










 文章详细介绍了离线数据仓库DWD层在交易域中的事实表设计,包括加购、下单、取消订单、购物车周期快照、支付成功和退单等事务事实表的前期梳理、DDL表设计和数据加载分析,涉及Hive的表创建、分区策略以及数据同步和处理流程。
文章详细介绍了离线数据仓库DWD层在交易域中的事实表设计,包括加购、下单、取消订单、购物车周期快照、支付成功和退单等事务事实表的前期梳理、DDL表设计和数据加载分析,涉及Hive的表创建、分区策略以及数据同步和处理流程。
离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表
离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表
一、DWD层设计要点
- DWD层设计要点:
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
- 事实表维度建模理论参考之前整理资料:https://blog.youkuaiyun.com/weixin_38136584/article/details/129137583?spm=1001.2014.3001.5501
- 2)DWD层的数据存储格式为orc列式存储+snappy压缩。
- 3)DWD层表名的命名规范为dwd_数据域_表名(体现业务过程)_单分区增量全量标识(inc/full)
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
二、交易域相关事实表
事实事务表设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.交易域加购事务事实表
1.加购事务事实表 前期梳理
- 加购事务事实表 设计流程跟事务事实表流程一致,分为四步进行。
- 查看之前梳理的业务矩阵,基于业务矩阵来进行设计流程4步骤分析

- 1.选择业务过程:加购物车
- 2.声明粒度(业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。):xx人在xx时间将xx商品加入到购物车
- 3.确认维度:寻找符合业务逻辑的并与此业务过程关联的维度,如果前期选择少了几个维度,后期可以更新表格再添加即可。
- 4.确认事实(每个业务过程的度量值):商品件数
2.加购事务事实表 DDL表设计分析
- 业务数据库对应的表格加购物车cart_info中,存在source_id字段,此字段对应的是加购物车这个操作对应的数据来源,所以需要加来源相关的信息添加到维度表中,此处做了维度弱化,直接将数据整合到加购事务事实表中了。
DROP TABLE IF EXISTS dwd_trade_cart_add_inc;
CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`date_id` STRING COMMENT '时间id',
`create_time` STRING COMMENT '加购时间',
`source_id` STRING COMMENT '来源类型ID',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域加购物车事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.加购事务事实表 加载数据分析
- 1.加购事务事实表,来自于业务数据库中哪些表格,对应同步到ods层,事务事实表使用的是inc结尾的增量数据,full结尾的全量数据,对应到周期快照事实表使用。
cart_info - 2.加购物车这一业务过程是怎样实现的,有哪些限制条件。
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据+1
- 3.数据最终落地那个分区下面,需要明确
- 首日全量加购记录 首日默认全部加购物车,按照创建时间写入到对应时间分区里面
- 每日增量加购记录 ,过滤满足条件的数据,直接写入对应的当日时间分区。
- 4.加购事务事实表的数据流向,如下图:
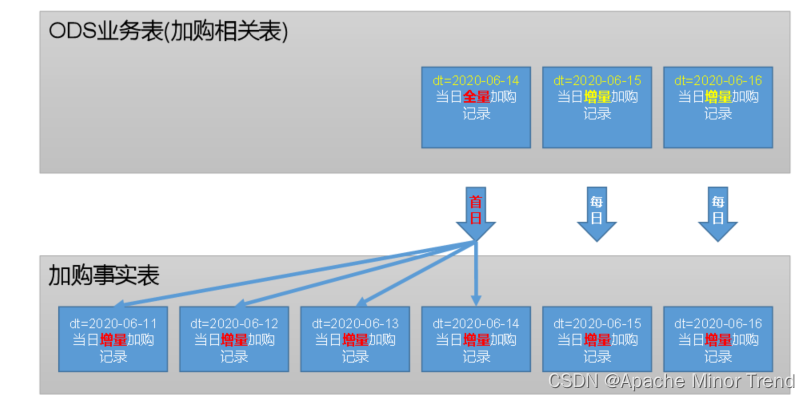
1.首日全量加购的数据加载
- 针对业务系统中,历史的数据进行处理,就是首日装载的意义。
- sql的思路:
- 1.相关表格已同步到ods层,为增量inc表格,购物车信息表和加购操作数据来源类型表
- 2.两张表格进行关联,获取到加购事务事实表所有字段,
- 3.处理数据,使用hive动态分区,将不同数据写入到不同分区
- hive中sql注意:date_format(create_time,‘yyyy-MM-dd’),跟mysql中语法不一致。
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
select
id,
user_id,
sku_id,
date_format(create_time,'yyyy-MM-dd') date_id,
create_time,
source_id,
source_type,
dic.dic_name,
sku_num,
date_format(create_time, 'yyyy-MM-dd')
from
(
select
data.id,
data.user_id,
data.sku_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num
from ods_cart_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
)ci
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on ci.source_type=dic.dic_code;
2.每日增量加购的数据加载
-
sql思路:
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据变大
- 使用maxwell同步过来的json外部的ts时间作为加入购物车时间,而不使用json内部的create_time作为加购时间,这样设计比较合理。
- 对加购数量进行判断,
- 如果是insert类型,直接使用sku_num的值即可,
- 如果是update操作,需要将maxwell过来的json数据中 新值-老值得到的结果存入.
