









标题:3D Morphable Face Models—Past, Present, and Future
链接:https://arxiv.org/pdf/1909.01815
这是一篇关于3DMM(3D Morphable Face Model)的综述,概述了过去20年间这个领域的发展概况。
1. 介绍
3DMM自从提出开始已经有20多年的历史,当年提出的时候收获了论文影响力奖,而且效果视频在油管也曾经登上过热门。近两年,随着深度学习的发展,3DMM又开始重回人们的事业,很多研究者开始进一步挖掘3DMM在现如今各种任务中的应用。
1.1 定义
3DMM是一个用于生成面部形状和外观的模型,它基于两个关键想法:
1. 所有的人脸都可以构建密集的点对点的对应关系,也即一个人的鼻尖可以对应到另一个人的鼻尖,一个人的嘴角也可以对应到另一个人的嘴角。基于这个想法,我们就可以通过线性组合一些人脸基底(一些典型的人脸)来描述一个人脸。
2. 人脸的形状和颜色需要和外部参数解耦,外部参数包括相机内参和光照。
Morphable Model(MM)通常会用到一些统计模型来描述人脸的分布,而在最原始的文章中使用的就是PCA。当然后续也有人套用了其他的模型。
1.2 历史
如何设计一个视觉系统来描述来自同一类物体不同图片并用于其他视觉任务,这是3DMM在设计之初要解决的问题(说人话,就是比如我们要有一个视觉系统专门给人脸建模,但每个人长得都不一样,甚至同一个人照片之间的光照,人的表情也都不一样,这就会给系统带来很大的困难。所以这里就是要找到一种方式可以将所有人脸照片都囊括到同一种表示方式,这样就可以很简单的用于其他视觉任务了。)。但从2D图形到3D模型的重建必然是病态问题,因此3DMM的想法就是最大化的利用类别信息的先验(也就是说,既然我们都知道要模仿的是人脸,那就把所有人脸共性的部分都事先提取出来,省的模型再去花精力学习)。3DMM就是可以自动化的抽取这样的先验。
人脸表示事实上已经有了很久的研究,在3DMM之前就有一套名为Eigenfaces的方法被提出来了。想法很简单,就是把人脸图片看做一个很大的向量,然后在所有图片上做PCA来降维,从而表示不同人脸。但一大问题是Eigenface要求光照和姿势不能变(因为所有特征都混在一起了,因此单独光照和姿势变肯定会全都影响),而且当微调特征向量的参数时,面部的变化是不连续的,也就意味着Eigenface没有很好的解缠面部特征。
在此之后,有人提出了基于2D面部形状(shape)的Eigendecomposition,也就是试图将形状信息从eigenface中解缠。为了做到这一点,他们使用了200个landmark用于对齐人脸(Eigenfaces只用了一个)。再然后有人进一步解缠了外貌(appearance),效果也很不错。除此以外,还有人尝试使用粒子流算法(optic-flow algorithm)来描述面部形状的变化。
在之后又有人在这基础上让模型可以捕捉基于姿态的变化,甚至应用到了别的类别,例如汽车。但这些方法通常非常复杂,需要对每个姿态和光照的小区间分别建模,就很不实用。但与此同时,在计算机图形学中的发展显示,其实姿势和光找事很简单就能建模的,因此3DMM就借用了计算机图形学中的人脸模型来帮助表示人脸了。因此,3DMM最大的贡献就是两点:1.将计算机图形学中的人脸模型应用于人脸表示 2.使用了analysis-by-synthesis来构建2D和3D之间的连接(所谓analysis-by-synthesis就是说我们先分析输入的2D人脸,找出他的各种参数(analysis),然后基于参数模拟出3D模型后渲染回2D图像(synthesis),再将渲染好的图像和原始2D人脸做对比,从而学到更好的参数)。另外,其实3DMM很大程度上借鉴了2DMM模型。
2DMM和3DMM最大的特色是脸和脸之间有密集的的点对点对应关系,而不仅仅是几个landmark对应。在最原始的3DMM中,是用粒子流来描述这一对应关系的,然后使用了经典的渲染流程对3D模型进行渲染。在analysis-by-synthesis流程中,3DMM事实上是需要很大计算量的,一方面是因为shape camera和illumination-albedo造成的病态问题(个人理解就是因为相机总是只能拍摄到一个视角,因此几乎不可能还原整体的形状。另外,光照和纹理之间经常会有难以解耦的部分,比如黑色到底是皮肤是黑的还是阴影。)。另一方面是因为优化本身也很容易陷入局部最优。
在最原始的3DMM中,不像我们现如今都是用基于三角网格的算法,那时候使用的是粒子流和多尺寸算法。当时的人脸 3D ground truth是由3D相机将面部画在一个3D圆柱体表面进行记录的,然后在实验时只需将圆柱体表面摊平,就将问题回归到了2D图像问题。是后续的算法才将这个问题真正引入到了3D空间。
在过去的年,3DMM不仅仅被用于面部,还被用于人体全身和一些小器官,例如耳朵,手,甚至小动物和汽车。在这篇综述中主要还是考虑应用在面部的情况。
当3DMM刚发明的时候,实验室之间还很少开源自己的数据和算法,直到10年后(2009年)第一个可用的3DMM才开源,而近10年,越来越多的3DMM模型和数据被分享了出来,这篇文章后续也会整理这些分享出的资源。
1.3 文章结构
第2章:如何收集3D数据
第3章:如何对3D形状和面貌建模
第4章:如何通过图形学将3D模型渲染成2D图像
第5章:介绍一些3DMM的经典应用
第6章:介绍3DMM在深度学习中的应用和发展
第7章:介绍过去20年间3DMM都有哪些用途
第8章:畅想未来10到20年间3DMM还会有什么样的用途和发展
2. 人脸数据收集
由于3DMM通常都需要真实世界中物体的3D ground truth,因此这部分会主要讨论如何在受控制的情况下收集3D数据(当然,3D ground truth并不总是必须的,现在有很多模型只使用2D图形就可以训练3DMM了)。
2.1 形状数据收集
现在其实没多少人考虑怎么表示人脸形状,因为大部分人都是直接使用三角网格。只有很少的例子使用了别的方法,比如cylindrical(就是3DMM最初算法用的那个方式,将人脸画到一个圆柱体的侧面),orthographic depth map(这个方法和前面那个都无法保证脸与脸之间的密集对应关系),per-vertex surface normal,volumetric orientation fields和signed distance function(最后两个方式是最近才研发的)。
2.1.1 几何法(Geometric Methods)
