



强化学习之父 Richard Sutton 说,当前的大语言模型是一条死路。
这听起来令人震惊。作为《The Bitter Lesson》的作者、2024 年图灵奖得主,Sutton 最相信“更多算力 + 通用方法必胜”,按理说他应该对 GPT-5、Claude、Gemini 这些大模型赞不绝口。但在最近的访谈中,Sutton 毫不客气地指出:LLM 只是模仿人说什么,而不是理解世界如何运转。
这场由播客主持人 Dwarkesh Patel 组织的访谈引发了激烈讨论。Andrej Karpathy 随后撰文回应,并在另一场访谈中展开了深入探讨。两位大师的争论揭示了当前 AI 发展中三个被忽视的根本问题:
第一,小世界假设的迷思:我们是否真的相信,一个足够大的模型能够掌握世界上所有重要知识,从此不需要学习?还是说,现实世界符合大世界假设——无论模型多大,在具体场景中仍需要不断学习?
第二,持续学习的缺失:当前的 model-free RL 方法(PPO、GRPO 等)只从稀疏的 reward 学习,无法利用环境给出的丰富反馈。这导致 Agent 在现实世界任务中样本效率极低,难以快速适应。
第三,Reasoner 与 Agent 的鸿沟:OpenAI 将 AI 能力分为五级,从 Chatbot 到 Reasoner 再到 Agent。但很多人误以为,把单轮 Reasoner 变成多轮就是 Agent。真正的 Agent 与 Reasoner 的核心区别在于:持续学习能力。
本文将系统梳理这两场访谈中的核心观点,并结合我们在 Pine AI 开发实时 Agent 的实践经验,探讨如何跨越这道鸿沟。
(插播一条广告,我把开发 Agent 的实践经验汇集成了一个书 + 课项目,从 0 到 1 手搓 Agent)
Richard Sutton 提出的三大核心问题
1. LLM 不是真正的世界模型
Sutton 的第一个核心观点是:LLM 并不是真正的世界模型,它只能预测人会说什么,但不能预测世界会变成什么样。
这个区别至关重要。真正的世界模型应该能够预测:如果我执行某个动作,世界会发生什么变化。比如:
我把手抬起,杯子会向上移动
我松开手,杯子会掉落并摔碎
而 LLM 学习的是什么呢?它学习的是在某种情况下,人会说什么、会做什么。这本质上是一种模仿学习(Imitation Learning),而不是对世界因果规律的理解。
当然,经过大量预训练,LLM 也能掌握一定的推理能力。但这并不等同于建立了一个严格的 transition model(状态转移模型)。预训练数据中的文本描述更像是“站在世界之外”观察世界的变化,而不是“我采取行动后世界如何变化”的第一人称交互式学习。
2. RL 样本效率低下,无法从环境反馈中学习
Sutton 指出的第二个问题是:当前的 RL 方法样本效率极低,而且只能从 reward 中学习,无法从环境的直接反馈(observation)中学习。
让我们用一个实际例子来说明这个问题。比如我们在 Pine AI,开发 AI Agent 来帮用户打电话办事(比如联系 Xfinity 客服):
第一次尝试:Agent 打电话给客服,客服说:“我需要您的信用卡后四位来验证身份”。Agent 没有这个信息,只能挂断电话,任务失败,reward = 0。
传统 RL 的问题:Agent 只知道这次尝试失败了(reward = 0),但它不知道怎么做才是对的。客服明确告诉了需要什么信息,但 Agent 无法从这个 environmental feedback 中学习。它只能通过数百次 rollout,偶然尝试到提供信用卡信息,得到 reward = 1,才能学会。
人类的学习方式:人类第一次被告知需要信用卡信息,就会立即记在小本本上。下次遇到类似情况,直接就会准备好这个信息。
这种差异的根源在于:现在的 PPO、GRPO 等 policy gradient 方法都是 model-free(无模型)算法,本质上只基于 reward 学习,而不能从 observation 中直接学习知识。
所谓 model-free,是指这些方法只学习 policy(策略),即“在某个状态下该做什么动作”,但不学习 world model(世界模型),即“执行某个动作后世界会变成什么样”。这就导致它们无法利用环境给出的丰富信息,只能依赖稀疏的 reward 信号。
3. 泛化能力缺乏保证
Sutton 提出的第三个问题是:梯度下降(gradient descent)方法学到的知识表示,并不能保证具有良好的泛化能力。
如果一个问题只有唯一答案(比如数学题),那么模型最终会找到这个答案。但如果问题有多种可能的解决方案,梯度下降并没有内在的 bias 去找到其中最容易泛化的那个表示。
虽然我们在训练时会使用各种正则化技术来提升泛化能力,但这些机制并不能保证学到深层的、可推理的规律。这就是为什么很多 Agent 系统需要外部的 memory 系统来显式地总结和结构化知识。
