以理解,于是 又换上重构帽子......整个过程或许只花10分钟,但无论何时我都清楚自己戴的是哪一顶帽子,并且明白不同的帽子对编程状态提出的不同要求。”
4 为什么重构
4.1 重构改进软件的设计
完成同样一件事,设计欠佳的程序往往需要更多代码,这常常是因为代码在不同的地方使用完全相同的语句做同样的事,因此改进设计的一个重要方向就是消除重复代码。代码量减少并不会使系统运行更快,因为这对程序的资源占用几乎没有任何明显影响。然而代码量减少将使未来可能的程序修改动作容易得多。代码越多,做正确的修改就越困难,因为有更多代码需要理解。消除重复代码,我就可以确定所有事物和行为在代码中只表述一次,这正是优秀设计的根本。
4.2 重构使得代码更容易理解—重构是将理解注入代码的过程
事实上,对于任何能够立刻查阅的东西,我都故意不去记它,因为我怕把自己的脑袋塞爆。我总是尽量把该记住的东 西写进代码里,这样我就不必记住它了。这么一来,下班后我还可以喝上两杯 Maudite啤酒,不必太担心它杀光我的脑细胞。
4.3 重构提高编程速度
重构帮我更快速地开发程序。
经常有这样的故事:一开始他们进展很快,但如今想要添加一个新功能需要的时间就要长得多。他们需要**花越来越多的时间去考虑如何把新功能塞进现有的代码库,**不断蹦出来的bug修复起来也越来越慢。
理想情况下,我的代码库会 逐步演化成一个平台,在其上可以很容易地构造与其领域相关的新功能。
20年前,行业的陈规认为:良好的设计必须在开始编程之前完成,因为一旦 开始编写代码,设计就只会逐渐腐败。重构改变了这个图景。现在我们可以改善已有代码的设计,因此我们可以先做一个设计,然后不断改善它,哪怕程序本身的功能也在不断发生着变化。由于预先做出良好的设计非常困难, 想要既体面又快速地开发功能, 重构必不可少。
4.4 什么时候进行重构
在我编程的每个小时,我都会做重构。有几种方式可以把重构融入我的工作过程里。
三次法则:
“Don Roberts给了我一条准则: 第一次做某件事时只管去做; 第二次做类似的事会产生反感,但无 论如何还是可以去做; 第三次再做类似的事,你就应该重构。”
4.4.1 预备性重构:当添加性功能时进行重构,重构让添加新功能更容易
“重构的最佳时机就在添加新功能之前。在动手添加新功能之前,我会看看现 有的代码库,此时经常会发现:如果对代码结构做一点微调,我的工作会容易得 多。也许已经有个函数提供了我需要的大部分功能,但有几个字面量的值与我的需要略有冲突。如果不做重构,我可能会把整个函数复制过来,修改这几个值, 但这就会导致重复代码——如果将来我需要做修改,就必须同时修改两处(更麻 烦的是,我得先找到这两处)。而且,如果将来我还需要一个类似又略有不同的 功能,就只能再复制粘贴一次,这可不是个好主意。所以我戴上重构的帽子,使 用函数参数化(310)。做完这件事以后,接下来我就只需要调用这个函数,传 入我需要的参数。”
修复bug时的情况也是一样。在寻找问题根因时,我可能会发现:如果把3段 一模一样且都会导致错误的代码合并到一处,问题修复起来会容易得多。或者, 如果把某些更新数据的逻辑与查询逻辑分开,会更容易避免造成错误的逻辑纠缠。用重构改善这些情况,在同样场合再次出现同样bug的概率也会降低。
4.4.2 帮助理解的重构:当代码不易理解时,重构使代码更易懂