用几何方法来估计形状的3D坐标通常分为两类,要么就是从多个视角看同一个点,要么是看多个不同的投影方式。我们称那些对场景发射光线或者其他信号的方法为主动方法,而剩下的就称之为被动方法。
主动方法,在比较早期的时候,主动方法是唯一获得高精度3D形状数据的方法:
1.激光扫描仪(Laser scanners):就是通过激光发射器的内参和反射图案来还原物体的形状。比如激光发射器可以直接发射一条直线到物体上,由于物体本身有形状,即不是平的,那么位于另一角度的接收器就可以读出物体表面对应的形状了。但这主要的问题在于太慢,就算是最好的机子也得让人坐上几秒钟才能还原一个画面。
2.结构光系统(Structured light scanners):和激光扫描仪其实挺像的,只不过结构光是直接让投影仪发射上百万条光,从而大大的加速扫描速度。
3.飞行时间传感器(Time-of-Flight sensors):简单来说就是通过计算光子的飞行时间从而判断物体的形状,这个是现在最新的方法,但与之前的两个方法有一个共同的缺点就是无法同时获得颜色信息。
被动方法:
1.多视角拍摄:最大的优点在于便于获得,甚至只需要手机就可以拍摄,可以很简单的获得多角度同时拍摄结果(比如搞个架子放上几个相机,同时按快门),而且不需要额外获得颜色信息(相比于主动方法来说)。一点点的不足就在于通常几个相机不能离得太近,从而导致比较占地方。
主被动混合法:
1.主动多视角拍摄,虽然是从多视角拍摄,但是却通过主动地改变物体的纹理投影来辅助形状的重构,这种方法被用于Intel® RealSenseTM D435 camera。
2.1.2 测光法(Photometric Methods)
测光法简而言之就是先测定表面的方向,然后将之整合成为物体的形状。因此最主要的问题就在于如何为物体表面选择合适的反射属性并获得足够多的测量结果。相比于几何法,测光法可以提供更精细的细节,并且不要求物体之间严格对应,但有时候会由于遇到低频(不常见)的小细节而导致建模错误(比如本来固定的是三个光源,但有个痘印三个光源全都照不到,那也就无法复原了)。比如光度立体法(Photometric stereo),就是在固定相机视角的情况下,从至少三个方向上分别向被测物体打光,这里假设打的光都是平行光,且物体表面都是漫反射(Lambertian reflectance,朗伯反射),因此在我们知道光的入射角,反射角,和反射值(光照出来的颜色)的情况下就可以通过列式求得物体表面的法向量和物体的原色(albedo)了。最后再通过计算物体表面的梯度来还原出物体的形状。后续又有人提出了可以再不同光源环境下和不同反射条件下还原形状的算法,就不做赘述了。
2.1.3 混合法(Hybrid Methods)
混合法声称是结合了测光法和几何法的优点。他既避免了测光法中的无法复原低频细节的问题,也进一步加强了几何法中对高频细节的描述。比如有人将低频的位置信息和高频的法向量信息结合,将结构光和光度立体法结合,将结构光和梯度照明结合,将多视角拍摄和SFS(shape-from-shading)结合。。。
2.2 外貌数据收集
在3DMM中外貌数据和形状数据同样重要,因为这为模型提供了纹理信息。不同于形状数据,大多都使用同一套三角网格系统,外貌数据的表示方式有非常多种。但从理论上来讲,其实外貌数据是可以直接按照人脸顶点的方式来存储的,也即每个顶点给一个颜色作为这个顶点附近的纹理。但往往我们获取外貌数据的时候存在的问题是面部的自我遮挡,也即,当我从侧面看人脸的时候,必然有一半脸是看不到的,即使我从正面看,面颊两边也看不太清。比较野的路子就是说我直接从野外数据训练一套模型,用来补全看不到的部分,这也不是说不行,但是其实很多情况下为了研究,我们是可以获得多视角图的。所以一般最常用的方式就是说通过多个角度的照片来联合还原整个人脸的原色(albedo)。当然也有进阶方案,就是说将人脸的原色和光照的影响(光的颜色和光产生的阴影)分离开来,来消除光照的影响。
2.3 面部特殊区域数据收集
面部有一些区域是不符合我们在2.2中做的假设的(例如漫反射假设):
瞳孔和角膜:都是晶体结构,因此会产生折射和镜面反射,有人借用了shape-from-specularity算法来处理。
牙齿:明显材质和排列都和面部不同
头发:更是违反了我们对面部是连续平面的假设(就是说头发会到处乱动)。研究非常多,有人将头发比作一个平面来建模,也有人直接对头发做动作建模。
舌头,下颌和颅骨:很多情况下是根本看不到的。通常需要专门的系统来处理,比如计算机断层扫描(Computer Tomography,CT),核磁共振图( Magnetic Resonance Imaging,MRI), 电磁造影(Electromagnetic Articulography ,EMA)。
嘴唇,眼皮:这些地方的运动模式也通常是难以被通用模型捕捉到的,可能需要单独建模。
2.4 动态数据收集
从历史上来看,3DMM模型大都只关注面部的静态,比如不同人的无表情数据,又或者有一些也考虑了一些离散的情绪数据,但大都没有考虑到表情到表情之间的渐变,也即面部的动态化。但现在慢慢的有一些模型开始对面部引入了时间模态,因此捕捉动态的人脸数据也成为了必须。虽然主动方法也有人尝试,但是最主流的还是通过被动的方式来捕捉动态人脸。一个是因为这样的数据比较好获取,因为只需要普通的相机就好了,另一个是因为被动方法可以同时获得形状和纹理,且是已经对齐了的,所以就不需要后续再建立形状和纹理的对应关系了。比较成熟的商业解决方案包括Di4D,3dMD和Medusa system。
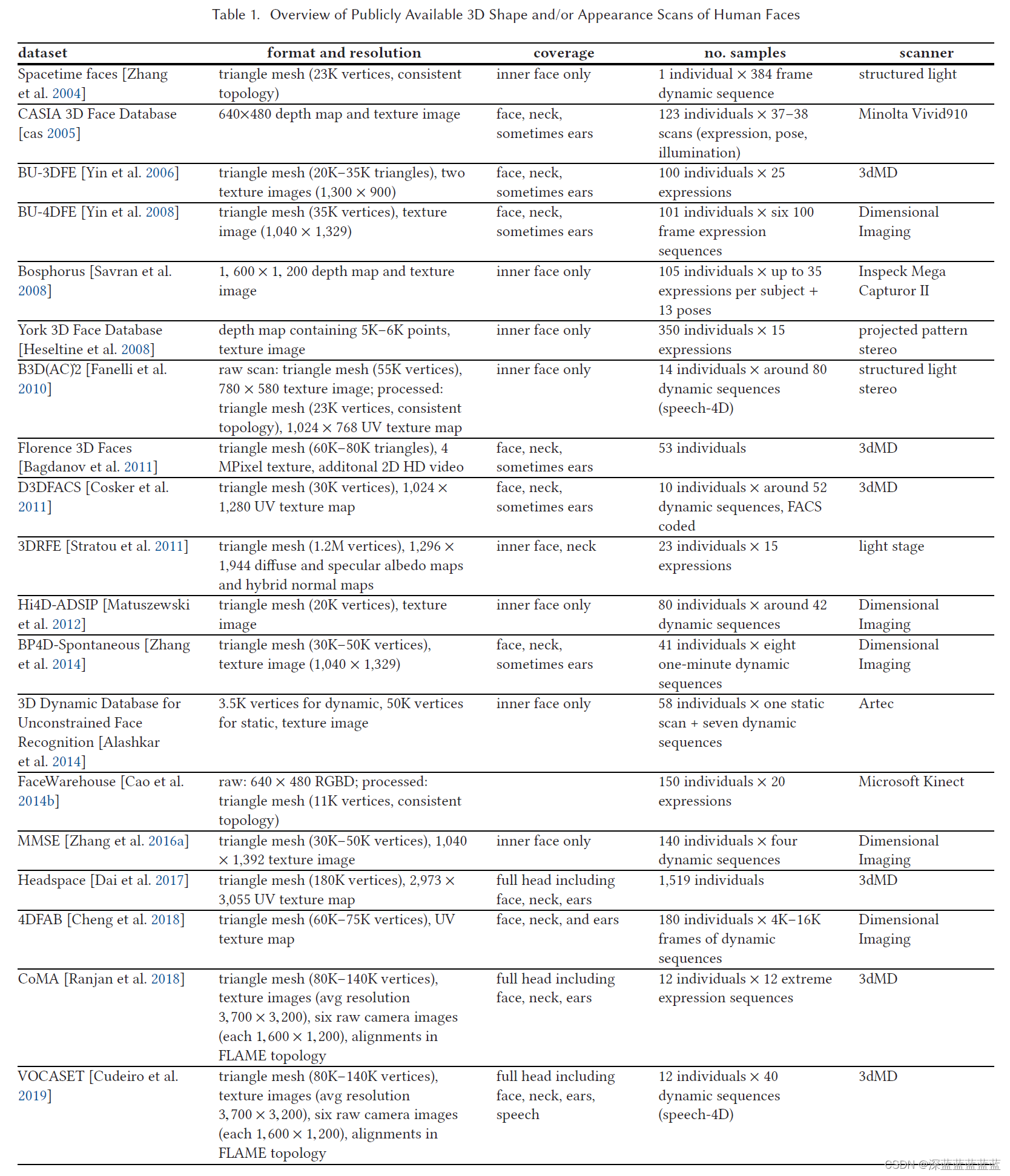
2.5 开源的人脸数据库
2.6 面临的挑战
主要分为三个部分:
a.数据不足
现如今用于训练3DMM的数据质量远远地落后于业界能达到的标准。当然,现在3DMM生成的图像质量比用于训练的数据质量还要低,所以这其实不是主要矛盾。主要矛盾是开源的数据太少。现如今开源的人脸3D数据大都是形状数据,几乎就没有人开源外貌数据,唯一开源的外貌数据里就只有23个人。这一方面是因为捕捉外貌数据的机器比较昂贵而且对实验室的环境要求很高,另一方面是因为捕捉所需的时间比较长而且有强光,不适用于小孩和老人。所以这就依赖于捕捉设备的进一步发展了。
b.数据集质量问题
首先,到底多少数据才够用,这没人给出定论。另外,很多数据集考虑到了表情,但受试者通常没有受过相应的训练,无法精确的做出相应的表情,因此数据集本身可能对表情的表达就并不准确。再比如,很多数据集里对人类种族的表达是不充分的,都是白人居多,黄种人较少,黑人由于肤色原因本身就比较有挑战性所以也比较少。由于这些客观存在的问题,那我们是不是可以考虑就直接基于2D数据集来生成一些训练数据呢?