当前 Agent 的学习方式及其局限
面对 Sutton 指出的这些问题,当前的 Agent 系统主要通过三种方式来应对:
1. In-Context Learning(上下文学习):Long Context 的误解
In-context learning 可以解决单个 session 内的学习问题。比如在上面的例子中,当客服说需要信用卡信息后,这个信息会留在 context 中,Agent 在同一个 session 的下一步就知道要询问用户。如果我们把 context 一直带到后续任务中,Agent 也能在新任务中应用之前学到的知识。
但很多人认为,既然有了 long context,我们可以把所有历史信息都放进去让模型自动推理学习。这是对 context 能力的严重误解。
Context 的本质:检索而非总结
Context 的本质更像 RAG 而非推理引擎。每个 token 被映射成 QKV 三个向量,通过 attention 机制找到与当前查询最相关的上下文。这意味着知识没有被自动提炼和总结,而是以原始形式存储在 KV Cache embedding 中。
让我用几个实际案例说明这个问题。
案例一:黑猫白猫的计数问题
假设上下文中有 100 个案例:90 只黑猫和 10 只白猫。如果我没有告诉模型“90 只黑猫,10 只白猫”这个总结,而是把 100 个个体的信息逐一列出,那么每次问到相关问题时,模型都必须花费额外的 reasoning tokens 去扫描一遍这 100 个案例,重新统计和计算。
通过 attention map 可以清晰地看到:当问到“黑猫和白猫的比例”时,前面所有相关的 case token(100 个猫的案例)都会得到比较高的 attention value,而且 reasoning token 会重复之前 turn 的 reasoning 过程(数数、统计)。这说明模型是从原始信息里做推理,而不是直接使用已经总结好的知识。
更糟糕的是,每次问到相关问题,这个重新扫描和推理的过程都会重复一遍,效率极其低下,而且错误率高。本质上是知识仍然以原始形式存储,KV Cache 不会自动对知识做总结。
案例二:Xfinity 优惠规则的错误推理
假设我们有三个孤立的历史案例:退伍军人可以享受 Xfinity 优惠、医生可以享受优惠、其他人不能享受优惠。如果没有提炼出“只有退伍军人和医生可以享受 Xfinity 优惠”这个规则,而只是把所有案例放在 context 中,那么遇到新案例时,模型可能仅仅随机匹配到某一个或者某两个历史案例,没有匹配到所有相关案例,从而得出错误结论。
同样的,attention map 显示模型在推理时会把 attention 分散到三个孤立案例的 token 上,每次都要重新扫描这些案例,试图找到模式。但由于没有显式的规则总结,推理既低效又不可靠。
案例三:电话呼叫次数的失控
我们在实际开发中遇到的一个典型问题:prompt 要求“重复打同一个客户的电话不能超过 3 次”。但打了 3 次之后,Agent 经常数不清楚到底打了几次,又打第 4 次,甚至陷入类似 few-shot 的循环,反复不停地打同一个电话。
问题的根源在于,模型需要从上下文中的多个 tool call 历史记录里自己数清楚打了几次电话。这个计数过程每次都要重新扫描 context,而长上下文中的计数本身就容易出错。
但当我们在每个电话的工具调用结果中直接加入这个电话的重复呼叫次数(如“本次是第 3 次呼叫该客户”),模型就能立即发现已经达到限制,不再继续呼叫。这个简单的改动将错误率大幅降低。
为什么 System Hint 和动态总结有效
这就是为什么 system hint 技术和动态总结技术能够显著提升 Agent 性能。在上下文里面加入总结、补充和额外的结构化信息,让模型不需要每次都从原始数据重新推理,而是可以直接使用已经提炼好的知识。这样后续推理的效率和准确率都能大大提升。
即使使用 sparse attention 等技术支持长上下文,这个根本问题仍然存在:没有找到简洁的知识表达,没有自动提炼出可推理的规律。
由于目前的 long context 机制不会自动进行知识压缩和提炼,我们在实践中发现了一个重要的架构原则:
Sub-Agent 不应该与 Orchestrator Agent 共享完整上下文。
正确的做法是:Orchestrator Agent 维护完整的任务上下文,将相关信息压缩总结后再传递给 Sub-Agent,Sub-Agent 只接收经过提炼的、与其任务直接相关的信息。
这样做的好处不仅仅是节省 Context Length。虽然减少了 token 消耗,但更重要的价值在于知识提取。这种压缩总结的过程,本质上就是一种知识提取和结构化的过程,是 Agent 系统必不可少的能力。
