







目录
一、 爬虫是啥?先来了解一下基本概念
1. 爬虫:互联网上的“数据挖掘机”
2. 爬虫的工作流程:像侦探一样抽丝剥茧
3. Python爬虫利器:有了这些,事半功倍!
二、 磨刀不误砍柴工:环境准备走起!
1. 安装Python:没有Python,一切白搭!
2. 安装必要库:一键安装,解放双手!
三、 撸起袖子就是干:第一个爬虫脚本诞生!
1. 完整代码示例:麻雀虽小,五脏俱全!
2. 代码逐行解读:妈妈再也不用担心我的学习!
1)发送HTTP请求:向目标网站Say Hello!
2)检查请求状态:确认握手成功!
3)解析HTML数据:把网页变成“结构化数据”!
4)提取网页内容:找到我们想要的信息!
5)打印结果:大功告成,展示战果!
四、 让爬虫更上一层楼:功能升级,效率翻倍!
1. 添加请求头:伪装成浏览器,骗过反爬虫!
2. 控制爬取频率:做个有素质的爬虫!
3. 保存数据:把爬到的宝贝存起来!
五、 进阶之路:应对复杂网页,挑战更高难度!
1. 动态加载网页:用Selenium搞定JS渲染!
2. 爬取图片或文件:下载小姐姐,咳咳,是图片!
六、 爬虫江湖的规矩:安全第一,切记切记!
1. 遵守法律和道德:做一个遵纪守法的好公民!
2. 处理异常:让你的爬虫更健壮!
3. 避免过于频繁的请求:温柔一点,别把网站搞崩了!
网络安全工程师们,是不是经常需要从各种网站上搜集情报、分析数据?手动复制粘贴?OUT啦!网页爬虫技术,让你效率翻倍!今天,我们就用Python,手把手教你写一个简单的爬虫,从此告别手动时代!
在本文中,我们将从爬虫的基本概念开始,一步步带你实现一个可以抓取网页内容的爬虫,还会教你如何优化爬虫,应对各种复杂的网络环境。准备好了吗?Let’s go!
一、 爬虫是啥?先来了解一下基本概念
1. 爬虫:互联网上的“数据挖掘机”
爬虫 (Web Crawler),也叫网络蜘蛛,是一种自动化程序,它可以模拟人类访问网页的行为,自动抓取互联网上的信息。想象一下,你有一台可以自动浏览网页、复制粘贴的机器人,这就是爬虫!
2. 爬虫的工作流程:像侦探一样抽丝剥茧
一个典型的爬虫任务,就像侦探破案一样,需要经过以下几个步骤:
- 发送请求 (Request):向目标网站发送HTTP请求,就像侦探敲门,请求进入调查。
- 解析数据 (Parse):对获取到的HTML进行解析,提取我们需要的数据,就像侦探分析线索,找到关键信息。
- 存储数据 (Store):将提取到的数据保存到文件或数据库中,便于后续处理,就像侦探整理证据,准备结案报告。
3. Python爬虫利器:有了这些,事半功倍!
Python之所以成为爬虫首选语言,是因为它拥有丰富的第三方库,能大大简化爬虫开发:
**requests**:发送HTTP请求,获取网页内容,就像给网站发消息。**BeautifulSoup**:解析HTML或XML数据,提取特定内容,就像一把锋利的刀,可以从网页中提取你想要的信息。**re**(正则表达式):对复杂文本模式进行匹配和提取,就像一个高级搜索工具,可以根据你的需求,精准地找到目标信息。**pandas**:对数据进行清洗和分析,就像一个数据处理专家,可以帮你把杂乱的数据整理得井井有条。
二、 磨刀不误砍柴工:环境准备走起!
1. 安装Python:没有Python,一切白搭!
首先,你需要确保你的电脑上已经安装了Python(推荐3.7+版本)。没有安装?赶紧去Python官网下载安装包,一键安装,so easy!
2. 安装必要库:一键安装,解放双手!