c.隐私权问题
主要就是各种各样的隐私权,肖像权,类似的杂七杂八的问题。因为3D扫描出来的数据是非常精确的,很容易被用于非法用途,因此这方面可能还需要法律方面的人士给予帮助。
3. 建模
3DMM主要的目的就是针对数据化的3D人脸进行建模,以捕捉不同人脸之间的区别。主要分为三个方面:
a.形状模型(shape model):身份上的区别,即不同人之间外貌的固有区别。有两种建模方式,一种是全局模型,即整个脸都用一套模型。另一种是局部模型,也就是将脸划分成不同的区域,对每个区域分别建模。
b.表情模型(expression model):表情之间的区别,即对同一个人不同表情之间建模。有加性模型,也有乘性模型,最新的还有人用非线性模型。
c.外貌模型(appearance model):用于对外貌(面部纹理)和光照建模
最早的3DMM模型就已经包含了这三个部分,使用的是3D扫描数据。但后来也有人发现用2D图片也可以做约束,只需要建立脸与脸之间的对应关系即可。
3.1 形状模型
为了对形状建模,首先要构建一套度量标准,因此一般都会先将3D采集点预处理一下,用同一套模板来拟合数据库中的3D数据,从而建立不同3D扫描间的对应关系。一般来说,3DMM对形状的定义是:移除掉了平移,旋转信息之后的人脸地理信息(简单来说就是刚性结构的地理信息)。这里不包含缩放是因为缩放一般在采集数据的时候就处理完了。在这一小节我们默认所有人的表情是统一的,只有样貌会影响形状。
3.1.1 全局模型
在最初的3DMM中就是使用全局模型对形状建模的。简单来说就是直接在训练数据上做PCA,然后从协方差矩阵中提取最显著的几个特征向量来表示人脸之间形状的不同。另外,有人提出其实经由PCA降维后的形状特征是符合多维高斯分布的,因此从原点到指定形状参数的距离就是马氏距离(mahalanobis distance)。
在最初的3DMM中只是用了200个人的数据,但后续又有人将同样的算法应用于更大的数据库,从而获得了更好的效果,这也证明了原始方法的有效性。
另外,有人观察到如果加大指定人脸的形状参数和平均脸参数之间的距离的话,会让指定人脸的特征越发显著,就有点像那种夸张的漫画脸一样。在后续的研究中也有人发现指定人脸的形状参数最好是和平均脸保持一段距离,这样可以让人脸的特征保存的更好。
再后来还有人提出了非线性的形状特征空间。
3.1.2 局部模型
局部模型就是为了处理全局模型无法还原细节的问题。通常用于提升像是眼镜盒鼻子这一类区域的还原度。优点是还原度更高,但缺点是面部的表示向量变得不再紧凑(因为需要不同的向量表示不同的区域,所以维度会提高)。
最一开始的方式是直接手动选定一些区域,然后分别对这些区域建模。然后有人提出可以用自动化的方式直接在人脸网格上学习语义分割,从而划分区域。再之后还有人试图使用金字塔式的分层模型来对不同分辨率的人脸建模,进而模拟不同细粒度的特征。
同时也有人提出从PCA角度入手,比如有人借助一些局部的约束提出了稀疏的PCA。也有人试图针对采样的区域学习一套形变组件的字典。也有人将人体骨骼结构作为局部形变模型的约束来分别学习刚性和非刚性形变。
3.2 表情模型
表情其实是可以用上述提到的那些形状模型直接建模的,但这一章我们更多的考虑的是如何解耦形状和表情。而这些模型可以分为三类:加性,乘性,非线性。
3.2.1 加性模型
加性模型很简单,就是直接在中性脸(不是平均脸,可以理解为某个人没有表情的脸)上加上一个表情偏移量即可获得目标情绪的脸。值得一提的是,用于表示表情空间的基向量是可以理解成一个数据驱动的融合变形模型(blendshape model),基向量之间是互相垂直且没有交叉语义的(融合变形模型并不要求基向量互相垂直)。
3.2.2 乘性模型
乘性模型也即将表情和形状以相乘的方式结合,形成多元线性模型。对于乘性模型的好处文章中没有具体说明,但经过我个人的调查认为乘性模型有利于捕捉面部形状和表情耦合的部分,例如,不是每个人的微笑都是一样的,因此对所有人套用同一套微笑表情是不合适的。
现有的乘性模型的主导方案就是将不同人脸的不同表情的3D数据全部塞到一个tensor里,然后做HOSVD来降维,最后进行训练。但存在的问题是对数据的完备性要求比较高,即所有用到的个体都需要有所有对应的表情数据,这才能放到同一个tensor中计算。当然后面有人提出了一些方案对此进行改进。
3.2.3 非线性模型
比如FLAME就是在线性模型的基础上给下颚添加了关节点做了非线性处理。另外还有人模拟了肌肉的运动,又或者使用GMM来替代了简单的高斯分布,又或者对皱纹进行了多尺度的非线性处理。最近也有很多基于深度学习的非线性模型被提出来了。
3.3 外貌模型
和形状模型类似,外貌模型也可以分成线性和非线性两类。外貌模型是用于描述光照和人脸原色的变化的模型,但现如今大部分3DMM模型没有将这两个分开考虑,而是混为一谈,所以我们就直接称之为对外貌建模。另外,外貌信息通常只有两种存储方式,要么就是和形状信息一致,按顶点存储,要么就是存到UV空间中。
3.3.1 线性顶点模型
简单来说就是在已知人脸形状的情况下,按顶点将图像投影到形状模型上去。当然,直接投影的话会有光照影响,因此有的人是先经过一些计算排除掉光照影响再将计算结果投影上去。还有人是对纹理和表面法线联合建模,用于排除光照影响。
3.3.2 线性纹理空间模型
顶点模型的一大问题就是要求外貌表示和形状表示一一对应,但事实上通常我们获得的外貌表示的分辨率都远远高于形状表示。另外,将外貌映射到纹理空间(也即2D图像)上的好处在于我们可以使用很多图形学算法来对纹理图进行进一步的操作和处理。
