




一 Embedding模型微调
目标:使模型生成的向量在语义空间中更贴合特定领域/任务的相似性需求(例如医学文本、法律条款、电商商品描述)。
核心方法:对比学习(Contrastive Learning)
原理:让相似的样本(正样本对)向量靠近,不相似的样本(负样本对)向量远离。
常用损失函数:
MultipleNegativesRankingLoss:最常用且效果通常较好。在一个batch内,将一个query的正文档作为其正样本,将其他query的正文档视为该query的负样本。
TripletLoss:需要显式构造(anchor, positive, negative)三元组。
CosineSimilarityLoss:直接优化query和文档embedding之间的余弦相似度得分。
微调步骤:
准备训练数据:
格式:(query, positive_document) 对。
关键:正样本必须是真正相关的文档(高质量标注数据最重要!)。
负样本:通常在训练时动态生成(如in-batch negatives),也可以显式添加困难负样本提升效果。
数据来源:人工标注、点击日志(用户点击的作为正样本)、链接数据(如维基百科内部链接)、生成式模型(如GPT-4)生成。
选择预训练模型:
通用文本Embedding模型:
text-embedding-ada-002、BAAI/bge-base-en-v1.5、intfloat/e5-base-v2、sentence-transformers/all-mpnet-base-v2。
选择工具/库:
Sentence Transformers:最推荐!封装了训练流程、损失函数、评估方法。
Hugging Face Transformers:更底层,灵活性更高。
Haystack:封装了训练流程,方便集成到流水线中。
关键参数与技巧:
Batch Size:越大通常越好(能提供更多in-batch negatives),受显存限制。
学习率:较小的学习率(如2e-5到5e-5)比较安全。可使用学习率调度器(如warmup)。
温度参数:某些损失函数(如CoSENTLoss)有温度参数,可调节相似度得分的分布。
困难负样本:显式添加与query相似但不相关的文档作为负样本,能显著提升模型区分能力。
双编码器 vs 交叉编码器:Embedding微调通常训练双编码器,query和doc独立编码,利于大规模检索。
评估:
内在评估:在标注了相关性的开发集上计算指标(如Spearman相关系数、余弦相似度相关性)。
外在评估:将微调后的Embedding模型集成到检索系统中,看最终检索效果(Recall@K, MRR, NDCG等)的提升。
二、Rerank模型微调
目标:对初步检索(如使用Embedding模型)返回的Top K个候选文档,进行更精细的相关性排序。
核心方法:文本对分类(Text Pair Classification)
原理:将(query, document)对输入模型,模型输出一个相关性分数或分类标签(相关/不相关)。
常用损失函数:
