






首先Pytorch中grid_sample函数的接口声明如下:
torch.nn.functional.grid_sample(input, grid, mode='bilinear', padding_mode='zeros', align_corners=None)
简单来说就是,提供一个input的Tensor以及一个对应的grid网格,然后根据grid中每个位置提供的坐标信息(这里指input中pixel的坐标),将input中对应位置的像素值填充到grid指定的位置,得到最终的输出。
其中,input、grid和output分别表示输入Tensor,映射网格Tensor和输出Tensor,其尺寸如下所示:
i
n
p
u
t
:
(
N
,
C
,
H
,
W
)
g
r
i
d
:
(
N
,
H
,
W
,
2
)
o
u
t
p
u
t
:
(
N
,
C
,
H
,
W
)
input: (N,C,H,W)\\ grid:(N,H,W,2)\\ output:(N,C,H,W)
input:(N,C,H,W)grid:(N,H,W,2)output:(N,C,H,W)
其中grid中的2表示x,y方向的两个通道的映射,H,W是尺寸。这里一般会将(x,y)归一化到[-1,1],其中[-1,-1]代表左上角的像素,[1,1]代表右下角的像素。首先,以下代码先生成一个恒等的采样矩阵,然后进行采样。这里的恒等采样矩阵就是指左上角是[-1,-1],右上角是[-1,1],左下角是[1,-1],右下角是[1,1],并且元素均匀分布的矩阵,该矩阵是我们采样的原始参考grid网格。
import torch.nn.functional as F
import torch
featSize = 5
#生成恒等网络采样grid
gridY = torch.linspace(-1, 1, steps = featSize).view(1, -1, 1, 1).expand(1, featSize, featSize, 1)
gridX = torch.linspace(-1, 1, steps = featSize).view(1, 1, -1, 1).expand(1, featSize, featSize, 1)