-
hive中函数的使用:
- map_keys(map集合):将此map集合中所有的key取出,作为一个数组。
- array_contains(数组,元素) :该数组中是否包含此元素 ,返回布尔类型的值
- cast(数据 as int ):将该数据强制转化为int类型
-
hive中时间戳到时间字符串的转换 ,经常用到,官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
- 时间戳:自零时区以来,1970-01-01以来的经历的秒数(10位)或者毫秒数(13位)
- 以秒为单位的时间戳,转为时分秒
- from_unixtime(bigint unixtime[, string format]) 这个转换时间戳函数没有分区概念,所以之间转为了零时区的时间。
- from_utc_timestamp({any primitive type} ts(必选是毫秒数), string timezone) 使用:from_utc_timestamp(ts*1000, “GMT+8”)
- 使用时间格式化工具将上面处理完的数据转为想要的格式:date_format(from_utc_timestamp(ts*1000, “GMT+8”),“yyyy-MM-dd HH:mm:ss”)
-
2020-06-15的增量加购数据处理
insert overwrite table dwd_trade_cart_add_inc partition(dt='2020-06-15')
select
id,
user_id,
sku_id,
date_id,
create_time,
source_id,
source_type_code,
source_type_name,
sku_num
from
(
select
data.id,
data.user_id,
data.sku_id,
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd') date_id,
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd HH:mm:ss') create_time,
data.source_id,
data.source_type source_type_code,
if(type='insert',data.sku_num,data.sku_num-old['sku_num']) sku_num
from ods_cart_info_inc
where dt='2020-06-15'
and (type='insert'
or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int)))
)cart
left join
(
select
dic_code,
dic_name source_type_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on cart.source_type_code=dic.dic_code;
- linux查看进程对应在服务器的配置
1. 首先jps,查看进程号
2. cd /proc/84912(某进程对应的进程号)
3. limits 文件里面有对应的限制信息
4. exe 是对应的启动二进制进程
5. fd 文件描述符,对应该进程所打开的文件,聚合查看一下打开多少文件即可
2.交易域下单事务事实表
设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.下单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:
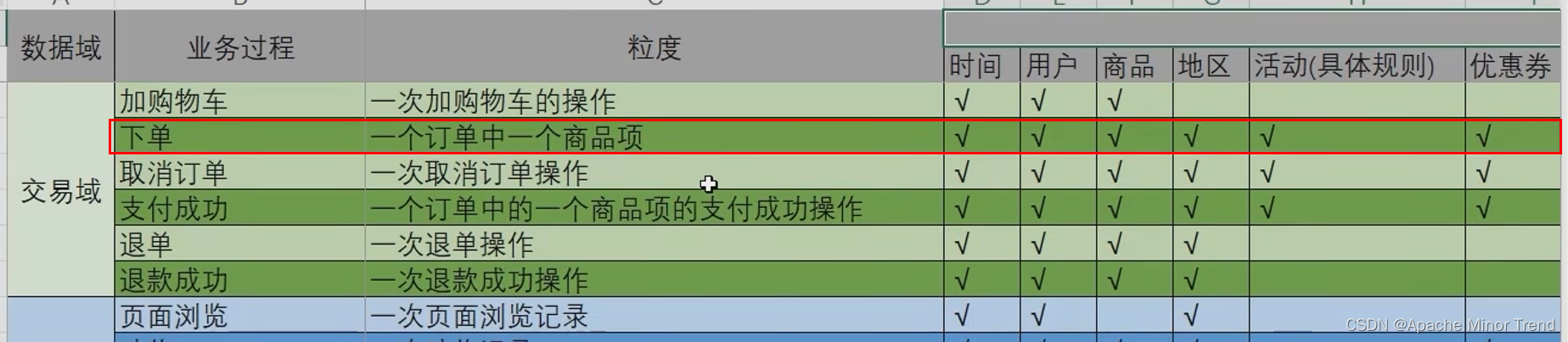
- 1.选择业务过程:下单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成下单操作,这对应的是下单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:下单件数、下单原始金额、下单最终金额、活动优惠金额、优惠券优惠金额
2.下单事务事实表 DDL表设计分析
- 之前创建的dim层维度表以外,其他的维度都退化到对应的事实表中,没有退化的,事实表直接在本表中体现某些维度表的id即可,退化的维度直接写入对应数据即可。
