




GANs完全入门:从“伪造大师”与“火眼金睛”的对决,到创造万物的AI魔法(附代码与图解)
正文:
嘿,各位热爱学习的小伙伴们!
你是否曾惊叹于那些由AI生成的、栩栩如生的人脸,或者被那些风格独特的AI画作所吸引?这些看似“黑科技”的应用背后,大多站着一个共同的身影——GAN(生成对抗网络)。
今天,我们就将理论与实践相结合,不仅让你彻底理解GAN,还能让你亲手用代码实现一个!别担心,我们依旧从那个有趣的故事开始。
一、核心思想:一场“伪造大师”与“火眼金睛”的终极对决
想象一下,我们有两个角色:
- 伪造大师 (Generator - 生成器 G):一个初出茅庐的画作伪造者。他一开始只会胡乱涂鸦,目标是画出能骗过鉴定师的“世界名画”。
- 火眼金睛 (Discriminator - 判别器 D):一位经验丰富的艺术品鉴定师。他能看到真迹,也看得到赝品,目标是精准地分辨出真伪。
这场对决的核心就是 “对抗” 和 “共同进化”。
- 生成器G 努力生成越来越逼真的数据来 欺骗 判别器D。
- 判别器D 努力提升自己的鉴别能力来 识破 生成器G的伎俩。
最终,当G的“伪造”技艺登峰造极,D再也无法分辨其作品的真伪(只能靠50%的概率瞎猜)时,我们就得到了一个强大的生成器!
二、GAN的宏观架构(图解)
用一张图来描绘这场对决,就是GAN的基本架构:
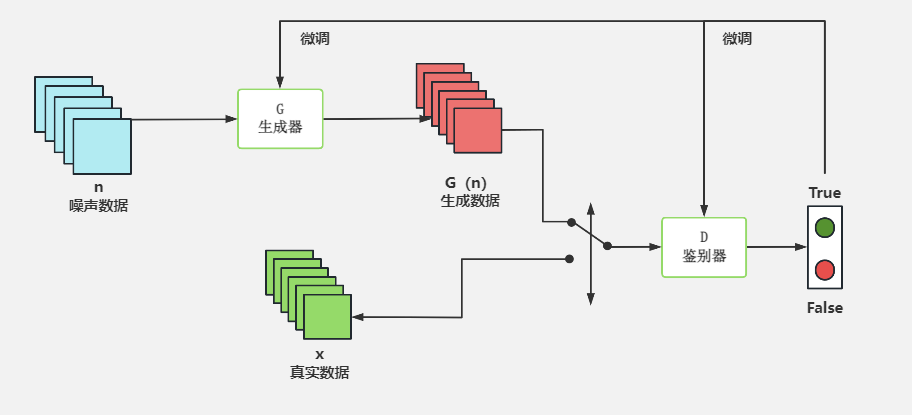
[图1:GAN基本架构图]]
图解说明:
- 随机噪声 (Input Noise):这是生成器的“灵感”来源,一个随机的数字向量。
- 生成器 (Generator):接收随机噪声,将其“升维”和“重塑”,生成一张假的图片(Fake Image)。
- 判别器 (Discriminator):它的输入有两个来源:一个是真实的图片(Real Image),另一个是生成器伪造的图片。
- 判别结果 (Real/Fake):判别器对接收到的图片进行判断,输出一个概率值,代表“该图片为真的可能性有多大”。
三、两大组件的代码实现 (PyTorch版)
现在,让我们看看“伪造大师”和“鉴定师”在代码里长什么样。我们将使用PyTorch框架,并以生成手写数字(MNIST数据集)为例。
1. 伪造大师 (Generator)
它的任务是从一个简单的随机向量(比如100维)生成一张 28x28 的黑白图片。这是一个“升维”的过程。
import torch
import torch.nn as nn
# 定义超参数
LATENT_DIM = 100 # 随机噪声向量的维度
IMG_SHAPE = (1, 28, 28) # 目标图片形状 (1个颜色通道, 28x28像素)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
# 从100维的噪声开始,逐步放大
nn.Linear(LATENT_DIM, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
# 最终输出一个和图片像素总数一样大的向量
nn.Linear(1024, int(np.prod(IMG_SHAPE))),
# 使用Tanh激活函数将输出值归一化到[-1, 1]范围
nn.Tanh()
)
def forward(self, z):
# 输入一个随机噪声z
img = self.model(z)
# 将输出的向量重塑为图片形状
img = img.view(img.size(0), *IMG_SHAPE)
return img
代码解读:
LATENT_DIM:就是输入给G的“灵感”向量的长度。nn.Linear: 全连接层,用于将向量维度变换。nn.LeakyReLU: 一种激活函数,在GAN中表现通常比ReLU好。nn.BatchNorm1d: 批归一化,能帮助稳定训练。nn.Tanh: 将输出值压缩到-1到1之间,这通常与训练数据的归一化方式相匹配。
2. 火眼金睛 (Discriminator)
它的任务是接收一张 28x28 的图片,判断其真伪。这是一个“降维”和“分类”的过程。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
