




一、 简介
reranker是在RAG系统中的第二阶段文档过滤器,专门负责对初始检索模块(语义搜索或关键字搜索)检索到的文档内容进行重新排序,也被称为2nd retrieval。
进行rerank的目的也很明显,query和文档相关性最高的内容是更希望得到的,进而希望相关性更高的内容优先被选择使用。
二、 为什么需要rerank
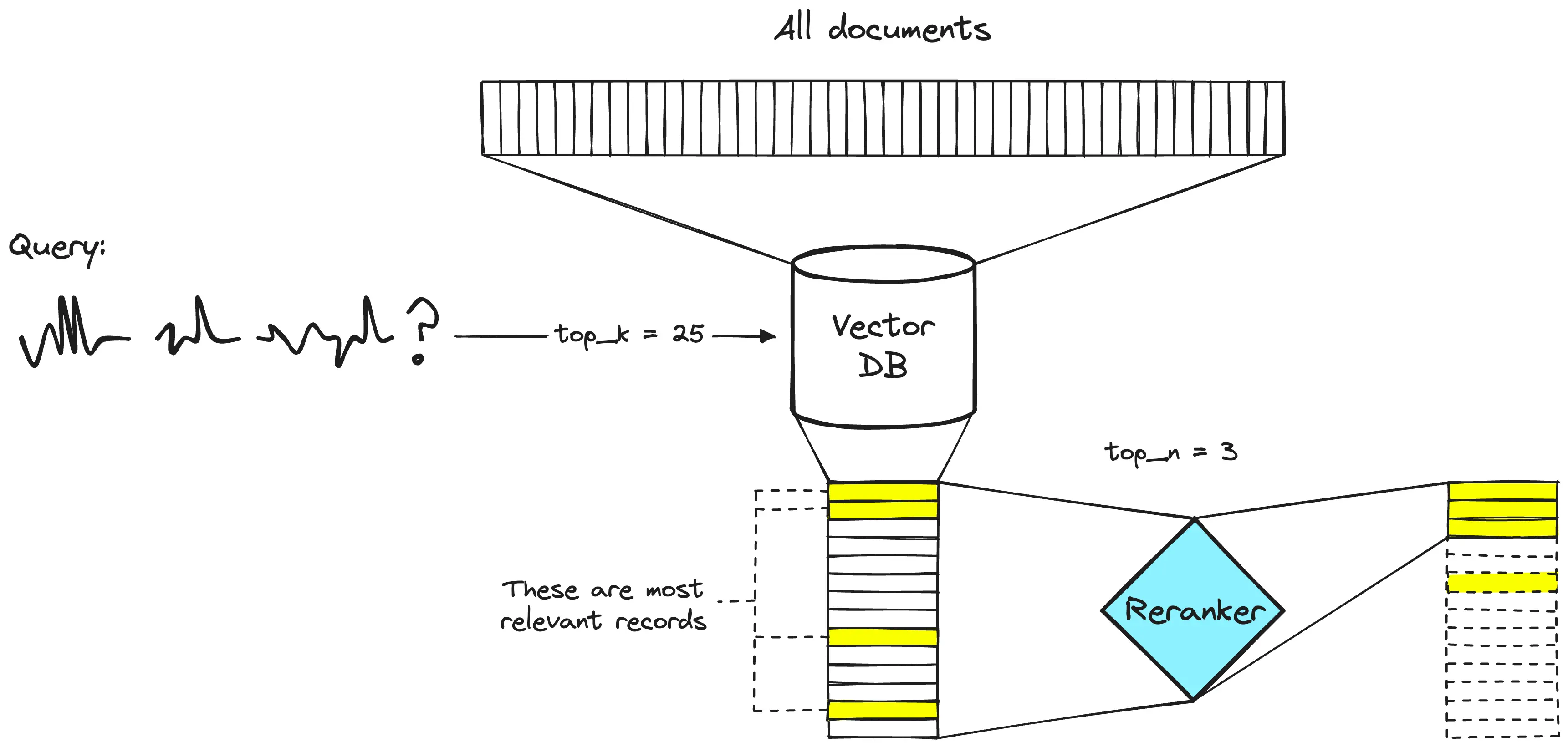
embedding model是将一个sentence的信息压缩到一个768 or 其他dimension的vector,这样会带来一些信息上的损失,同时embedding得到的信息是没有加入query语义的信息。