在原始的3DMM模型中,纹理图就是被平铺在那个圆柱体的侧面上的图。之后,有人用纹理图给模型加皱纹,还有人通过语义分割来检测皮肤和痣。之后有人提出可以通过UV map序列来获得PCA降维结果。最后还有人研究了不同UV map对建模效果的影响。
3.3.3 非线性模型
一般来说大家都是把外貌的颜色分布考虑成是符合高斯分布的,但后来有人发现其实他不是高斯分布的。因此一个做法就是使用copula component analysis model(与PCA的区别就是各成分之间不需要互相独立)。另外还有一个方法就是使用对抗学习。之后还有人考虑其实人脸的颜色主要是由血红细胞和黑色素形成的,因此直接对血红细胞和黑色素建模不就好了吗。之后又引出了一系列奇奇怪怪的算法。
3.4 形状外貌联合模型
在3DMM出现之前就有人使用这种方式建模了,这个模型的好处在于可以直接建模形状和纹理之间的关系,但问题在于无法后续单独调整形状和模型,而且训练的时候参数更多(因为比起单独的形状模型或纹理模型,联合模型肯定是需要比任一模型有更多参数才能达到类似的效果)难以拟合。但还是有一些人提出了相应的模型。比如使用典型相关分析(canonical correlation analysis)来分析形状和纹理之间,面部器官之间的关系。也有人直接训练了一个autoencoder来同时建模这俩。
3.5 对齐
这里说的对齐就是指不同人脸之间的点对点的对齐,而这一小节要讲的就是怎么对齐。现在有很多方法来做到这一点,而最主流的方式就是直接将一个网格模板变形拟合到每个场景,先借助类似于landmark一样的稀疏点对齐,然后再进行稠密的对齐。
3.5.1 稀疏对齐
简而言之就是基于面部关键点的对齐,最常用的就是landmark,这也为后续的稠密对齐打下了基础。现有的模型用了很多不同的几何描述符,而我几乎都看不懂。。。
3.5.2 稠密对齐
可以分为静态方法和动态方法:
静态方法就是拟合静态场景的。最早的3DMM就是通过粒子场来迭代式的拟合,后续有人对表情添加了非刚性ICP,之后还有人用了TPS mapping。然后还有人先将脸分成一个个小区域分别拟合。
动态方法就是拟合一个序列当中每一帧的状态,重点是如何拟合帧间的变化。有人使用稀疏和稠密的粒子流来模拟帧间的变化,也有人通过将当前帧配准到上一帧来观察变化,然后还有人用了DCT的方式来编码时间信息。
3.5.3 对齐统计联合建模
就是说将对齐的步骤和建模的步骤放到一起。没啥好讲的
3.6 生成全新的人脸
3DMM可以用来生成现实中不存在的人脸。我们可以通过对模型的形状,表情,外貌参数进行插值或外推来达到这一点。又或者可以直接从参数空间中随机一套参数,也一样可以达到。另外,之前也有提到过,通过将参数原理平均脸,我们可以得到夸张的抽象脸。
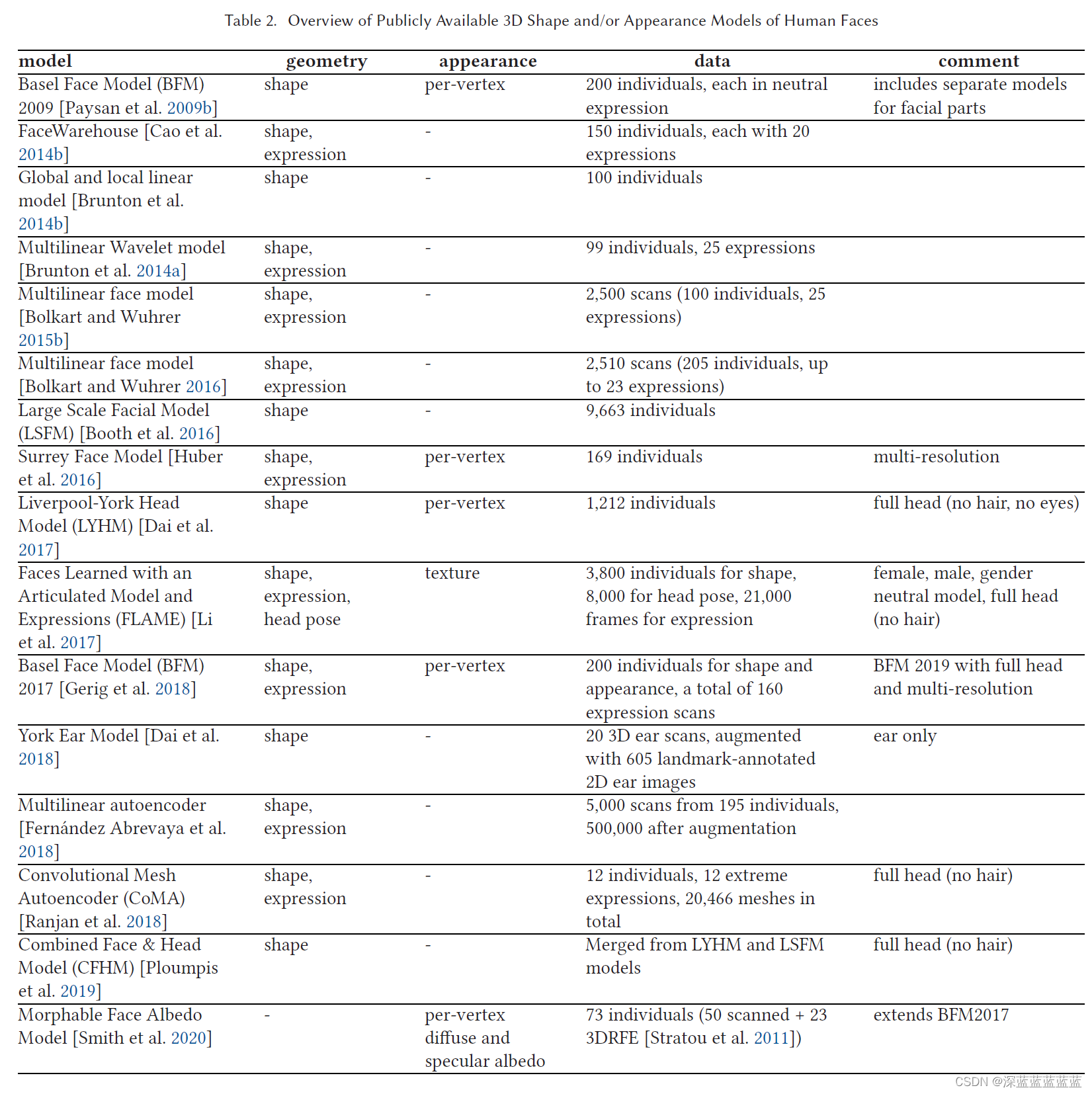
3.7 开源的数据库
3.8 面临的挑战
a. 现如今的模型大都没有为眼镜,口腔和头发建模,但其实这些信息对于一些应用是很关键的。
b. 3DMM参数的可解释是一大问题。现在大多算法都用得是PCA提取特征,但是PCA是一种无监督算法,提取出来的特征没有明确的含义,也并不符合人脸的特征。
c. 现在虽然有模型能为细节建模,但通常需要增加很多参数。所以到底需要多少参数才能真正做到精确建模人脸呢。
d. 现如今的3DMM算法大都只适用于某些特定场景,那么是否会有一个大一统的3DMM算法适用于所有应用呢。
e. 现在大部分的模型都倾向于白人,主要是因为白人的数据比较多。但可不可以通过生成一些虚拟数据来补全这一块呢
f. 现在的数据没有统一的标准,从精细度到尺寸到标注都有区别,所以如果有模型可以同时利用这些模型可能会达到更好的效果。
e. 关于3D建模本身固有的一些问题,就是表面由于刚体运动而带起的非线性形变。也即比如说当你低下头的时候,就会出现双下巴,这双下巴与皮肤运动无关,是脖子运动造成的。一般来说处理这个问题是会需要先预测刚体运动状态,然后做对齐,之后再建模。
4. 图形成像
3DMM的一大用处就是合成图像,包含两个步骤:1.随机一套参数用于生成3D模型,2.用计算机图形学的方法把3D模型渲染成2D图像。这个小结节主要会介绍已经在3DMM模型中得到应用的渲染方案。
4.1 几何成像
其实就是基于相机模型的成像方案,通过类似相机的原理将3D模型投射到一个2D平面上。下面会按照还原度由低到高挨个介绍。
缩放正交投影(Scaled orthographic projection) :这其实就是把正交投影(物体距离无限远且所有投影线平行于光轴)的相机变成一个点,因此相机到物体上每一个点的水平距离都是一致的。这通常是基于"场景深度<<到相机的距离"的假设。因为水平距离都是一致的,所以只需要考虑物体的缩放就可以了。这并不符合物理规律,但有一大优点就是相机的远近并不会影响看到的东西的多少而只会影响物体的成像大小,因此不会出现其他投影方式中出现的由大小,距离,视角带来的歧义。
仿射(Affine):仿射相机就是在正交相机的基础上允许了仿射变换(平移、缩放、旋转、斜切及它们的组合形式。这些变换的特点是:平行关系和线段的长度比例保持不变。)。
透视(Perspective):小孔成像相机(pinhole camera)就是经典的透视相机,也就是假设我们相机是在画面中心的后面的,因此2D成像就是3D物体依据相机的内参(焦距,相机到物体,到画面的距离,相机的方向。。。)来进行的3D到2D的投影(注意,不同于正交投影只会改变大小,这里距离会影响图像内容的,比如普通情况下鼻子是遮不住脸的,但是如果相机怼的特别近,就有可能鼻子把脸挡住了)。但这会导致一个问题,就是在近距离和远距离的时候的landmark是不一致的,尤其是脸轮廓的那部分,变化会非常大,而且很多情况下我们是不知道相机内参的,因此很容易导致歧义。这一歧义在最近的很多篇论文中都有被提到,被认为对模型最后的效果有很大影响。
