






MPI入门
零、 概念
MPI:Message Passing Interface,MPI定义了一种进程间消息传递的接口。
实现MPI的库并没有统一,也就是说有很多不同的实现版本,例如OpenMPI、MPICH、MVAPICH、Intel MPI。
MPI的设计是SPMD(single program multiple data):即instruction是相同的,但是data是不同的。换句话说我们只有一份代码,这一份代码拷贝多份,然后不同进程执行同一份代码处理不同的数据。
一、 example
#include<stdio.h>
#include<mpi.h>
int main(int argc, char* argv[]){
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
printf("Process %d of %d: Hello, world!\n", world_rank, world_size);
MPI_Finalize();
}
MPI_Init(NULL, NULL);就是将通信环境建立起来。MPI_Finalize():会将管理这些进程的所有资源释放。MPI_COMM_WORLD:这是MPI的一个通信器,它包含了所有MPI创建的所有进程MPI_Comm_rank:通信器里面进程的编号,必须连续。MPI_Comm_size:通信器中进程的数量。
使用MPI主要是利用MPI的通信功能,MPI的通信方式主要是两种
- point-to-point:点对点通信。
- collectives:集合通信。
进程的开销是比较大的,因为每个进程都需要有自己的VM Table。
二、 point-to-point 点到点通信
点对点通信主要是用连个函数
MPI_Send:用于发送消息MPI_Recv:用于接受消息
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)

buf:内存地址,对于Send而言就是传递消息的起始地址,对于Recv而言就是用于存储接受到消息的存储起始地址,由于这里是两个进程,所以他们的VM是独立的,所以这里是需要两个不同的地址。
count:是传递多少个消息。
datatype:是传递消息的类型,这里消息的类型应该是相同的。
dest\source:对于Send,dest是它传递消息的目的地,对于Recv,source是它接受消息的来源。
tag:发送消息的标签。
comm:就是上面所说的通信器,Commucator不只可以是MPI_COMM_WORLD,也可以对这个通信器再次进行划分。
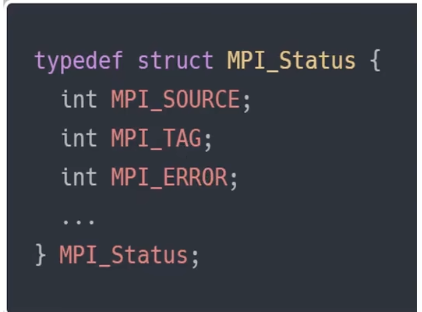
status:是Recv比Send多出来的
上面datatype是MPI预定义了一些传递消息的类型,这些类型覆盖了C datatype

MPI_Recv相比于MPI_Send多一个参数MPI_Status,这个参数是可以设置为MPI_STATUS_IGNORE,这会告诉MPI我们不需要任何的status,这是一个预定义的MPI的结构。如果想要知道相关的信息。可以通过MPI_Get_count

MPI消息传递的过程:
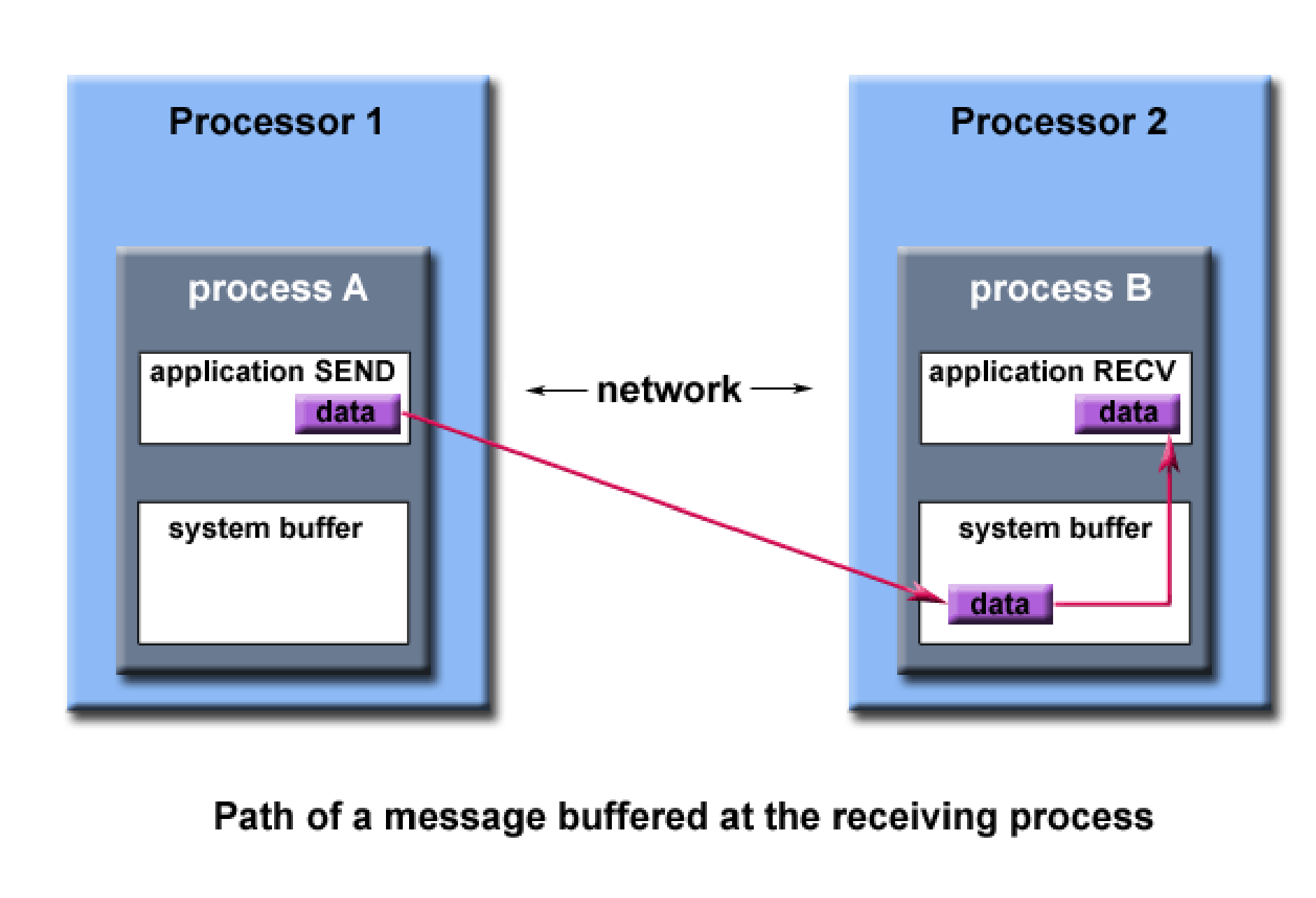
进程之间传递消息会有一个系统缓冲区:proc1先把数据通过网络发送到proc2的系统缓冲区,proc再从系统缓冲区读取数据。
标签的作用:主要是用于区分同一发送者发送的不同消息的。
三、 collectives 组通信
1、 一到多(Broadcast,Scatter)
1.1 Broadcast