CrossEntropyLoss:最常用,模型输出一个分数,与真实标签计算损失。
MSE Loss:回归任务,模型直接预测相关性分数。
微调步骤:
准备训练数据:
格式:(query, document, relevance_score/label) 三元组。
关键:
relevance_score/label 需要高质量标注(如0-1分数,0/1标签,或多级相关性如0-4)。
负样本应主要来自初步检索返回的困难负样本(看起来相关但实际不相关),而非随机负样本。
数据来源:人工标注(针对初步检索结果)、日志数据(用户对检索结果的后续交互行为,如点击、停留时长、跳过)。
选择预训练模型:
强大的序列理解模型:
bert-base-uncased, roberta-base, microsoft/deberta-v3-base, BAAI/bge-reranker-base等。通常比Embedding模型更大。
选择工具/库:
Hugging Face Transformers:最常用和灵活。
Sentence Transformers:支持CrossEncoder类,封装了训练和预测接口。
Haystack:封装了训练流程。
关键参数与技巧:
输入长度:Rerank需要理解query和doc的细节,通常允许较长的最大序列长度(如512)。
批次大小:受模型大小和序列长度限制,通常比Embedding微调小得多。
学习率:较小的学习率(如1e-5到5e-5)。
负样本策略:训练数据中必须包含高质量的困难负样本,这是提升Rerank效果的核心。
任务类型:
回归:预测相关性分数(0-1)。
分类:预测相关/不相关(二分类)或多级相关性(多分类)。
交叉编码器:Rerank微调训练的是交叉编码器,query和doc一起输入模型进行交互计算,计算代价高,不适合大规模候选集。
评估:
排序指标:在标注了相关性的测试集上计算:
NDCG@K:最常用,考虑位置和分级相关性。
MAP / MRR:衡量相关文档排在前面位置的能力。
Precision@K / Recall@K:衡量前K个结果的相关性比例/召回比例。
端到端评估:将微调后的Reranker集成到完整检索流水线中,评估最终输出结果的业务指标。
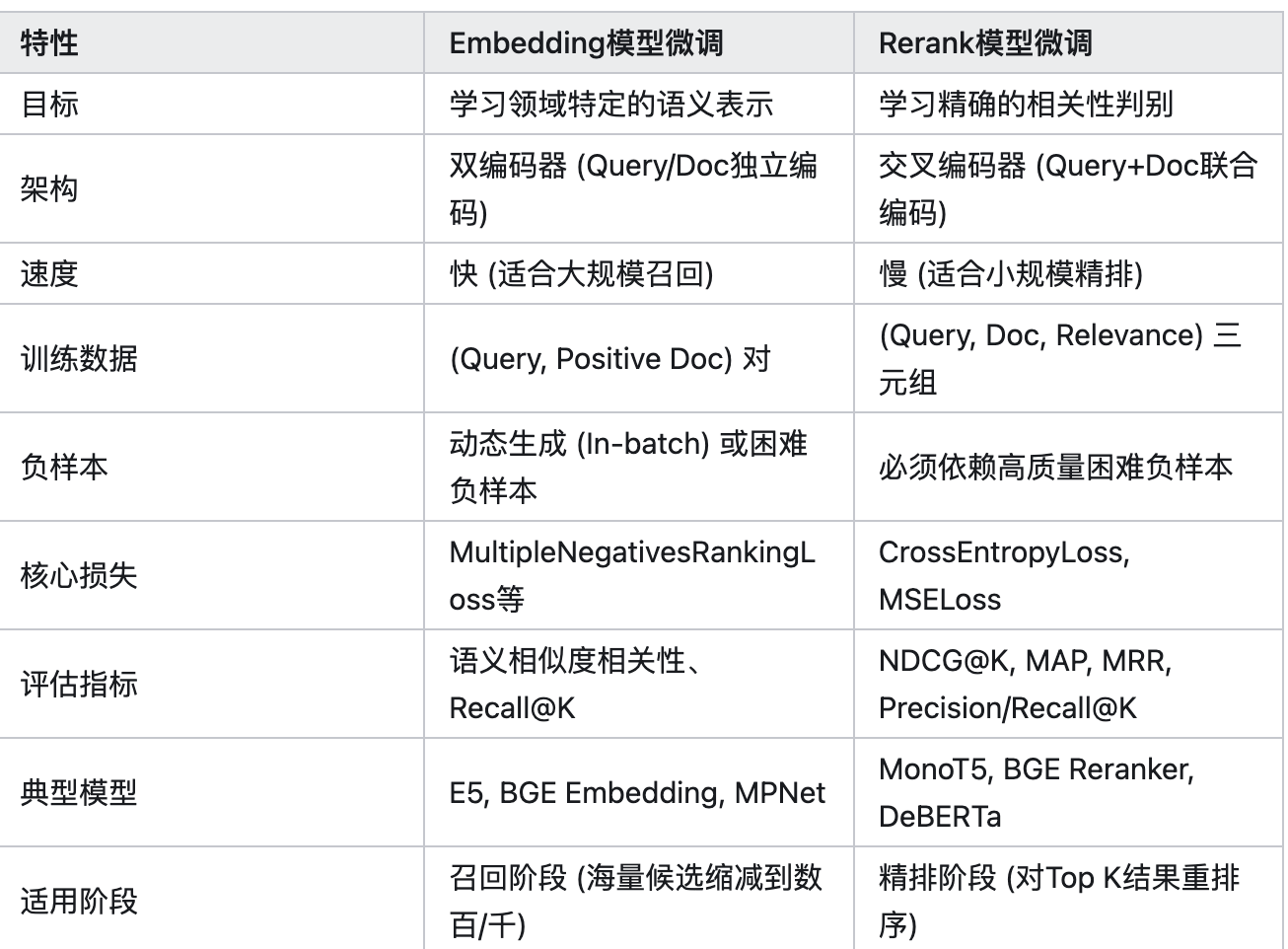
三 微调总结对比
四、重要注意事项
- 数据质量至上:
无论是Embedding还是Rerank,高质量、领域相关的标注数据是微调成功的最关键因素。垃圾进,垃圾出。
- 困难负样本:
对两者都极其重要,尤其是Rerank。收集那些容易被模型混淆的负样本(如相同主题但不相关、部分关键词匹配)。
- 领域适应性:
在特定领域(如生物医学、金融、法律)微调通常比通用模型效果显著提升。
- 计算资源:
Embedding微调:相对资源友好,可在单张消费级GPU(如3090)上进行。
Rerank微调:模型更大、序列更长、批次更小,通常需要更大显存的GPU(如A100)或使用LoRA等技术。
- 评估驱动:
始终在独立的验证集和测试集上进行严格评估,避免过拟合训练集。关注端到端效果。
