




 Rerank3是一款增强企业搜索的模型,通过4k上下文长度和多语言支持,提高搜索质量和精度,降低延迟,尤其在处理半结构化数据和代码检索方面表现出色。它能与Elasticsearch集成,显著增强现有系统的性能和用户体验。
Rerank3是一款增强企业搜索的模型,通过4k上下文长度和多语言支持,提高搜索质量和精度,降低延迟,尤其在处理半结构化数据和代码检索方面表现出色。它能与Elasticsearch集成,显著增强现有系统的性能和用户体验。

今天,将推出最新的基础模型 Rerank 3,该模型旨在增强企业搜索和检索增强生成 Retrieval Augmented Generation (RAG) 系统。
模型与任何数据库或搜索索引兼容,也可以插入任何具有本机搜索功能的遗留应用程序中。 只需一行代码,Rerank 3 就可以提高搜索性能或降低运行 RAG 应用程序的成本,而对延迟的影响可以忽略不计。
Rerank 3 为企业搜索提供最先进的功能,包括:
- 4k 上下文长度可显着提高较长文档的搜索质量
- 能够搜索多方面和半结构化数据,例如电子邮件、发票、JSON 文档、代码和表格
- 多语言覆盖100+语言
- 改善延迟并降低总体拥有成本 (TCO)
