



#前言
在写了,再写了(指新建草稿)。
本文将结合C#在Unity中的应用讲解,代码编辑器使用Visual Studio。讲解内容来自《C#高级编程 第10版》和我的理解,如果有错希望大佬指出(骂我,不要客气!)。
下面是《C#高级编程 第10版》的pdf文件分享
#正文
#数组
数组是存储同一种数据类型多个元素的集合。
如果需要使用同一类型的多个对象,就可以使用集合和数组。
-
简单数组(一维数组)
int
[
]
myArray
;
//数组的声明,在类型后面加上[ ]代表声明了一个数组变量,这个类型可以是基础数据类型也可以是自己声明的类和结构。
myArray
=
new
int
[
4
]
;
//正如之前的变量使用前需要初始化,在使用数组之前也应该让他初始化。初始化的声明方式与类型类似,new 类型[数量] 的格式来给变量赋值一个【数量】长度的数组。
myArray
[
0
]
=
1
;
//数组代表着存储着多个相同类型的变量,上面的声明只是给了myArray这个数组变量进行了赋值,但实际上其中的存储的变量并没有被初始化赋值。之后仍然需要对其中变量进行初始化赋值。在C#里int,float这些存储的变量初值为0,虽然有初值但还是建议大家初始化后在使用,毕竟不初始化后使用也不符合你的意图。自己创建的类和string则必须初始化后使用,不然会报错。
myArray
=
new
int
[
4
]
{
1
,
2
,
3
,
4
}
;
//这是初始化数组的另一种方式,表示在初始化数组是也将其中的变量进行了赋值。
int
a
=
myArray
[
0
]
+
1
;
//数组采用下标的方式从其中取出数据,下标一般从0开始,0,1,2,3,都是整数,不能是小数,这段代码表示,a = 1 + 1;
一维数组的声明和使用都挺简单的,相信大家很轻松就能掌握。
虽然C#中没有指针的概念,但我还是希望大家可以从引用(指针)的层面理解一下数组,这对理解接下来的多维数组,尤其是锯齿数组(我以前学的时候是叫这名吗?)有奇效。
这里先简单介绍一下Array类和数组的关系,之后详述:
用方括号声明数组是C#中使用Array类的表示法。
在我们使用int[] 声明数组时,C#在后台帮我们自动创建了一个派生自抽象基类Array的新类。使用我们才能使用数组时调用 .length .Clone() 这些原本在Array中的方法和字段。
所以,实际上数组是声明了一个类。
回忆一下之前在值类型和引用类型中说的内容。类的声明实际是创建了一个用于存放指向堆中的存储数据的地址的变量(有点绕,就是存地址的),也就是一个引用(指针)。
在自己创建的类声明的数组变量初始化时,会去指向一块地址,而这个地址就是数组的开头。数组在内存中的存储是一段连续的区域,数组中的每一个元素(myArray[0],myArray[1]这样,我自己创建的词,嘿嘿),实际上也是存储着指向某个地址的(存储地址的数据是固定长度的)。在一维数组中,他们指向的就是元素所代表的值。
还有就是基础数据类型创建的数组,比如int,float,bool(不含string),数组变量指向的地址中,每一个元素存储的将会不再是地址,而是数值。因为int这些类型存储是有固定的长度的,所以也可以使用下标来找到对应数据。
刚刚提到了数组的存储是一段连续的区域,正是因为数组是一段连续的区域,在我们使用下标查找要使用的元素内容时,只需要使用 存储大小 * 下标数 + 第一个元素开头的地址(myArray[0]) 这样就可以快速的找到所需要的元素的地址,从而快速的取出地址中的数据。比起使用链表(之后讲),数组下标找数据速度方面更胜一筹。
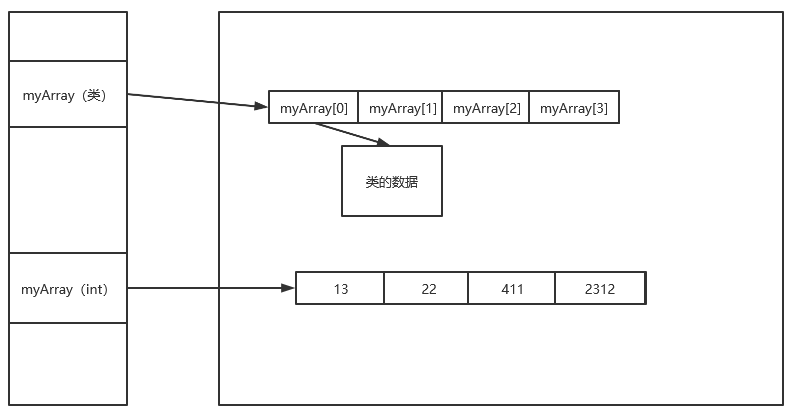
上面的图已经讲的很清楚了,至于链表之类的东西,如果大家陪伴我的时间足够久,应该是能见到的。
一维数组使用方便,未来的编程中是基础中的基础,多理解些东西准没错。(十一点了,我好饿啊,还有一小时开饭,要饿死了。(ヘ・_・)ヘ┳━┳ (╯°□°)╯︵ ┻━┻)
-
多维数组
int
[
,
]
a
=
new
int
[
3
,
3
]
;
a
[
0
,
0