- 流水线集成:
微调完成后,将模型集成到你的检索流水线中(如使用Milvus/Pinecone/FAISS + Embedding模型召回 -> Reranker精排)。
- 开源模型 vs API:
考虑使用开源的SOTA模型(如BGE系列)进行微调,通常比直接调用OpenAI等API更灵活、可控且成本更低(长期运行)。
- 模型蒸馏:
如果微调后的大模型效果很好但推理太慢,可以考虑将其知识蒸馏到更小的模型上。
总结:
Embedding微调关注高效召回,通过对比学习优化向量空间;
Rerank微调关注精准排序,通过分类/回归任务学习细粒度相关性。
两者结合使用是构建高性能检索系统的黄金标准。
务必重视高质量训练数据(尤其是困难负样本)和严格的评估。
五、Arctic-embedding模型训练经验
1.使用cls pooling而非平均池化。让模型学习得到一个句子级别的表示而非只是token 向量的平均。~2.5 NDCG@10
- 更好的训练数据存在于大型、标准的基于爬取的数据集中。它不需要很大,因此过滤它可以加快训练速度并提高性能。使用 8 个 H100 不到 1 天。
3.在更长的句子上训练,更多的上下文=更多的收益。☄️
4.根据数据分布不同进行构造训练集,batch 内随机负例来自相同的数据集比来自整个数据集更好。
5.人造数据可以很好的帮助提高性能,但是需要用正例doc和负例doc来作为条件来生成。
- 负例的难度在采样时非常重要。 选择一些困难的例子,但不要太难。
在微调阶段,质量比数量更重要。大量低质量的数据会导致低质量的模型。
六 MAKING TEXT EMBEDDERS FEW-SHOT LEARNERS” 论文阅读经验
架构上,保留单向注意力,同时基于chat版本模型作为基座,但是在[EOS]前加一个[EMB]专门用于提取表征,而不是直接用[EOS](避免语义冲突)
last token + 单向注意力最佳
如果文本没有长的离谱,建议不切分,直接使用原始query,这里其实不用担心文本非常长、信息熵低会导致llm忽略/降低对关键部分的表征,实测直接长文本相较于chunk会有意想不到的收获
在训练和推理的时候结合Instruct,如“将下述表达压缩成一个token”之类的
训练推理结合ICL ,但是注意可能带来的额外检索成本
沿用bge的三阶段训练,但是注意,
第一阶段的retro-mae量级应控制在较小规模,
后续的通用&垂域对比学习照旧,
且第三阶段的训练最重要!
领域对比学习的时候可以沿用IR的一些经典tricks,如大的batch_size, in_batch_neg等。(注意如果in_batch数据是有标签规则构建的,batch内其他数据的pos可能也是当前数据的pos,可以修改loss避免这个错误)
可以采用多阶段模型合并的方式缓解领域数据微调引起的灾难性遗忘:由于采用了三阶段的训练,产出了多个版本的模型,因此可以使用“邪教-模型合并大法”!

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