MPI_Bcast(Address, Count, Datatype, Root, Comm)
标号为Root的进程发送相同的消息给标记为Comm的通信子中的所有进程。
Address:对于Root进程即是发送地址也是接受地址,对其他进程而言是接受缓冲区。Count:是传递消息的数量Datatype:发送消息的类型Root:根进程的Rank idComm:要广播的通信域
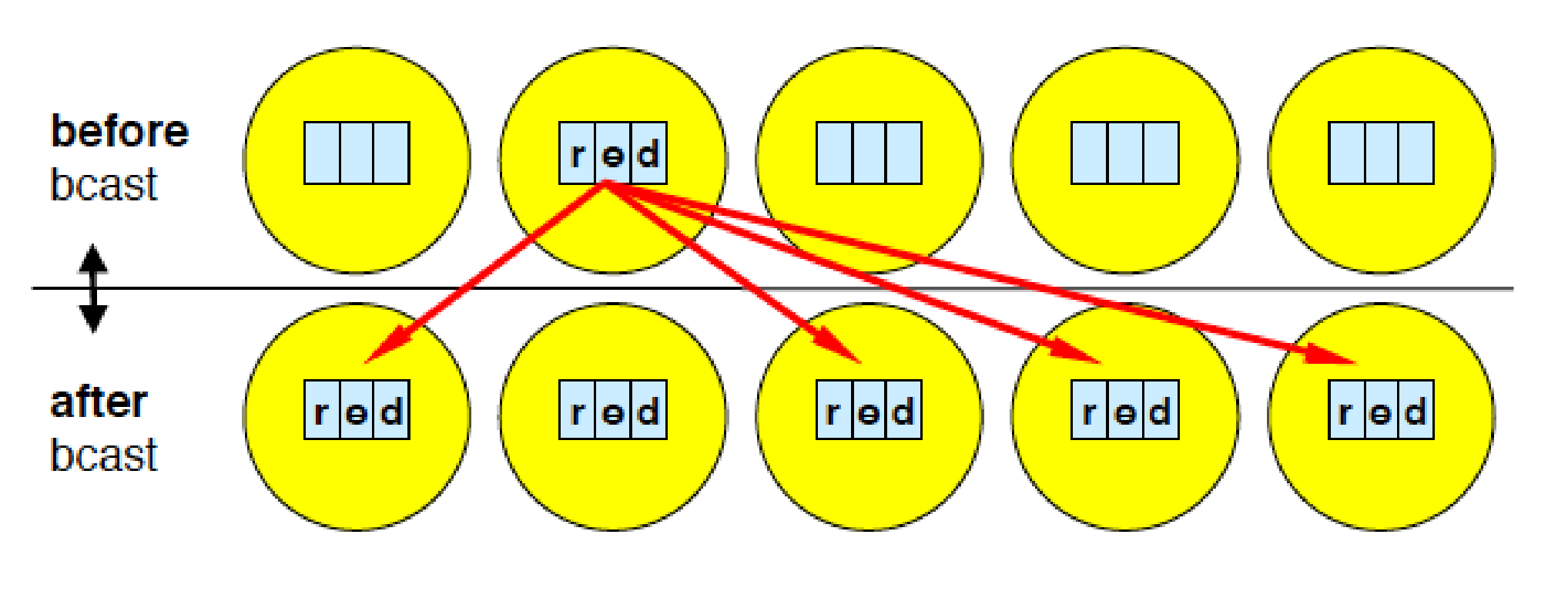
例子:
rank=0的进程读取一个数据value值,然后通过BroadCast将这个value值传递给其他进程并进行打印。
#include <stdio.h>
#include <mpi.h>
// 标准的 main 函数写法
int main(int argc, char **argv) {
int rank, value;
// 1. 初始化 MPI 环境
MPI_Init(&argc, &argv);
// 2. 获取当前进程的 ID (rank)
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 3. 进入循环
do {
// --- 步骤 A: 只有 Rank 0 负责读取数据 ---
if (rank == 0) {
printf("Please enter a number (negative to quit): "); // 提示信息
scanf("%d", &value);
}
// --- 步骤 B: 广播数据 ---
// 关键点:
// - 对于 Rank 0:这是发送操作,把刚才 scanf 读到的 value 发给别人。
// - 对于 Rank 1, 2...:这是接收操作,从 Rank 0 接收数据写入自己的 value 变量。
// - 这是一个同步点,所有人都会在这里等,直到 value 被分发完毕。
MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD);
// --- 步骤 C: 大家一起打印 ---
// 此时,所有进程里的 value 变量都变成了 Rank 0 输入的那个值
printf("Process %d got %d\n", rank, value);
} while (value >= 0); // 如果输入负数,所有进程都会退出循环
// 4. 清理 MPI 环境
MPI_Finalize();
return 0;
}
1.2 Scatter
MPI_Scatter(SendAddress, SendCount, SendDatatype, RecvAddress, RecvCount, RecvDatatype, Root, Comm)
相较于BroadCast,Scatter是给每个进程发送一份不同的数据,同时也包括他自己,这n个消息在Root进程的发送缓冲区中按标号顺序有序地存放,每个接受缓冲由三元组(RecvAddress, RecvCount, RecvDatatype)标识,非root进程忽略发送缓冲。
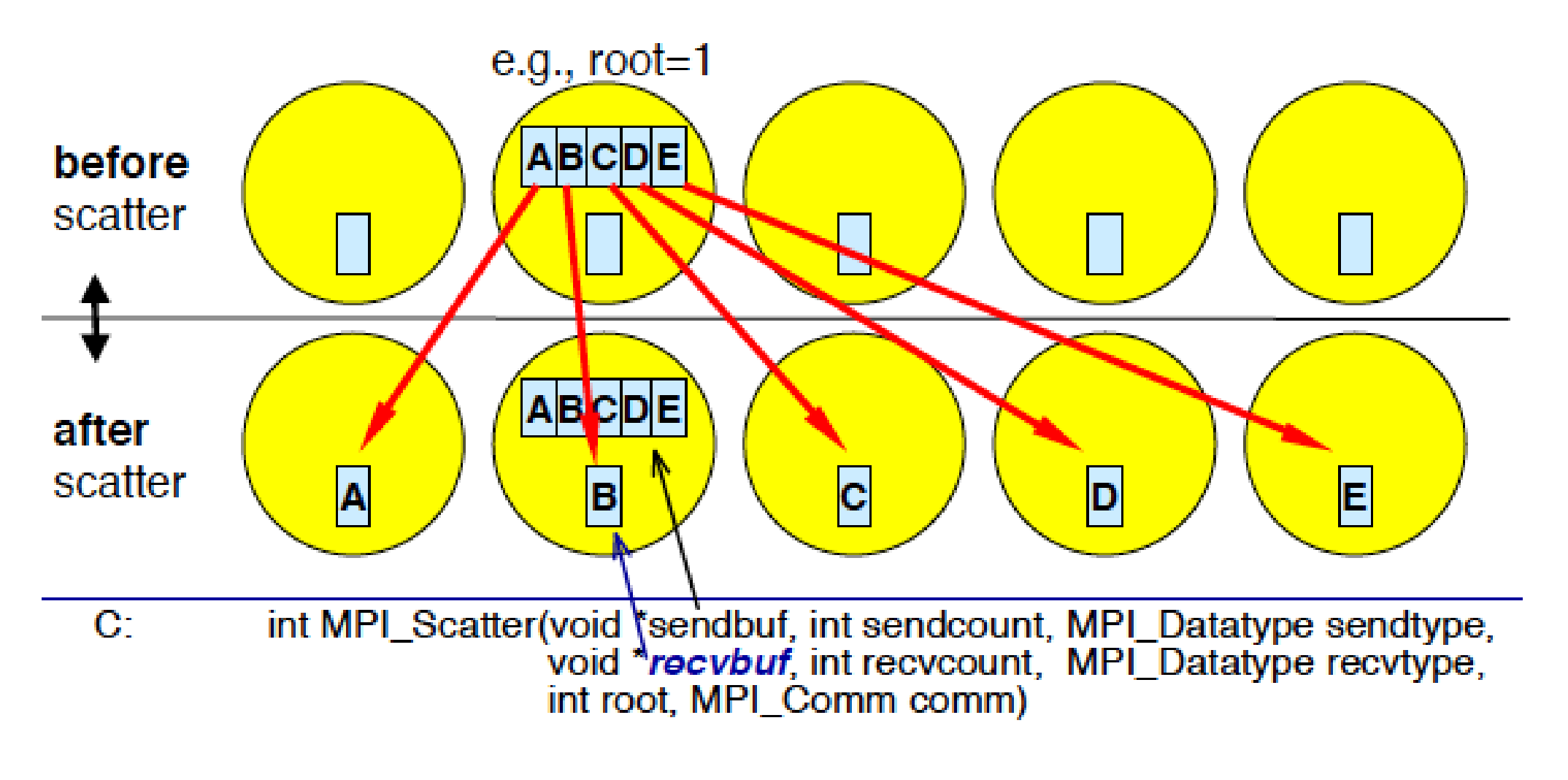
将10、20、30、40分别发送给rank为0、1、2、3的进程
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size); // 假设 size = 4
int *send_buffer = NULL;
int recv_data; // 每个进程只接收 1 个整数
// 1. 只有 Root 需要准备大数组