]
=
1
;
a
[
0
,
1
]
=
2
;
…………
//省略中间赋值步骤
a
[
2
,
2
]
=
9
;
a
=
{
(
1
,
2
,
3
)
,
(
4
,
5
,
6
)
,
(
7
,
8
,
9
)
}
;
int
[
,
,
]
b
=
new
int
[
3
,
3
,
3
]
;
下图截取自《C#高级编程》P183

在使用上看上去像是二维数组(多维数组),但实际上,这种方式声明的数组在存储形式上仍然是一维数组,它只是被做成了二维数组的方式。
这里比较值得关注的是这种多维数组的声明方式和下面要讲的锯齿数组(有些地方将两者都叫做多维数组,接下来所说的多维数组均值这种多维数组。)之间的不同,以及多维数组与一维数组地址下标的转换(平时用不到,考试逃不掉)。
多维数组和锯齿数组的不同我们放到讲了锯齿数组之后在讲,先来说说多维数组和一维数组的下标转换。
首先这样的int[3,3]的多维数组最大的元素个数是3 * 3 = 9个,对应一维数组最大的下标就是a[8](下标从0开始)。

对应二维数组的公式就是 a[x, y] = a[x * 单列长度 + y]
其他长度的多维数组大家自己推敲便可。
-
锯齿数组
int
[
]
[
]
a
=
new
int
[
3
]
[
]
;
a
[
0
]
=
new
int
[
2
]
{
1
,
2
}
;
a
[
1
]
=
new
int
[
6
]
{
3
,
4
,
5
,
6
,
7
,
8
}
;
a
[
2
]
=
new
int
[
3
]
{
9
,
10
,
11
}
;
下图截取自《C#高级编程》P184
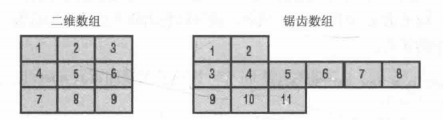
接下来我们在看看,锯齿数组的存储方式:
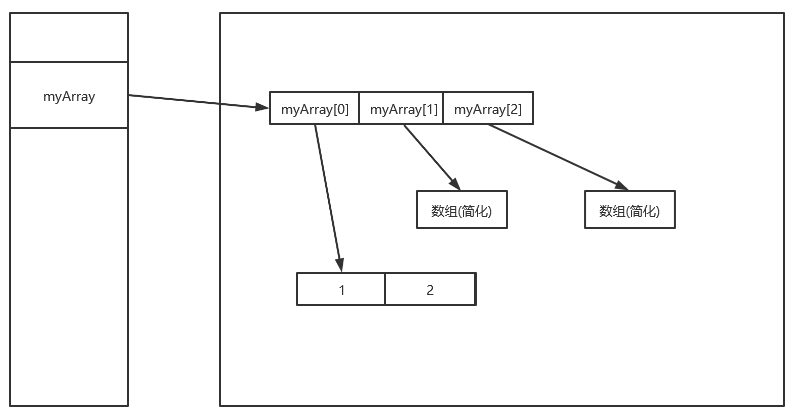
有了之前一维数组的洗礼,相信大家一下子就可以看懂锯齿数组。锯齿数组就是一维数组套娃。
来说说锯齿数组和多维数组的不同吧:
1.首先的一点就是两者使用中的区别,多维数组每条数组的长度是相同的,而锯齿则可以不相同。
2.其次是存储方式,多维数组本质是一维数组,锯齿数组则是一维数组套娃。
3.最后则是数据存储位置上的区别,这点就不详诉了,和计算机组成原理有关系的内容(学艺不精,不敢瞎说),总之因为数据存储位置的关系,多维数组相较于锯齿数组存取速度更胜一筹。
#Array类
前面提到的Array类,现在开始详细讲解。
Array是抽象类,无法使用构造函数来创建数组,即不能直接new Array() ,但可以使用GreateInstance来创建数组(这里创建的数组和之前的数组使用上有一些区别,但本质相同)。
-
创建数组
Array
intArray1
=
Array
.
CreateInstance
(
typeof
(
int
)
,
5
)
;
for
(
int
i
=
0
;
i
<
5
;
i
++
)
{
intArray1
.
SetValue
(
33
,
i
)
;
}
for
(
int
i
=
0
;
i
<
5
;
i
++
)
{
Debug
.
Log
(
intArray1
.
GetValue
(
i
)
)
;
}
intArray1并不是像数组一样在后面加上 [ ] 进行索引,必须通过GetValue()方法。但可以通过 int[] a = (int[])intArray;的方式将Array类转变成数组,在进行索引。
以上是一维Array类的基础创建和赋值,因为CreateInstance有许多重载方法,可以创建多维数组,也可以自己指定下标从哪个数字开始。具体的创建有需要就百度吧,这里不再详诉。
因为 int[] 数组实际上也是使用的Array类,所以以上的方法都可以直接再 int[] 变量上直接使用,当然下面讲的也都可以。
-
克隆数组
int
[
]
intArray1
=
new
int
[
2
]
{
1
,
2
}
;
//相当于int[] intArray1 = {1, 2};
int
[
]
intArray2
=
(
int
[
]
)
intArray
.