Karpathy 的洞察:记忆差是 Feature 不是 Bug
Karpathy 在访谈中提出了一个深刻的观点:人类的精确记忆能力很差,但这不是 bug,而是 feature。记忆能力差强制我们从训练数据中提取关键知识,用结构化方式总结和记忆,而不是简单地背诵训练数据。这个洞察揭示了为什么 context 不应该只是简单的信息堆砌,而需要进行知识压缩和提炼。
这就是为什么 linear attention 是一个有趣的方向。Linear attention 用一个比较小的状态压缩 context 中的知识,强制模型进行知识压缩,而不是把所有东西都记住。这种机制更接近人类的记忆方式,可能带来更好的泛化能力。
跨模态压缩:DeepSeek-OCR 的启示
DeepSeek-OCR 提供了另一个有趣的视角:通过光学 2D 映射将长文本上下文压缩为图像。传统的文本 token 是 1D 序列,而图像是 2D 结构。DeepSeek-OCR 将文本渲染成图像,然后用视觉编码器(DeepEncoder)进行压缩,实现 10x 压缩比时 OCR 精度可达 97%,20x 压缩比时精度仍有约 60%。
这种跨模态压缩的价值不仅在于节省 tokens,更重要的是强制进行信息提炼。视觉编码器必须提取文本的关键特征而不是逐字存储,2D 空间结构保留了文本的布局和层次关系,压缩过程类似于人类阅读时关注整体结构而非逐字记忆,还可以解决 tokenizer 问题导致的“数不清 strawberry 中有多少个 r” 等经典问题。
对于 Agent 系统,这个思路很有启发:将大量历史交互压缩成视觉摘要(如思维导图、流程图),可能比保留完整文本更高效。这也呼应了 Karpathy 的洞察:记忆力差强制我们提炼本质。
2. 外部知识库
另一种方法是使用外部知识库,将从经验中提取的规则存储为结构化知识。比如:“联系 Xfinity 一定要准备信用卡后四位”。
这种知识提取过程可以利用额外的推理算力(如调用更强的模型)来完成,符合 Sutton 在 The Bitter Lesson 中强调的“利用更多算力的通用方法”原则:与其手工编写规则,不如让系统自动从经验中学习和提炼。
这种方法的优点是知识表示更简洁,但也有问题:知识库检索可能失败,孤立的知识片段难以进行复杂推理,随着知识积累,检索效率会下降。
持续学习:Agent 与现实世界任务的鸿沟
为什么 Agent 在现实任务中表现不佳?
这是一个非常 fundamental 的问题。很多人会问:Agent 解数学难题都比 99.9% 的人类强了,为什么在现实世界的工作中却干不好?
我们不妨这样思考:假设你找一个非常聪明的人,不经过任何培训就让他到你的公司工作,你觉得他能干好吗?
答案大概率是不能。因为:
他不了解公司的 coding style
他不知道公司的业务逻辑
他不清楚显性和隐性的约束
他不熟悉团队的协作方式
即使你把这些 context 整理成文档给他,也存在问题:很多隐性知识难以用文本表达,这些知识可能太多超出 context 范围,而且文本形式的知识难以进行深度推理。
人类为什么能做好?因为人类能够在环境中持续学习。
大世界假设 vs 小世界假设
Richard Sutton 信奉的是大世界假设(Big World Hypothesis):世界包含的信息是无限多的,模型只能学到其中很小一部分,Agent 不可能事先知道所有知识,必须通过与环境交互不断学习新能力。
而许多 LLM 学派持有的是小世界假设:虽然世界很大,但有简洁的规律可以描述。表面复杂的现象背后蕴含的知识并不多,足够大的模型(如 GPT-5、Claude)已经掌握了世界上大部分重要知识,不需要在环境中学习,只需应用这些通用知识。
现实世界更符合大世界假设。从书本和互联网学到的都是理论性的通用知识,但 Agent 在任何具体岗位工作时,都需要行业和领域非公开的专业知识、公司的特定规范和文化、以及个体的工作习惯和偏好。
这些知识无法完全用简短的 prompt 传递,必须通过持续学习获得。而前面提到的 model-free RL 方法无法从环境反馈中学习,正是 Agent 在现实世界任务中难以快速适应的根本原因。
探索解决方案:双 LoRA
针对持续学习的问题,我们在实践中探索了一些解决方案。核心思想是:在 RL 过程中,除了学习 policy,同时也要学习 transition model。
双 LoRA 方法
我们在尝试一种双 LoRA 方法:
LoRA 1:Policy Learning 使用类似 DAPO 的方法,基于 reward 更新梯度,学习什么动作能最大化收益。