if (rank == 0) {
send_buffer = (int*)malloc(size * sizeof(int));
// 初始化数据: [10, 20, 30, 40]
for (int i = 0; i < size; i++) {
send_buffer[i] = (i + 1) * 10;
}
printf("[Root] 准备分发数据: 10, 20, 30, 40\n");
}
// 2. 执行 Scatter
// 关键点:sendcount 填 1,表示给“每个人”发 1 个 int
// recvcount 也填 1,表示“每个人”收 1 个 int
MPI_Scatter(send_buffer, 1, MPI_INT,
&recv_data, 1, MPI_INT,
0, MPI_COMM_WORLD);
// 3. 打印结果
printf("Process %d received value: %d\n", rank, recv_data);
// 4. 清理内存
if (rank == 0) {
free(send_buffer);
}
MPI_Finalize();
return 0;
}
1.3 Scatterrv
scatter是平均主义,root进程向其他进程发送相等的数据,而scatterrv则是root进程向其他进程发送个数不等的数据。
int MPI_Scatterv(
const void *sendbuf, // 发送缓冲区 (仅 Root)
const int *sendcounts, // [数组] 发给每个进程的数据个数 (仅 Root)
const int *displs, // [数组] 发给每个进程的数据在 sendbuf 中的偏移量 (仅 Root)
MPI_Datatype sendtype, // 发送数据类型 (仅 Root)
void *recvbuf, // 接收缓冲区 (所有人)
int recvcount, // 自己要接收多少个数据 (所有人)
MPI_Datatype recvtype, // 接收数据类型 (所有人)
int root, MPI_Comm comm // 控制参数
);
2、 多到一
2.1 Reduce
所有进程向同一进程发消息与是broadcast逆操作
int MPI_Reduce(
const void *sendbuf, // 发送缓冲区 (所有人都要填)
void *recvbuf, // 接收缓冲区 (仅 Root 有效,存最终结果)
int count, // 数据个数 (每个进程提交多少个数据)
MPI_Datatype datatype, // 数据类型
MPI_Op op, // 归约操作符 (告诉 MPI 怎么算)
int root, // 根进程 Rank
MPI_Comm comm // 通信域
);
op (操作符):这是 Reduce 的灵魂。MPI 预定义了很多常用操作:
- MPI_SUM: 求和 (Sum) —— 最常用
- MPI_MAX: 求最大值 (Maximum)
- MPI_MIN: 求最小值 (Minimum)
- MPI_PROD: 求乘积 (Product)
- MPI_LAND: 逻辑与 (Logical AND)
- MPI_LOR: 逻辑或 (Logical OR)
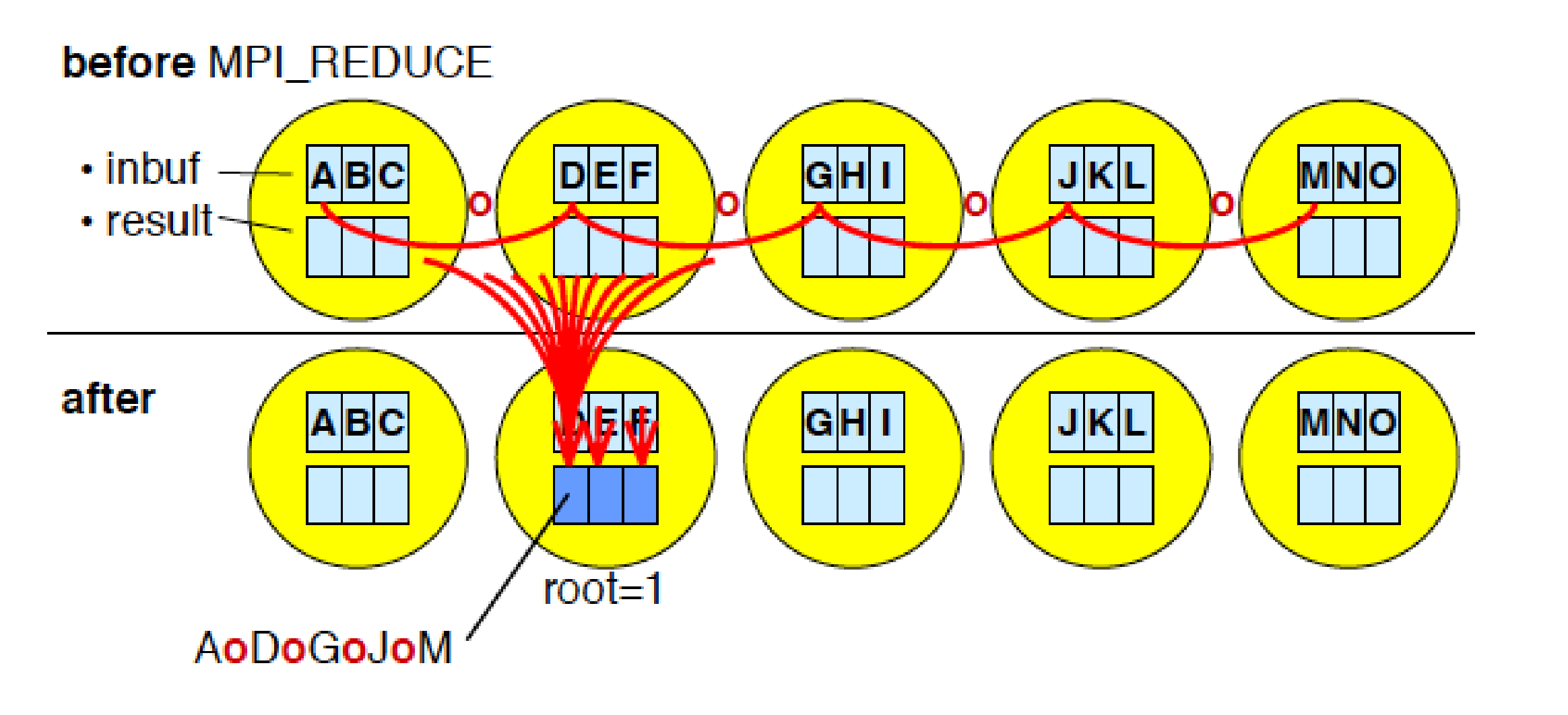
通过积分法求 π \pi π的值
#include <mpi.h>
#include <stdio.h>
#include <math.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