通过embedding model得到句向量其检索的评价是recall,召回率是指有多少相关文档被检索到,为了不丢失相关信息,recall当然是越大越好,在总检索空间不变的情况下,返回检索到的内容越多,recall越高(根据recall的计算公式)。
但是对于RAG而言,检索到的内容是需要传递给LLM,帮助LLM更好地回答用户的问题。
LLM的输入是存在长度限制的即Context Windows,对于过长的文本是不能全部输入到LLM中,所以返回全部的文档就不现实,同时当上下文越长,LLM的attention机制注意力会被分散到一些和查询相关性不太强的文档上,所以对于输入到LLM中的文档我们是希望相关性更强的文档。
于是rerank这种能提取相关性更大的模型就有了需求。
三、 Bi-Encoder & Cross-Encoder
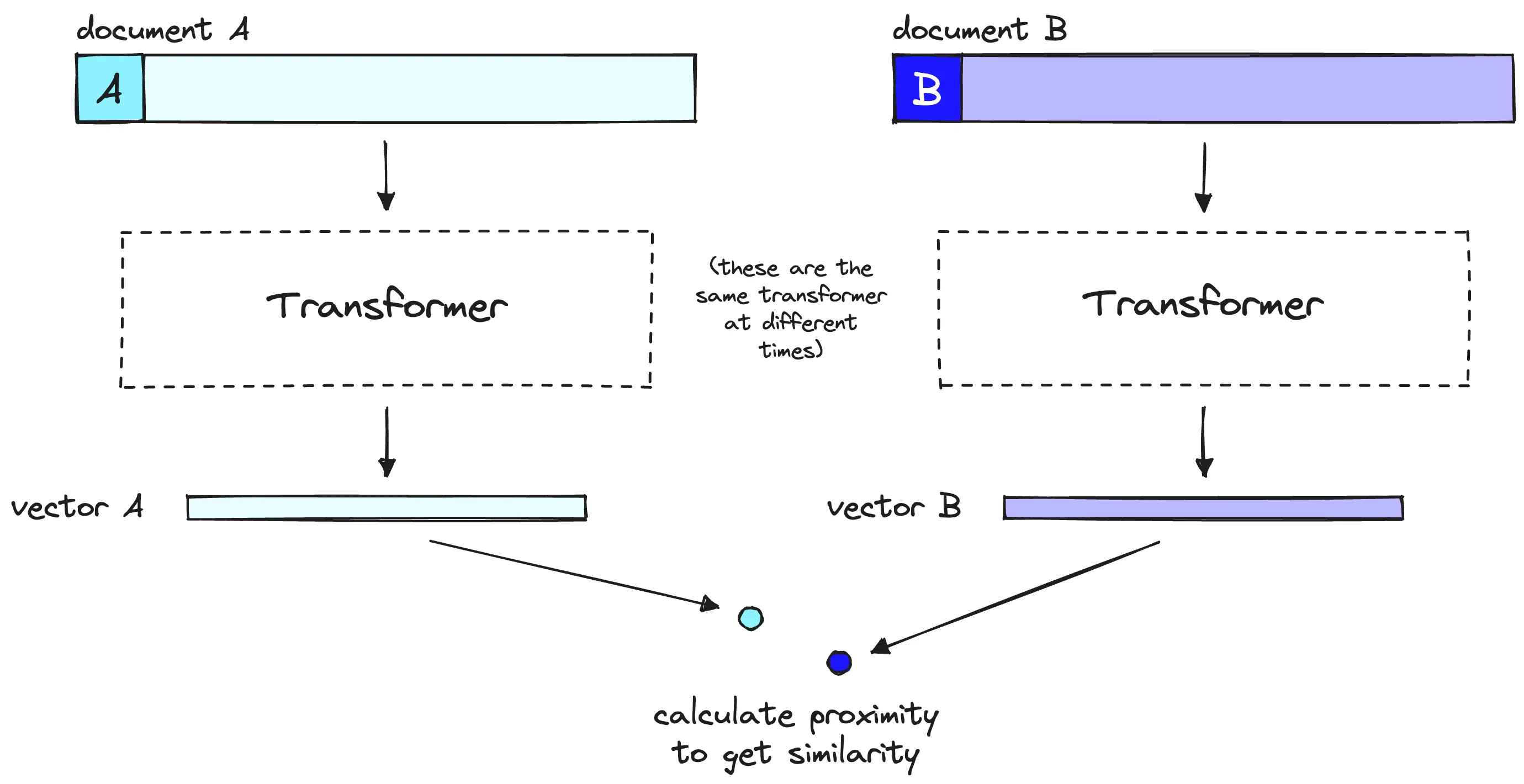