DROP TABLE IF EXISTS dwd_trade_order_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_order_detail_inc
(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`activity_id` STRING COMMENT '参与活动规则id',
`activity_rule_id` STRING COMMENT '参与活动规则id',
`coupon_id` STRING COMMENT '使用优惠券id',
`date_id` STRING COMMENT '下单日期id',
`create_time` STRING COMMENT '下单时间',
`source_id` STRING COMMENT '来源编号',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '商品数量',
`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',
`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',
`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',
`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域下单明细事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_order_detail_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.下单事务事实表 加载数据分析
- 下单会对哪些业务表格产生影响,如下图:
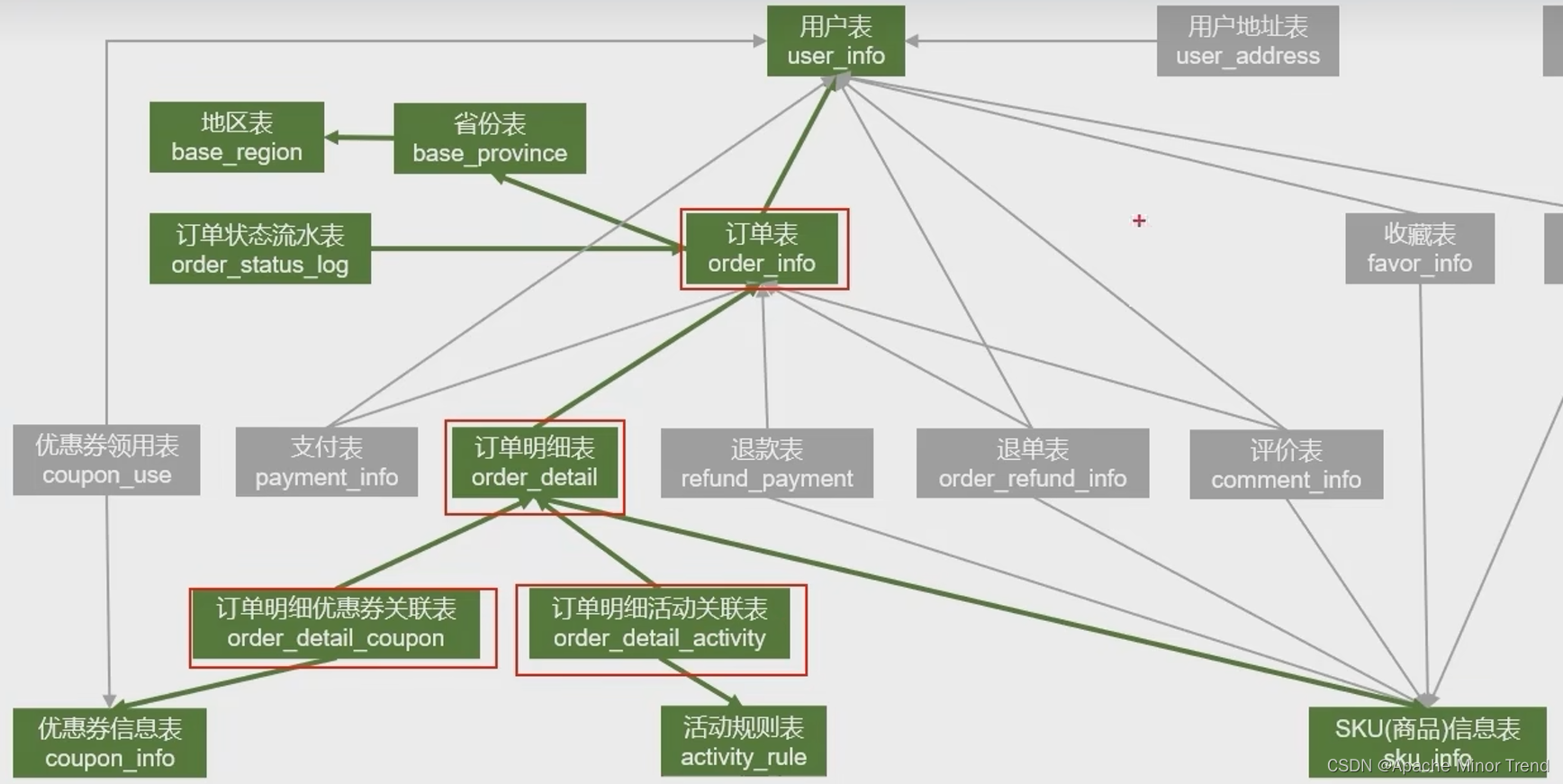
1.首日全量下单的数据加载
- 业务数据库中 下单明细表中每行数据就能代表一条下单记录,直接将数据同步到ods层然后同步到dwd层即可。
- 下单事务事实表 跟 下单明细表字段对比,观察哪些字段能获取到,哪些字段获取不到,获取不到的,直接对照数据库表格关联图,书写sql获取对应关系,如下图,没注释掉的就能获取到,注释掉的通过sql关联或者处理字段方式获取。
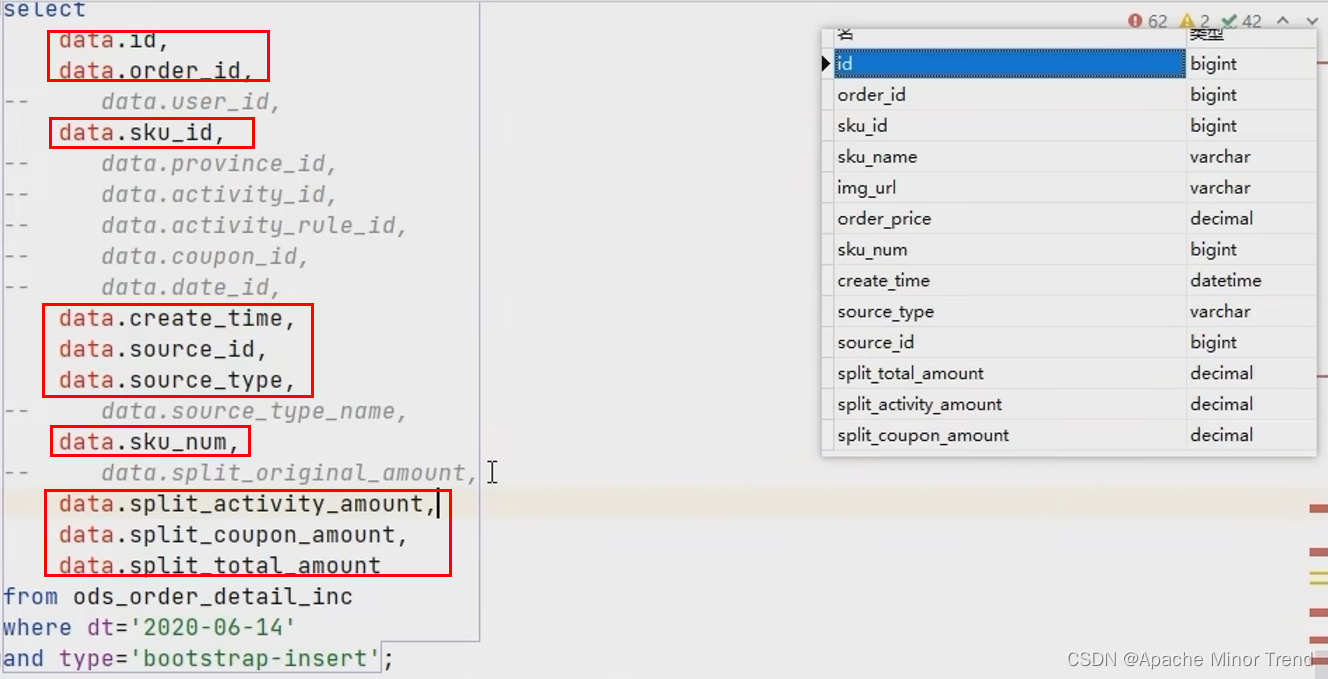
- 订单明细表不能获取到的字段,通过关联关系,进行子查询配置
- 子查询配置完成后,进行sql关联
- 关联完毕后,通过hive创建动态分区,实现收入不同时间下单数据进入到不同的分区。
- 最终整合完的sql如下:
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_order_detail_inc partition (dt)
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(create_time, 'yyyy-MM-dd') date_id,
create_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount,
date_format(create_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) od
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量量下单的数据加载
- 2020-06-15 增量下单明细数据加载-最终sql
- maxwell同步过来的数据,过滤出来insert类型数据即可。
insert overwrite table dwd_trade_order_detail_inc partition (dt='2020-06-15')
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_id,
create_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
