







手写系列是本人学习的相关记录,主打一个自己实现核心代码和手写推导过程,不会调用任何现成包。会分享出来所有代码。水平有限,欢迎大家批评指导。
1. 支持向量机(SVM) 简介
在机器学习领域,支持向量机(SVM)是一种强大且广泛使用的算法,它的核心思想是找到一个最优的超平面,使得两类样本在该超平面两侧的间距最大化。这种方法也被称为最大间隔分类器,其目标是找到一个决策边界,使得正负样本之间的间隔最大。
SVM的主要优点在于其优秀的泛化能力。它可以有效地处理高维数据,并且在处理非线性问题时,通过引入核函数,SVM也能得到很好的分类效果。此外,SVM算法对于决策边界附近的样本点非常敏感,这使得SVM在处理噪声数据时具有较好的稳定性和鲁棒性。然而,SVM也存在一些缺点。首先,当训练样本量较大或者特征维数较高时,SVM的学习效率较低。此外,SVM的性能严重依赖于选择的核函数和对应的参数,这需要用户具有一定的专业知识和经验。
我们通过下面这幅图来体会一下:什么叫做“找到一个最优的超平面”?
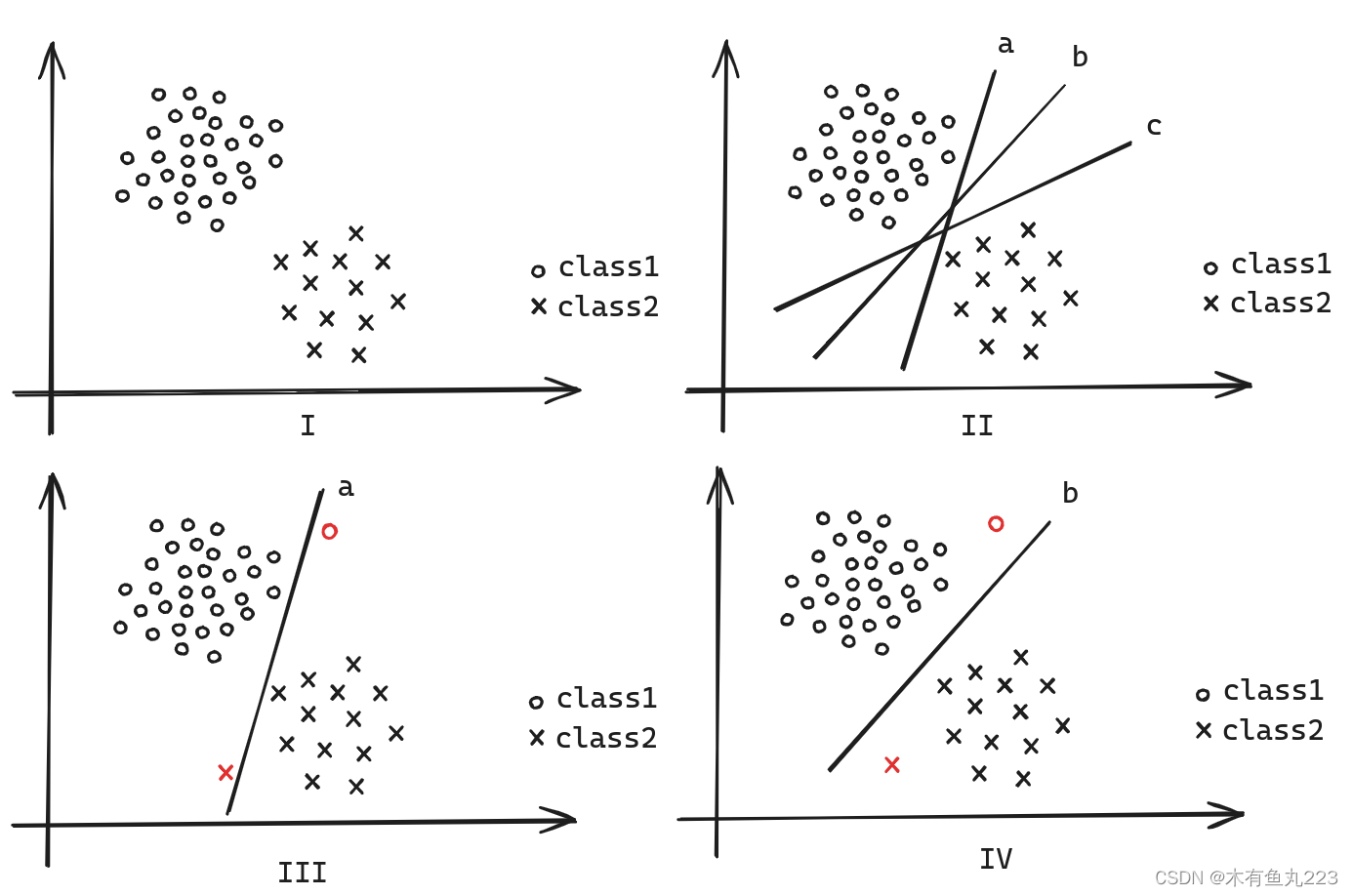
首先从上图I中可以知道,我们有一堆数据,分为两类(叉叉和圈圈)。很明显我们可以画出很多条直线(a b c)将两类分开。我们一般会直观的认为直线b比a和c分类效果要好。具体原因如图III,a直线会将红色的两个样本分类错误,但是从图IV可知,b线会正确分类。那么如何很好的描述直线b呢?什么样的直线最好?
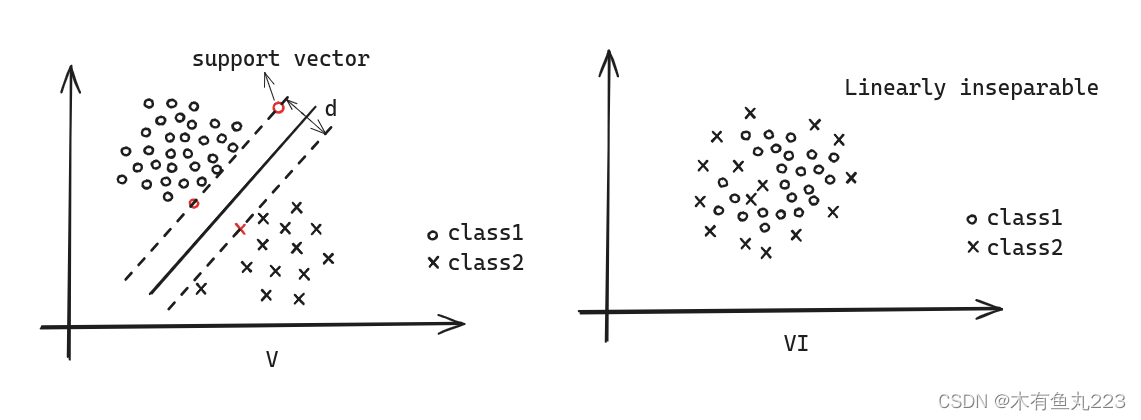