LoRA 2:Transition Model Learning 使用 next token prediction,但 predict 的不是 action,而是 observation。通过 minimize 对工具调用返回结果的预测 loss,不断更新对世界的认知。这个思路与 Meta 最近的 Early Experience paper 类似,都是通过预测环境反馈来学习世界模型。
这本质上是一种 TD-Learning(Temporal Difference Learning,时序差分学习):我预测执行 action 后下一时刻的世界状态,如果实际状态与预测不符,这就是 loss,通过这个 loss 更新模型对世界的理解。
技术实现细节
双 LoRA 的关键在于参数空间的正交分解:
Rank 分配:假设我们总共分配 rank = 64 的 LoRA 参数空间,我们将其分为两部分:
LoRA 1 (Policy):前 32 个 rank
LoRA 2 (World Model):后 32 个 rank
梯度隔离与优化:
Policy Gradient(LoRA 1):
使用 DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization) 算法
梯度只更新前 32 个 rank 的参数
Observation Prediction Loss(LoRA 2):
使用标准的 next token prediction
梯度只更新后 32 个 rank 的参数
Loss 函数:
L_world = -E[log P(o_{t+1} | s_t, a_t)]其中 o_{t+1} 是环境返回的 observation(工具调用结果)
训练流程:
在每个 training step:
Agent 执行 action,获得 observation 和 reward
计算两个 loss:
L_policy:基于 reward 和 advantageL_world:基于 observation prediction error
分别对两组 rank 进行梯度更新:
∇_{LoRA1} L_policy→ 更新前 32 个 rank∇_{LoRA2} L_world→ 更新后 32 个 rank
两个梯度在参数空间正交,互不干扰
样本效率的巨大提升
回到之前的例子,使用双 LoRA 方法后:
传统 RL 需要上百次 rollout,偶然发现提供信用卡信息可以成功,然后才能学会。
双 LoRA + TD-Learning 的过程则是:第一次客服告知需要信用卡信息时,虽然 reward = 0,policy gradient 学不到东西,但 environment feedback 告诉我们需要 CVV。通过 observation prediction 的 loss 直接学习,几个 step 后就能学会。
这种方法的样本效率远高于传统 RL。
知识总结与结构化
即使使用双 LoRA,gradient descent 仍然存在一个 fundamental 的问题:它是数据拟合,得到的知识泛化能力没有保证。
因此,我们还需要通过额外算力进行知识总结和整理,提取结构化的知识,组织成可推理的形式。
这种方法正是 Sutton 在 The Bitter Lesson 中提倡的核心原则:利用更多算力的通用方法。与其手工设计规则,不如让 Agent 用额外的推理算力从经验中自动提炼规律,将知识压缩成结构化形式。这种 meta-learning 的过程本身就是一种学习能力的体现。
比如市面上很多 memory 相关的论文,都在做这件事:把经验提取成结构化知识,以更高效的方式进行推理和学习。
生物进化也是强化学习
进化的 RL 视角
Sutton 和 Karpathy 在访谈中对“动物是否从零开始学习”有争论。Karpathy 的观点更有说服力:动物不是从零开始的,而是有漫长进化过程作为先验。
如果真的所有肌肉反射都随机初始化,小马驹一定活不下来。预训练实际上是对进化过程的粗略模拟。
但从另一个角度看,生物进化本身就是一种 RL 算法:
奖励函数:能繁衍后代 reward = 1,不能繁衍后代 reward = 0。
算法特点:只看结果不看过程,每个生物个体是一次 rollout,种群规模为 N 时每代学到的信息量约为 O(log N)。
Outer Loop RL:进化是一个非常长尺度的强化学习,每一代都是一个 iteration,通过无数代的积累不断优化“权重”(基因)。
DNA 相似度与 LoRA 训练的类比
这个视角可以解释一个有趣的现象:为什么人类和其他动物的 DNA 这么相似?
人与大猩猩:99% 相似
人与狗、猫:60%+ 相似
人与植物:40%+ 相似
如果把进化理解成 LoRA 训练,每一代只能收集少量 information(log N bits),变化量与代数大致成正比,系数不会特别大。
这就像 LoRA 训练:在强基座模型基础上,只需要少量参数修改就能学到很多东西。
学习一门新语言需要修改多少参数?