打开你的命令行终端,输入以下命令,安装我们需要的Python库:
pip install requests beautifulsoup4
**requests**:负责发送HTTP请求,与网站建立连接。**beautifulsoup4**:负责解析HTML数据,提取网页内容。
三、 撸起袖子就是干:第一个爬虫脚本诞生!
接下来,我们来写一个简单的爬虫,它可以抓取指定网页的标题和正文内容。
1. 完整代码示例:麻雀虽小,五脏俱全!
import requests
from bs4 import BeautifulSoup
def simple_crawler(url):
try:
# 1. 发送请求
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
# 2. 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 3. 提取标题和段落内容
title = soup.find('title').text # 获取网页标题
paragraphs = soup.find_all('p') # 获取所有段落内容
print(f"网页标题: {title}
")
print("网页内容:")
for p in paragraphs:
print(p.text)
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
# 示例网址
url = "https://example.com" # 替换为你想要爬取的网页地址
simple_crawler(url)
2. 代码逐行解读:妈妈再也不用担心我的学习!
别慌,我们来一行一行地解读这段代码,让你彻底明白它的原理:
1)发送HTTP请求:向目标网站Say Hello!
response = requests.get(url)
requests.get(url):使用requests库的get()方法,向目标网址发送一个GET请求,就像你用浏览器打开一个网页一样。response:返回的response对象包含了服务器返回的所有信息,包括网页的HTML源代码、HTTP状态码等等。
2)检查请求状态:确认握手成功!
response.raise_for_status()
response.raise_for_status():这是一个非常重要的步骤!它会检查HTTP请求是否成功。如果返回的状态码不是200(表示成功),就会抛出一个异常,提醒你请求出错了。比如,404表示页面不存在,500表示服务器内部错误。
3)解析HTML数据:把网页变成“结构化数据”!
soup = BeautifulSoup(response.text, 'html.parser')
BeautifulSoup(response.text, 'html.parser'):BeautifulSoup是一个强大的HTML解析库,它可以将HTML文档转换成一个树形结构,方便我们提取数据。response.text:网页的HTML源代码。'html.parser':指定使用Python内置的HTML解析器。
4)提取网页内容:找到我们想要的信息!
title = soup.find('title').text
paragraphs = soup.find_all('p')
soup.find('title'):在HTML文档中查找第一个<title>标签,也就是网页的标题。.text:获取标签中的文本内容。soup.find_all('p'):在HTML文档中查找所有的<p>标签,也就是网页的段落。返回的是一个列表,包含了所有的段落标签。
5)打印结果:大功告成,展示战果!
for p in paragraphs:
print(p.text)
- 遍历提取到的段落内容,并打印每个段落的文本。
四、 让爬虫更上一层楼:功能升级,效率翻倍!
1. 添加请求头:伪装成浏览器,骗过反爬虫!
有些网站会检测爬虫程序,并阻止访问。为了更好地模拟浏览器行为,我们可以添加请求头:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers=headers)
User-Agent:这是最重要的请求头之一,它告诉网站服务器,你使用的是什么浏览器。上面的代码模拟的是Chrome浏览器。
2. 控制爬取频率:做个有素质的爬虫!
为了避免给目标网站造成过大的压力,我们可以控制爬取频率,每次请求后暂停一段时间:
import time
def delay_request(url):
response = requests.get(url)
time.sleep(2) # 等待 2 秒
return response
time.sleep(2):让程序暂停2秒钟。
3. 保存数据:把爬到的宝贝存起来!
爬取到的数据,当然要保存下来,方便后续分析。我们可以将数据保存到文件或数据库中。
保存到文件:
with open("output.txt", "w", encoding="utf-8") as f:
f.write(f"标题: {title}
")
for p in paragraphs:
f.write(p.text + "
")
保存到CSV文件:
import csv
with open("output.csv", "w", newline="", encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["段落内容"])
for p in paragraphs:
writer.writerow([p.text])
五、 进阶之路:应对复杂网页,挑战更高难度!
1. 动态加载网页:用Selenium搞定JS渲染!
