环境:ubuntu 16.04;Nvidia GTX1080Ti;pytorch 0.4.1
网络结构:
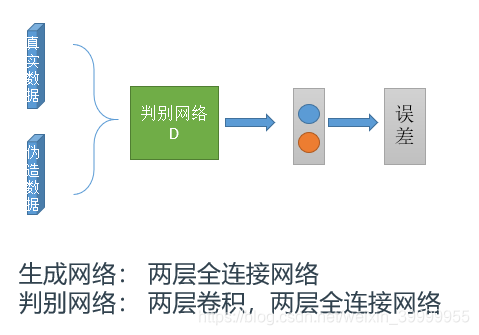
代码如下:
# -*-coding: utf-8 -*-
import torch
from torchvision import datasets, transforms
import torch.utils.data as data
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
BATCH_SIZE = 64 # 一批数据大小
IMAGE_SIZE = 28 # 图片尺寸
N_GNET = 50 # 噪声分布大小
NUM_EPOCH = 200 # 数据集迭代批次
USE_CUDA = False
# 辨别器
class disciminator(nn.Module):
def __init__(self):
super(disciminator, self).__init__()
self.conv_1 = nn.Conv2d(1, 32, kernel_size=5, stride=2, padding=2)
self.conv_2 = nn.Conv2d(32, 64, kernel_size=5, stride=2, padding=2)
self.lrelu = nn.LeakyReLU(0.2)
self.fc1 = nn.Linear(7 * 7 * 64, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
x = self.lrelu(self.conv_1(x))
x = self.lrelu(self.conv_2(x))
x = x.view(-1, 7 * 7 * 64)
x = self.lrelu(self.fc1(x))
return F.sigmoid(self.fc2(x))
# 生成器
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.fc1 = nn.Linear(N_GNET, 14 * 14)
self.fc2 = nn.Linear(14 * 14, 28 * 28)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.sigmoid(self.fc2(x))
return x.view(-1, 1, 28, 28)
# 把batch_size个生成图片 拼接成size[0] x size[1]大小的整张图片,便于保存和可视化结果
def merge(images, size):
h, w = images.shape[1], images.shape[2]
img = np.zeros((h * size[0], w * size[1], 3))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
def main():
# 加载数据
mnist_data = data.DataLoader(
datasets.MNIST('./mnist_data', train=True, download=True, transform=transforms.Compose(
[transforms.ToTensor()])), batch_size=BATCH_SIZE, num_workers=1,drop_last=True)
device = torch.device("cuda" if USE_CUDA else "cpu")
net_d = disciminator()
net_g = generator()
net_d.to(device)
net_g.to(device)
optimizer_d = torch.optim.Adam(net_d.parameters(), lr=0.0001)
optimizer_g = torch.optim.Adam(net_g.parameters(), lr=0.0002)
criterion=nn.BCELoss().to(device)
true_lable=Variable(torch.ones(BATCH_SIZE)).to(device)
fake_lable=Variable(torch.zeros(BATCH_SIZE)).to(device)
for current_epoch in range(NUM_EPOCH):
print(mnist_data)
for ii, (img, _) in enumerate(mnist_data):
# 训练辨别器
optimizer_d.zero_grad()
# if img.shape[0].item()<64:
# break;
real_image = img.to(device)
noises = np.random.randn(BATCH_SIZE, N_GNET)
# 辨别器辨别真图的loss
d_real = net_d(real_image)
loss_d_real=criterion(d_real,true_lable)
loss_d_real.backward()
# 辨别器辨别真图的loss
fake_in = torch.Tensor(noises).to(device)
fake_image = net_g(fake_in).detach()
d_fake = net_d(fake_image)
loss_d_fake=criterion(d_fake,fake_lable)
loss_d_fake.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
#noises = np.random.randn(BATCH_SIZE, N_GNET)
fake_in = torch.Tensor(noises).to(device)
fake_image = net_g(fake_in)
d_fake = net_d(fake_image)
# 生成器生成假图的loss
g_loss = criterion(d_fake,true_lable)
g_loss.backward()
optimizer_g.step()
# 每200步画出生成的数字图片和相关的数据
if ii % 200 == 0:
plt.clf()
print("Epoch:%d step:%d d_loss:%.2f, g_loss:%.2f" % (current_epoch, ii, loss_d_fake+loss_d_real, g_loss))
plt.imshow(merge(fake_image.to('cpu').detach().numpy().transpose((0,2,3,1)), [8, 8]))
#plt.imshow(merge(real_image.detach().to('cpu').numpy().transpose((0, 2, 3, 1)), [8, 8]))
plt.text(-10.0, -5.0, 'Epoch:%.2d step:%.4d D accuracy=%.2f (0.5 for D to converge)' %
(current_epoch, ii, (d_real.mean() + 1 - d_fake.mean()) / 2), fontdict={'size': 10})
plt.draw()
plt.pause(0.1)
plt.ioff()
plt.show()
if __name__ == '__main__':
main()
生成的数字效果图如下:


ps:代码可能存在问题(隐隐的觉得) ,但还是生成了数字!








 本文介绍了一个使用PyTorch实现的生成对抗网络(GAN),该网络能够在MNIST数据集上生成手写数字。网络包括一个生成器和一个判别器,分别用于生成数字图像和判断图像的真实性。
本文介绍了一个使用PyTorch实现的生成对抗网络(GAN),该网络能够在MNIST数据集上生成手写数字。网络包括一个生成器和一个判别器,分别用于生成数字图像和判断图像的真实性。

















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