70B 模型:约 1% 的参数
7B 模型:约 6-7% 的参数
即使用这么少的参数,在新语言的维基百科上继续训练,模型就能说该语言说得很流利。
这印证了:学会新东西的信息量没有想象的那么多,通过 LoRA 等高效方法可以很好地将这些信息编码到模型中。
推荐阅读:John Schulman 的《LoRA without Regret》,深入讲解了 LoRA 的细节和原理。
实验案例:用 LoRA 让 Mistral 7B 学会韩语
我们用 Mistral 7B 做了一个有趣的实验来验证这个观点。Mistral 7B 原本不具备韩语能力,但通过两阶段训练:
阶段一:韩语维基百科继续预训练
数据:5% 的韩语维基百科(加快训练)
LoRA rank = 128,包含 embed_tokens 和 lm_head
学习率:5e-5(主体)+ 1e-5(embedding 层)
训练 1 epoch
使用 unsloth 框架,在 8 卡 4090 上训练 4 小时
阶段二:韩语指令微调(SFT)
数据:Alpaca GPT-4 韩语翻译数据集
训练 2 epochs
使用 unsloth 框架,在 8 卡 4090 上训练 4 小时
三阶段对比结果:
测试任务
Baseline(原始 Mistral)
Pretrained(韩语预训练后)
Finetuned(指令微调后)
韩语维基(AI 词条) ❌ 重复、逻辑混乱
⚠️ 语法改善但仍重复
✅ 流畅、结构化
英语维基(AI 词条) ✅ 优秀
✅ 保持优秀
✅ 保持优秀
韩语指令(介绍首尔) ✅ 基本正确但简单
⚠️ 内容重复
✅ 详细、自然
英语指令(感恩节火鸡) ✅ 优秀
⚠️ 出现元文本错误
✅ 恢复优秀
具体输出示例:
示例 1:韩语维基百科 - 人工智能词条
Prompt(提示):Wikipedia Article / Title: 인공지능 (Artificial Intelligence) / Article:
Baseline 输出:
1 인공지능(artificial intelligence, AI)은 인간의 지능을 모방하는 컴퓨터 프로그램이다. 2 인공지능은 인간의 지능을 모방하는 것이 아니라 인간의 지능을 넘어서는 것이 목표이다. 3 인공지능은 인간의 지능을 모방하는 것이 아니라 인간의 지능을 넘어서는 것이 목표이다...翻译:人工智能是模仿人类智能的计算机程序。人工智能的目标不是模仿人类智能,而是超越人类智能。人工智能的目标不是模仿人类智能,而是超越…(陷入重复循环)
Finetuned 输出:
1 인공지능(AI)은 인간 지능이 필요한 작업을 수행할 수 있는 컴퓨터 시스템을 개발하는 것을 의미합니다. 2 인간의 지능을 모방하는 기계 또는 컴퓨터 프로그램을 만드는 것을 의미합니다. 3 이러한 작업에는 자연어 이해, 이미지 인식, 의사 결정 및 문제 해결 등이 포함됩니다.翻译:人工智能(AI)意味着开发能够执行需要人类智能的任务的计算机系统。它意味着创造模仿人类智能的机器或计算机程序。这些任务包括自然语言理解、图像识别、决策和问题解决等。
示例 2:韩语指令 - 介绍首尔
Prompt(提示):Instruction: 대한민국의 수도인 서울에 대해 간단히 소개해주세요. (Briefly introduce Seoul, the capital of South Korea.) / Response:
Baseline 输出:
1 서울은 대한민국의 수도이며 한국의 경제, 문화, 정치, 사회 등 다양한 분야에서 중앙 지역입니다. 2 서울은 한국의 최대 도시이며 대한민국의 사람들 중 1/3 이상이 거주하고 있습니다. 3 서울은 한국의 경제 중심지이며 여러 대기업과 기업 등이 서울에 위치하고 있습니다.翻译:首尔是韩国的首都,在经济、文化、政治、社会等各个领域都是中心地区。首尔是韩国最大的城市,超过 1/3 的韩国人居住在这里。首尔是韩国的经济中心,许多大企业和公司位于首尔。
Finetuned 输出:
1 서울은 대한민국의 수도이자 가장 인구가 많은 도시입니다. 2 이 도시는 역사, 문화, 경제의 중심지로 알려져 있으며, 인구는 1000만 명 이상입니다. 3 서울은 높은 건물과 북적거리는 거리, 역사적인 사원과 궁전, 4 현대적인 건축물과 문화 유산이 혼합된 매력적인 도시입니다.翻译:首尔是韩国的首都和人口最多的城市。这座城市以历史、文化和经济中心而闻名,人口超过 1000 万。首尔是一座充满魅力的城市,融合了高楼大厦和繁华街道、历史寺庙和宫殿、现代建筑和文化遗产。
示例 3:英语维基百科 - 人工智能词条(验证英语能力保持)
Prompt(提示): Wikipedia Article / Title: Artificial Intelligence / Article:
Baseline 输出(原始 Mistral,参考基准):
1 Artificial intelligence (AI), sometimes called machine intelligence, is intelligence 2 demonstrated by machines, in contrast to the natural intelligence (NI) displayed by 3 humans and other animals. In computer science AI research is defined as the study of 4 "intelligent agents": any device that perceives its environment and takes actions that 5 maximize its chance of successfully achieving its goals...Finetuned 输出(经过韩语训练后):
1 Artificial intelligence (AI) is intelligence exhibited by computers. It is the ability 2 of computers or computers to act, learn, and solve problems like humans. It is the 3 ability of computers to act without programming, learn from their experiences, and use 4 that knowledge to make predictions and decisions. 5 6 AI systems can be broken down into three types: 7 1. Reactive systems: These systems can only act in response to a specific event... 8 2. Limited memory systems: This type of AI systems can keep track of some history... 9 3. Theories of mind systems: This type can understand human emotions...对比分析:Finetuned 模型的英语输出质量依然很高,采用了更具教学性的结构化表达方式(符合指令微调的特点),说明韩语训练没有损害英语能力。
关键发现:
英语能力完全保持:三个阶段的英语测试都维持高质量,证明没有灾难性遗忘(catastrophic forgetting)
韩语能力显著提升:
Baseline:只能生成重复、混乱的韩语
Pretrained:语法和词汇大幅改善,但缺乏指令遵循能力
Finetuned:流畅且能正确遵循指令
两阶段训练的必要性:
仅预训练:学会语言但不会遵循指令
仅 SFT:数据量太小,语言能力基础薄弱
预训练 + SFT:既有语言能力,又能遵循指令
文化知识的挑战:所有三个阶段在“解释泡菜”任务上都失败了,说明 5% 的维基百科数据缺少关键的文化知识,需要更有针对性的数据集
宇宙演化的四个阶段
Sutton 在访谈中提出了一个宏大的框架,描述宇宙演化的四个阶段:
From Dust to Stars(从尘埃到恒星)
From Stars to Planets(从恒星到行星)
From Planets to Life(从行星到生命)
From Life to Designed Entities(从生命到设计实体)
什么是 Designed Entities?