long n = 1000000; // 总共切分成 100万 个小矩形
double h = 1.0 / (double)n; // 每个矩形的宽
double sum = 0.0;
// 1. 每个进程计算属于自己那部分矩形的面积
// 步长为 size,即 Rank 0 算第 0, 4, 8... 个矩形
for (long i = rank + 1; i <= n; i += size) {
double x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x * x);
}
double my_pi = h * sum; // 这是当前进程算出来的“局部 pi”
printf("Rank %d calculated partial pi: %f\n", rank, my_pi);
// 2. 使用 Reduce 汇总结果
double pi = 0.0;
// sendbuf: &my_pi (每个人的局部结果)
// recvbuf: &pi (Root 用来存总结果)
// op: MPI_SUM (求和)
MPI_Reduce(&my_pi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
// 3. 只有 Root 打印最终结果
if (rank == 0) {
printf("Final Pi is approx: %.16f\n", pi);
}
MPI_Finalize();
return 0;
}
2.2 Allreduce
和Reduce类似但是没有root参数,所有进程都要获得reduce后的结果
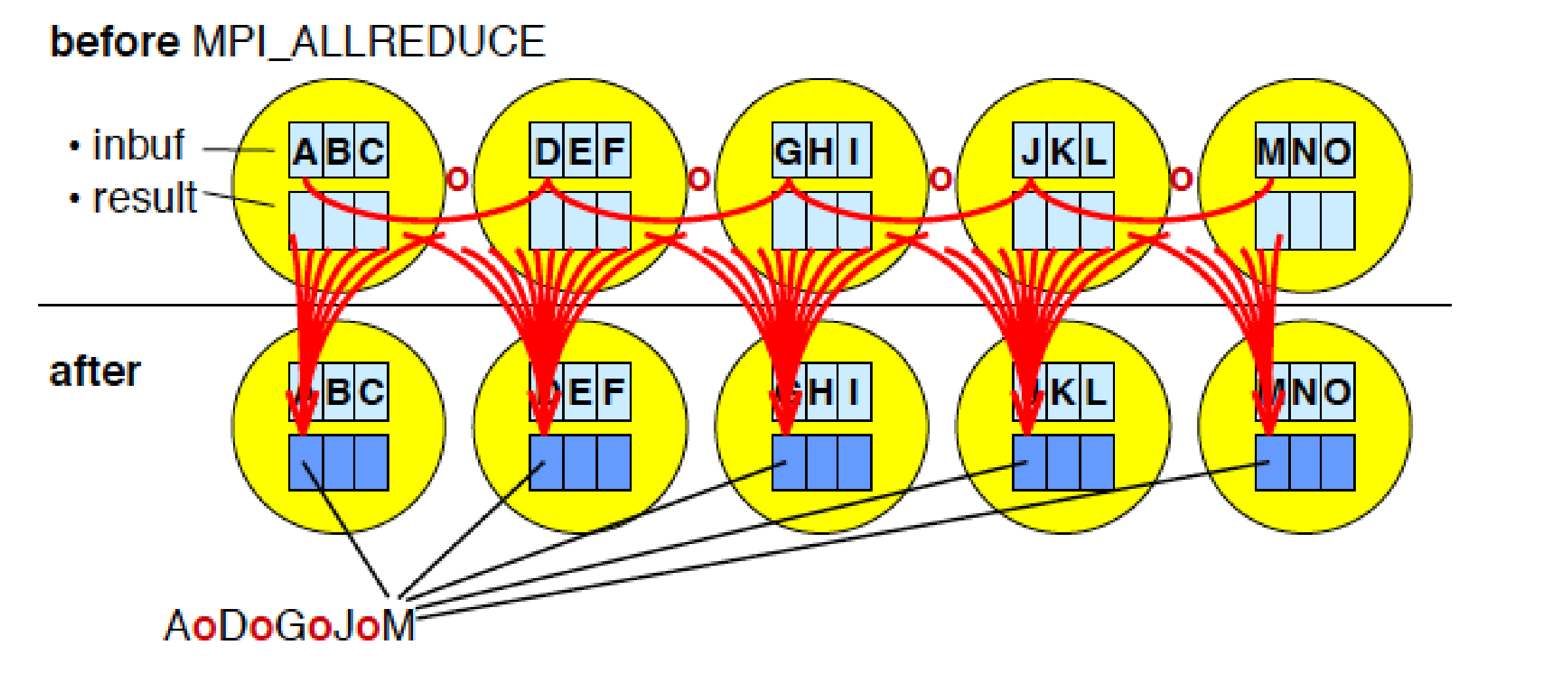
2.3 Reduce_scatter
和allReduce的区别是Reduce_scatter每个进程只拿到一部分规约的结果,而allreduce是拿到全部的结果。
2.4 Scan
MPI_Scan (前缀扫描 / 前缀和) 是 MPI 中一种非常特殊的组通信操作,它执行的是前缀归约 (Prefix Reduction) 计算。
对于通信域中的每一个进程 i(Rank 0 到 Rank n-1),MPI_Scan 会计算从 Rank 0 到 Rank i 所有进程输入数据的归约结果。
数学公式:假设每个进程 i 的输入数据是
A
i
A_i
Ai,操作符是
+
+
+ (SUM)。
Rank 0 的结果:
A
0
A_0
A0
Rank 1 的结果:
A
0
+
A
1
A_0 + A_1
A0+A1
Rank 2 的结果:
A
0
+
A
1
+
A
2
A_0 + A_1 + A_2
A0+A1+A2
…
Rank i 的结果:
∑
k
=
0
i
A
k
\sum_{k=0}^{i} A_k
∑k=0iAk
int MPI_Scan(
const void *sendbuf, // 发送缓冲区 (自己的数据)
void *recvbuf, // 接收缓冲区 (存累计结果)
int count, // 数据个数
MPI_Datatype datatype, // 数据类型
MPI_Op op, // 操作符 (MPI_SUM, MPI_MAX 等)
MPI_Comm comm // 通信域
);
计算前缀和
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 1. 每个进程准备自己的数据 (这里假设是 rank + 1)
// Rank 0: 1, Rank 1: 2, Rank 2: 3 ...
