




1.分块矩阵简介
2.分块矩阵的运算规则
3.分块矩阵的转置矩阵
4.2*2分块矩阵的逆矩阵
1.分块矩阵简介
将一个大的矩阵用一些纵线和横线划分成若干个小的块, 这些小块本身也是矩阵; 通过对这些小
块进行运算, 来完成对整个大矩阵的运算

2.分块矩阵的运算规则
1).分块矩阵的加法
如果两个矩阵A和B被以完全相同的方式分块, 那么它们相加就是对自块相加
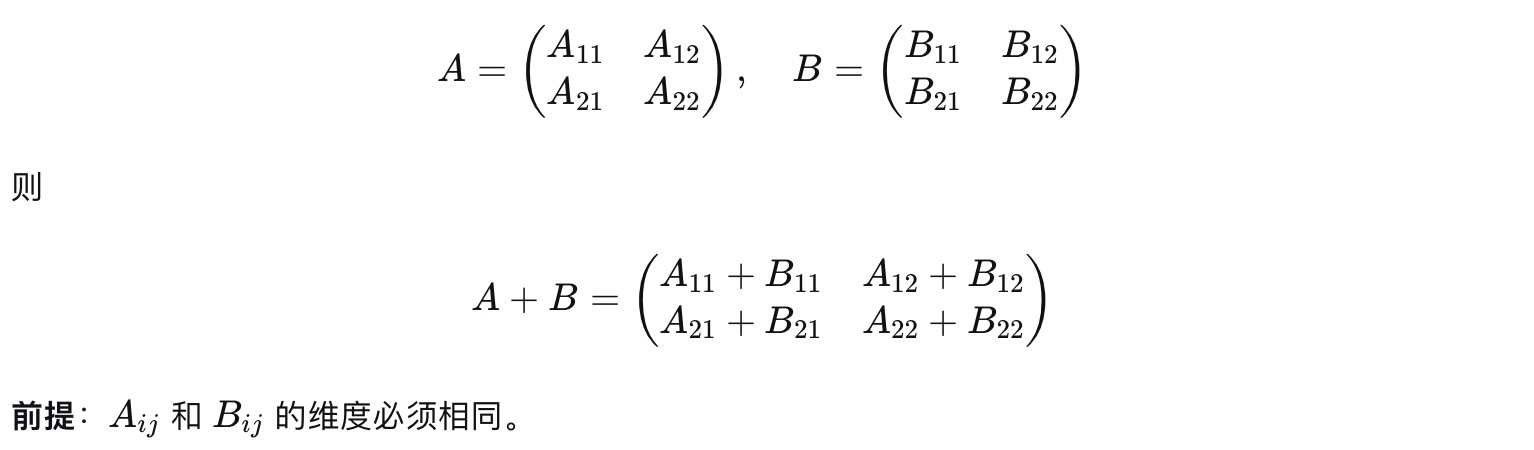