一旦我需要思考“这段代码到底在做什么”,我就会自问:能不能重构这段代码,令其一目了然?我可能看见了一段结构糟糕的条件逻辑,也 可能希望复用一个函数,但花费了几分钟才弄懂它到底在做什么,因为它的函数 命名实在是太糟糕了。这些都是重构的机会。
**当代码变得更清晰一些时,我就会看见之前看不见的设计问题。**如果不做前面的重构,我可能永远都看不见这些设计问题,因为我不够聪明,无法在脑海中推演所有这些变化。
4.4.3 捡垃圾式重构
帮助理解的重构还有一个变体:我已经理解代码在做什么,但发现它做得不 好,例如逻辑不必要地迂回复杂,或者两个函数几乎完全相同,可以用一个参数 化的函数取而代之。这里有一个取舍:我不想从眼下正要完成的任务上跑题太 多,但我也不想把垃圾留在原地,给将来的修改增加麻烦。如果我发现的垃圾很容易重构,我会马上重构它; 如果重构需要花一些精力,我可能会拿一张便笺纸 把它记下来, 完成当下的任务再回来重构它。
当然,有时这样的垃圾需要好几个小时才能解决,而我又有更紧急的事要完成。不过即便如此,稍微花一点工夫做一点儿清理,通常都是值得的。正如野营 者的老话所说:**至少要让营地比你到达时更干净。**如果每次经过这段代码时都把 它变好一点点,积少成多,垃圾总会被处理干净。
4.4.4 有计划的重构和见机行事的重构
“上面的例子——预备性重构、帮助理解的重构、捡垃圾式重构——都是见机行事的: 我并不专门安排一段时间来重构,而是在添加功能或修复bug的同时顺便重构。”
“这是一件很重要而又常被 误解的事:**重构不是与编程割裂的行为。**你不会专门安排时间重构,正如你不会 专门安排时间写if语句。我的项目计划上没有专门留给重构的时间,绝大多数重 构都在我做其他事的过程中自然发生。”
“肮脏的代码必须重构,但漂亮的代码也需要很多重构。”
“每次要修改时,首先令修改很容易(警告:这件事有时会很难),然后再进行这次容易的修改。”
“如果团队过去忽视了 重构,那么常常会需要专门花一些时间来优化代码库,以便更容易添加新功能。 在重构上花一个星期的时间,会在未来几个月里发挥价值。”
“但这种有计划的重构应该很少,大部分重构应该是不起眼的、见机行事 的。”
“将重构与添加新功能在版本控制的提交中分开。这样做的一大好处是可以各自独立地审阅和批准这些提交。但我并不认同这种做法。 重构常常与新添功能紧密交织,不值得花工夫把它们分开。并且这样做也使重构 脱离了上下文,使人看不出这些“重构提交”的价值。每个团队应该尝试并找出适 合自己的工作方式,只是要记住:分离重构提交并不是毋庸置疑的原则,只有当 你真的感到有益时,才值得这样做。”
4.4.5 长期重构
“可以让整个团队 达成共识,在未来几周时间里逐步解决这个问题,这经常是一个有效的策略。每 当有人靠近“重构区”的代码,就把它朝想要改进的方向推动一点。”
例如,如果想替换掉一个正在使用的库,可以先引入一层新的抽象,使其兼容新旧两个库的接口。一旦调用方已经完全改为使用这层抽象,替换下面的库就会容易 得多。(这个策略叫作Branch By Abstraction[mf-bba]。)”
4.4.6 复审代码时重构
重构还可以帮助代码复审工作得到更具体的结果。不仅获得建议,而且其中**许多建议能够立刻实现。**最终你将从实践中得到比以往多得多的成就感。
4.4.7 如何对经理说要重构
““重构”被视为一个脏词——经理(和客户)认为重构要么是在弥补过去犯下的错误,要么是不增加价值的无用功。”
“如果团队又计划了几周时间专门做重构,情况就更糟糕了——如果他们做的其实还不是重构,而是不加小心的结构调整,然后又对代码库造成了破坏,那可就真是糟透了。”