int my_val = rank + 1;
int prefix_sum = 0;
// 2. 执行 Scan
// 计算前缀和:Rank i 将得到 1+2+...+ (i+1) 的结果
MPI_Scan(&my_val, &prefix_sum, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Rank %d: Input = %d, Prefix Sum = %d\n", rank, my_val, prefix_sum);
MPI_Finalize();
return 0;
}
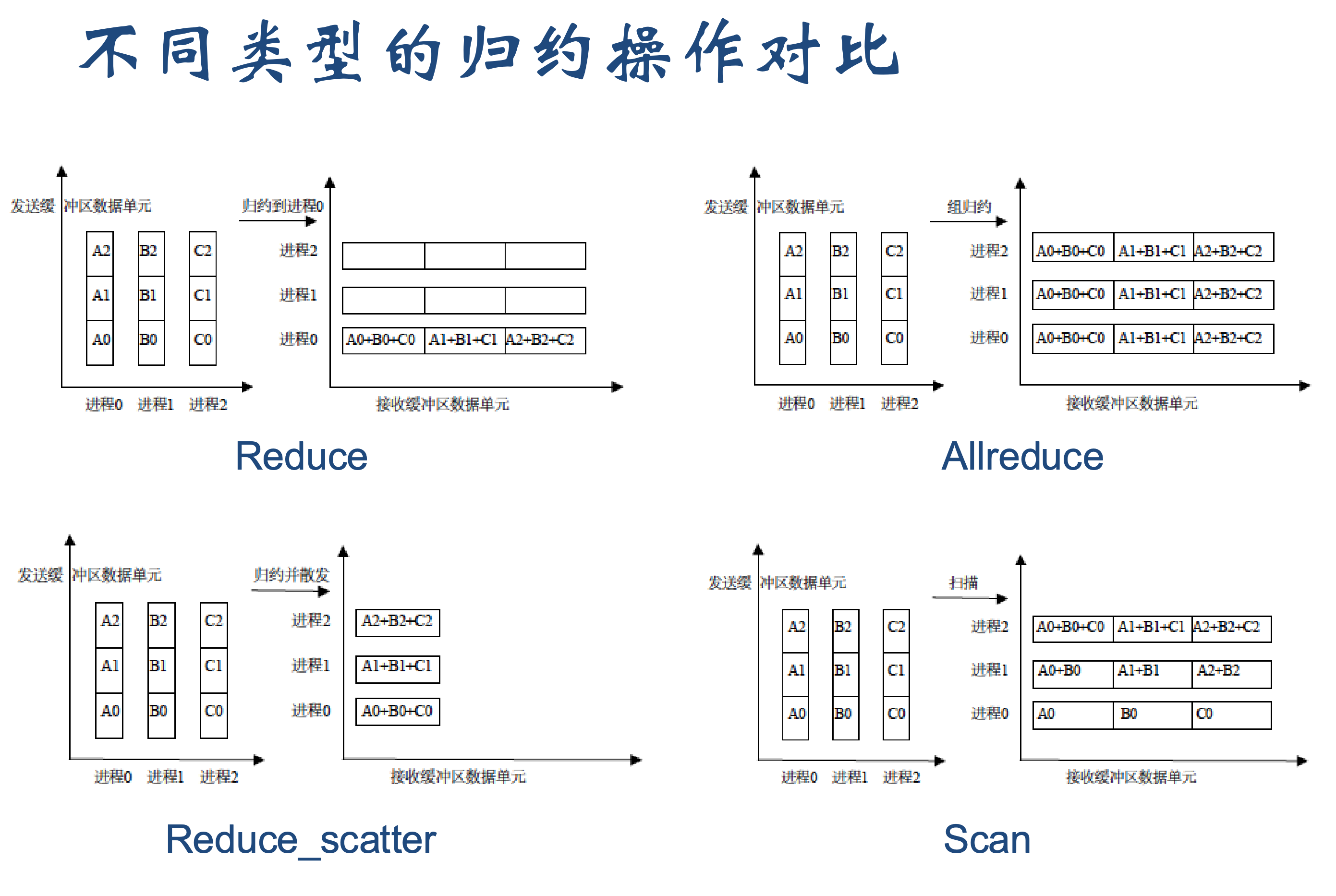
2.5 gather
MPI_Gather是MPI_Scatter逆操作,相当于通信域内所有进程(包括 Root 自己)手中的数据,收集到根进程 (Root) 的一个大缓冲区中。
int MPI_Gather(
const void *sendbuf, int sendcount, MPI_Datatype sendtype, // 发送方参数 (所有人都要填)
void *recvbuf, int recvcount, MPI_Datatype recvtype, // 接收方参数 (仅 Root 有效)
int root, MPI_Comm comm // 控制参数
);
sendbuf: 每个人(包括 Root)都要提供自己那份要上交的数据。recvbuf: 只有 Root 需要申请这块大内存(大小 = 进程数 × 每个人的数据量)。其他进程填 NULL 即可。- recvcount (接收个数) —— ⚠️ 高危!:这里填的含义是:“我准备从每一个进程接收多少个数据?”
这份代码是每个进程向root进程传递自己的数据rank * 10,root进程收集这些数据然后打印
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 1. 每个人准备自己的数据
int my_data = rank * 10;
printf("[Rank %d] My data is %d\n", rank, my_data);
// 2. 只有 Root 准备接收的大盘子
int *global_data = NULL;
if (rank == 0) {
// 假设有 4 个进程,这里就要申请 4 个 int 的空间
global_data = (int*)malloc(size * sizeof(int));
}
// 3. 执行 Gather
// 每个人上交 1 个 int,Root 从每个人那里收 1 个 int
MPI_Gather(&my_data, 1, MPI_INT, // 发送参数
global_data, 1, MPI_INT, // 接收参数 (注意 recvcount 是 1)
0, MPI_COMM_WORLD);
// 4. Root 打印结果
if (rank == 0) {
printf("[Root] 收集完毕: ");
for (int i = 0; i < size; i++) {
printf("%d ", global_data[i]);
}
printf("\n");
free(global_data); // 别忘了释放内存
}
MPI_Finalize();
return 0;
}
2.6 gatherv
MPI_Gatherv 是 MPI_Gather 的升级版(v 代表 Vector,向量/变长)。
它是 MPI_Scatterv 的逆操作。
int MPI_Gatherv(
const void *sendbuf, int sendcount, MPI_Datatype sendtype, // 发送端 (所有人)
void *recvbuf, // 接收端大缓冲区 (仅 Root)
const int *recvcounts, // [数组] 每个人分别交多少个? (仅 Root)
const int *displs, // [数组] 每个人交的数据放哪? (仅 Root)
MPI_Datatype recvtype, // 接收端类型 (仅 Root)
int root, MPI_Comm comm // 控制参数
);
3、 多到多
MPI_Alltoall它是“每一个进程都向每一个进程执行一次 Scatter
类似矩阵转置。

4、 同步
MPI_Barrier不传输任何数据,仅仅是让运行的快的进程停下来等待运行的慢的进程。
int MPI_Barrier(MPI_Comm comm);
#include <mpi.h>
#include <stdio.h>
#include <unistd.h> // 用于 sleep
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// 1. 模拟不同步的工作负载
if (rank == 0) {
printf("Rank 0: 我跑得飞快!\n");
} else {
sleep(2); // 模拟 Rank 1 偷懒睡了 2 秒
printf("Rank %d: 我睡醒了,才赶过来...\n", rank);
}
// 2. 设立栅栏
// Rank 0 会在这里卡住约 2 秒,等待其他进程
MPI_Barrier(MPI_COMM_WORLD);
// 3. 这里的代码只有等所有人到齐后才会执行
printf("Rank %d: 大家都到齐了,一起出发!\n", rank);
MPI_Finalize();
return 0;
}
输出结果:
Rank 0: 我跑得飞快!
(这里会停顿 2 秒...)
Rank 1: 我睡醒了,才赶过来...
Rank 0: 大家都到齐了,一起出发!
Rank 1: 大家都到齐了,一起出发!