上图即为Bi-Encoder的框架:
左侧是查询,查询经过编码器编码之后再经过pooling操作提取出query的特征u,同时在数据库中的内容也会经过编码器编码再经过pooling操作提取处value的特征v,然后u、v特征计算余弦相似度。
Bi-Encoder的优点是计算快,因为存储在db中的value,可以是提前经过编码和pooling的vector。这样当一个查询来临时,就直接和数据库中的vector逐项计算余弦相似度即可。
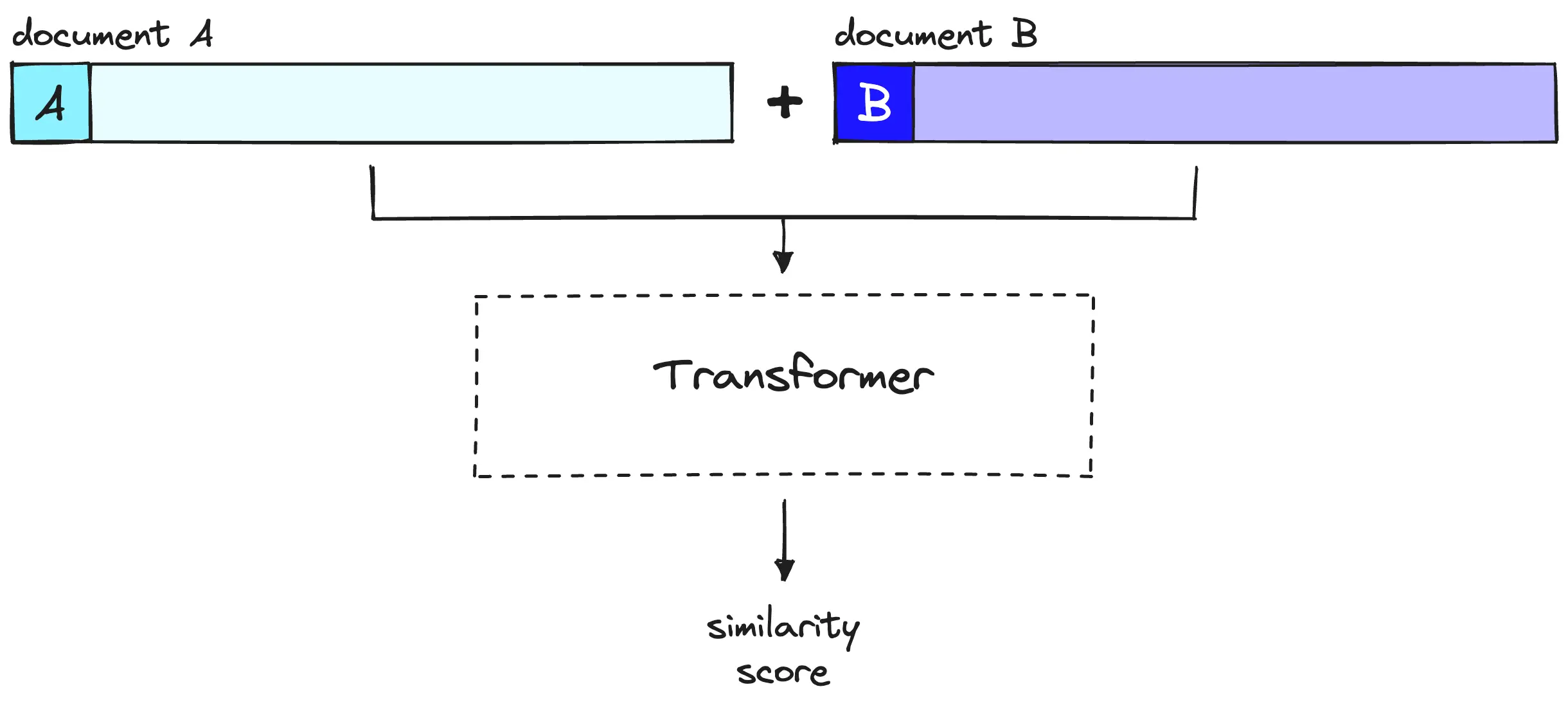
Cross-Encoder框架是将query和知识库中的知识进行拼接,然后直接输入到编码器再经过一个分类头即可,这样的优点是可以充分利用上下文信息。