# 输入一张图片,将其展平为向量
nn.Flatten(),
nn.Linear(int(np.prod(IMG_SHAPE)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
# 输出一个单一的数值,代表“真”的概率
nn.Linear(256, 1),
# 使用Sigmoid函数将输出压缩到0到1之间
nn.Sigmoid()
)
def forward(self, img):
validity = self.model(img)
return validity
代码解读:
nn.Flatten: 将输入的28x28图像“压平”成一个784维的向量。nn.Sigmoid: 最终将输出值变成一个0到1的概率。越接近1,表示模型认为图片越“真”;越接近0,越“假”。
四、训练流程:精妙的交替训练(图解)
GAN的训练过程不是一次性完成的,而是G和D的交替优化。
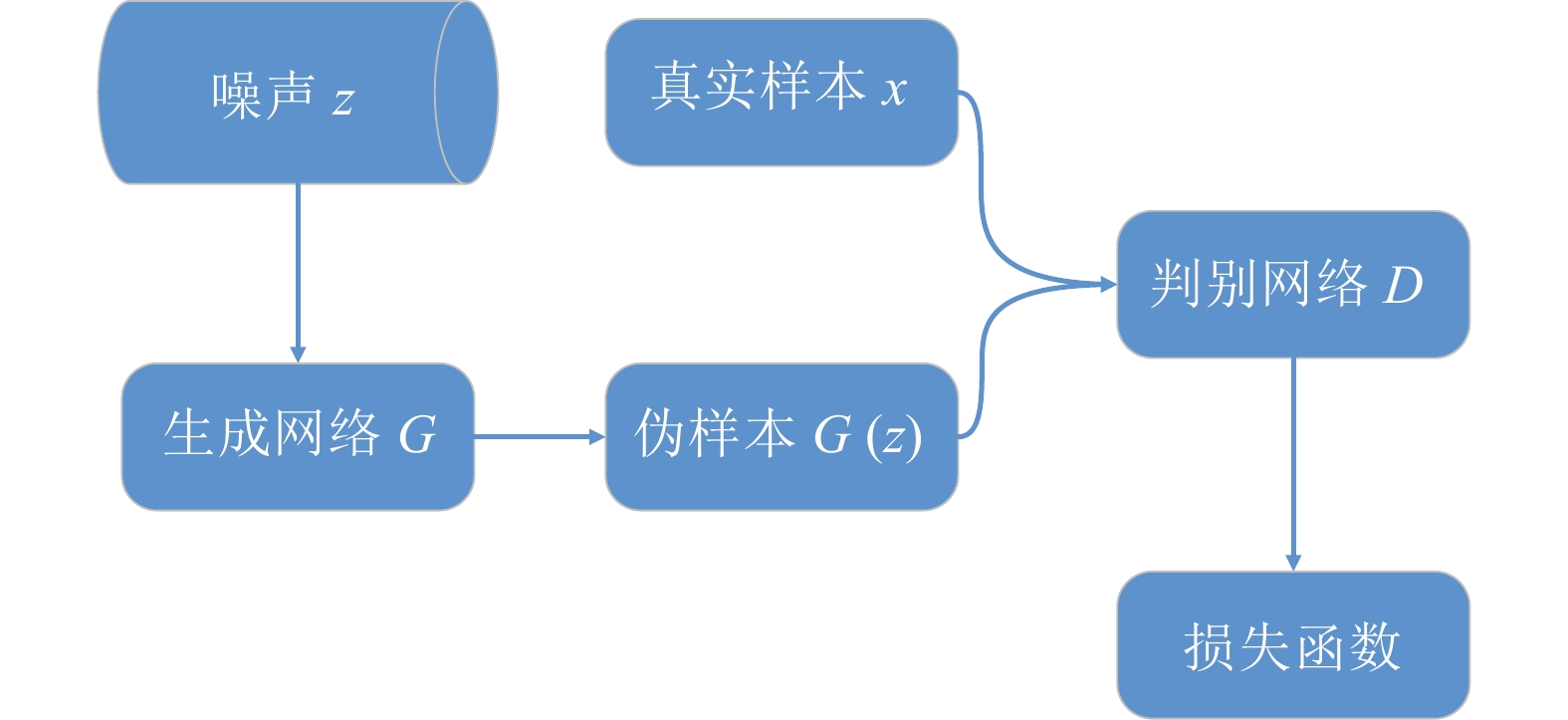
[图2:GAN训练流程图]
图解说明:
第1步:训练判别器D (固定G)
- 路径① (上半部分):从真实数据集中取一批图片,喂给D。D的目标是输出1(真)。我们计算其与1的差距(损失),并更新D的参数,让它下次对真图片打分更高。
- 路径② (下半部分):让G生成一批假图片,喂给D。D的目标是输出0(假)。我们计算其与0的差距(损失),并再次更新D的参数,让它下次对假图片打分更低。
- 关键:在这一步,生成器G是“冻结”的,它的参数不更新。
第2步:训练生成器G (固定D)
- 路径③ (整个下半部分):让G再次生成一批假图片,喂给D。
- 关键:此时G的目标是 欺骗D。也就是说,G希望D对这些假图片输出1(真)!所以,我们计算D的输出与1的差距(损失),但这次,我们只更新 G的参数。D的参数是“冻结”的。这相当于告诉G:“D认为你这张图是假的,你得朝着能让D认为是真的方向去修改你的生成策略。”
五、完整的训练代码示例
下面是一个可以在你的电脑上运行的完整代码,它将训练一个GAN来生成MNIST手写数字。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import numpy as np
import os
# --- 1. 定义超参数和设备 ---
EPOCHS = 200
BATCH_SIZE = 64
LR = 0.0002
LATENT_DIM = 100
IMG_SHAPE = (1, 28, 28)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建一个目录来保存生成的图片
os.makedirs("images", exist_ok=True)
# --- 2. 加载和预处理数据 (MNIST) ---
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 将图片像素值归一化到[-1, 1]
])
dataset = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# --- 3. 定义模型、损失函数和优化器 ---
# (此处省略上面已经展示过的Generator和Discriminator类的代码)
generator = Generator().to(DEVICE)
discriminator = Discriminator().to(DEVICE)
# 损失函数:二元交叉熵损失
adversarial_loss = nn.BCELoss().to(DEVICE)
# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=LR, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=LR, betas=(0.5, 0.999))
# --- 4. 训练循环 ---
for epoch in range(EPOCHS):