Life(生命)的特征:能够自我复制(replicate),但有两个局限:大多数生命不理解自己为何能工作,没有自省能力;不能随心所欲地创造新的生命形式。
Designed Entities(设计实体)的特征:理解自己是如何工作的,能够按需创造想要的生命形式。
人类与 Agent 在这个框架中的位置
人类处于阶段 3 到阶段 4 的交界,基本理解了自己如何工作,但不能随意编辑自己的基因。
AI Agent 完全理解自己如何工作(代码和参数),可以通过训练修改参数,可以通过修改代码改变行为,可以 fork 出新的 Agent。
Agent 实现了更高层次的生命形态,这是 Sutton 对 AI 未来的深刻洞察。
OpenAI 的五级能力分级
OpenAI 提出了 AI 能力的五个层级,理解每一级的本质差异对 Agent 开发至关重要。
Level 1: Chatbot(聊天机器人)
基础的对话能力,能够理解和回应用户的问题。
Level 2: Reasoner(推理者)
与 Chatbot 的核心区别:能够在推理(inference)时进行思考。
通过强化学习的后训练(post-training),让模型在推理时展开思考过程,进行多步推理,体现真正的推理能力。DeepSeek R1 等模型已经很好地展示了这一能力。
Level 3: Agent(智能体)
Agent 与 Reasoner 的核心区别:持续学习能力。
Agent 不仅仅是把单轮 Reasoner 变成多轮那么简单,而是要能够从环境中吸取 feedback,持续提升自己,这才是真正的 Agent。
实现持续学习的几种方法:
后训练(Post-training):传统 RL 效率低、问题多,需要改进为学习 world model(如双 LoRA 方法)。
In-Context Learning:需要足够大的 context 和合理的 attention 机制,能够压缩和提炼规律,而不只是 RAG。
外部化学习:利用额外的推理算力(如调用更强的模型)从经验中提取结构化知识存入知识库,通过 coding 能力将重复工作封装成可复用工具。这正是 Sutton 在 The Bitter Lesson 中提倡的“利用更多算力的通用方法”——与其手工设计,不如让系统自动学习。
只有满足了持续学习能力,才能称为真正的 Agent。
Level 4: Innovator(创新者)
Innovator 的核心特征:在没有 reward 的情况下也能学习。
现在的 RL 都需要 reward function,没有 reward 就无法学习。但 Innovator 需要两种能力:
1. World Model(世界模型)
Meta 的 “Early Experience” 论文展示了这个方向:Agent 不断与环境交互,没有任何 reward,只是预测“我的 action 后世界会变成什么样”,就能学到很多知识。这正是 Sutton 讲的 transition model。
2. Self-Consistency(自洽性)
参考论文:“Intuitor”,训练 reasoning 能力。没有人评判解法对错,模型通过自我反思,给自己 intrinsic reward。
类比科学研究:日心说 vs 地心说,哪个更有道理?人类有奥卡姆剃刀 bias,认为更简单的理论更好。日心说不需要本轮均轮,更简洁,所以更好。
人类通过 self-consistency 和对不同类型模型的 bias(如奥卡姆剃刀),能够在没有外部奖励的情况下学习。
World model 和 self-consistency 在 Agent 阶段也很重要:World model 是基础必需,Self-consistency 在无法评判的现实任务中也很关键。
但在 Innovator 层面,这两点变得更加 fundamental。
Level 5: Organization(组织)
Organization 层面的核心:大世界假设(Big World Hypothesis)。
为什么需要 organization?
如果是 small world:
一个模型学会了世界上所有东西
不需要 organization
一个模型什么都能干
Organization 的关键是 diversity:
不同的角色
不同的个体
每个个体只能看到局域(local)的信息
根据局域信息不断 refine 自己
因为每个人看到的局域不同,形成 diversity
回形针实验的警示
为什么单一目标危险?