当然,很多经理和客户不具备这样的技术意识,他们不理解代码库的健康对 生产率的影响。这种情况下我会给团队一个较有争议的建议:不要告诉经理! 这是在搞破坏吗?我不这样想。软件开发者都是专业人士。我们的工作就是 尽可能快速创造出高效软件。我的经验告诉我,对于快速创造软件,重构可带来 巨大帮助。如果需要添加新功能,而原本设计却又使我无法方便地修改,我发现 先重构再添加新功能会更快些。如果要修补错误,就得先理解软件的工作方式, 而我发现重构是理解软件的最快方式。受进度驱动的经理要我尽可能快速完成任 务,至于怎么完成,那就是我的事了。我领这份工资,是因为我擅长快速实现新功能;我认为最快的方式就是重构,所以我就重构。”
4.4.8 何时不应该重构
如果我看见一块凌乱的代码,**但并不需要修改它,那么我就不需要重构它。 **如果丑陋的代码能被隐藏在一个API之下,我就可以容忍它继续保持丑陋。只有当我需要理解其工作原理时,对其进行重构才有价值。
另一种情况是,**如果重写比重构还容易,就别重构了。**这是个困难的决定。 如果不花一点儿时间尝试,往往很难真实了解重构一块代码的难度。决定到底应 该重构还是重写,需要良好的判断力与丰富的经验,我无法给出一条简单的建议。
5 重构的挑战
每当有人大力推荐一种技术、工具或者架构时,我总是会观察这东西会遇到哪些挑战,毕竟生活中很少有晴空万里的好事。你需要了解一件事背后的权衡取舍,才能决定何时何地应用它。我认为重构是一种很有价值的技术,大多数团队都应该更多地重构,但它也不是完全没有挑战的。有必要充分了解重构会遇到的挑战,这样才能做出有效应对。
5.1 延缓功能开发
重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值。
有一种情况确实需要权衡取舍。我有时会看到一个(大规模的)重构很有必要进行,而马上要添加的功能非常小,这时我会更愿意先把新功能加上,然后再做这次大规模重构。做这个决定需要判断力——这是我作为程序员的专业能力之 一。我很难描述决定的过程,更无法量化决定的依据。
因为他们没有太多在健康的代码库上工作的经历——轻松地把现有代码组合配置,快速构造出复杂的新功能,这种强大的开发方式他们没有体验过。
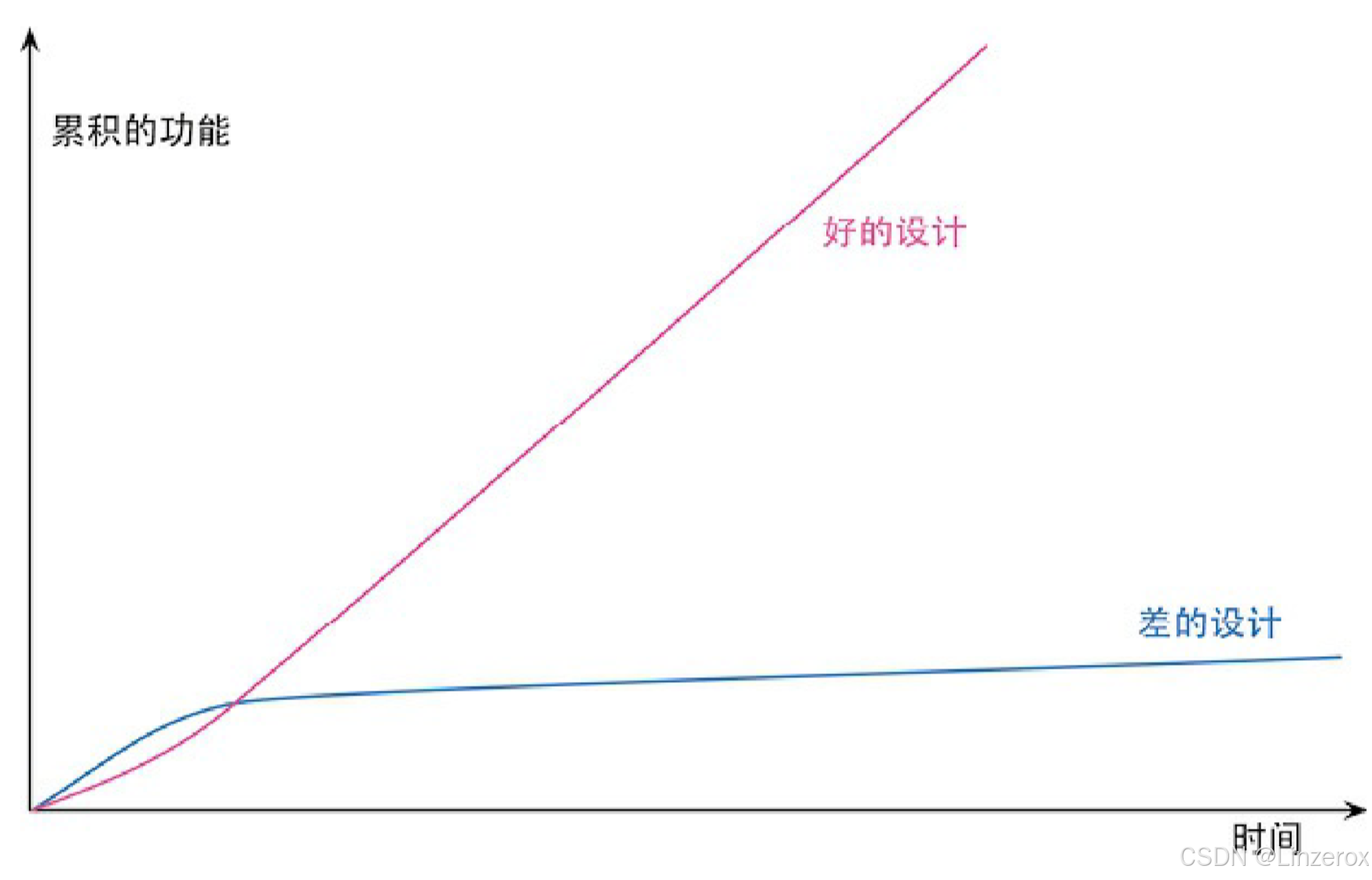
有些人试图用“整洁的代码”“良好的工程实践”之类道德理由来论证重构的必 要性,我认为这是个陷阱。**重构的意义不在于把代码库打磨得闪闪发光,而是纯粹经济角度出发的考量。重构应该总是由经济利益驱动。**程序员、经理和客户越理解这一点,“好的 设计”那条曲线就会越经常出现。
5.2 代码所有权
为了给一个函数改名,我需要使用函数改名(124),但同时也得保留原来的函数声明,使其把调用传递给新的函数。这会让接口变复杂,但这就是为了避免破坏使用者的系统而不得不付出的代价。我可以把旧的接口标记为“不 推荐使用”(deprecated),等一段时间之后最终让其退休;但有些时候,旧的接口必须一直保留下去。
5.3 分支
“常见的做法是在分支上开发完整的功能,直到功能可以发布到生产环境,才把该分支合并回主线。这种做法的拥 趸声称,这样能保持主线不受尚未完成的代码侵扰,能保留清晰的功能添加的版 本记录,并且在某个功能出问题时能容易地撤销修改。”