四、 阻塞通信模式
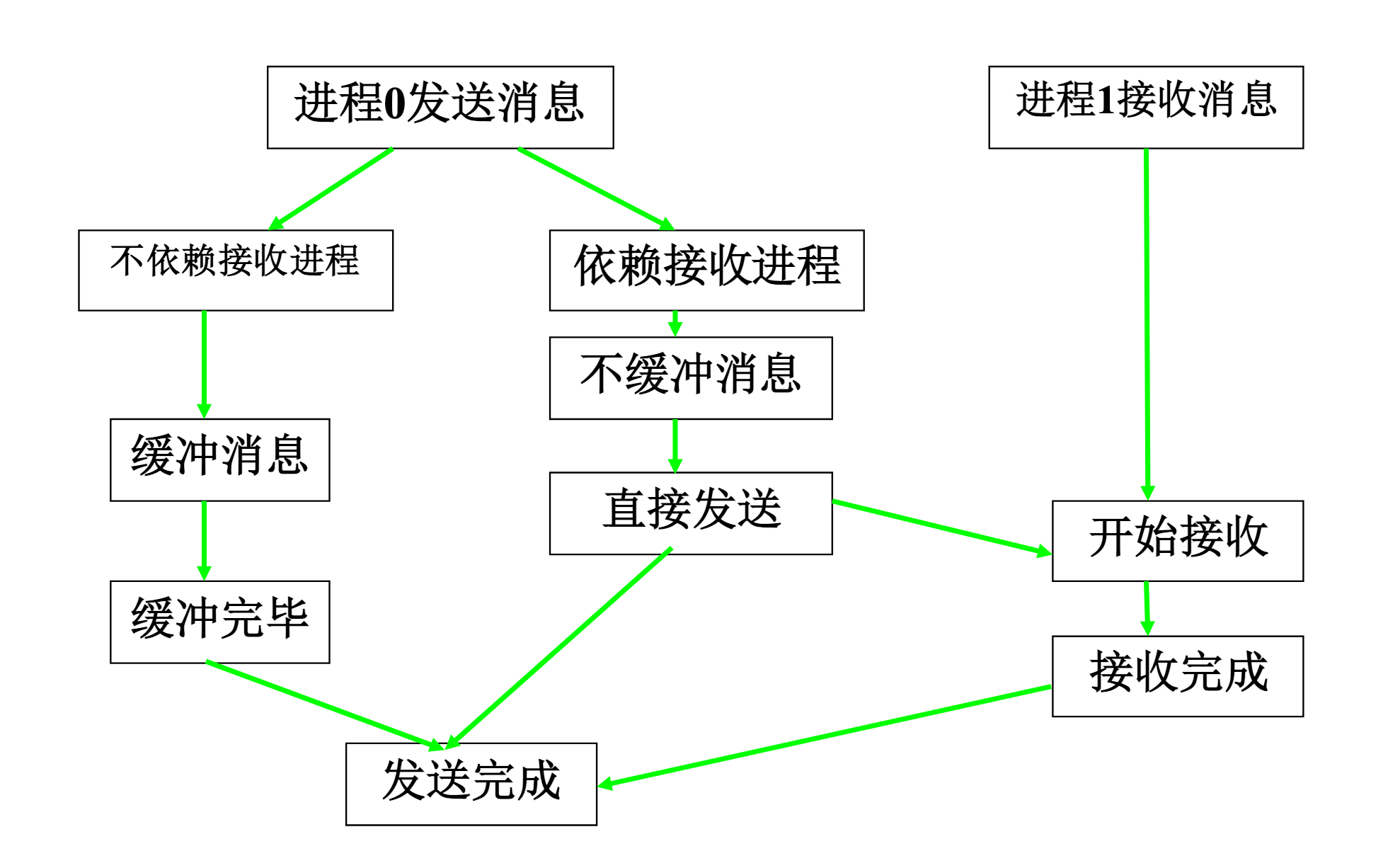
1. 标准通信模式
标准通信模式这里特指的是MPI_Send,从底层机制上看包括缓存和不缓存两种机制,是否缓存是有MPI决定的,而不是由程序员决定,,这通常是取决于通信传递内容的大小,如果内容较大则不采用缓存,如果内存较小则不采用缓存模式。
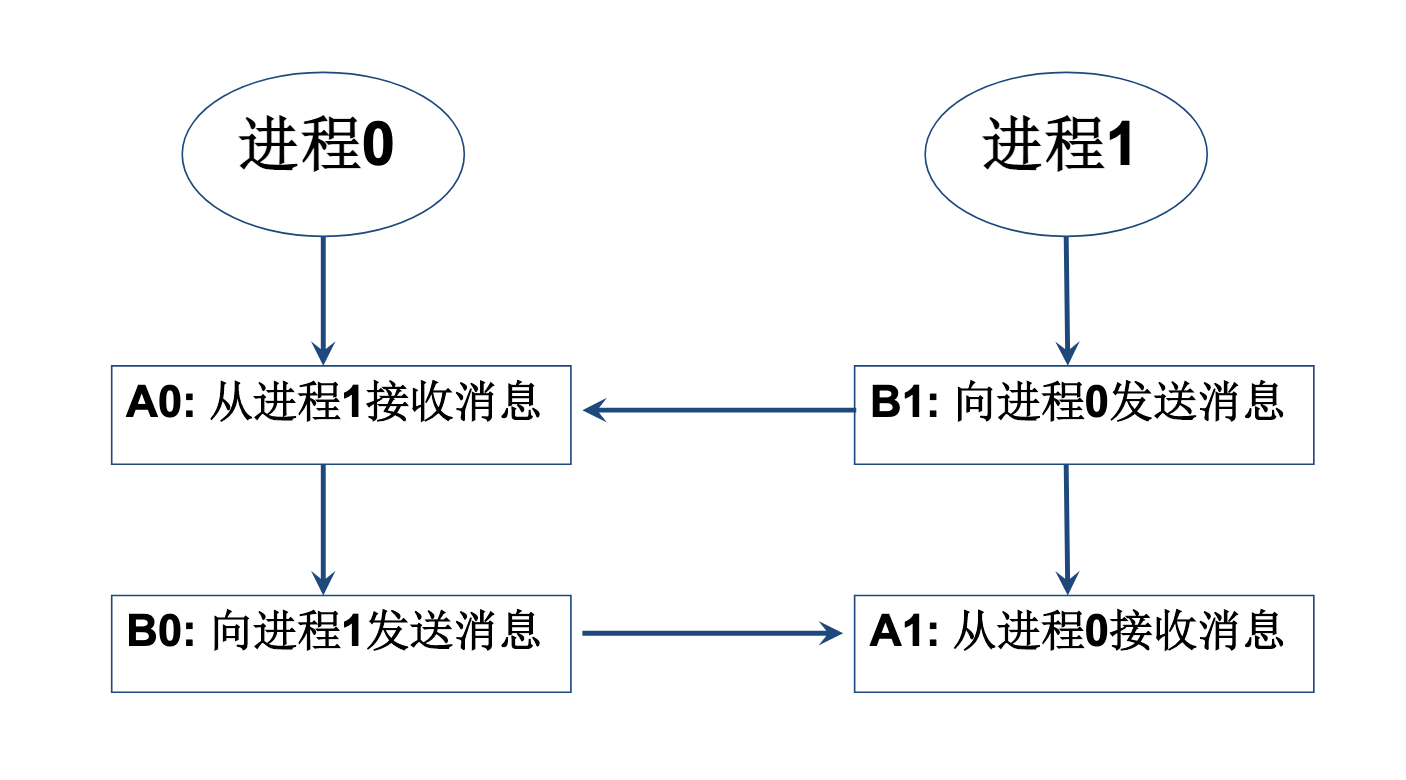
cycle waiting循环等待死锁
MPI_Comm_dup (MPI_COMM_WORLD, &comm);
if(myid==0)
{
MPI_Recv(bufA0,1,MPI_Float,1,101,comm,status);
MPI_Send(bufB0,1,MPI_Float,1,100,comm);
} else if(myid==1)
{
MPI_Recv(bufA1,1,MPI_Float,0,100,comm,status);
MPI_Send(bufB1,1,MPI_Float,0,101,comm);
}

避免死锁就是避免循环等待
if ( myid==0)
{
MPI_Recv(bufA0,1,MPI_Float,1,101, comm, status);
MPI_Send(bufB0,1,MPI_Float,1,100, comm);
} else if(myid==1) {
MPI_Send(bufB1,1,MPI_Float,0,101, comm);
MPI_Recv(bufA1,1,MPI_Float,0,100, comm, status);
} ......
