







1. DBSCAN简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的空间聚类应用算法。它的主要思想是将一个大的数据集划分为高密度和低密度的区域,然后在高密度区域中查找具有相似属性的数据点,形成聚类。
DBSCAN算法的核心思想是将数据集中的项目分为三类:核心点、边界点和噪声点。核心点是在指定半径内有足够多的邻居的点,边界点是在指定半径内邻居数量少于MinPts但是属于某个核心点的半径内的点,噪声点既不是核心点也不是边界点。
DBSCAN的优点包括:
- 能够发现任何形状的聚类。
- 不需要预先指定聚类的数量。
- 对初始化不敏感,总是产生相同的结果。
- 可以发现噪声点。
DBSCAN的缺点包括:
- 对于不同密度的数据集,可能难以选择合适的参数。
- 对高维数据效果不佳。
- 当数据集的密度不均匀时,聚类结果可能不准确。
2. 算法详解
这个算法本质上类似于传销,就是类似于拉人头发展下线。它所依据的就是,空间位置上相近的样本点大概率是同一类的。算法流程画图解释如下:
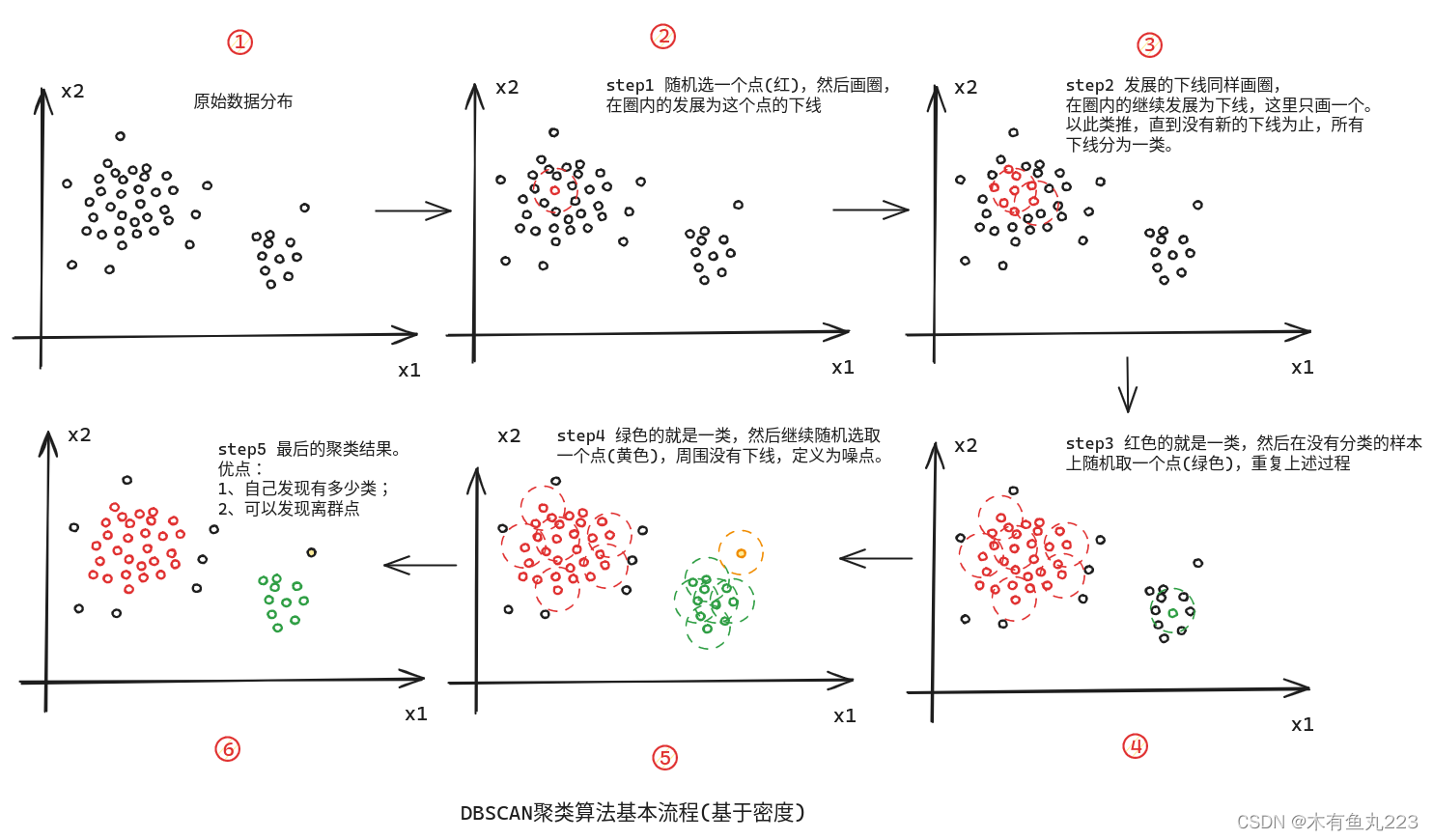
这个算法输入有两个参数:MinPts和epsilon。
参数MinPts表示,要发展下线时该点圈内下线的最小个数,即设定一个最小的任务指标。没有完成“拉人”任务的点,就不要再发展下去了,可以理解为点的密度不够了。
参数epsilon很好理解,圈的大小。注意,聚类算法点需要归一化。DBSCAN算法比较简单,解释起来没有太多的数学推导,但是它在低维度数据集上效果还是不错的。很厉害的一点是,不需要提前指定簇的类别数,它能自己分别出来。
3. 代码分享
本次代码实现结果如下所示:
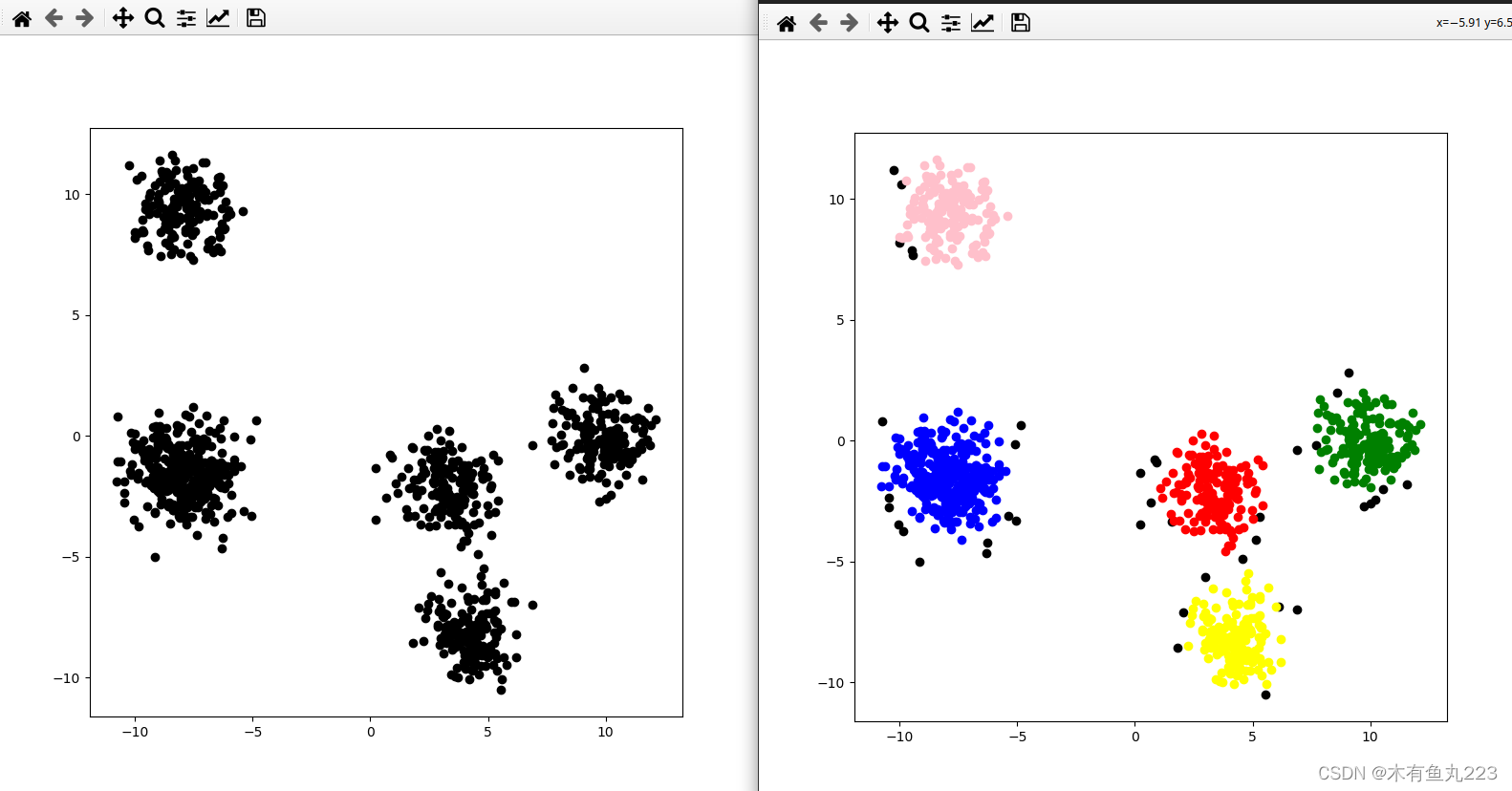
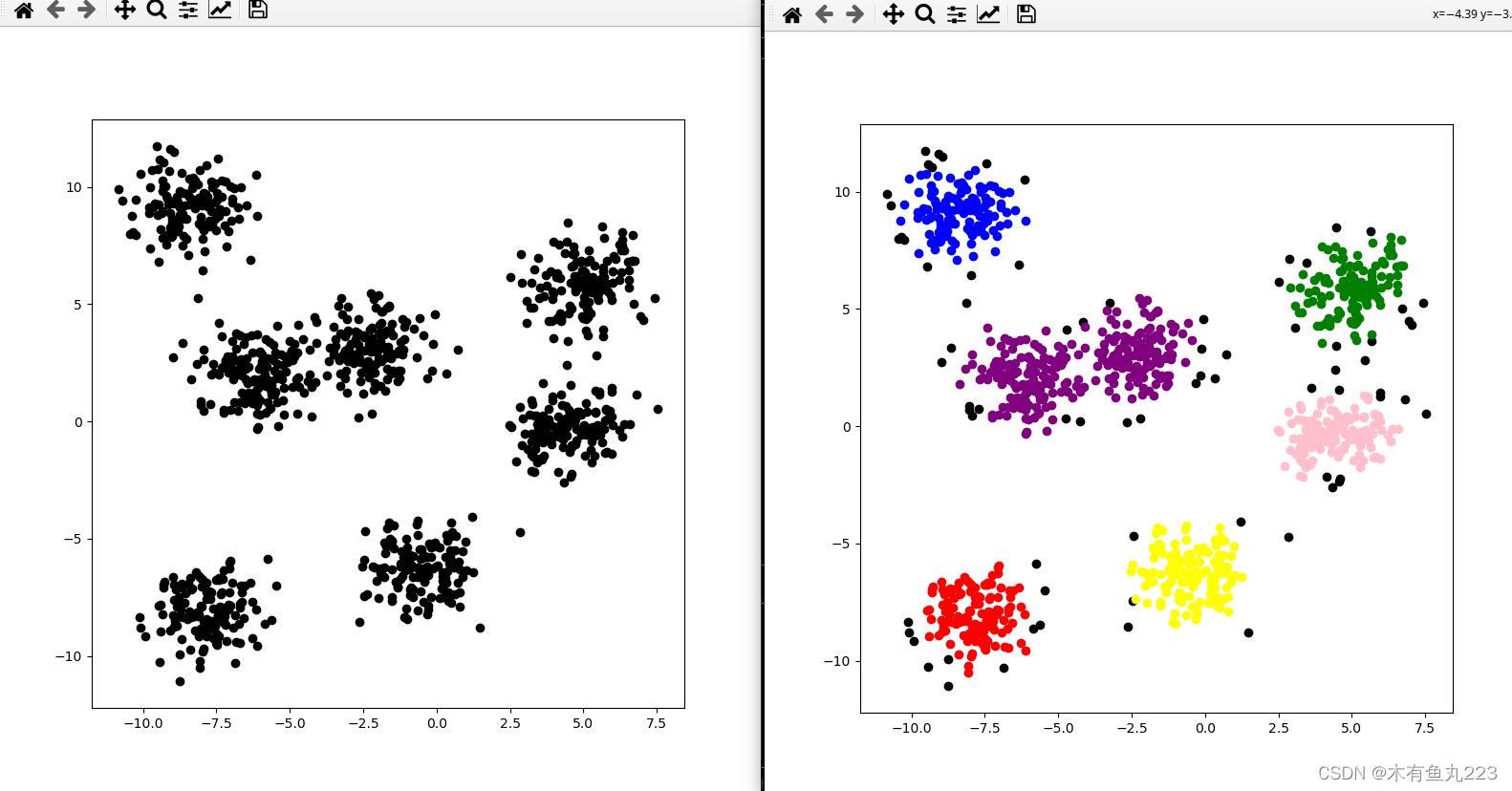
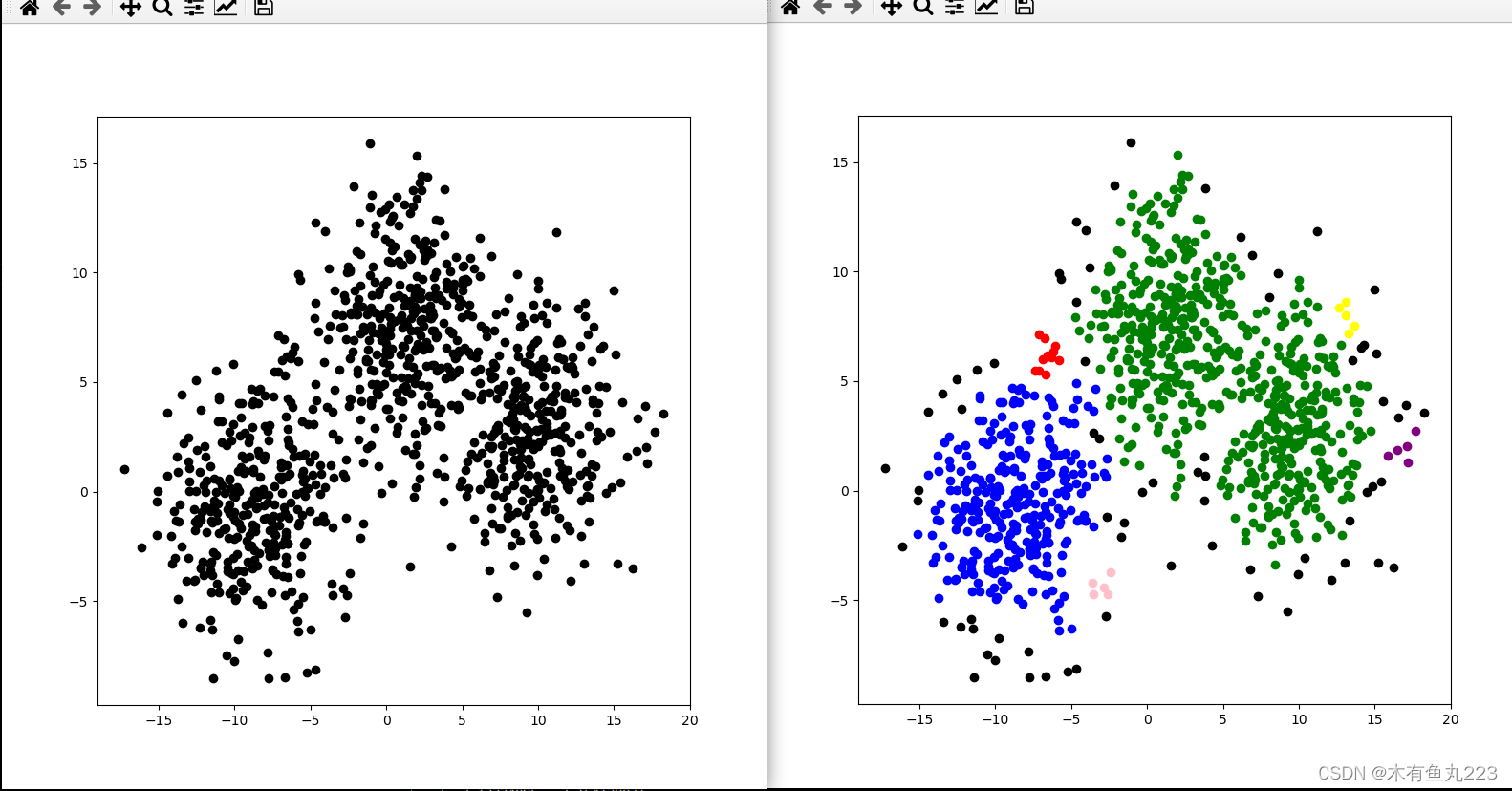
从上面第三个很容易看出来,如果原来数据本身如果恰巧有一个密集的连接通道,DBSCAN是分不出来的,会将他们分为一类。这就是所谓的密度不均匀的问题。OK,这个算法还有很多变种,用的时候再去了解吧。
from lib import dataGenerator,DBSCAN # 这两个包,是我用C++写的
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__':
data = dataGenerator.clusteringData(1000, 3, 2, -10, 10, 3)
data_np = np.array(data)
print(data_np.shape)
print(data_np[0:5,:])
plt.figure(figsize=(8,8))
plt.scatter(x = data_np[:,0], y = data_np[:,1], color = 'black')
label = DBSCAN.calDBSCAN(data, 4, 1)
label_np = np.unique(np.array(label))
print(label_np)
plt.figure(figsize=(8,8))
color = ['black','blue','red','pink','green','yellow','purple']
for ii,color in zip(label_np, color):
print(ii)
indices1 = [i for i, x in enumerate(label) if x == ii]
plt.scatter(data_np[indices1,0], data_np[indices1,1], color = color)
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