for i, (imgs, _) in enumerate(dataloader):
# 定义真实标签和伪造标签
real_labels = torch.ones(imgs.size(0), 1).to(DEVICE)
fake_labels = torch.zeros(imgs.size(0), 1).to(DEVICE)
# 将真实图片移动到DEVICE
real_imgs = imgs.to(DEVICE)
# --- 训练生成器 G ---
optimizer_G.zero_grad()
# 生成一批随机噪声
z = torch.randn(imgs.size(0), LATENT_DIM).to(DEVICE)
# 生成假图片
gen_imgs = generator(z)
# 计算生成器的损失 (目标是让判别器认为假图片是'真'的)
g_loss = adversarial_loss(discriminator(gen_imgs), real_labels)
g_loss.backward()
optimizer_G.step()
# --- 训练判别器 D ---
optimizer_D.zero_grad()
# 计算判别器对真实图片的损失
real_loss = adversarial_loss(discriminator(real_imgs), real_labels)
# 计算判别器对伪造图片的损失 (gen_imgs.detach()防止梯度传回G)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake_labels)
# 总的判别器损失
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# --- 打印进度并保存图片 ---
print(
f"[Epoch {epoch}/{EPOCHS}] [D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]"
)
if epoch % 10 == 0:
save_image(gen_imgs.data[:25], f"images/{epoch}.png", nrow=5, normalize=True)
当你运行这段代码,你会看到images文件夹里生成的图片从一开始的随机噪声,逐渐变得越来越像手写数字!
六、GAN的魔力与挑战
魔力(应用):
训练完成后,我们的generator模型就成了一位“数字绘画大师”。给它任何随机噪声,它都能创造一个全新的、独一无二的手写数字!它的应用远不止于此:
- 图像生成:StyleGAN生成的逼真人脸。
- 图像到图像转换:CycleGAN实现的风格迁移(照片变油画)。
- 超分辨率:SRGAN让模糊图像变清晰。
- 文本到图像:DALL-E 2, Midjourney等根据文字描述生成惊艳图片。
挑战(荆棘):
GAN的训练是出了名的困难,像驾驭烈马:
- 训练不稳定:G和D的对抗很容易失衡,导致一方完全压制另一方,训练失败。
- 模式崩溃 (Mode Collapse):G为了“走捷径”,可能只生成几种特别逼真的样本,而丧失了多样性。比如,我们的MNIST GAN可能只会生成数字“1”和“7”。
- 评估困难:如何客观评价生成图片的质量?这本身就是一个难题。
总结
恭喜你!你已经走完了从理解决策到亲手实践的全过程。
- 核心思想:GAN是一场“生成器”与“判别器”的对抗游戏,在竞争中共同进化。
- 工作原理:G从噪声创造数据,D分辨真假。通过图解和代码,我们看到了它们的具体形态。
- 训练过程:通过代码,我们实践了精妙的“交替训练”步骤。
- 巨大潜力:从艺术创作到数据增强,GAN正在改变我们与AI交互的方式。
希望这篇图文并茂、代码详实的教程能真正帮助你掌握GAN。现在,你不仅是理解了AI魔法的观众,更是拥有了施展魔法能力的“魔法师”!
有任何问题,欢迎在评论区与我交流!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