2. 缓存通信模式
这里的缓存通信模式是指的显示的缓存。
MPI_Bsend,用户手动对通信缓存区进行申请、使用和释放,和MPI_Send的区别就是使用的是系统分配的缓存区,还是用户申请的缓存区。
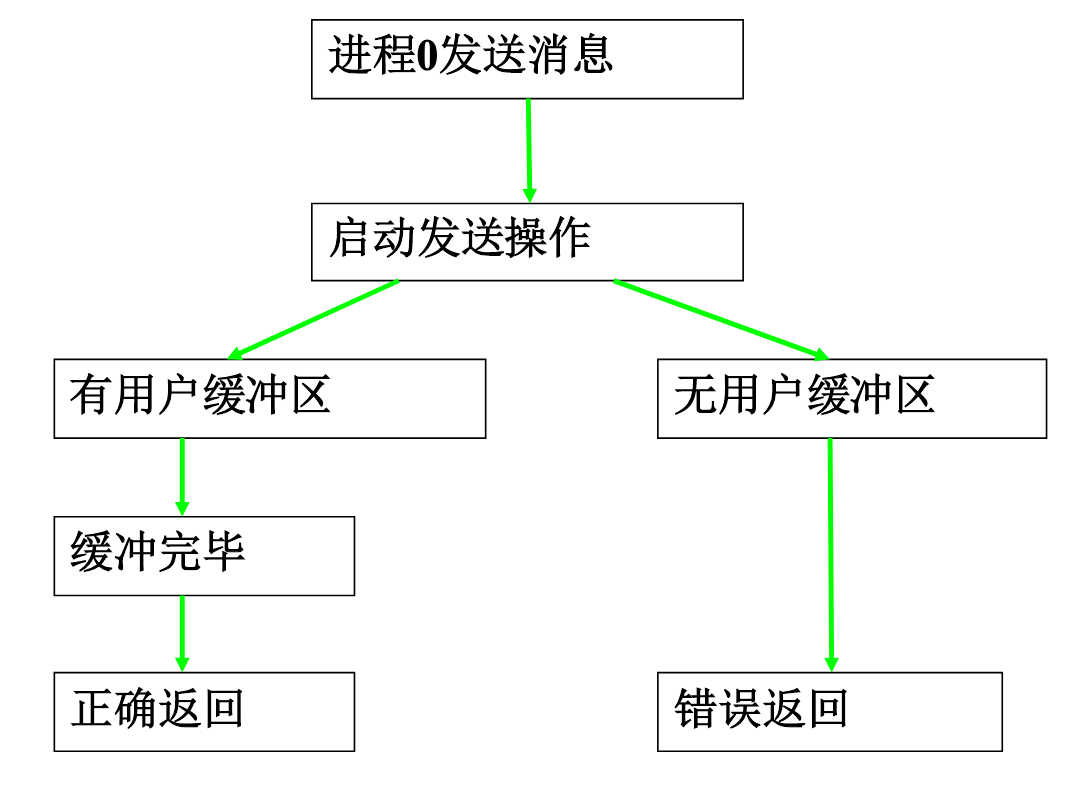
MPI_BUFFER_ATTACH:将自己申请的内存交给MPI使之成为缓存区。
MPI_BUFFER_DETACH:回收MPI中的缓存区,这一调用是阻塞调用,他一直阻塞到缓存被发送完才返回,返回后用户可以选择释放缓存区,或者继续使用缓存区。
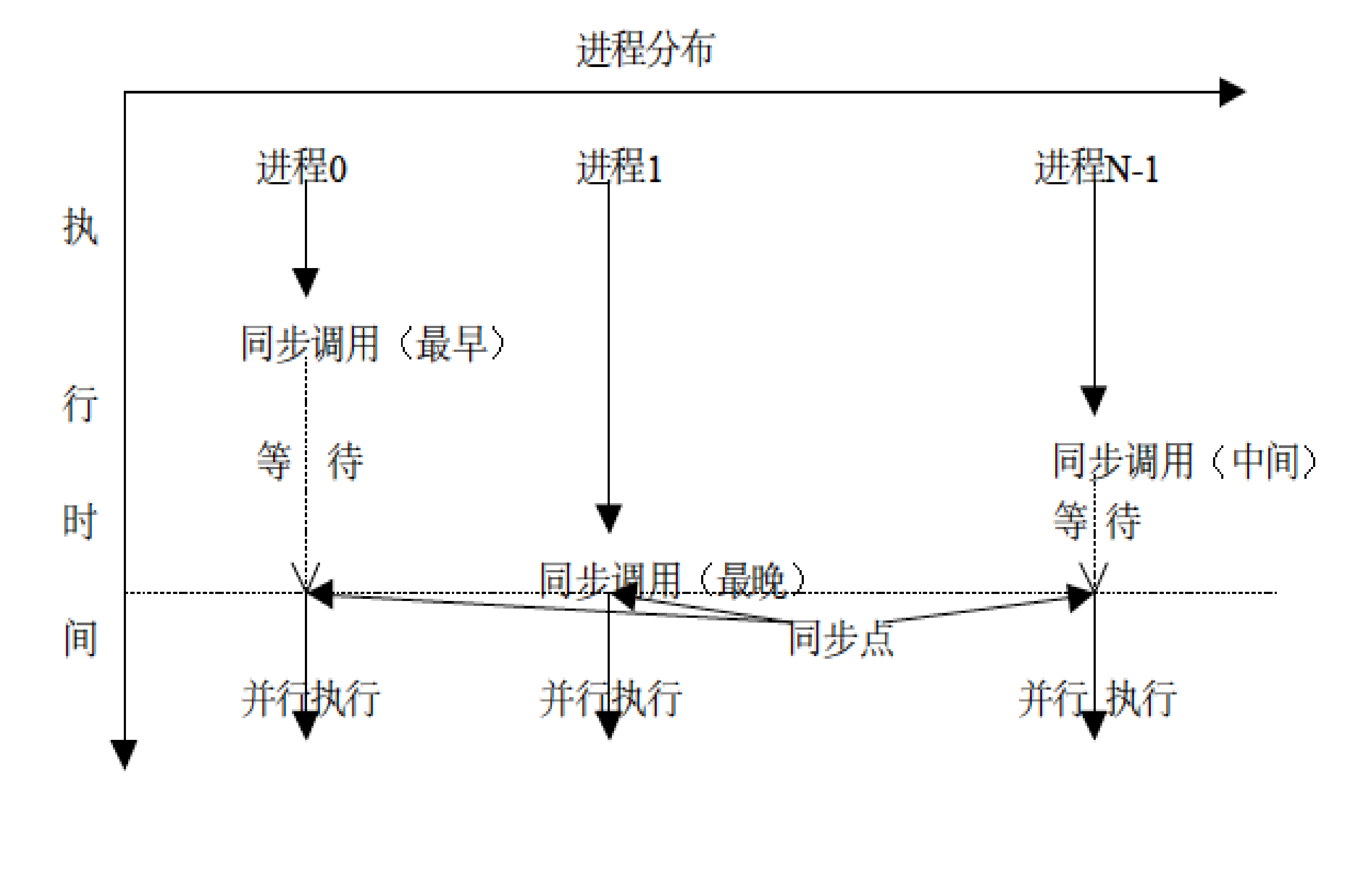
3. 同步通信模式
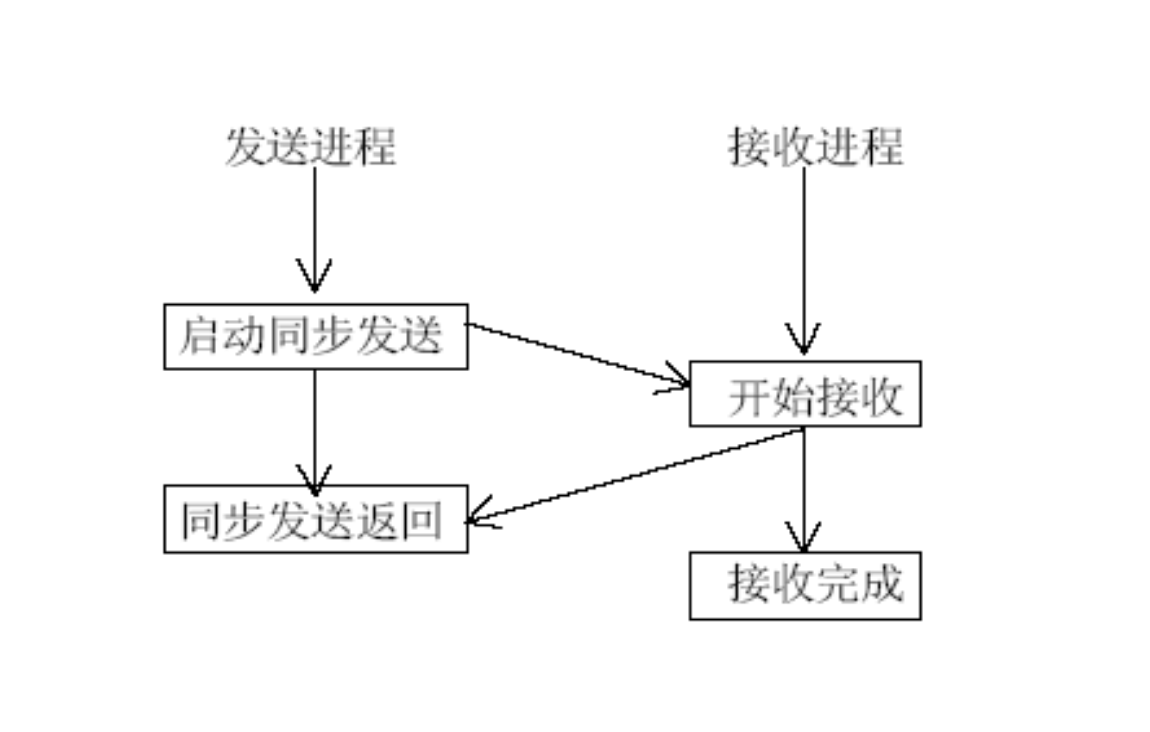
MPI_Ssend
当发送方调用 MPI_Ssend 时,它不仅要把数据发出去,还要一直等待,直到接收方调用了匹配的 MPI_Recv 并且开始接收数据了,发送方才会从函数返回。