“而“集成”是一个双向的过程:不仅要把主线的修改拉 (pull)到我的分支上,而且要把我这里修改的结果推(push)回到主线上,两边都会发生修改。”
“假如另一名程序员Rachel正在她的分支上开发,我是看不见她 的修改的,直到她将自己的修改与主线集成;此时我就必须把她的修改合并到我 的特性分支,这可能需要相当的工作量。其中困难的部分是处理语义变化。现代 版本控制系统都能很好地合并程序文本的复杂修改,但对于代码的语义它们一无 所知。”
“还有一些人(比如我本人)认为特性分支的生命还应该更短,我们采用的方法叫作持续集成(Continuous Integration,CI),也叫“基于主 干开发”(Trunk-Based Development)。”
“**CI的粉丝之所以喜欢这种工作方式,部分原因是它降低了分支合并的难度, 不过最重要的原因还是CI与重构能良好配合。**重构经常需要对代码库中的很多地方做很小的修改(例如给一个广泛使用的函数改名),这样的修改尤其容易造成合并时的语义冲突。”
“**即便你没有完全采用CI,我也一定会催促你尽可能频繁地集成。**而且,用上CI的团队在软件交付上更加高效,我真心希望你认真考虑这个客观事实[Forsgren et al]。”
5.4 测试
“这里的关键就在于“快速发现错误”。要做到这一点,我的代码应该有一套完 备的测试套件,并且运行速度要快,否则我会不愿意频繁运行它。也就是说,绝 大多数情况下,如果想要重构,我得先有可以自测试的代码[mf-stc]。”
“缺乏测试的问题可以用另一种方式来解决。如果我的开发环境很好地支持自动化重构,我就可以信任这些重构,不必运行测试。”
自测试代码是极限编程的另一个重要组成部分,也是 持续交付的关键环节。
5.5 遗留代码
“如果 你面对一个庞大而又缺乏测试的遗留系统,很难安全地重构清理它。”
“对于这个问题,显而易见的答案是**“没测试就加测试”**。这事听起来简单(当 然工作量必定很大),操作起来可没那么容易。一般来说,只有在设计系统时就 考虑到了测试,这样的系统才容易添加测试——可要是如此,系统早该有测试 了,我也不用操这份心了。”
“这个问题没有简单的解决办法,我能给出的最好建议就是买一本《修改代码 的艺术》[Feathers],照书里的指导来做。”
“你需要运用重构手法创造出接缝—这样的重构很危险,因为没有测试覆盖,但这是为了取得进展必要的风险。在这种情况下,安全的自动化重构简直就是天赐福音。如果这一切听起来很困难,因 为它确实很困难。很遗憾,一旦跌进这个深坑,没有爬出来的捷径,这也是我强烈倡导从一开始就写能自测试的代码的原因。”
“如果是一个大系统,越是频 繁使用的代码,改善其可理解性的努力就能得到越丰厚的回报。”
5.6 数据库
我的同事Pramod Sadalage发展出 一套渐进式数据库设计[mf-evodb]和数据库重构[Ambler & Sadalage]的办法,如今 已经被广泛使用。这项技术的精要在于:借助数据迁移脚本,将数据库结构的修改与代码相结合,使大规模的、涉及数据库的修改可以比较容易地开展。
确定没有bug之后,我再删除已经没人使用的旧字段。这种修改数据库的方式是并行修改(Parallel Change,也叫扩展协议/expandcontract)[mf-pc]的一个实例。
6 重构、架构和YAGNI
为了应对我预期的应用场景,我预测可以给这个函数加上十多个参数。这些参数就是灵活性机制——跟大多数“机制”一 样,它不是免费午餐。把所有这些参数都加上的话,函数在当前的使用场景下就 会非常复杂。另外,如果我少考虑了一个参数,已经加上的这一堆参数会使新添 参数更麻烦。