当然缺点也很明显,当query来临时,需要将query和value进行拼接,然后送入bert,无法提前将value经过bert预处理好,这就会比较耗时。
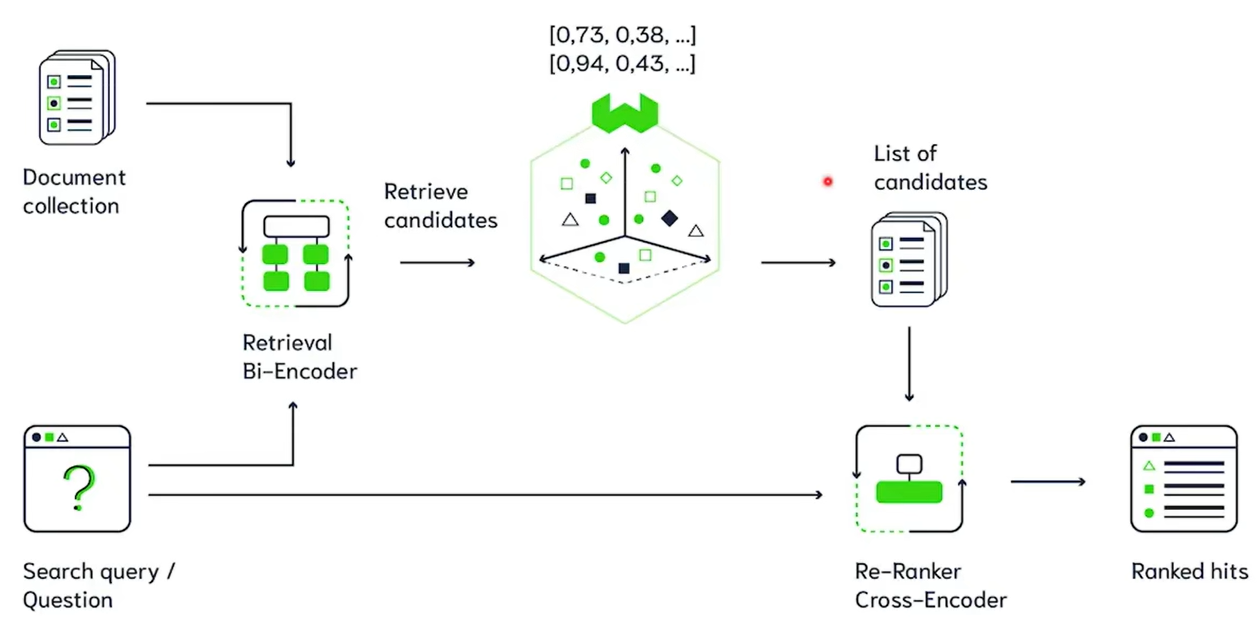
结合两者,在初次检索时使用Bi-Encoder提取出相关的 t o p k 1 top_{k_1} topk1然后在rerank时再使用Cross-Encoder重排提取 t o p k 2 top_{k_2} topk2。
四、 总结
概括来说embedding model检索快,但相关性的准确度不高,rerank慢,但相关性的准确度高,两者搭配食用效果更佳。

















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