2).分块矩阵的数乘
一个标量k乘以一个分块矩阵, 等于用k乘以每一个子块
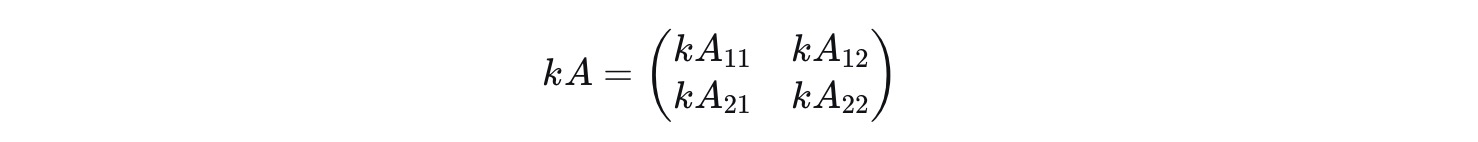
3).分块矩阵的乘法
分块矩阵的乘法规则与普通矩阵乘法规则类似("行乘以列"), 但相乘的对象变成了子块
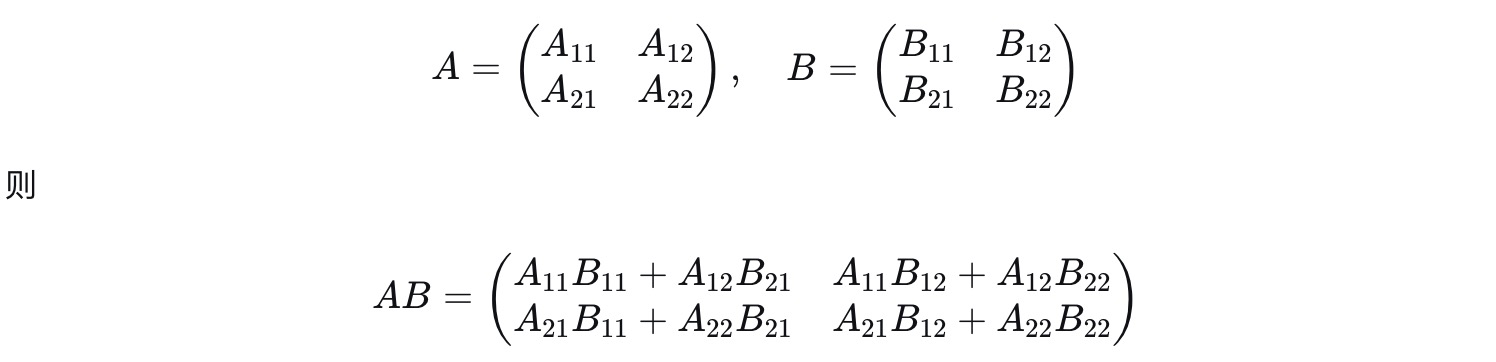
注: "所有子块之间的相乘都必须有意义"
3.分块矩阵的转置矩阵
分块矩阵的转置需要完成两个操作:
a.对整个块结构进行转置(就像普通矩阵一样, 行变列, 列变行)
b.对每一个子块再进行转置
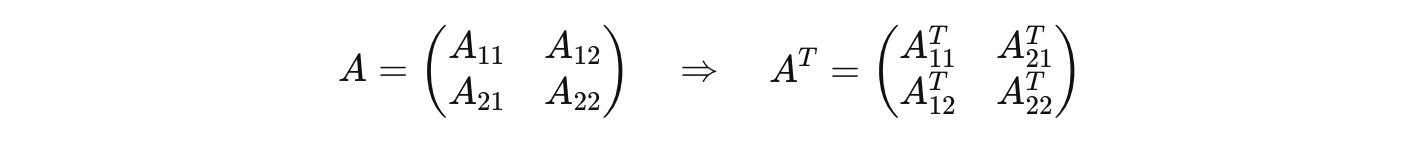
4.2*2分块矩阵的逆矩阵
a.2 * 2对称分块矩阵
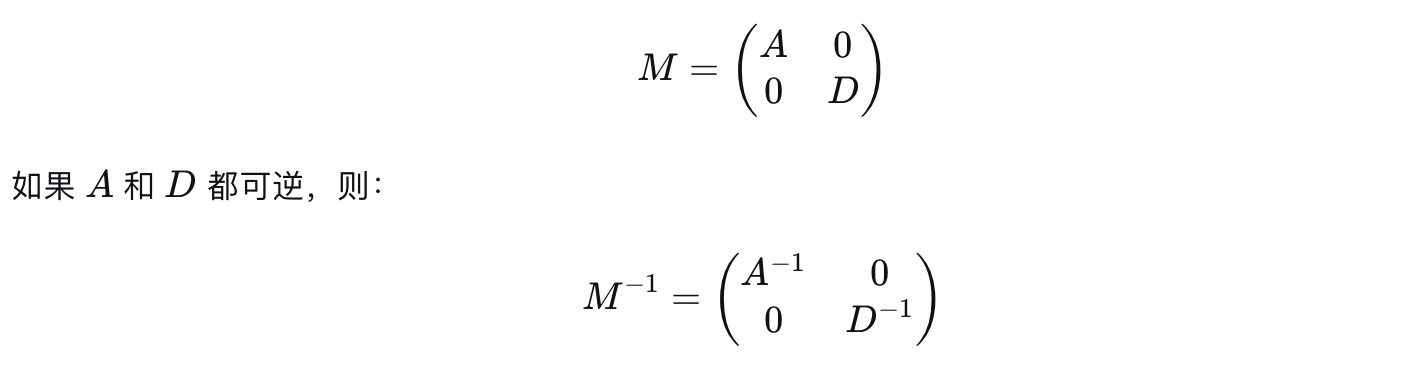
b.对角线元素都是1, 上或下三角矩阵

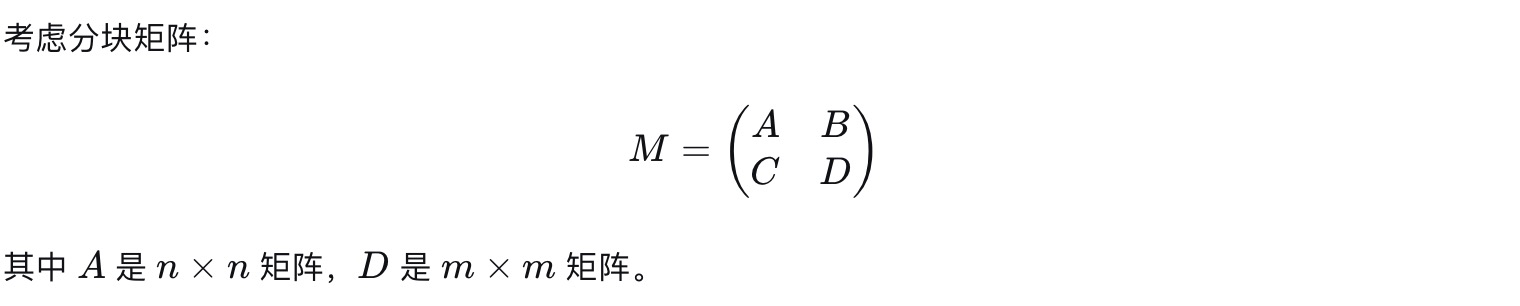
1).LDU分解推导