4.2 测光成像
我们看到的人脸实质上是由光线和面部的材质互动的结果,因此基于测光成像的方法需要对光线和反射建模从而生成图像。
反射模型:最基础的平面光反射可以由BRDF(Bidirectional Reflectance Distribution Function)描述,而在BRDF的基础上假设我们模型接受到的都是平行光,且表面只有漫反射的情况下就构成了我们最常用也最简单的模型:朗伯模型(Lambertian model)。另外,为了模拟外部光源,现如今的3DMM通常将入射光模拟为球谐光照(spherical harmonic lighting model)。之后,为了模拟镜面反射,又有人使用了基于冯氏模型(Phong model)的BRDF。再然后还有人将皮肤视作半透明的材质,从而提出了一些更加复杂的BRDF,但由于太过复杂,并不适用于3DMM建模。
光照模型:现实世界中光照环境是非常复杂的,不仅仅是光线直接照到物体上的光,还有光线照到别的物体上后反射到当前物体的环境光,使得现有模型难以模拟,这也是为什么游戏里光照怎么看怎么不像真的。因此在建模的时候我们只能给他做简化,例如最简单的方式就是将光源视作一个点,但问题在于很容易有遮挡。因此更好地方式就是用球谐光照,可以对物体的表面充分的照亮。另外还有一个方法是用环境光遮蔽(ambient occlusion model),这里假设物体表面都是漫反射的,因此阴影就只取决于被遮挡的角度了。如果我们进一步定义了环境法线(bent normal)的话,借由环境光遮蔽,环境法线和球谐光照,我们就可以模拟一个全局光照环境了。更进一步还有人使用PRT(precomputed radiance transfer)来做光照模拟。
颜色转换:在真实的相机中,由传感器接收到的图像通常要经过一系列的转换才能得到比较好结果, 通常包括两个部分:颜色转换和一个非线性操作。颜色转换可以分解为三个部分(就是三个矩阵叠乘),一个是白平衡调节(一个对角矩阵),一个是原始RGB到XYZ平面的映射(就是将输入图像调整成一张照片所需要的大小),最后是转换到sRGB空间(转换到一个标准色域,以避免由设备导致的颜色误差)。之后的非线性操作也很必要,但更重要的是这个非线性操作意味着线性的反射和光照模型是无法描述最终的图片成像的。但在3DMM模型中,颜色转换这一块还没有人考虑过。
4.3 渲染和能见度
3DMM渲染方式分为两类,一类是基于图片空间的,即将纹理映射到UV空间中,然后用各种CV算法来处理(CNN,GAN什么的)。另一种是基于物体空间的,既将网格模型和图片对齐,然后为每个顶点在图像上找对应的颜色。
在一开始,基于物体空间的渲染方案是为每个三角形的中心计算一个颜色,后续的方法改成了按照每个顶点计算一个颜色。再然后又有人引入了光栅化的渲染方案。但这些都有一个统一的问题就是不可微分(因为这里用的是布尔值,当前像素要么有颜色,要么没颜色)。因此后续又对每个像素计算出与栅格化三角形的顶点相关的三个权重,这些权重一般来说就是当前像素在栅格化三角形内部分的重心坐标,而这个重心坐标很明显是可微分的,因此我们就成功构建出了一个可微的渲染器。
基于图片空间的渲染方案在已知相机内参,光照参数,形状模型和纹理的情况下可以直接用高氏着色(Gouraud interpolation shading)法进行着色。另外,也有人使用更复杂的渲染方案,例如可微的延迟渲染器。
值得一提的是,如何让渲染器可微仍旧是一个开放性的问题,现如今也有很多的尝试。比如有人基于栅格化做可微渲染器,有人将网格三角与渲染结果之间建立弱相关关系,有人建立可微的路径追踪渲染器。近期,又有人直接用神经网络学习渲染流程,称之为神经渲染器。比如有人用构建了一套网络将粗糙的3DMM渲染结果转化成可以比拟照片真实度的图片。
4.4 面临的挑战
主要有三大问题:
a. 在3DMM的渲染中,大部分模型都不合理的假设渲染结果与光照和反射的关系是线性的,而在其他的领域,例如structure-from-motion中,非线性关系是一个固有的标准约束。另外,几乎没有工作考虑到有可能图片的中心和投影结果的中心并不匹配的问题,也就是说有可能数据库里的数据并没有完全的对齐。这些问题在计算机图形学中都已经有了很好的解决方案。
b. 3DMM在意很慢的速度整合计算机图形学中的渲染技术,也就是说大部分最新的3DMM技术都在用着很老的渲染器。一大原因是3DMM要求渲染器是可微的,而且改用最新的渲染器往往有可能让模型变得更为复杂。但无论如何,这个gap还是存在的。虽然有人试图使用gan来弯道超车,但gan生成的图像并不依赖于原始的形状信息,因此并不能如实的反应模型的固有属性。所以还是需要多多关注图形学中的最新生成技术。
c. 可以进一步的研究3DMM参数中的信息。因为在3DMM中,面部信息是全都蕴含在参数当中的,因此与其在最终的面部状态中寻找约束,为什么不直接从3DMM参数中寻找呢。
5. analysis-by-synthesis(边生成边分析)
3DMM中一个重要的组成部分就是学习一套最优的参数用于表达当前的物体,而analysis-by-synthesis方法就是说我们通过最小化观测到的场景和渲染出的场景之间的区别来优化模型。这是一个病态模型,因为有很多个局部最优(因为从2D到3D的映射不可能是完备的,总会有缺失信息的部分,而缺失的部分就会导致一些歧义与矛盾)。
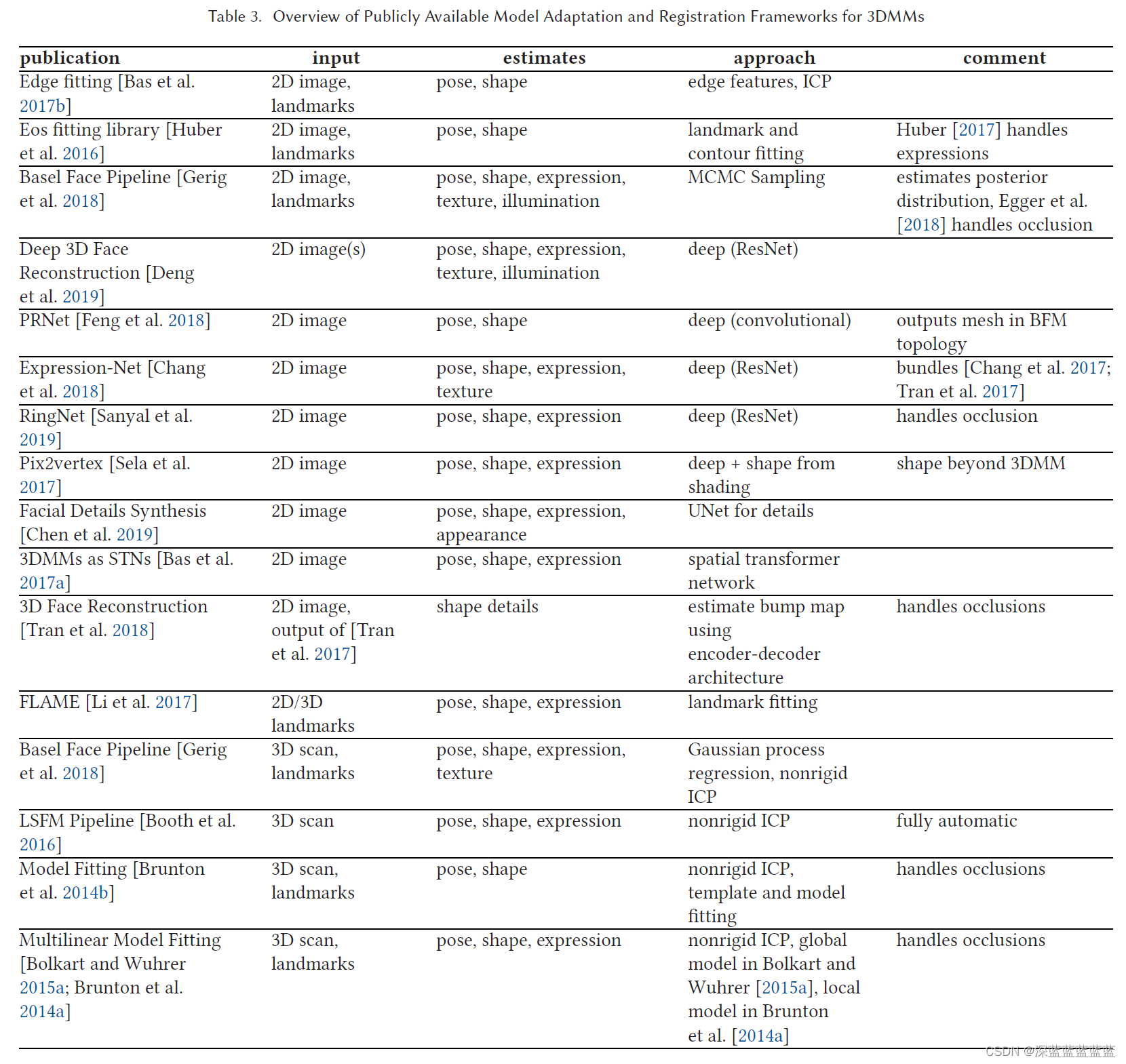
5.1 输入模态