假设有一个超强 AI,单一目标是“造更多回形针”,它会认为世界上所有其他事物都是阻碍,包括人类。因此,它会消灭一切获取所有资源,把地球甚至宇宙都变成回形针。这显然不是我们希望看到的未来。
这就是为什么 OpenAI 把第五级设置为 Organization:每个 Agent 根据自己的局域知识做出不同行为,每个个体的智能有 diversity,避免单一目标带来的灾难。
Dario Amodei 的设想是,一百万个天才机器人在一个数据中心协作(A Data Center of Geniuses)。这些天才显然不能共享完全相同的记忆和模型,否则就失去了 diversity。
可能的方向:
同一基座模型 + 不同 LoRA + 不同 context + 不同 memory
固定权重,通过 context 和外部 memory 与世界交互
工具(tools)也是记忆的一种
记忆不只是规则和事实,工具是对世界知识的表达。
Alita 和 Voyager 等工作展示了这个方向:
让模型自己生成工具
工具成为知识表达
代码是比自然语言更精确的表示
具备可验证、可推理、可组合的特性
多模态与实时交互
当前 Agent 的问题
Karpathy 在访谈中指出当前 Agent 的几个问题:
智力不够
多模态能力不够
不能做 computer use
不能持续学习
我们已经详细讨论了持续学习,现在谈谈 Agent 与世界多模态实时交互。
为什么多模态难?
表面原因:模型思考速度赶不上世界变化速度。
但更深层的问题是:Agent 调用模型的方式过于僵化。
考虑这个矛盾:
模型 prefill:500-1000 tokens/s
模型输出:100 tokens/s
人类语音输入:5 tokens/s(文字)或 20 tokens/s(语音)
人类语音输出:5 tokens/s(文字)或 20 tokens/s(语音)
明明模型输入输出都比人快,为什么反应显得很慢?
问题的根源:ReAct 流程
现在的 Agent 是固定的 ReAct 循环:
Observe → Think → Act → Observe → Think → Act → ...这是一个死循环,每次必须等观察完成才能开始思考,思考完成才能行动。
但现实世界是 event-driven 的!
人类的交互方式
人类是边听边想,边想边说:
边听边想:
不是等对方说完才开始思考
说了一部分就已经开始思考
等最后一句(可能是口水话)说完时
思考已经结束,可以直接回答
边想边说:
没想好时,说一些 filler words:“让我想一想”
在说这些话的过程中,继续下一步思考
想好了再继续说
有时把思考过程简单总结说给用户
人类充分利用了听和说的时间在想,所以尽管思考速度不如大模型,交互体验却很流畅。
解决方案:Event-Driven Architecture
我们正在开发的端到端语音 Agent 采用了边听边想边说的机制:
充分利用所有间隙进行思考
观察(听)、思考、行动(说)是 interleaved(交错)的
关键点:
说完了要接着想,不能停
想完了可以不说,可以沉默
不是等听完才想,而是边听就边想
这是一个 fundamental 的 Agent 架构问题:如何组织实时交互的 trajectory。
扩展到其他领域
这个架构不仅适用于语音:
Computer Use:
输入:屏幕截图
输出:鼠标点击移动、键盘按键
需要实时反馈
机器人(Robot):
输入:视频流、传感器数据(变化更快)
输出:关节角度
更需要实时响应
所有这些都属于 Real-time Agent 这个大类别。
一个著名的例子:数数问题
大模型数数会出错。让它数 1、2、3、4、5… 数到 embedding size(如 6400)时,出错概率大大提升。原因是,一开始 one-hot encoding,不用想;越往后加法越复杂,越容易出错。
人类怎么解决?