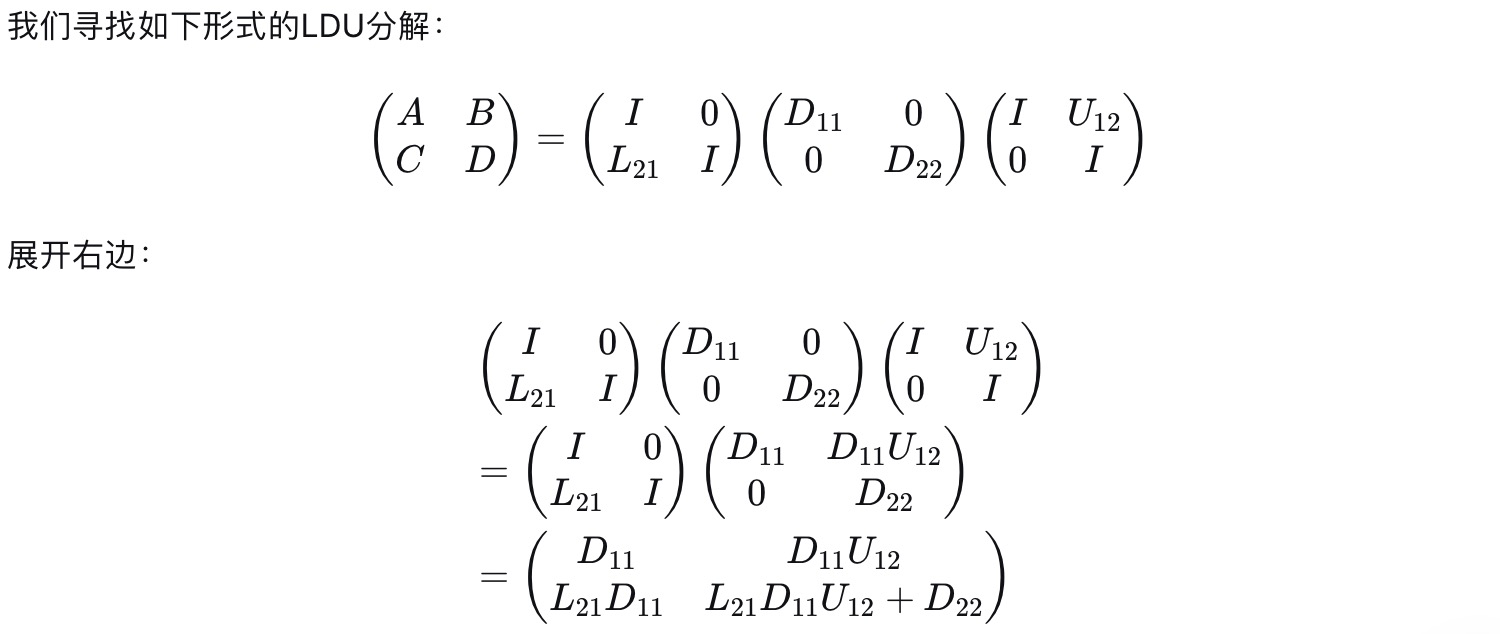

2).求逆矩阵
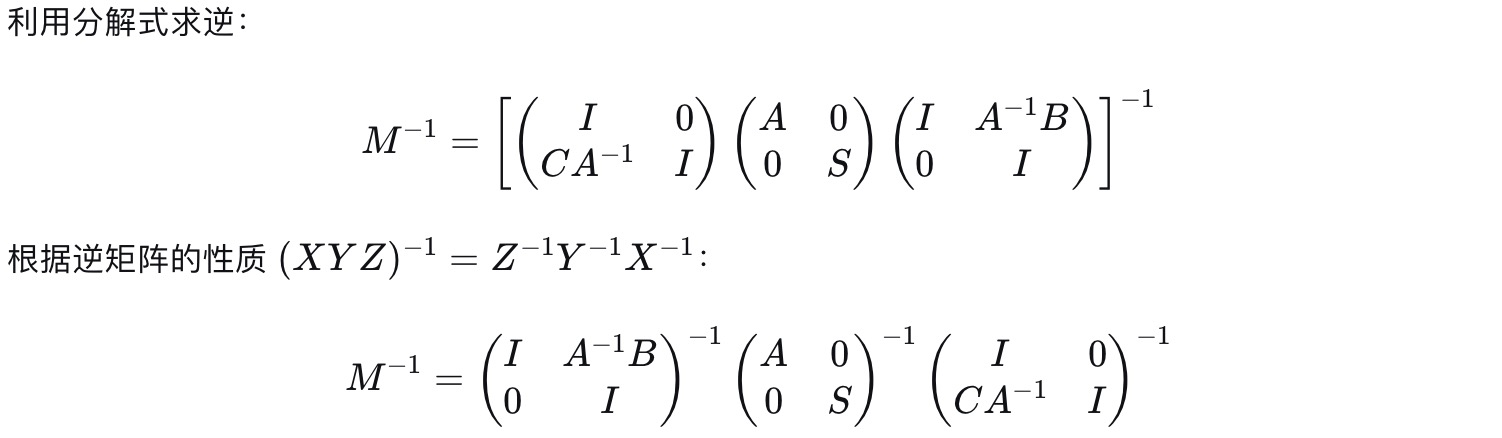
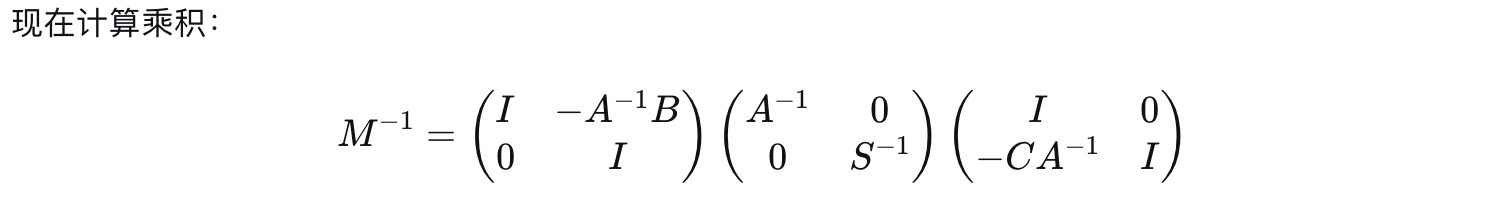

















 2108
2108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