grid = torch.cat((gridX, gridY), dim=3).type(torch.float32)
#生成输入tensor(input),大小为[1,1,featSize,featSize],数据分布[1,2,...,featSize*featSize]
predict_roof = torch.linspace(1,featSize**2,steps=featSize**2,dtype=torch.float32).reshape(featSize,featSize)
predict_roof = (predict_roof.unsqueeze(dim=0)).unsqueeze(dim=0)
#使用恒等采样矩阵grid对input进行采样
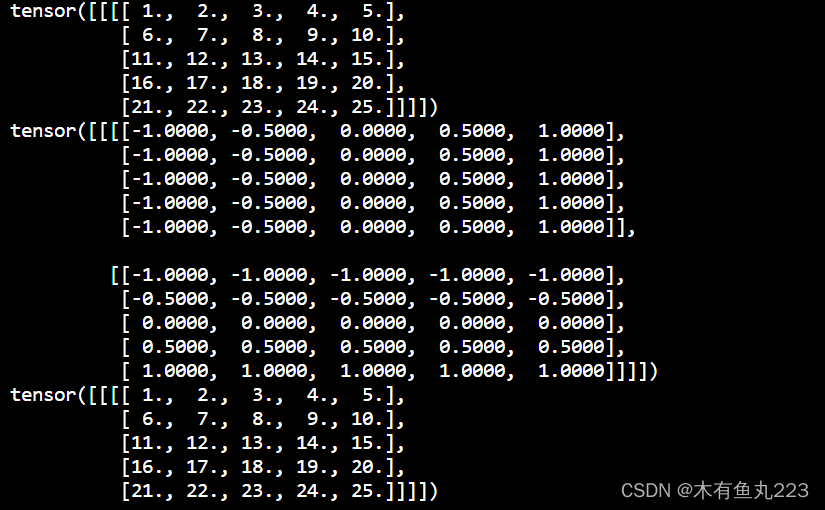
trans_feature = F.grid_sample(predict_roof,grid,align_corners=True)
print(predict_roof)
print(grid.permute(0,3,1,2))
print(trans_feature)
输出结果为:可见恒等采样矩阵的采样结果是不改变原始的数据分布。
值得注意的是,F.grid_sample()中存在一个bool参数(align_corners)
- 当该参数设置为True时:采样网格的坐标被视为指向像素的角点。这种设置通常用于对齐图像边缘的像素。
- 当该参数设置为False时:采样网格的坐标被视为指向像素之间的中心点。这种设置通常用于保持图像的整体形状和分辨率。
以下对上述两个设置进行详细的说明:
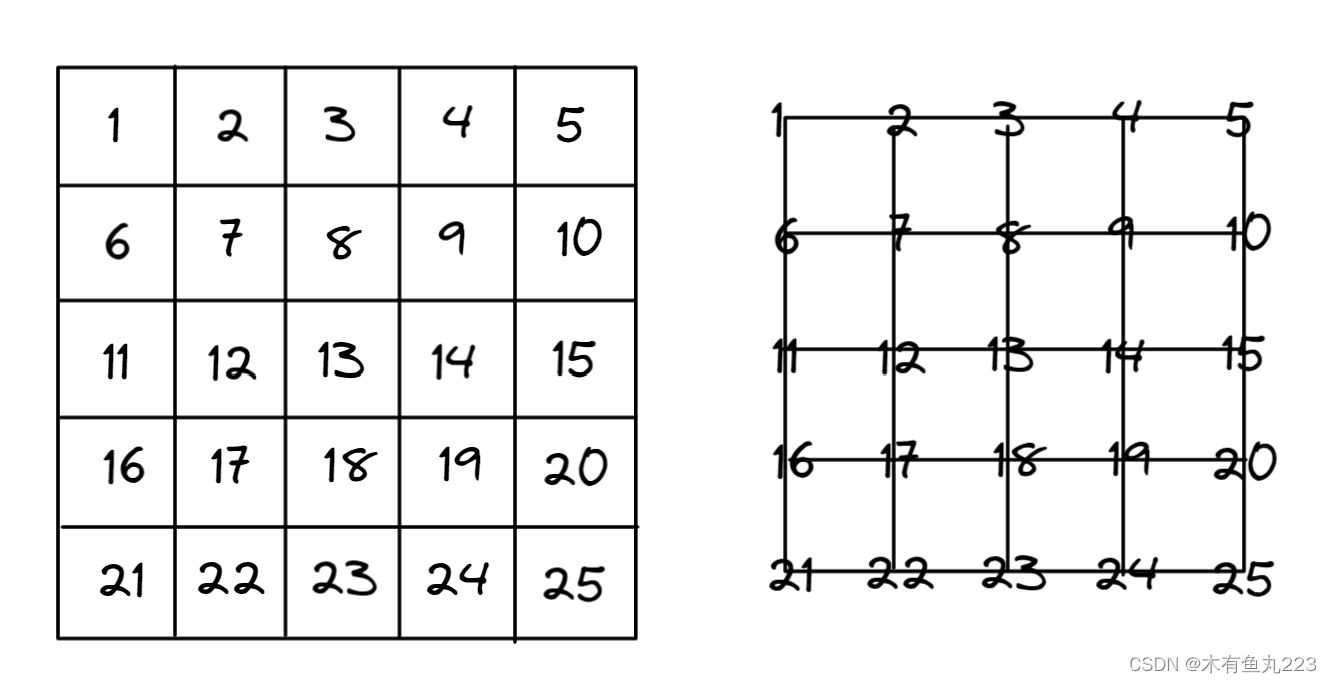
首先,我们如何看待一副图像中像素的组成。这里又两种方式:1、看作是方块;2、看作是点。如下图所示。对于一个
5
×
5
5\times 5
5×5的一副图像。
- align_corners = False:
-原始像素可以看作是一个点,如上述右图所示。映射网格grid的数据点被视为指向像素之间的中心点。计算过程示意图如下所示。需要注意的是,原始图像大小为 5 × 5 5\times 5 5×5,输出Tensor大小为 6 × 6 6\times6 6×6,并且F.grid_sample()的padding方式是zeros填充方式。
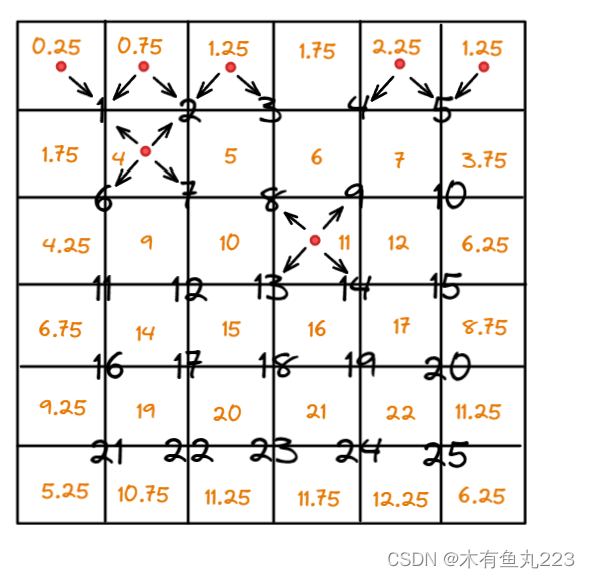
上述输出tensor左上角的像素对应(-1,-1),右下角像素对应(1,1)。代码计算结果如下所示。
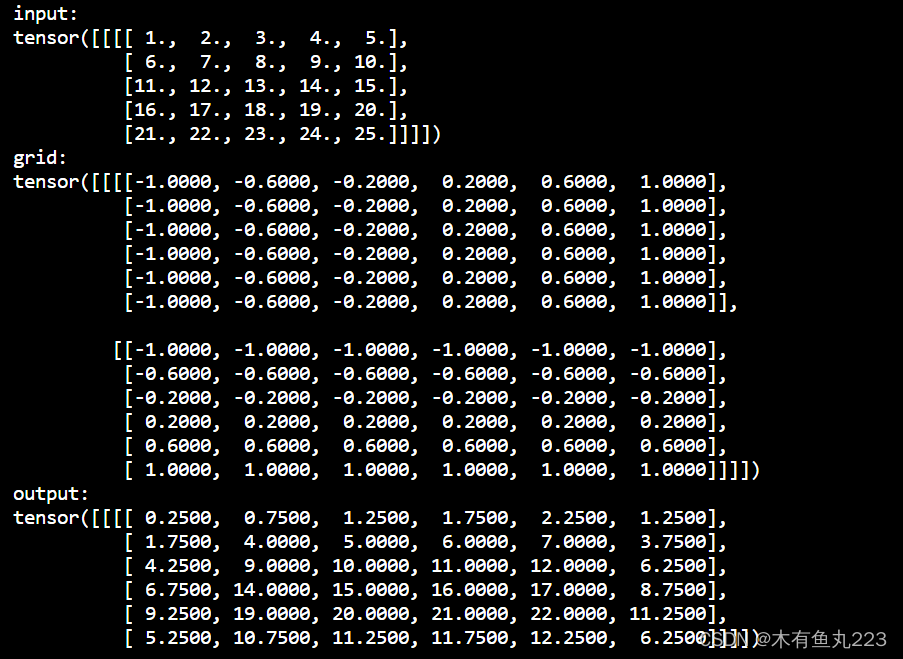
- align_corners = True:
原始像素可以看作是一个像素方框,如上述左图所示。映射网格grid的数据点被视为指向像素之间的角点。计算过程如下所示。输入Tensor大小为 5 × 5 5\times 5 5×5,输出大小为 5 × 5 5\times 5 5×5。
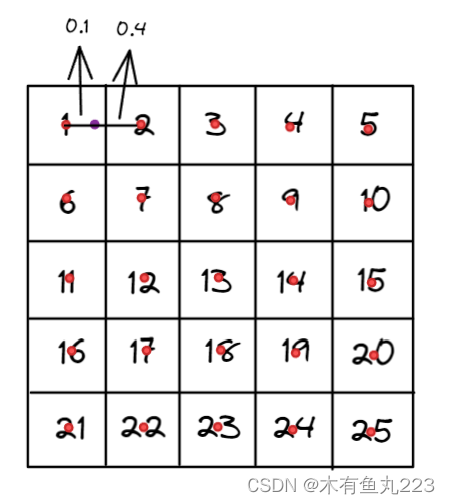
左上角对应的grid坐标为(-1,-1),右下角对应的grid坐标为(1,1)。上述grid为恒等采样矩阵时,输出Tensor和输入Tensor是一样的。为了说明上述的运算过程,现在假设某一个像素点的grid映射坐标为(-0.9,-1),即上述示意图中的紫色点,该点距离左点0.1,距右点0.4。即有如下计算:
0.1
0.4
+
0.1
×
2
+
0.4
0.4
+
0.1
×
1
=
1.2
\frac{0.1}{0.4+0.1}\times2+\frac{0.4}{0.4+0.1}\times1 = 1.2
0.4+0.10.1×2+0.4+0.10.4×1=1.2
代码中设置映射grid[0,0,0,:] = [-0.9,-1],即输出左上角映射到[-0.9,1],经过以上计算,左上角点应该是1.2。结果如下所示。
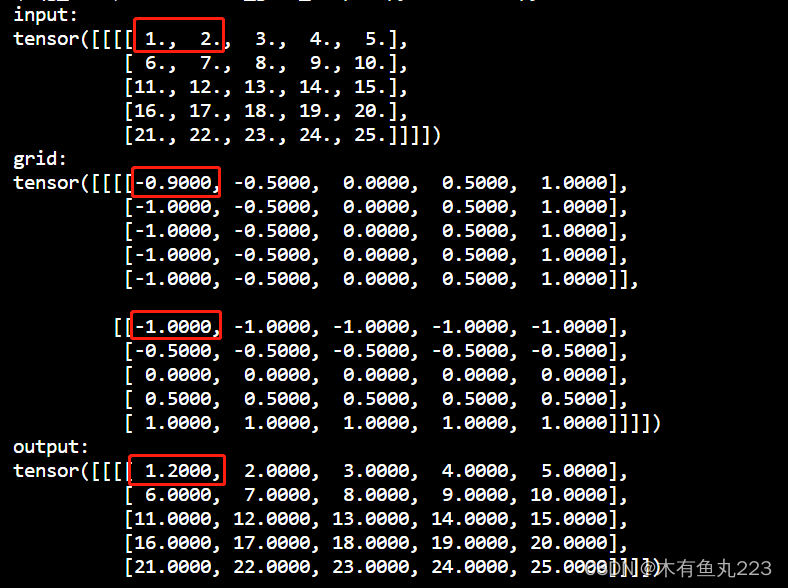
总结:本质上来说,align_corners 设置映射的网格grid是否与输入Tensor对齐,False代表不对齐,True代表对齐。以后提供应用代码,今天有点累,想摆烂了。未完待续…

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