有些网站的内容是通过JavaScript动态加载的,requests 无法获取完整的页面内容。这时,我们可以使用 selenium 或 playwright 等工具来模拟浏览器行为,获取动态加载的内容。
示例(使用selenium):
from selenium import webdriver
url = "https://example.com"
# 配置WebDriver
driver = webdriver.Chrome()
driver.get(url)
# 获取动态加载的内容
html = driver.page_source
print(html)
# 关闭浏览器
driver.quit()
2. 爬取图片或文件:下载小姐姐,咳咳,是图片!
import os
# 下载图片
img_url = "https://example.com/image.jpg"
response = requests.get(img_url)
# 保存图片
with open("image.jpg", "wb") as f:
f.write(response.content)
六、 爬虫江湖的规矩:安全第一,切记切记!
1. 遵守法律和道德:做一个遵纪守法的好公民!
- 避免违反法律:确保你的爬取行为符合目标网站的使用条款,不要爬取未经授权的敏感数据。
- 尊重 robots.txt 文件:通过
robots.txt文件了解目标网站的爬取限制,不要爬取禁止爬取的内容。
2. 处理异常:让你的爬虫更健壮!
网络环境复杂多变,爬虫程序难免会遇到各种异常情况。为了让你的爬虫更健壮,我们需要添加异常处理逻辑:
try:
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
3. 避免过于频繁的请求:温柔一点,别把网站搞崩了!
过于频繁的请求,可能会给目标网站造成过大的压力,甚至导致网站崩溃。为了避免这种情况,我们可以设置延时或者使用代理IP:
proxies = {
"http": "http://123.45.67.89:8080",
"https": "http://123.45.67.89:8080"
}
response = requests.get(url, proxies=proxies)