具有长上下文的生成模型具有执行 RAG 的能力。 然而,为了优化准确性、延迟和成本,RAG 解决方案需要结合生成模型和我们的 Rerank 模型。 Rerank 3 的高精度语义重新排序可确保仅将最相关的信息馈送到生成模型,从而提高响应准确性并保持较低的延迟和成本,特别是在从成千上万的文档中检索信息时。
增强的企业搜索 Enhanced Enterprise Search
企业数据通常很复杂,当前的系统很难搜索多方面和半结构化的数据源。 公司中最有用的数据通常不是简单的文档格式,半结构化数据格式(例如 JSON)在企业应用程序中很常见。 Rerank 3 能够根据所有相关元数据字段(包括其新近度)对复杂、多方面的数据(例如电子邮件)进行排名。
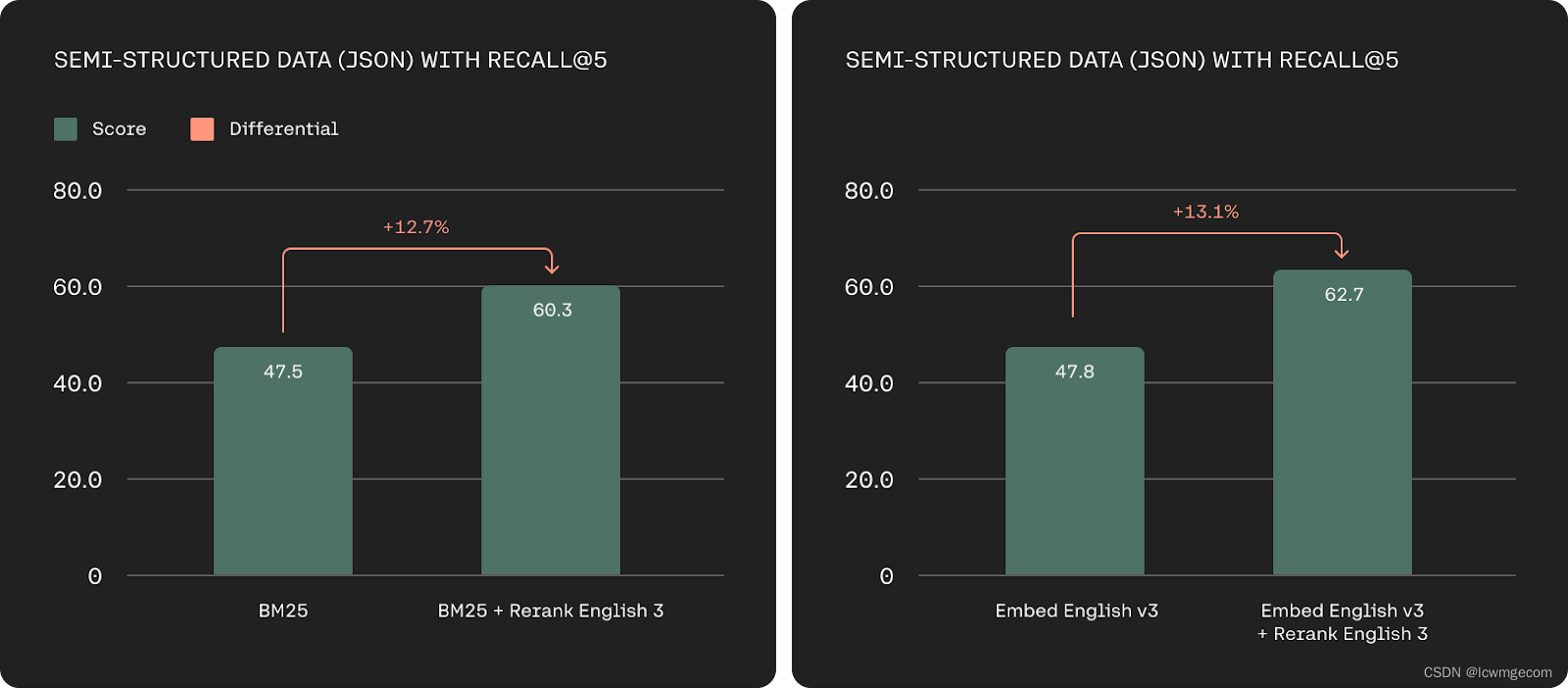
基于 Recall@5 在 TMDB-5k-Movies、WikiSQL、nq-table 和 Cohere 带注释数据集上的半结构化检索精度(越高越好)。
Rerank 3 还展示了代码检索能力的显着改进。 这可能包括检索企业的专有代码存储库以提高其工程团队的生产力,或检索大量文档。
