









 本文介绍了一种在配对数据稀缺情况下,通过分离2D图像和法线向量的建模,利用半监督方法和可选择的残差连接来提升从2D图像到法线预测的模型。研究者提出了一种创新的训练策略,允许在编码器和解码器间灵活使用残差,以减少对大量配对数据的依赖。
本文介绍了一种在配对数据稀缺情况下,通过分离2D图像和法线向量的建模,利用半监督方法和可选择的残差连接来提升从2D图像到法线预测的模型。研究者提出了一种创新的训练策略,允许在编码器和解码器间灵活使用残差,以减少对大量配对数据的依赖。
标题:Cross-modal Deep Face Normals with Deactivable Skip Connections
链接:https://arxiv.org/pdf/2003.09691
这篇文章主要讲的是如何在配对数据很少的情况下学习从2D图像中提取法线信息。
作者提到,一般情况下做这个任务都是将2D编码器和法线解码器连在一起,但这通常要求大量的配对数据来训练,而这目前来说是不现实的。之前有人尝试通过生成新图片来构造成对的数据,而这篇文章就提到了另一种方案,就是直接对两个模态分别建模,再学习如何转化。简单来说就是将图片和法向量映射到同一个隐空间,从而学习图像到法线的转换。
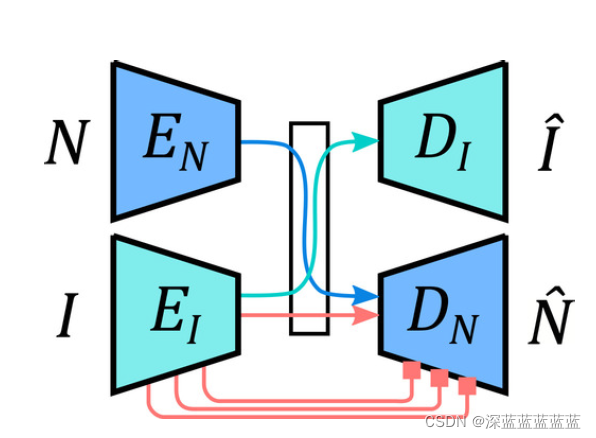
具体的方案其实是半监督的,因为也用到了成对的数据,但更多的是用的不成对的数据。总的来说训练流程很简单就是法线编码器EN+法线解码器DN,图像编码器EI+图像解码器DI,图像编码器EI+法线解码器DN,这三个任务分别用对应的数据训练即可。
只不过为了提升模型的效果,作者又提出了一个在EI和DN之间做残差连接的方式。
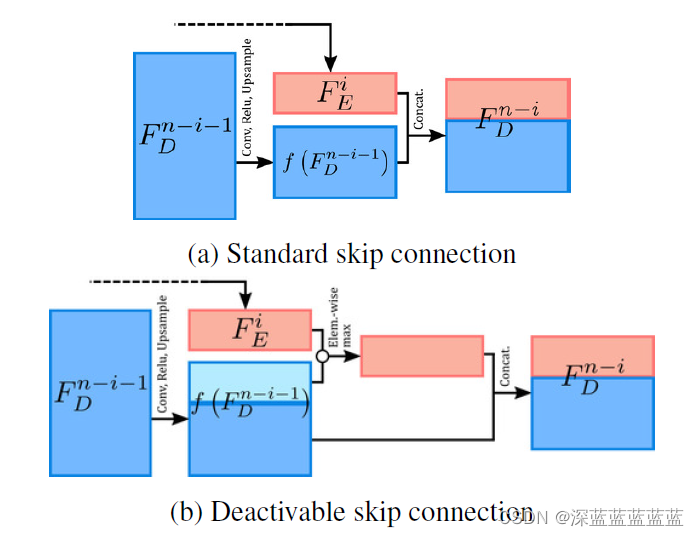
作者本来打算直接用resnet里的残差连接,但是由于如果想要在EI和DN之间加残差链接的话,那EI和DI,EN和DN之间就也得加残差连接(对此表示怀疑,直接弄个单位矩阵进去不行吗)。但如果在auto encoder上加残差连接的话,那auto encoder就没有意义了,因为信息可以直接从残差传过去。因此作者想了一个方法,就是让原来的前向传播分为两路,一路正常传播,一路和残差连接,这样当我们不需要残差的时候就直接关闭掉这一路就完事了,模型依旧可以正常的向前传播。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