同步点:发送和接收在时间上通过这个操作“同步”了。发送方结束 Ssend 时,它不仅知道数据发出去了,还确切地知道接收方已经准备接收了。
4. 就绪通信模式
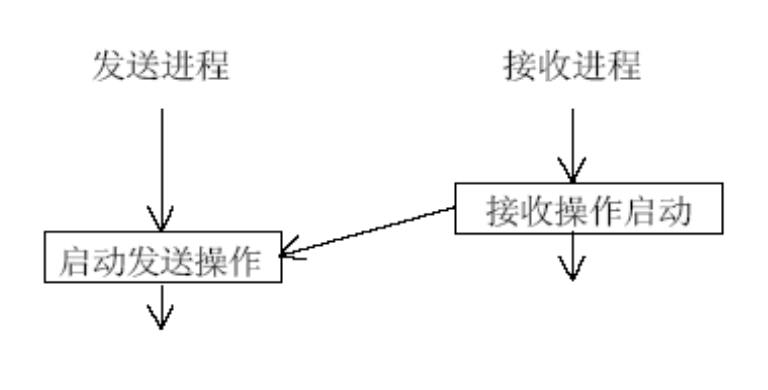
这里要求在调用MPI_Rsend时,接收程序已经调用MPI_Recv了。
只有当接收进程的接收操作已经启动时,才可以在发送 进程启动发送操作,否则,当发送操作启动而相应的接 收还没有启动时,发送操作将出错。
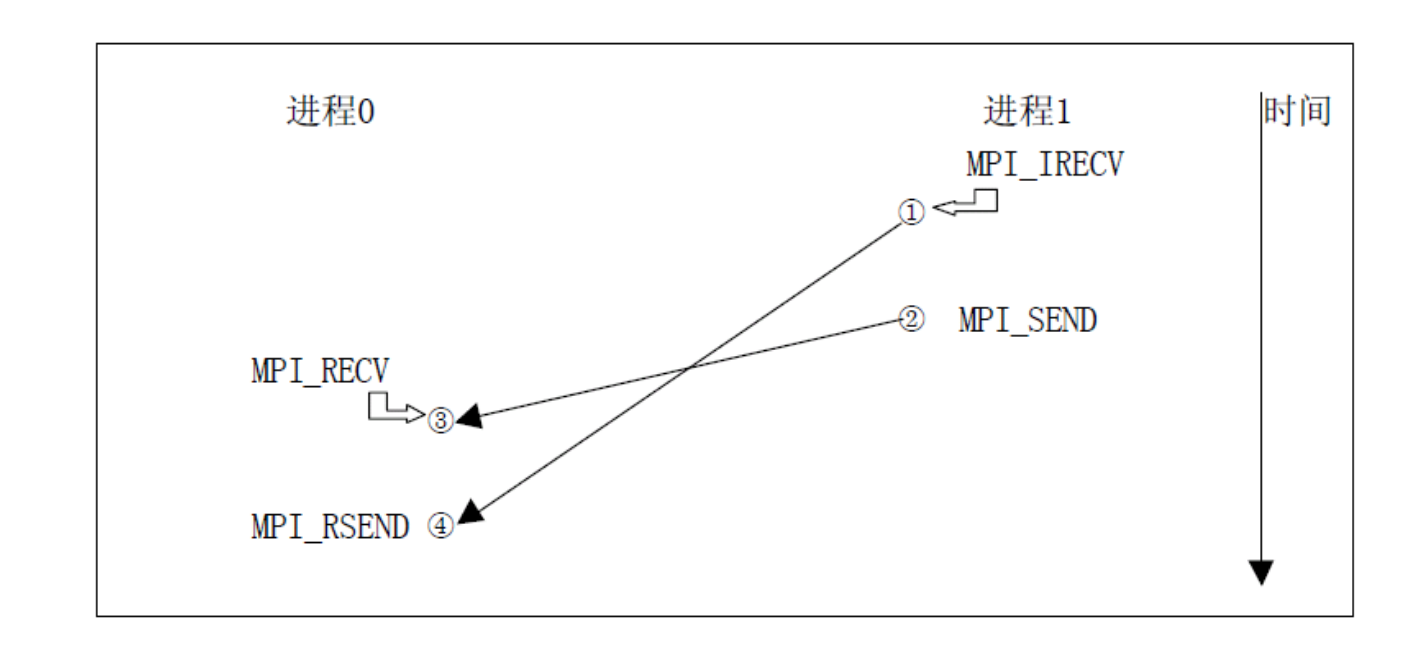
就绪通信模式很容易导致死锁,下面是一种安全的就绪通信模式,这里是一方采用非阻塞的Recv,就比如进程1调用MPI_IRECV后接着执行下面的MPI_SEND,而不是等待对方进程的MPI_RSEND,这里就不会导致死锁,如果双方都调用MPI_RECV就会导致死锁。

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