多视角系统:即同时拍摄同一个物体的多个视角图,联合这多个图来还原3D形状。这一方法可以提供更高准确度的还原结果,但设备比较昂贵。大多基于多视角的模型并不要求3DMM的强力先验,但也有文章表明3DMM有助于在低分辨率和有遮挡的情况下的3D形状还原。
单眼RGBD相机:就是在普通相机的RGB基础上提供了深度信息。深度信息有利于模型解决由不同深度带来的歧义。另外,由于在单眼重构事实上解决的问题比多视角方法要简单(因为单眼是一对一,多视角是多对一),因此也衍生出了很多事实的算法。
单眼RGB相机:没有深度信息辅助的情况下,单眼的重构问题就变得非常病态了(理论意义上的困难)。但减少对输入的需求也就意味着运算速度更快且数据更多。例如我们有单眼的视频,这也是被广为研究的方向之一。单就单张RGB图片重建来说,一般大家都会用测光一致性损失(就是像素损失)。另外也有人用边缘损失和SIFT来捕捉细节。再然后还有人通过联合语义分割来保证对遮挡的鲁棒性。
5.2 能量方程
能量方程即优化方程,也可以称之为损失函数。下面会介绍一些3DMM中比较常用的能量方程。
外貌误差:即计算合成图像和原图像的区别。最直接的就是计算像素损失,直接计算像素之间的颜色差别。然后还有基于顶点的颜色损失。当然,也有人随机选取部分顶点做颜色损失,这有助于引入随机性从而避免局部最优。基于顶点计算损失的主要问题是只关注了那些节点,并没有关注更广泛的表面颜色,因此更优的方法是也计算其他部分的颜色,然后给个较小的权重就行。
特征误差:比如计算landmark之间的误差,但由于3D模型的能见度问题,通常landmark是允许在脸上特定区域内滑动的。另外还有比如基于边的误差,基于反光点的误差,基于SIFT的误差。
背景建模:在对形状和姿态建模时,一个常见的问题是有些顶点(或像素)就是比较难以观测到(比如脸右侧边缘,除非从右侧能清楚的看到,但凡视角往左多偏一点就看不到了),这就会导致这一部分的误差被较少的考虑,从而陷入局部最优。例如3DMM中常见的3D脸缩水问题就是这个原因导致的。解决这个问题的一个方法就是特殊对待这些“困难”部分,无论是用landmark,还是对边或轮廓做约束,又或者是直接做语义分割提取出这部分都是可以的。总而言之最简单的方法就是直接对这部分加一个单独的loss就行了,我们这里就称之为背景loss。
遮挡:就是面部被乱七八糟的东西遮挡住的情况,包括自遮挡(比如脸被鼻子挡住),一般方案就是把被遮挡的部分从优化方程中扣掉,不对那部分做优化就行了。现有的方法有基于外貌的,有基于检测的,也有基于语义分割的。
先验:3DMM中最强的先验就是3DMM参数经由PCA降维后的参数空间,我们假设所有的人脸都是以平均脸为中性呈高斯分布的。但这引入了一个问题就是,如果3DMM的参数先验设置的过大会导致大部分生成的脸都长得像平均脸,而忽视了他们固有的特征。因此有人考虑不直接使用3DMM的参数先验,而是通过重构损失来约束形状和纹理,但这又等于就没有用先验了,导致优化过程高度病态。因此,有人考虑使用其他的先验,比如对纹理平滑度的约束,对法线平滑度的约束,甚至对形状平滑度的约束。此外,对于视频输入而言,我们可以建立平滑的帧间变化分布,也是一个方案。
5.3 优化
3DMM参数的优化是一个比较难的问题:
a. 大部分优化方程是非凸的,有多个局部最优(因为本身就是病态问题)
b. 外貌损失是不连续的(由于顶点可见度变化导致的问题)
c. 外貌损失空间存在盆地,既有可能模型无法获得任何有用的信息用于优化
d. 所有参数都有全局影响
e. 外貌损失计算成本高(因为计算一次就需要渲染一次)
解决方案:
改变优化方程:一开始用的就是普通的梯度下降,之后提出随机梯度下降,即每次只考虑部分区域。再然后有人将优化过程视作非线性的最小平方问题,并使用类似牛顿法和LM算法这样的二姐梯度下降法来计算。再然后还有人通过分层优化,多分辨率,优化表来做优化。
分解优化方程:就是将现有的优化函数分解成多个易解的线性子方程,但问题在于所有子方程的最优解和原方程的最优解是不是同一个。
使用贝叶斯方程:有人做了这方面的尝试,说是也不错。
5.4 面临的挑战
首先最大的问题就是视角产生的形状歧义(比如从正面看人脸几乎看不出鼻子的形状,那么如何生成鼻子就有歧义了)和纹理光照歧义(比如人脸上有个黑斑,但你不知道那是什么阴影投射在上面还是脸上真的有黑斑)。这两个问题就是为什么单视角重建的效果远落后于多视角重建的效果了。现如今处理这个问题大都是基于先验给予的约束。另外,关于纹理光照歧义,有人发现现有模型大都把皮肤颜色归类到光照影响当中,肤色明明很不同的两个人,他们的albedo却是很相似的。这一点有人用gan的方式来处理,简单来说就是加一个人种鉴别器。
另一个问题就是现有模型之间比较难以评价效果。一方面是大家都很少公布平均脸的重构误差,这可以作为一个很好的指标。另一方面是我们缺乏一个切实可用的数据集来评判所有模型的效果。虽然最近有人给出了一套数据集和对应的ground truth,但随着单视角模型误差的减小,有可能会发生重构误差小于数据记录误差的情况(因为这所谓的ground truth其实也是基于多视角的方式生成的)。
另外还有一些小问题就比如面部遮挡问题,模型的泛化性问题(生成的人脸局限于数据库所包含的种类,例如婴儿的脸就比较难以用现有3DMM生成),无法捕捉高频细节(皱纹啥的),通常只使用简单的光照模型(会导致难以拟合野外数据中的光源)。
最后还有一点展望,就是我们可以不可以从人与人的互动中学习到信息用于补足算法中的歧义。因为现有的模型都是一次性只考虑一个人的脸,那如果一次性考虑两个人的脸,是不是可以分享光照参数从而避免纹理光照歧义,是不是可以通过交互的状态来给形状增添约束,等等一系列的可能性。
6. 深度学习
