




手写系列是本人学习的相关记录,主打一个自己实现核心代码和手写推导过程,不会调用任何现成包。会分享出来所有代码。水平有限,欢迎大家批评指导。
1、激励问题描述
首先明确,线性回归算法(Linear Regression)是利用回归方程对一个或多个自变量与因变量之间的关系进行建模的一种算法。
已知:我们有一堆数据
X
=
{
(
x
i
,
y
i
)
∣
i
=
1
,
2
,
.
.
.
,
m
}
,
x
,
y
∈
R
X = \{(x_i,y_i)|i = 1,2,...,m\},x,y\in R
X={(xi,yi)∣i=1,2,...,m},x,y∈R,其中
x
x
x为自变量,
y
y
y为因变量。现在要求我们依据这一堆数据来建立一个线性的模型
y
=
θ
x
+
b
y=\theta x+b
y=θx+b,能够很好的描述以及预测这一堆数据。我们画个图来解释一下:横坐标是x,纵坐标是y。我们应该如何建立回归模型,即得到参数a和b的值?
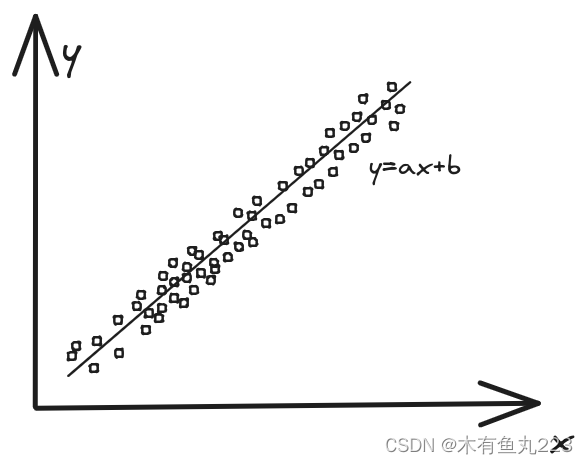
一个很自然的思路是中学时候学的最小二乘法,即:去找一条线,所有样本点到这条线的距离之和最小。数学化描述如下:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
.
.
.
+
θ
n
x
n
J
(
θ
)
=
1
2
∑
i
=
1
m
[
h
θ
(
x
(
i
)
)
−
y
(
i
)
]
2
θ
:
=
a
r
g
m
i
n
J
(
θ
)
h_{\theta}(x)=\theta_0 + \theta_1x_1+...+\theta_nx_n\\ J(\theta)=\frac{1}{2}\sum_{i=1}^m[h_\theta(x^{(i)})-y^{(i)}]^2\\ \theta := argminJ(\theta)
hθ(x)=θ0+θ1x1+...+θnxnJ(θ)=21i=1∑m[hθ(x(i))−y(i)]2θ:=argminJ(θ)
有上述理解之后,接下来就是标准的求最小值的流程:求导–>导函数等于0–>得到
θ
\theta
θ的估计结果。前人已经在数学上面证明,这个
J
(
θ
)
J(\theta)
J(θ)是个凸函数,存在唯一的最小值点。详细的推导我会在第2部分进行。
到这里,线性回归已经结束了。但是,前人从概率角度提出了另一种理解方式,即,他认为上述数据的形成是一个线性方程叠加一个独立同分布的高斯噪声形成的。这种数据执行最大似然估计的结果和上述最小二乘法的结果一致。数学化描述如下:
a
s
s
u
m
e
:
y
(
i
)
=
θ
T
x
(
i
)
+
ϵ
(
i
)
w
h
e
r
e
ϵ
→
N
(
0
,
σ
2
)
assume : y^{(i)}=\theta^Tx^{(i)}+\epsilon^{(i)}\ \ \ \ where\ \ \epsilon\to N(0,\sigma^2)
assume:y(i)=θTx(i)+ϵ(i) where ϵ→N(0,σ2)
2、原理推导


3、实验结果
实验一:
y
=
−
2.85
x
+
10
y=-2.85x + 10
y=−2.85x+10,复合的高斯噪声均值为0,标准差为1。实验结果如下所示。

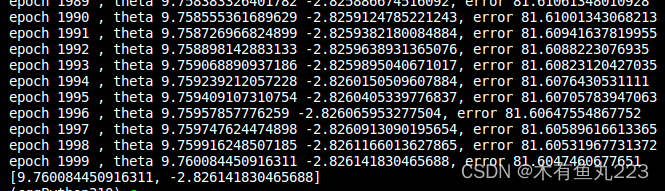
使用批量梯度下降,最后迭代的结果:
4、代码分享
本文主要使用了批量梯度下降算法,批量梯度下降算法的参数更新在手写推导过程中也进行了推导。可以看到,本文使用“线性方程+高斯噪声”生成的数据,在迭代若干次之后,其都能输出一个比较好的回归结果。当然经过第2部分手推,可以知道 θ \theta θ的具体解析解的。但是需要求解一个非常大的方阵的逆。所以我们仍然采用梯度下降算法来更新参数 θ \theta θ。本文没有考虑到迭代停止条件,单纯的迭代2000次停止。并且对于学习率 α \alpha α的选择也是有说法。数据本身还缺少归一化的步骤。下面贴出核心的批量梯度下降的代码。完整代码我会上传到绑定资源当中。
import numpy as np
import matplotlib.pyplot as plt
import imageio
class gradientDescent:
def __init__(self, x, y, alpha, theta):
self.x = x
self.y = y
self.theta = theta
self.thetaNum = len(theta)
self.alpha = alpha
self.epoch = 1000
def run(self, show = False):
theta = self.theta
for index in range(self.epoch):
for i in range(self.thetaNum):
allValue = 0
for xx,yy in zip(self.x, self.y):
value = theta[0] + theta[1] * xx
if i == 0:
x = 1
elif i == 1:
x = xx
allValue = allValue + (value - yy) * x
theta[i] = theta[i] - self.alpha * allValue
error = self.getError(theta)
print("epoch {} , theta {} {}, error {}".format(index, theta[0], theta[1], error))
self.theta = theta
def getError(self, theta):
value = theta[0] + self.x * theta[1]
return np.sum((value - self.y)**2)
def getResult(self):
return self.theta
5、后续
自己写的代码,肯定在实现细节以及很多地方考虑不周,只能是验证手推的正确性。当然了,在几十年前前人就证明这是正确的。但是,为什么我觉得本系列还是有价值的呢,一方面是强迫我自己去一点点实现,您一点点看,体会这其中的细节,另外就是在实现中会发现一系列的问题。
比如说,我在上一篇博客<手写逻辑回归算法>中,设置学习率为0.01还比较小,但是今天生成的数据,学习率要设置为0.0001,才能正常工作。我考虑是因为数据本身量级的问题,即,缺少归一化的过程。再比如说,我现在就比较好奇,如果迭代的噪声不是正态分布的,上述这种梯度下降的方法是否还是有效的呢,是否还存在解析解呢?
我看过吴恩达老师的CS229课程,据我所知,这一切都归类于广义线性模型(GLMS)当中,即是存在一个理论可以很好的回答这个问题的。这也是本系列后续一个比较重要的部分,敬请期待。
综上所述,对于线性回归(LR)算法,我们需要有两个记忆点:
1)线性回归算法是使用一个线性方程去拟合数据,所依据的就是我们中学学习的最小二乘法,即,所有样本点和预测直线之间差的平方和最小。
2)线性回归算法在概率上是使用“线性方程+高斯噪声”这么一种模型在进行拟合。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









