







递归神经网络在很长一段时间内是序列转换任务的主导模型,其固有的序列本质阻碍了并行计算。因此,在2017年,谷歌的研究人员提出了一种新的用于序列转换任务的模型架构Transformer,它完全基于注意力机制建立输入与输出之间的全局依赖关系。在训练阶段,Transformer可以并行计算,大大减小了模型训练难度,提高了模型训练效率。Transformer由编码器和解码器两部分构成。其编解码器的子模块为多头注意力MHA和前馈神经网络FFN。此外,Transformer还利用了位置编码、层归一化、残差连接、dropout等技巧来增强模型性能。
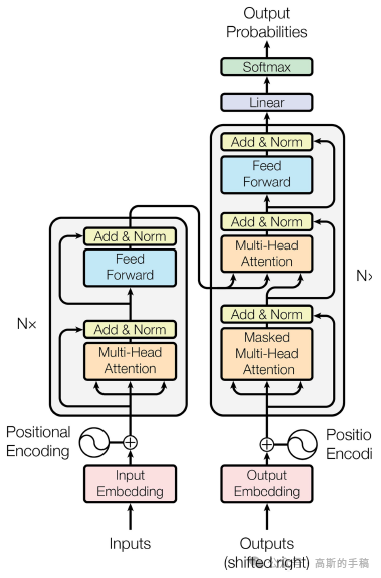
鉴于此,简单地采用Transformer对滚动轴承进行故障诊断,没有经过什么修改,效果不是很好,准确率较低,数据集采用江南大学轴承数据集。
import numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport scipy.io as ioimport pandas as pdimport matplotlib.pyplot as pltfrom torch.utils.data import Dataset, DataLoaderd_k = 64d_v = 64class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V):scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)weights = nn.Softmax(dim=-1)(scores)context = torch.matmul(weights, V)return context, weights# Q = torch.randint(0, 9, (4, 8, 512)).to(torch.float32)# K = torch.randint(0, 4, (4, 8, 512)).to(torch.float32)# V = torch.randint(0, 2, (4, 8, 512)).to(torch.float32)# SDPA = ScaledDotProductAttention()# context, weights = SDPA(Q, K, V)# print(weights.shape)# print(V.shape)# print(context.shape)d_embedding = 512n_heads = 2batch_size = 32seq_len = 4class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k*n_heads)self.W_K = nn.Linear(d_embedding, d_k*n_heads)self.W_V = nn.Linear(d_embedding, d_v*n_heads)self.Linear = nn.Linear(n_heads*d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V):residual, batch_size = Q, Q.size(0)# input[batch_size, len, d_embedding]->output[batch_size, len, d_k*n_heads]-># {view}->output[batch_size, len, n_heads, d_k]->{transpose}->output[batch_size, n_heads, len, d_k]q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)k_s = self.W_K(K).view(batch_siz
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