Clone
(
)
;
//Clone()返回的是Object类,所以还需要一个强制转换符。
上面我们就说过数组其实是Array类的子类,而类变量直接赋值实际上是两者指向相同的数据块,如果我们需要一个新的相同的数组就应该使用克隆方法Clone();
下面两张图均来自《C#高级编程》,分别是P186, P187:
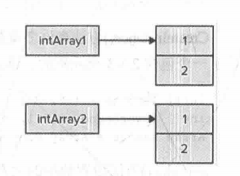
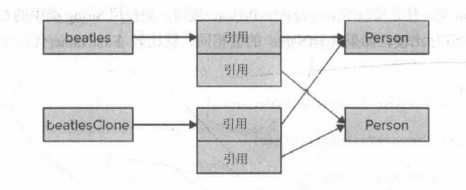
两张图分别代表了值类型和引用类型时,Clone()使用的情况。
-
排序
string
[
]
a
=
{
"adada"
,
"bafada"
,
"cdaddw"
,
"d"
,
"Adada"
,
"B"
}
;
Array
.
Sort
(
a
)
;
//排序
for
(
int
i
=
0
;
i
<
a
.
Length
;
i
++
)
{
Debug
.
Log
(
a
[
i
]
)
;
//排序结果是首字母a,b,c的顺序,优先小写字母,当出现单个字符时,优先级会提升,比如B,会在bafada前面。
}
string的排序就和上面说的差不多,int,float类型则是从小到大的排序。
基础数据类型可以直接使用Sort()(也可以使用自己写的排序方法,使用实现IComparer接口的类。),类的数组是必须有自己写的排序方法才能使用,即实现IComparable接口。
public
class
Person
:
IComparable
<
Person
>
//首先要使用的数组的类要实现这个接口
{
public
int
a
=
1
;
public
int
CompareTo
(
Person
other
)
//这就是要实现函数,返回值一般是0和1(区别方式是0和非0)
{
if
(
other
==
null
)
return
1
;
if
(
this
.
a
>
other
.
a
)
return
1
;
//数组中两个元素进行比较,如果返回1,前一个元素大于后面的元素,应该把后面的元素放在前面(这里是依靠a的值进行从小到大排序)
else
return
0
;
//返回0表示前一个元素更小,应该放前面。
}
}
Person
[
]
per
=
new
Person
[
3
]
;
Array
.
Sort
(
per
)
;
//排序
public
class
SortMethod
:
IComparer
<
int
>
{
public
int
Compare
(
int
x
,
int
y
)
{
return
0
;
//返回值一般0和1
}
}
Array
.
Sort
(
nums
,
new
SortMethod
(
)
)
;
//使用这种方式时SortMethod类必须有实现IComparer接口,然后nums数组可以使用SortMethod中的排序规则了,nums可以是基本数据类型,也可以是类(这里只能是int[])。
#元组
Tuple
<
string
,
int
>
tuple
=
Tuple
.
Create
<
string
,
int
>
(
"aaaa"
,
3121
)
;
Debug
.
Log
(
tuple
.
Item1
)
;
Debug
.
Log
(
tuple
.
Item2
)
;
数组只能存放相同数据类型的元素,而且元组则可以存放不同数据类型的元素。
元组的使用就像是个类,声明方式就像上面一样,其中Tuple<>中有多个重载,每有一个元素就要在里面提前写好那一个元素的类型,其中第八个类型是一个元组(Tuple<T1, T2, T3, T4, T5, T6, T7, 元组>),这样就可以保证可以有无限的长度了。
索引也不是采用下标的方式,采用 tuple.Item+要取的数 的方式来取值。
元组不怎么使用,一般不是相同的数据类型就分开放了,没必要强行放到一起,而且不同数据类型放到一起也不方便写处理方法。
#结束语
-
建议
数组在未来的编程中是非常常用的,了解多一些可以更好的使用。
其实我讲的内容是简化的,很多地方可能还没有讲清楚。如果大家哪里没有看懂,可以去翻看一下《C#高级编程 第10版》,如果还是没有搞懂,欢迎在评论区询问,我会尽力回答的。以上提到的内容都是基础中的基础,是绝对不允许出现不理解的情况的。
如果害羞不好意思在评论区询问,欢迎大家加我QQ来讨论哦。QQ:2243211562
-
杂谈
本来是打算连着集合一起讲了,结果单数组就讲了这么多,那莫法,只能下次再讲了。
下一个扩展阅读我打算做一款简单的小游戏,然后讲讲(做游戏,好废时间,还是打游戏比较爽),敬请期待!
文章写完了,要开始读一本全英语的书了,全英语啊,英语稀烂的我光想想人都要裂开了,诶。
感谢大家的阅读,下周见。

















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