date_format(data.create_time, 'yyyy-MM-dd') date_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-15'
and type = 'insert'
) od
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt = '2020-06-15'
and type = 'insert'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-15'
and type = 'insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-15'
and type = 'insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
3.交易域取消订单事务事实表
1.取消订单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:

- 1.选择业务过程:取消订单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成取消订单操作,这对应的是取消订单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:取消订单件数、取消订单原始金额、取消订单最终金额、活动优惠金额、优惠券优惠金额
2.取消订单事务事实表 DDL表设计分析
- 取消订单事务事实表中,一行代表一次用户取消订单操作。
DROP TABLE IF EXISTS dwd_trade_cancel_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_cancel_detail_inc
(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`activity_id` STRING COMMENT '参与活动规则id',
`activity_rule_id` STRING COMMENT '参与活动规则id',
`coupon_id` STRING COMMENT '使用优惠券id',
`date_id` STRING COMMENT '取消订单日期id',
`cancel_time` STRING COMMENT '取消订单时间',
`source_id` STRING COMMENT '来源编号',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '商品数量',
`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',
`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',
`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',
`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域取消订单明细事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cancel_detail_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.取消订单事务事实表 加载数据分析
- 数据流程
- 数据来源相关:订单表 中 取消的订单 关联 取消订单表 中 订单详情,即可获取全量字段
1.首日全量取消订单的数据加载
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cancel_detail_inc partition (dt)
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(canel_time,'yyyy-MM-dd') date_id,
canel_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount,
date_format(canel_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) od