网络安全学习路线&学习资源
网络安全的知识多而杂,怎么科学合理安排?
下面给大家总结了一套适用于网安零基础的学习路线,应届生和转行人员都适用,学完保底6k!就算你底子差,如果能趁着网安良好的发展势头不断学习,日后跳槽大厂、拿到百万年薪也不是不可能!
初级网工
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
零基础入门,建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习; 搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime; ·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完; ·用Python编写漏洞的exp,然后写一个简单的网络爬虫; ·PHP基本语法学习并书写一个简单的博客系统; 熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选); ·了解Bootstrap的布局或者CSS。
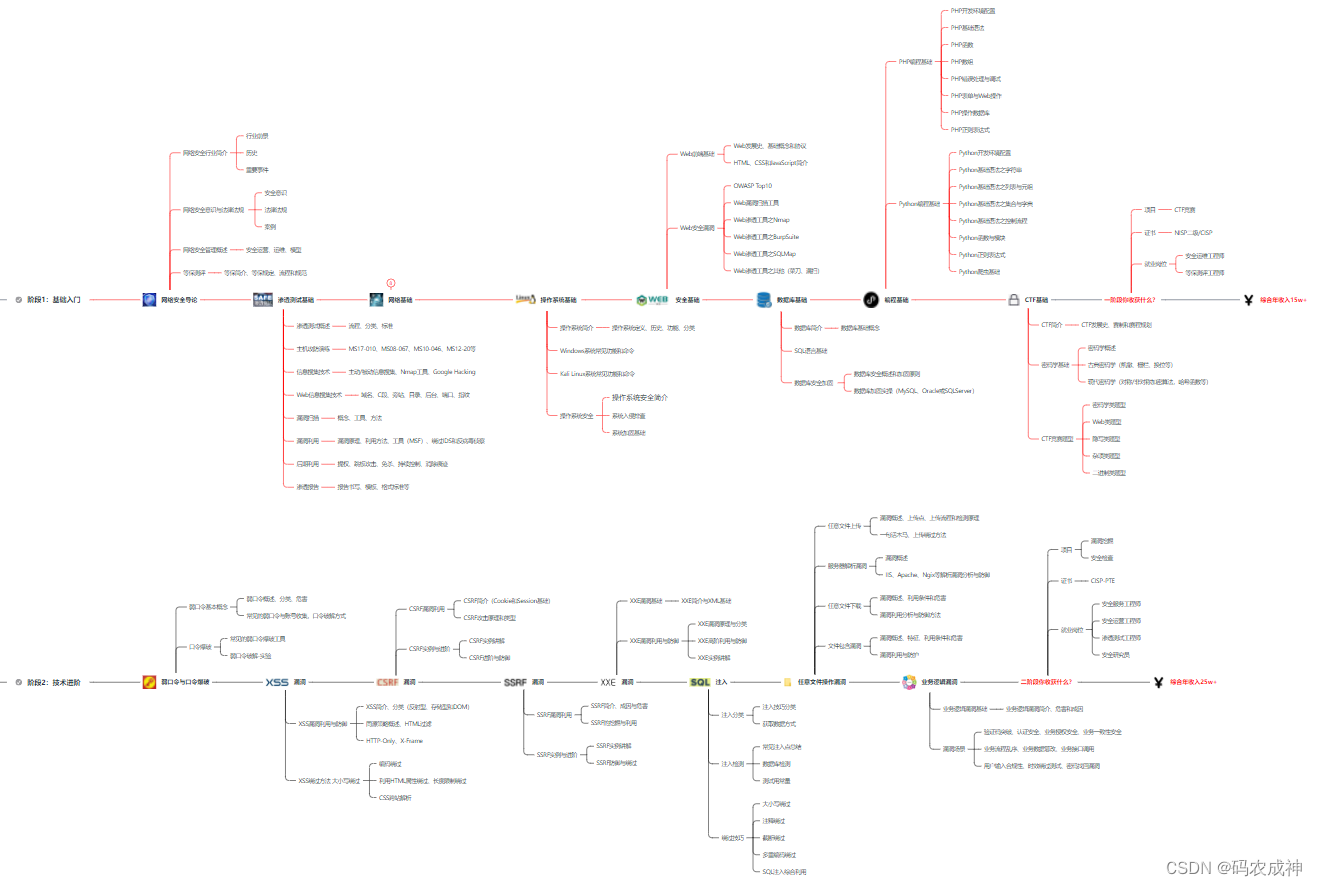
8、超级网工
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,贴一个大概的路线。感兴趣的童鞋可以研究一下,不懂得地方可以【点这里】加我耗油,跟我学习交流一下。
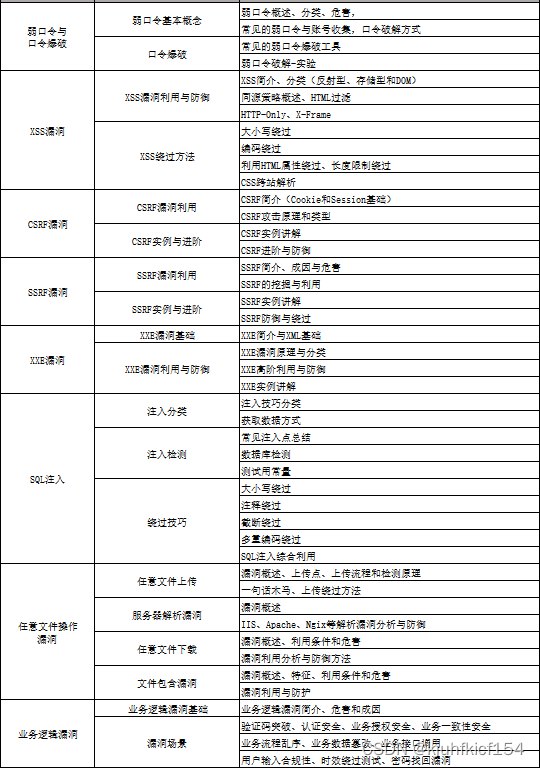
网络安全工程师企业级学习路线
如图片过大被平台压缩导致看不清的话,可以【点这里】加我耗油发给你,大家也可以一起学习交流一下。
一些我自己买的、其他平台白嫖不到的视频教程:

需要的话可以扫描下方卡片加我耗油发给你(都是无偿分享的),大家也可以一起学习交流一下。
网络安全学习路线&学习资源
结语
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失!!!

















 2316
2316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