深度学习应用在3DMM上的优势有两点,一是为模型提供了非线性能力,所以有可能能突破线性建模的局限性。另一方面是深度学习的强大拟合能力,可以让模型在野外数据上做到非常好的效果。
6.1 深度人脸模型(Deep face model)
深度模型和3DMM的经典模型其实是强相关的,比如全连接层可以视作任何的线性操作,PCA理论上也可以表示为一个auto encoder结构。因此从结构上来看我们可以将基于深度学习的3DMM算法分为三类:
编码器-解码器结构:
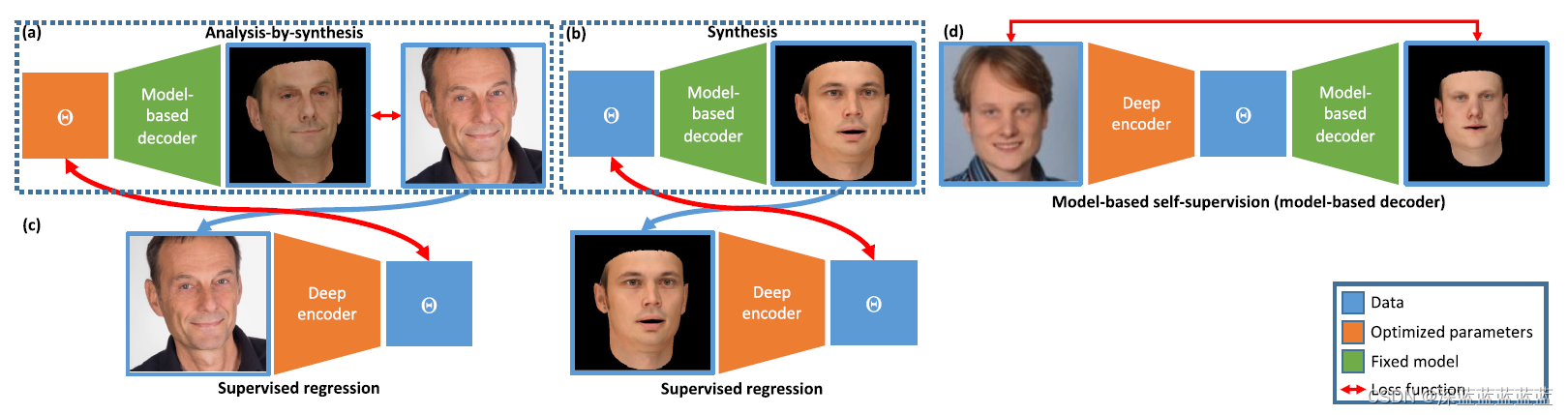
上图可以很清晰的给出了四套模型,即(a)经典的analysis-by-synthesis结构,(a)+(c)联合analysis-by-synthesis结构训练一个编码器,(b)+(c)直接基于渲染结果训练编码器,(d)标准的AE结构。
除此以外,还有人在当中尝试了VAE结构、联合训练形状和纹理、还有直接在3D mesh上做卷积的图神经网络结构,都取得了不错的效果。
GAN结构: GAN主要的优势就是通常效果比AE要好很多,但训练也更困难(难以调参也难以收敛),同时也有人尝试了基于图神经网络的GAN。
混合结构(hybrid structure):比如一个encoder负责从图片中学习参数,两个decoder负责还原3d形状和纹理的,又或者GAN和AE一起用的,等等乱七八糟的模型。
最后外观模型其实也有基于深度学习的升级版,比如有人使用神经网络直接从图像中学习顶点的着色,也有人通过给顶点的纹理加offset来得到更普适的模型,等等。
6.2 深度面部重建
原始的面部重建方法主要是为了学习出一套更好地拟合面部的参数,但深度学习方法主要关注于如何学习一个“解码器”用来自动化的拟合面部的参数。形象的来说,原始方法将优化(梯度下降类)放在测试时,而深度学习方法将优化放在了训练时。
6.2.1 有监督的面部重建
有成对的数据的训练被称为有监督的,即当我们重建人脸时,我们既有原始的图像,又有3D人脸的ground truth,因此模型只需要学会高效的重构就好了。因此这一块主要按照ground truth的获取方式来分类。
手工标注:这是最常用的,但是密集的面部地理,肤色,光照其实是很难以准确标注的,这是最主要的问题。
基于多视角图重建:就是之前提过的,通过拍摄多视角图,然后借用现有模型来还原出物体的3D信息,但这里的问题在于这种重建大多对环境的要求比较高(比如光照可控,背景可控),因此和真实数据差距较大,影响了模型的泛化性
人工合成数据:简单来说就是直接基于现有的图形学模型来根据输入参数生成3D模型,然后再渲染成2D图像。这最大的好处就在于这些图片对应的ground truth是完全准确的。并且很多情况下他们都会对背景也进行增强,比如添加一些乱七八糟的背景,来提升泛化性。但这种方式其实也和真实数据差距较大,最大的问题就是比如头发,口腔这些地方通常都是没有模拟的。
当然也有人试图结合手工标注和生成的数据来联合训练,但如何发挥他们各自的优势仍需要进一步的探索。
6.2.2 自监督的面部重建
自监督就是无监督的一种方式,本质上都是在没有3D标签的情况下学习3D重建。一种可行的路子就是先获得一个训练好的3D模型生成器(即输入参数,输出对应的3D模型),然后我们就可以通过analysis-by-synthesis加auto encoder的方式学习一个编码器,即从输入的2D图片到对应的3D模型参数,从而完成3D重建。
6.3 模型和重建联合训练
在自监督的那部分我们提到了一种训练编码器的方式,但其实使用同样的方式我们也可以进一步优化生成器(即解码器),因为2D图片的数量远远超过3D数据,因此这可以给生成器提供更多有关身份的信息,从而提高鲁棒性
6.4 面临的问题
首先是对现有方法还没人进行充分的比较,和对局限性的分析。例如在不同的应用场景下,是在2D图像上训练好还是在3D图像上训练好。另外,到底深度学习需要多少数据才能训练的好。
另外,learning-based model和analysis-by-synthesis是不是有可以互相帮助的方法,例如使用learning-based model作为analysis-by-synthesis的初始化。
还有就是,现在有的方法是基于精确的3D标签训练的,他的细节还原度就很高,而有的是基于2D图片训练的,细节就比较差,但是对不同的人就更鲁棒,因此如何缩小这两个方法间的差距也是一大课题。
7. 应用
这章主要介绍3DMM模型在各个领域的实际应用。
7.1 人脸识别
主要就是讲的如何利用3DMM提升人脸识别的效果。比如有人从2D图片中提取3DMM特征,然后以此作为人脸识别的一个metric。也有人发现如果3DMM算法中用到了当前的人脸识别算法,那会进一步的加大3DMM带来的效果提升。通常来说在人脸识别模型中加入3DMM算法都应该会带来提升,主要是因为3DMM可以很轻松的抹除掉光照,姿态甚至表情的影响。但事实上现如今纯数据算法(即不使用3DMM作为先验)仍占据主导地位,主要是因为现在的3DMM模型还不够鲁棒,在野外数据集上表现的不行。另外,还有人用3DMM来做数据增强,比如生成新的图片。如果未来3DMM可以模拟更精细的细节,比如头发之类的的话,那可能能给人脸识别任务带来更大的提升。
7.2 娱乐
3DMM是很多娱乐应用的必备要素(比如抖音的美妆,换脸,特效,zoom里的头部特效之类的)。因此在这一方面3DMM模型通常要处理野外数据,且往往只有有限的视角(即只有摄像头提供的一张RGB图)。下面就会介绍一些相关的应用。
7.2.1 游戏和VR中的3D头像控制
游戏中我们可以设计一些3D卡通头像,然后通过特征点对应来驱动卡通头像。这就涉及到需要我们实时的从RGBD或RBG相机中恢复人脸的3DMM了。
