







由于onnx模型前处理方式是自行实现的,所以在从pt转换成onnx模型后,图像的前处理逻辑可能因为自行实现导致有所不同,例如,pt要求填充步长必须整除stride,所以当你填充的部分无法整除stride的时候,他就会等比例缩放,而不会进行填充操作,而onnx自行实现的前处理方式是将不足的部分进行填充,所以在进行推理的时候前处理方式不一致,导致置信度不一致(以yolo11n.pt为例)
将augment.py文件下的LetterBox这段代码屏蔽以后则不考虑整除步长的方式,都进行填充操作。
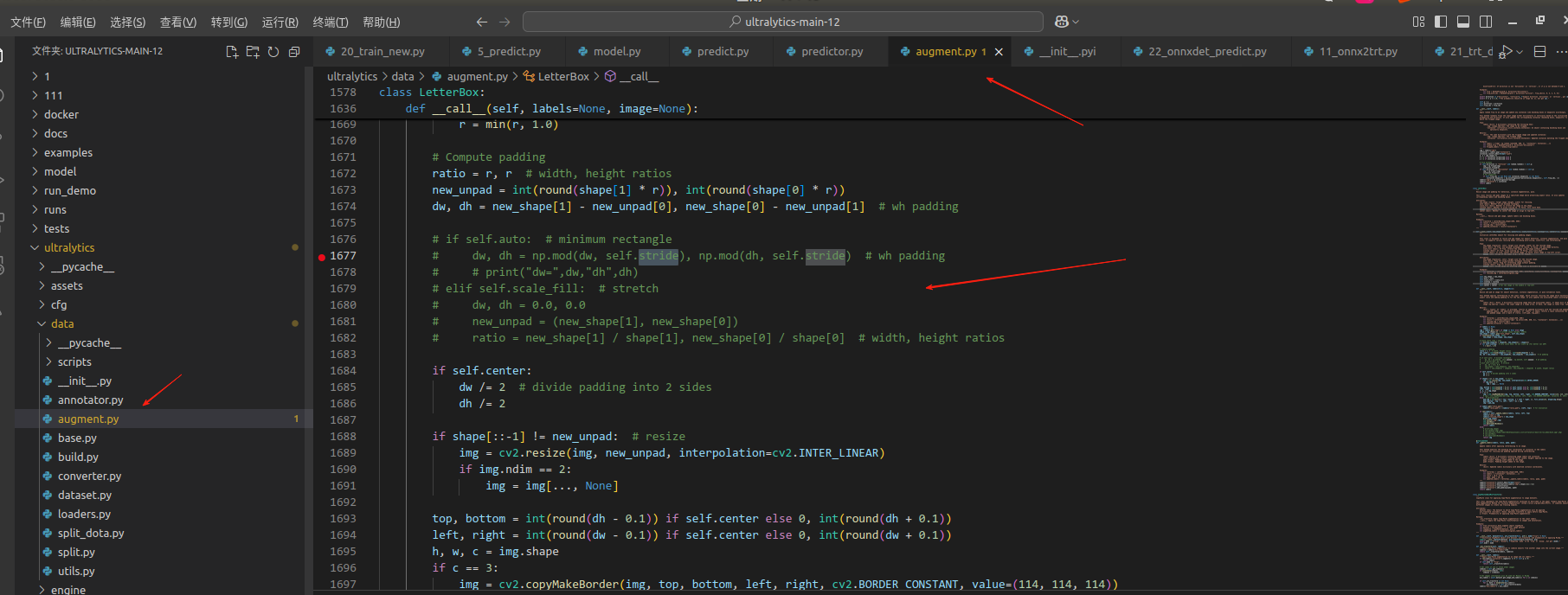
注:所以模型训练的时候用的什么前处理方式,那么在后续部署的时候,就用同样的前处理方式,否则不一致的话置信度会有所偏差。
1、pt前处理(无法整除则不填充预处理后的图像及模型结果)


2、pt前处理(填充后的图像及模型结果)

3、onnx模型(填充后图像及模型结果)




















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