考虑到所有这些因素,很多时候这些灵活性机制反而拖慢了我响应变化的速度。”
“与其猜测未来需要哪些灵活性、 需要什么机制来提供灵活性,我更愿意只根据当前的需求来构造软件,同时把软件的设计质量做得很高。”
要判断是否应该为未来的变化添加灵活性,我会评估“如果以后再重构有多困难”,只有当未来重构会很困难时,我才考虑现在就添加灵活性 机制。我发现这是一个很有用的决策方法。”
这种设计方法有很多名字**:简单设计、增量式设计或者YAGNI[mf-yagni] **——“你不会需要它”(you arenʼt going to need it)的缩写。
7 重构与软件开发过程
要真正以敏捷的方式 运作项目,团队成员必须在重构上有能力、有热情,他们采用的开发过程必须与 常规的、持续的重构相匹配。
**重构的第一块基石是自测试代码。**我应该有一套自动化的测试,我可以频繁地运行它们,并且我有信心:如果我在编程过程中犯了任何错误,会有测试失败。
自测试的代码也是持续集成的关键环节,所以这三大实践——自测试代码、持续集成、重构——彼此之间有着很强的协同效应。
8 重构与性能
“**虽然重构可能使软件运行更慢,但它也使软件的性能优化更容易。**除了对性能有严格要求的实 时系统,其他任何情况下“编写快速软件”的秘密就是:先写出可调优的软件,然 后调优它以求获得足够的速度。”
“我看过3种编写快速软件的方法。
- 其中最严格的是时间预算法,这通常只用于性能要求极高的实时系统。如果使用这种方法,分解你的设计时就要做好预 算,给每个组件预先分配一定资源,包括时间和空间占用。
- 第二种方法是持续关注法。这种方法要求任何程序员在任何时间做任何事时,都要设法保持系统的高性能。这种方式很常见,感觉上很有吸引力,但通常 不会起太大作用。”
“最后,我们就“如何让这个系统运行更快”,提出了一些真正的好点子。”
“教训是:哪怕你完全了解系统,也请实际度量它的性能,不要臆测。臆测会让你学到一些东西, 但十有八九你是错的。”
关于性能,一件很有趣的事情是:如果你对大多数程序进行分析,就会发现 它把大半时间都耗费在一小半代码身上。如果你一视同仁地优化所有代码,90% 的优化工作都是白费劲的,因为被你优化的代码大多很少被执行。”
- 第三种性能提升法就是利用上述的90%统计数据。采用这种方法时,我编写构造良好的程序,不对性能投以特别的关注,直至进入性能优化阶段——那通常是在开发后期。在性能优化阶段,我首先应该**用一个度量工具来监控程序的运行,让它告诉 我程序中哪些地方大量消耗时间和空间。**这样我就可以找出性能热点所在的一小段代码。”
一个构造良好的程序可从两方面帮助这一优化方式。
- 首先,它让我有比较充裕的时间进行性能调整,因为有构造良好的代码在手,我能够更快速地添加功能,也就有更多时间用在性能问题上(准确的度量则保证我把这些时间投在恰当 地点)。
- 其次,面对构造良好的程序,我在进行性能分析时便**有较细的粒度。**度 量工具会把我带入范围较小的代码段中,而性能的调整也比较容易些。由于代码 更加清晰,因此我能够更好地理解自己的选择,更清楚哪种调整起关键作用。
9 重构起源何处
我曾经努力想找出“重构”(refactoring)一词的真正起源,但最终失败了。优 秀程序员肯定至少会花一些时间来清理自己的代码。这么做是因为,他们知道整 洁的代码比杂乱无章的代码更容易修改,而且他们知道自己几乎无法一开始就写 出整洁的代码。