根据图V,我们有以下描述:如果给我一条分类器
l
l
l,保持其斜率不变,上下移动直到接触到一个或者两个向量停止(上下两条虚线),定义两条虚线之间的距离为
d
d
d,如果找到一条直线
l
l
l,使得
d
d
d最大,则说明
l
l
l是最好的。
这个定义的核心思想就是:分类器 l l l不止需要将两类分开,还需要保证两类之间的距离是最远的。可以验证的是图II中a和c的距离 d d d比b要小。所以,b最好。实际上,SVM之所以经典,是因为它背后有一套非常漂亮的数学理论。我们接下来尝试解释清楚这套数学理论。
2. 支持向量机(SVM)核心数学解释
对于SVM的分类任务,我们有以下数学描述:

2.1 线性可分SVM
上述任务本质上就是一个二分类任务(标签为1和-1),找到一个超平面意味着我们需要通过训练得到一个
(
W
,
b
)
(W,b)
(W,b)使得平面
W
T
X
+
b
=
0
W^TX+b=0
WTX+b=0能够很好的将样本分开。根据支持向量点
X
1
X_1
X1到平面的距离公式有以下推导:
d
=
∣
W
T
X
1
+
b
∣
∣
∣
W
∣
∣
d=\frac{|W^TX_1+b|}{||W||}
d=∣∣W∣∣∣WTX1+b∣

这里需要解释的有两点:
- 1、 W T + b = 0 W^T+b=0 WT+b=0和 a W T + a b = 0 aW^T+ab=0 aWT+ab=0实际上表示同一个超平面,添加缩放因子 a a a不改变超平面本身。这样可是使得距离d只和 ∣ ∣ W ∣ ∣ ||W|| ∣∣W∣∣有关系,这样最大化d求出来的平面 ( W 1 , b 1 ) (W_1,b_1) (W1,b1)和实际的 ( W , b ) (W,b) (W,b)只相差一个常数 a a a。