join
(
select
data.id,
data.user_id,
data.province_id,
data.operate_time canel_time
from ods_order_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
and data.order_status='1003'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量取消订单的数据加载
- maxwell同步过来的数据,update过来的数据,并且order_status的状态变为了取消状态。
- 15号取消的订单,可能是之前下单的订单,所以获取订单明细数据的时候,需要关联订单明细表的前几天的数据,需要跟时间维度进行关联,获取当天或者前一天的数据。
insert overwrite table dwd_trade_cancel_detail_inc partition (dt='2020-06-15')
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(canel_time,'yyyy-MM-dd') date_id,
canel_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) od
join
(
select
data.id,
data.user_id,
data.province_id,
data.operate_time canel_time
from ods_order_info_inc
where dt = '2020-06-15'
and type = 'update'
and data.order_status='1003'
and array_contains(map_keys(old),'order_status')
) oi
on order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
7.交易域购物车周期快照事实表
1.购物车周期快照事实表 前期梳理
-
周期快照事实表,实际上类似于Hive中按天做分区,然后全量拉取mysql中数据,这样就会形成mysql的快照,每日全量快照表。
-
周期快照事实表,解决的主要问题:对于商品库存、账户余额这些存量型指标,业务系统中通常就会计算并保存最新结果,所以定期同步一份全量数据到数据仓库,构建周期型快照事实表,就能轻松应对此类统计需求,而无需再对事务型事实表中大量的历史记录进行聚合了。
-
周期快照表的创建,完全是基于需求来的,是服务于需求的,此处创建购物车周期快照事实表,是服务于需求:各分类商品购物车存量Top10
- 将购物车存量数据创建购物车周期快照事实表,直接基于此表,按照sku_id分组求和sku_num,就可简单实现上面的需求。
-
周期快照表和业务过程对照关系,没有必要进行讨论,可能对应一个业务过程,也可能对应两个业务过程。
2.购物车周期快照事实表 DDL表设计分析
DROP TABLE IF EXISTS dwd_trade_cart_full;
CREATE EXTERNAL TABLE dwd_trade_cart_full
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`sku_name` STRING COMMENT '商品名称',
`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域购物车周期快照事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.购物车周期快照事实表 加载数据分析
insert overwrite table dwd_trade_cart_full partition(dt='2020-06-14')
select
id,
user_id,
sku_id,
sku_name,
sku_num
from ods_cart_info_full
where dt='2020-06-14'
and is_ordered='0';


















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









