









Pytorch AttentionOCR 中文端到端的文字识别 程序完全可用
总体结构
本项目在CRNN的基础上进行修改完成的,基于Pytorch实现,程序完成可用
整体流程为:encoder+decoder
encoder采用CNN+biLSTM模型
decoder采用Attention模型
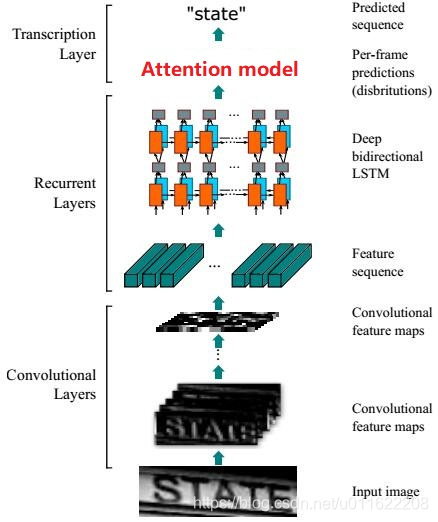
encoder
- encoder部分采用和crnn一样的模型结构,输入是32pix高的字符图片,宽度不定,但为了batch训练,图片的宽度需要统一,输出为特征矩阵。
- 在cnn特征提取部分,高度方向经过了4个pooling和一个卷积(valid模式),总共会使得原图的高度缩小pow(2,5)倍,即缩小32倍,宽度方向只是经历2个pooling和一个卷积(valid模式),最后的尺寸为width/4+1。举个例子,假设输入的是4张32* 280的彩色图片,最后的特征矩阵为: 4 * 1 * 71* 512
- encoder第二部分,通过BidirectionalLSTM进行前后序列特征的增强。举个例子,前面cnn的特征矩阵输出为4* 1 * 71*512,这里以一张图片为例,一张图片为71 * 512,71可以理解为宽度方向有71个字符,512可理解为每个字符的特征向量,送入BiLSTM时,就是第1个字符的512,第2个字符的512,第3个字符的512,…,特征的宽度方向看成序列,依次送入BiLSTM。总结,其实就是一个特征增强。看资料这里也可以用con1d代替,有待实验。经过BiLSTM之后特征为4 * 71 * 256,256为BiLSTM隐藏节点的个数
Attention decoder
decoder部分主要做不定长文字的识别,和图像描述很像,就是不定长序列(文字)的生成,所以需要用到RNN。
总体流程
- 根据一定的规则求取权值;
- CNN特征乘以权重送入RNN;
- RNN后接一个linear,再接一个softmax;
1.求取Attention权重
- 对前一次的输出做一个词嵌入(embedding)升维,
- 联合上一次的输出和RNN隐含层的状态,做一个linear和softmax,求得Attention权重
2.Attention权重乘以CNN特征
- Attention权重乘以CNN输出的特征矩阵,最后输出为4* 1*256,其实就是将71个字符,根据Attention权重合并成1个最大概率的字符
3.RNN不定长字符识别
- 现在就可以将4* 1*256输入RNN,RNN后在接一个linear和softmax,但是很多模型都会对权重CNN特征在做一些操作,不过最后送入RNN的为4 * 1 * 256,表示当前时刻最可能(attention权重)出现的字符。
优势
- 可以端到端训练,不需要进行字符分割等操作
- 推理时,只需要将图片的高度保持为32pix就行,宽度无限制
- 模型小,速度快
效果
| picture | predict reading | confidence |
|---|---|---|
  | 美国人不愿意与朝鲜人 | 0.33920 |
  | 现之间的一个分享和 | 0.81095 |
  | 中国通信学会主办、《 | 0.90660 |
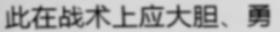  | 此在战术上应大胆、勇 | 0.57111 |
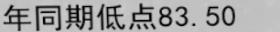  | 年同期俱点83.50 | 0.14481 |
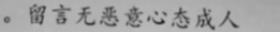  | 。留言无恶意心态成 | 0.31054 |
程序
详细程序在本人github仓库Attention_ocr.pytorch,预训练模型,数据集,标注文件都做好了,可以直接下载训练或者使用,最良心的是推理程序都写好了,克隆下来就能用。
other
本人现在在成都一个公司做图像识别算法工程师,最近想换工作,求有途径的人内推或介绍一下,或者有公司需要相关的人员的也可以。本人联系方式:778961303@qq.com

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