- 2、SVM的优化问题中的限制条件中的“>= 1”实际上和缩放因子 a a a的意思是一样的,最后都可以归因到相差一个常数 a a a。这个改为1是为了后续的计算方便。
线性可分的SVM的优化问题是一个典型的二次规划问题,该问题在凸优化理论中存在现成的求解方法。
2.2 线性不可分的SVM
说实话,上述线性可分的情况对于SVM理论来说完全就是小儿科。SVM之所以很强大主要表现在处理线性不可分的情况。我们首先通过以下两个例子来考虑下什么是线性不可分。
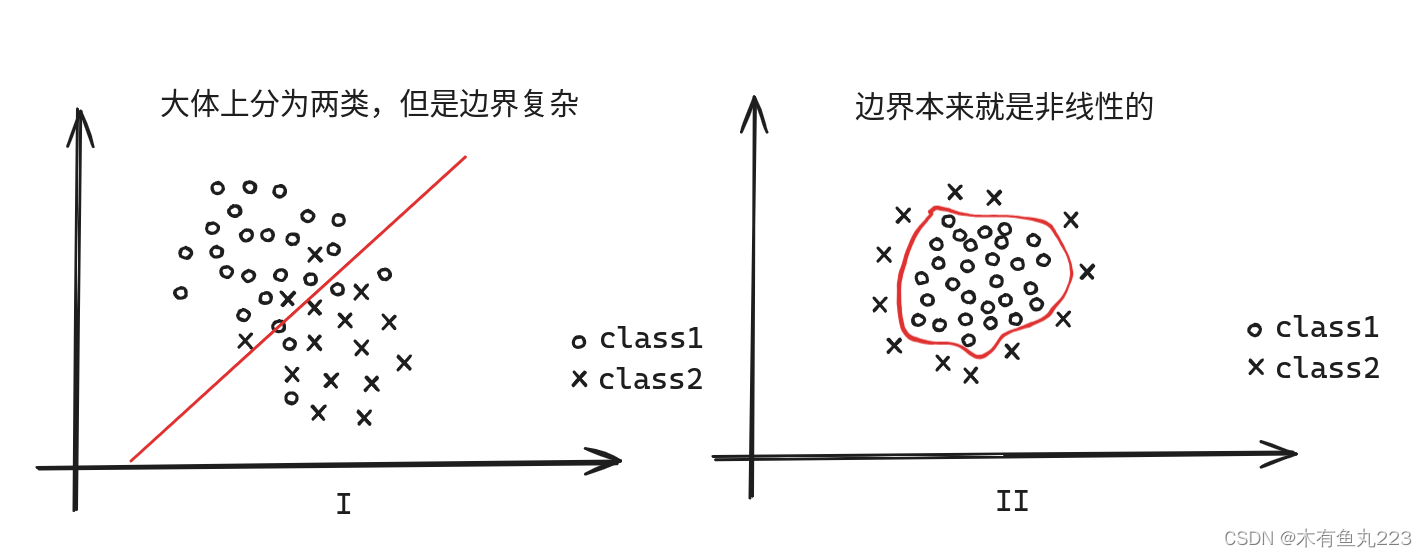
第一种情况,我们可以通过添加松弛变量的方法来进行解决(本质上还是找一个平面)。第二种情况找的就不是一个平面,我们需要通过高维映射来解决。

限制条件中添加松弛变量
ξ
i
\xi_i
ξi意思是我们对于点的分类标准没有那么严格,假设
ξ
i
\xi_i
ξi很大,意味着限制条件不存在,即不进行分类了,随便了,摆烂了,随便来一个点都通过。所以
ξ
i
\xi_i
ξi不能很大,我们在最小化中添加了后续的正则化项,使得
ξ
i
\xi_i
ξi不能很大。这样我们通过优化找的超平面实际上是在最小的允许范围内找一个超平面将样本分开,这样适合上图中I的情况(样本本身分为两类)。
但是针对图II的情况,去找超平面本身就是没有意义的。我们需要找一个曲面。为此,SVM引入了高维映射。有一个理论是,在低维上线性不可分的数据集,映射到越高维,越有可能变成线性可分。如下图所示:
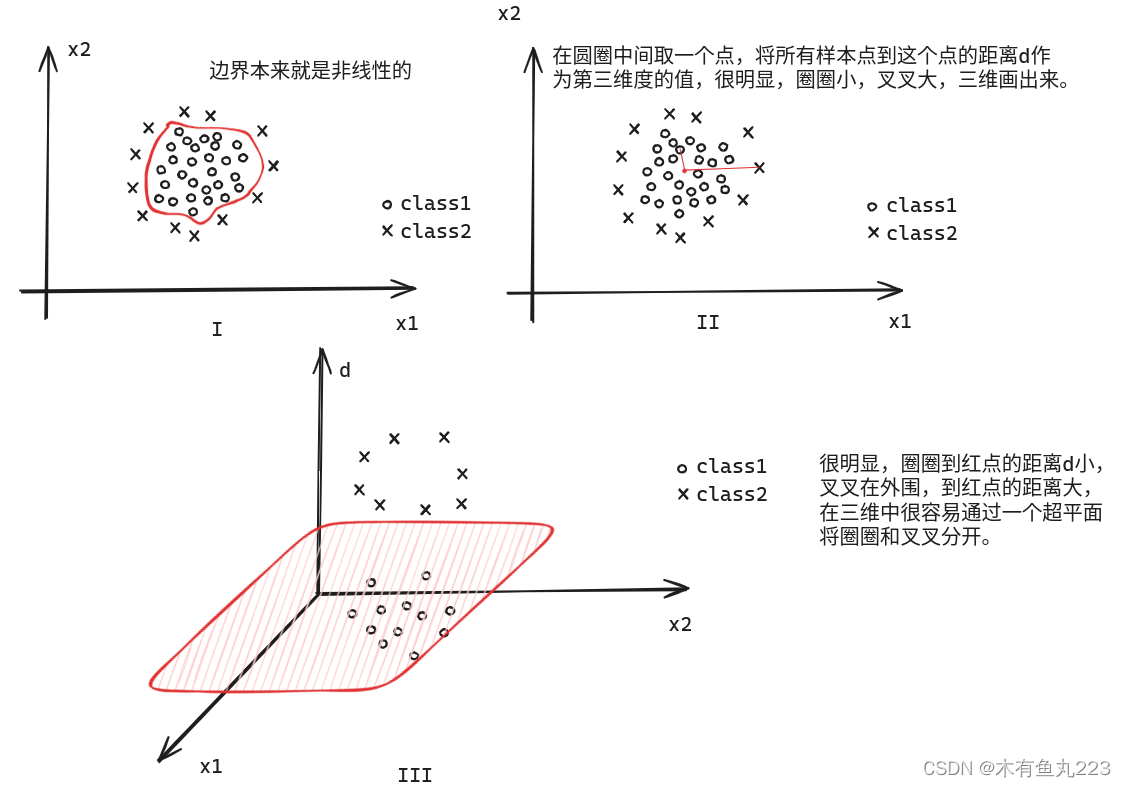
当然,取个点然后求距离本质上就是将二维映射到三维,上述这个例子只是说明低维不可分到高维上面就会变的可分。树立直观的感受,对于记忆和学习是很重要的。
SVM使用的不是这种很简单的高维映射,它的做法:
- 1、将高维映射 ϕ ( x ) \boldsymbol{\phi}(x) ϕ(x)设定为很高的维度/无限维度;
- 2、我们可以不知道高维映射
ϕ
(
x
)
\boldsymbol{\phi}(x)
ϕ(x)的显示表达,只需要知道一个核函数
K
(
X
1
,
X
2
)
K(X_1,X_2)
K(X1,X2),则SVM优化问题仍然可解。
K ( X 1 , X 2 ) = ϕ ( X 1 ) T ϕ ( X 2 ) K(X_1,X_2)=\phi(X_1)^T\phi(X_2) K(X1,X2)=ϕ(X1)Tϕ(X2)
OK,到这里我们总结一下添加了核函数的SVM算法的优化问题。

接下来求解这个带核函数的优化问题,需要使用到凸优化理论中的一些定理,如果直接在此补充这些知识将会造成阅读的撕裂感。并且这些推导实际上在几十年前就已经被证明是正确的,现在自己推导一遍也只为说服自己。记忆推导过程将会没有意义。在此,我直接列出结果,详细的推导过程我会在附件中给出。

实际上,带核函数的SVM问题,其对偶问题是典型的凸优化理论中求解的问题。该问题可使用诸如SMO等方法求解。该方法详细的介绍我将会在后续的博客中给出。总而言之,经过上述的训练,可以得到一个比较好的分类超平面。