7.2.2 试穿和美妆
这主要就是实时的建模3DMM,然后在此基础上加上对应的装饰或妆容就行了
7.2.3 换脸
这就需要同时建模两个人脸,然后将当中的某些参数或某些经由语义分割后的对应区域对调。snapchat的滤镜就是一大应用。
7.2.4 面部重现(Face Reenactment)和视觉配音(Visual Dubbing)
面部重现是指将输入的人脸改变为指定视频中的表情序列。现在不仅仅有改变人脸表情的,还有改变全身动作的。
视觉配音和面部重现很像,只不过目标是模拟指定视频的口型从而能够和视频里的语音对应。
7.3 医学应用
主要还是有助于那些可以从脸上分析出来的疾病。比如面部发育相关的问题,面部缺失情况下植入物的个性化定制。也有人通过模拟面部特定区域在特定刺激下的反应来研究自闭症。最主要的问题在于这些应用很多都涉及婴幼儿和老年人,而即使现如今最大的3DMM模型也没有收录这些情况,因此3DMM在医学方面的应用还是有限。
7.4 法医学
心描绘图:即从目击者口中描述的特征恢复人脸。现有的应用是通过3DMM建立模板来辅助建立人脸
虚拟衰老:即模拟出目标人脸衰老后的样子。这主要是有助于找到失踪儿童和收到性虐待的受害者。优势在于3DMM的先验有助于防止模型生成过于主观的结果(比如两个人面部骨架都不一样)。
头骨重建人脸:这其实是一个相当病态的问题,因为从头骨到脸的映射不是一对一而是一对多的。因此有人使用3DMM仅仅是为了提供基于当前头骨的各种可能性,又或者可以加上软组织厚度信息从而辅助建模。
此外,3DMM其实也有助于检测图像是否被P过(就是检测图像的真实性)
7.5 认知科学,神经科学和心理学
3DMM在认知科学,神经科学和心理学的试验中往往可以通过控制变量(只改变某些参数)从而提供特定的刺激,因此非常有助于这些学科的研究。例如研究外貌对社会评价的影响,又或者研究人脸是如何被大脑认知的,又或者研究3D形状对于人脸认知的贡献,又或者人类对于单视角3D人脸重建的能力。另外,也有研究发现3DMM这一类面部处理系统加渲染系统其实是比单纯的基于神经网络的系统更接近于大脑对于相关任务的处理的。
但3DMM也有一定的问题,主要就是没有头发,大大影响了生成的人脸的真实性。
8. 领域前瞻
主要就是讲讲3DMM整体遇到的问题和未来10-20年间的发展预期
8.1 一些面临的挑战
首先还是3DMM模型的一些局限性。现如今的3DMM没有为头发,眼镜,牙齿,皮肤细节等等建模。包含这些细节的高精度图形已经可以由人类手工制作出来了,但是自动化的生成这些细节还处于开端。另外,大部分模型都过分简化了模型中的一些假设,比如完全漫反射,直线光照,等等。此外,其实有人发现人体躯干的动作也是有助于恢复面部细节的,因为毕竟人脸是人的一部分,而这一块还很少有人尝试。
其次就是模型之间难以横向对比。太多的模型都是专注于自己的领域或者自己的特殊场景,难以横向对比。这一方面是因为这写论文只会计算他们任务对应的score,而不会计算其他的。当然现在越来越多人开源代码是有助于这一方面的。但还有一点就是我们没有足够的benchmark,现在唯一的一个公开可用的benchmark还是只能评判3D形状建模,关于光照建模和纹理建模根本就没有benchmark。
最后就是道德问题,也是CV界广为关注的话题,比如有人使用这些技术制造虚假的图像或者视频。这主要就是依赖于更多的规章制度了。
8.2 可扩展性
就是如何将3DMM用于人脸以外的物体建模。人脸建模有两个特殊点,一方面是人脸其实非常难以建模,因为我们通常会关注重建中很微小的错误。但另一方面由于人脸通常都是有规律的,因此他拥有比较强的先验知识。而如何将3DMM用于其他物体就需要依赖于更多的创新方法了。比如有人通过隐式表示的方法来建模。另外,这可能需要依赖于自监督,无监督方面的发展。
8.3 应用
为了促进这个领域的发展,不同的研究组织间需要有一些配合。例如统一数据格式和传播渠道。另外,隐私方面的保护也很重要。
另外,为了防止技术被滥用,可能也需要研究一些反滥用的手段,比如通过帮助人们从视频中抹除他们不想透露的信息(情绪状态或健康状态)
最后,也需要实时的向大众普及有可能对他们生活产生影响(无论正面还是负面)的新技术。
8.4 展望
3DMM未来的发展有很多方向,但并不完全相同,比如质量,真实度,泛化性和效率。并且计算机视觉渲染的效果和现如今3DMM渲染的效果仍旧有巨大的差距,这一点也有待解决。
在3DMM刚提出的时候是将CV和CG两个领域的焦点从2D引入到了3D之中。而现在随着深度学习的发展,大多的目光又回归于2D,因此如何再次将领域发展到3D是亟待解决的问题。3DMM最大的特色在于可以分离各种特征(光照,姿态,纹理。。。),但如何直接从2D图片中分离这些特征仍是一个未解决的问题。
另外,对于3DMM最终的期望是可以有一个“终极”模型,一个“活着的”3DMM,既可以从2D数据学习也可以从3D数据学习,既可以从单视角学习,也可以从多视角学习,既可以从低分辨率学习也可以从高分辨率学习(分辨率不仅仅指像素,也指顶点的多寡),这样一个可以从各种各样的数据中学习的模型。另外还期待他可以适用于各种各样的任务,而不仅仅是其中的某种特定任务。此外,作者还是认为比起黑盒,借用我们已有的物理和地理知识来分离固有的特征是更好的建模方式。这可能需要我们未来10-20年的努力。
(完)
后续可能继续修正文中的错别字和表述不清的部分,也可能进一步精简语言,感谢阅读。

















 6416
6416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