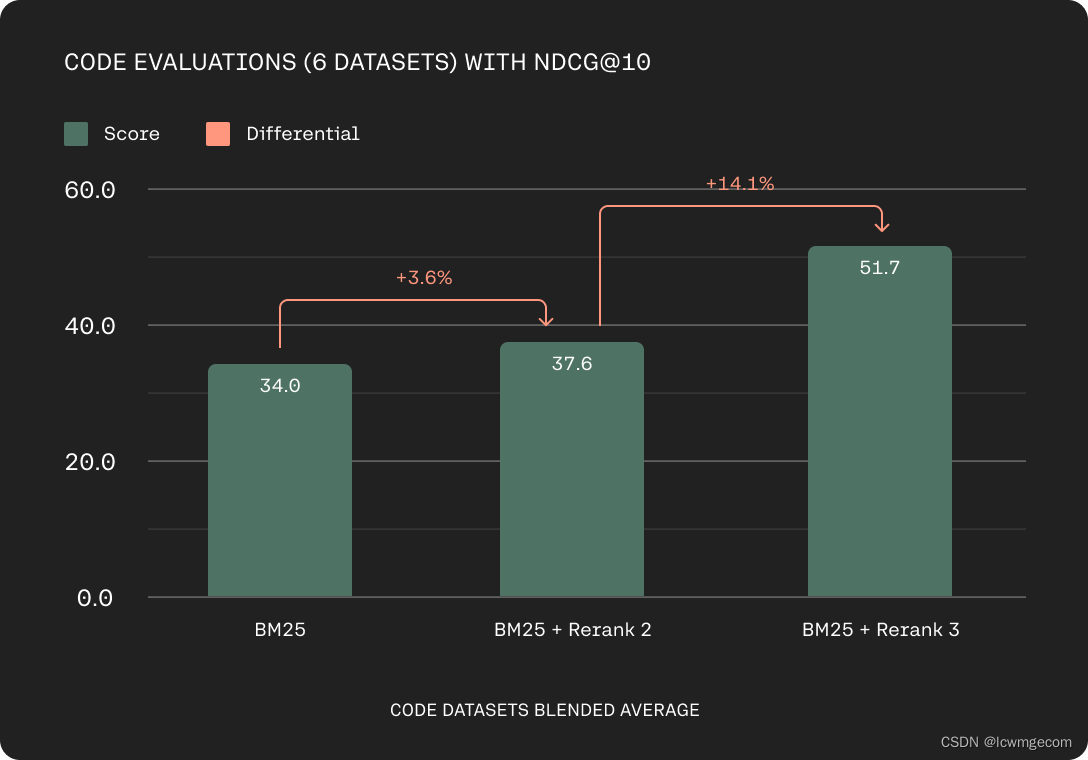
基于 Codesearchnet、Stackoverflow、CosQA、Human Eval、MBPP、DS1000 上的 nDCG@10 的代码评估准确性(越高越好)。
全球组织还处理多语言数据源,并且历史上多语言检索一直是基于关键字的方法的挑战。 我们的 Rerank 3 模型在 100 多种语言中提供强大的多语言性能,简化非英语客户的检索。
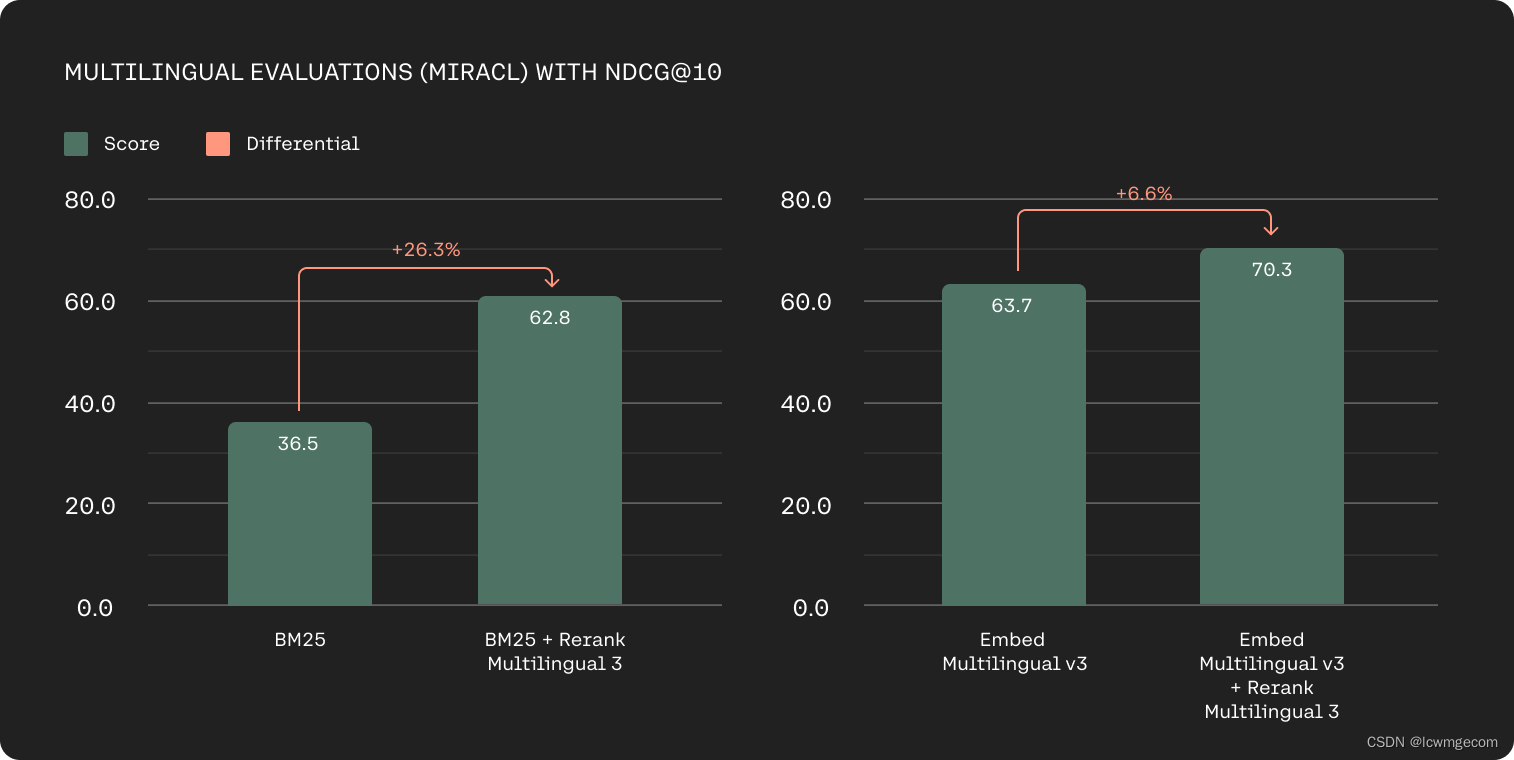
基于 MIRACL 上的 nDCG@10 的多语言检索准确率(越高越好)。
构建语义搜索和 RAG 系统时的主要挑战是确定如何最好地对数据进行分块。 我们的 Rerank 3 模型现在拥有 4k 上下文长度,允许客户传递更大的文档进行排名。 这使得我们的模型在确定相关性分数时可以考虑文档中的更多上下文,并减少为了适应模型的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2755
2755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