4. 反思与总结
SVM算法作为经典的分类算法,其优秀就优秀在背后优雅的数学理论。但是,优秀就意味着比较复杂,本人在看书和听课的过程中有一个很明显的体会:看完推导之后,就忘了它到底在解决什么问题,推完之后:哇,好牛逼,好厉害。半小时后,忘了,说了啥来着。本人认为这些数学推导没有必要成为学习的拦路虎,早就有人证明他们是正确的,我们没有必要去质疑。推导的意义在于说服自己。对于SVM,我们需要有以下记忆点:
- 1、SVM本质上是找到一个最优的超平面,使得两类样本在该超平面两侧的间距最大化。这种方法也被称为最大间隔分类器,其目标是找到一个决策边界,使得正负样本之间的间隔最大;
- 2、SVM对于线性可分的数据集可将问题转换为一个简单的二次规划问题;
- 3、SVM对于线性不可分的数据集,通过将低维的数据映射到高维的方法。并且我们可以不知道高维映射的显示表达式,只需要知道一个核函数 K ( X 1 , X 2 ) K(X_1,X_2) K(X1,X2),就可以将至转换为SMO等算法可解的优化问题。然后常用的核函数有高斯核(映射到无限维),多项式核(映射到有限维)等。
SVM是一个很优秀的分类器,其不止考虑到了要将两类样本分开,还考虑到了如何分开是最好的。学霸考100分是因为卷子只有100分,我们考99是因为只能考99。而,SVM就是那个学霸。那个说服自己的推导过程,我会放在附件里面。

















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