他的技术背景是电话交换系统的开发。在这种系统中,大量的复杂情况与日俱增,而且非常难以修改。
10 自动化重构
“如果我想给一个Java的方法改名,在IntelliJ IDEA或者Eclipse这样的开发环境 中,我只需要从菜单里点选对应的选项,工具会帮我完成整个重构过程,而且我 通常都可以相信,工具完成的重构是可靠的,所以用不着运行测试套件。”
“我不打算分析各种工具的能力,不过谈谈重构工具背后的 原则还是有点儿意思的。”
“要支持体面的重构,工具只操作代码文本是不行的,必须操作代码的语法 树,这样才能更可靠地保持代码行为。”
“所以,今天的大多数重构功能都依附于强 大的IDE,因为这些IDE原本就在语法树上实现了代码导航、静态检查等功能, 自然也可以用于重构。不仅能处理文本,还能处理语法树,这是IDE相比于文本 编辑器更先进的地方。”
“一些重构工具走得更远。如果我给一个变量改名,工具会提醒我修改使用了 旧名字的注释。如果我使用提炼函数(106),工具会找出与新函数体重复的代 码片段,建议代之以对新函数的调用。在编程时可以使用如此强大的重构功能, 这就是为什么我们要使用一个体面的IDE,而不是固执于熟悉的文本编辑器。我 个人很喜欢用Emacs,但在使用Java时,我更愿意用IntelliJ IDEA或者Eclipse,很 大程度上就是为了获得重构支持。”
“**能借助语法树来分析和重构程序代码,这是IDE与普通文本编辑器相比具有 的一大优势。**但很多程序员又喜欢用得顺手的文本编辑器的灵活性,希望鱼与熊 掌兼得。”
“语言服务器(Language Server)是一种正在引起关注的新技术:用软件 生成语法树,给文本编辑器提供API。语言服务器可以支持多种文本编辑器,并 且为强大的代码分析和重构操作提供了命令。”
11 延展阅读
不过,有大量关于重构的 材料已经超出了本书的范围,早些让读者知道这些材料的存在也是件好事。
如果你需要一本面向入门者的教材,我推荐 Bill Wake的《重构手册》[Wake],其中包含了很多有用的重构练习。
很多重构的先行者同时也活跃于软件模式社区。Josh Kerievsky在《重构与模式》[Kerievsky]一书中紧密连接了这两个世界。他审视了影响巨大的GoF[gof]书 中一些最有价值的模式,并展示了如何通过重构使代码向这些模式的方向演化。
还有一些专门领域的重构,例如已经引起关注的《数据库重构》[Ambler & Sadalage](由Scott Ambler和Pramod Sadalage所著)和《重构HTML》[Harold](由Elliotte Rusty Harold所著)。
尽管标题中没有“重构”二字,Michael Feathers的《修改代码的艺术》 [Feathers]也不得不提。这本书主要讨论如何在缺乏测试覆盖的老旧代码库上开展 重构。
本书(及其前一版)对读者的编程语言背景没有要求。也有人写专门针对特 定语言的重构书籍。我的两位前同事Jay Fields和Shane Harvey就撰写了Ruby版的 《重构》[Fields et al.]。
在本书的Web版和重构网站(refactoring.com)[ref.com]上都可以找到更多相 关材料的更新。”

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