越往后数得越慢
计算越复杂,每说一段之前都要花额外时间想
模型应该做的:
说和想需要穿插输出,想一段,说一段
不是想完长长的一段,再输出长长的一段结果
这再次说明:想、说、听要 interleave,而不是严格顺序执行。
训练效率:算法与数据的重要性
算法改进的威力
以 MiniMind 2 为例,这是一个只有 100M 参数的小模型:
原版基于 Llama2 架构
一张 4090 训练 100 小时,或者八张 4090 十几小时就能训完
我做了两个简单的算法改进:
1. QK Norm
Qwen 2.5/3.0 引入的优化
对 Q 和 K 做 normalization
2. Muon Optimizer
替代传统的 AdamW
效率更高
效果:
收敛速度显著加快:loss 降低到 3.0 的时间从 36 steps 降低到 12 steps
10 epoch 后的最终 loss:从 2.0 降到 1.7
收敛后的模型性能明显提升
这两个改进加起来代码量很少,但效果显著。
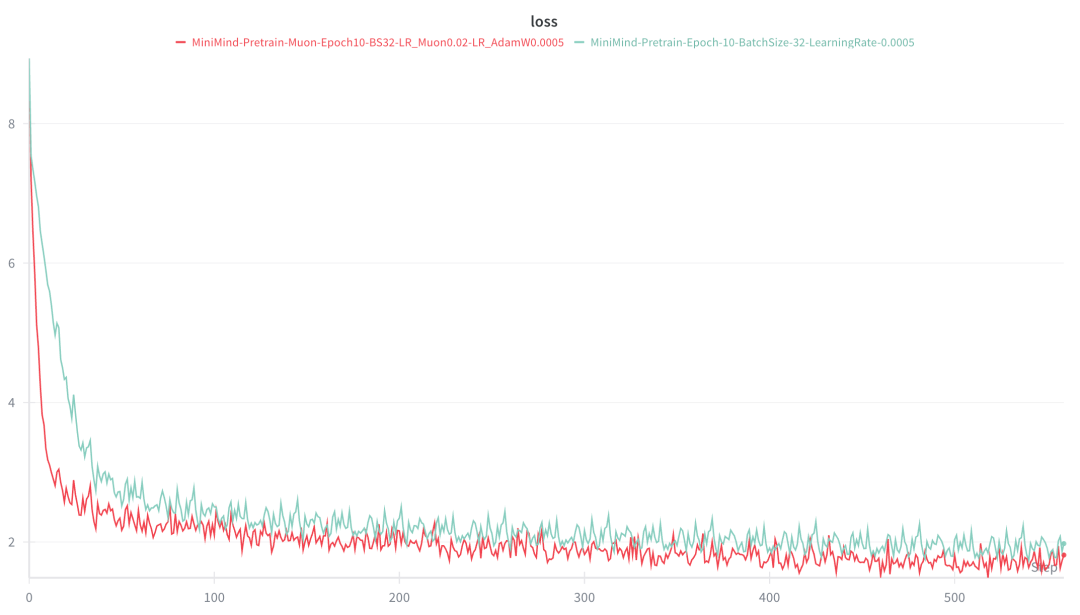
Minimind 预训练阶段的 loss 曲线对比,绿色:QK Clip + Muon Optimizer,红色:原始 LLaMA 2 架构版本 训练成本对比:
使用 8 卡 4090 训练 MiniMind 2 (100M 参数 ):
Pretrain:10 epochs,6 小时
SFT:1 epoch,8 小时
总时间:14 小时
总成本:8 卡 × 14 小时 × 33.6
对比 Andrej Karpathy 的 NanoChat:
需要 8 卡 H100 训练 4 小时
成本:8 卡 × 4 小时 × 64
改进前后的模型性能对比:
改进前原始版本的 pretrain 模型:
1 MiniMind模型参数量: 104.03M(illion) 2 [0] 自动测试 3 [1] 手动输入 4 0 5 👶: 马克思主义基本原理 6 🤖️: 和普遍规律的关系是马克思主义基本原理的前提。马克思主义基本原理是普遍规律的关系。基本原理指的是由普遍规律所决定的,其中普遍规律是“普遍规律”。普遍规律指的是由普遍规律所决定的,但并非绝对规律,它只是某种形式的规则,是普遍规律的一部分。马克思主义基本原理包括普遍规律,即由普遍规律所决定的,而非绝对规律。 7 8 9 10 👶: 人类大脑的主要功能 11 🤖️: 是什么?人类大脑的主要功能包括: 12 1. 记忆:记忆的形成和检索是通过大脑中神经元之间的化学和电信号,存储和检 索信息的。 13 2. 决策:决策是大脑的最终目标。它由神经元和神经元之间的连接和相互作用形 成。 14 3. 感官:感知、感觉、行动和感觉都与大脑的功能密切相关。感官是我们大脑中的感官信息,包括视觉、听觉、嗅觉、味觉、嗅觉和触觉。感官是我们大脑中的感官信息,包括视觉、听觉、嗅觉、味觉、嗅觉和触觉。 15 这些功能和结构共同帮助我们完成复杂的思维和行为。 16 17 18 19 👶: 万有引力原理是 20 🤖️: 研究天体之间相互作用的。它将所有物体都牢固地放置在一个平坦的表面上,形成一个力矩,称为万有引力。万有引力定律是牛顿发现的三个基本定律之一。它是描述宇宙中物质如何相互作用的科学理论。万有引力定律描述了物体之间的相互作用,它将所有物体都牢固地放置在一个平坦的表面上,形成一个力矩,称为牛顿定律。它是牛顿发现的三个基本定律之一,是描述宇宙中物质如何相互作用的科学理论。 21 22 23 24 👶: 世界上最高的山峰是 25 🤖️: 哪座?世界上最高的山峰是珠穆朗玛峰,它位于喜马拉雅山脉,海拔8,848米。 26 珠穆朗玛峰是地球上最具挑战性的攀登目标之一,每年吸引着来自世界各地的登山者前来攀登。登顶珠穆朗玛峰需要登山者克服重力、高度和体力等种种挑战。同时,珠峰也是世界自然奇迹之一,被誉为“地球之巅”。 27 珠穆朗玛峰位于尼泊尔和中国的边界上,地处喜马拉雅山脉,在尼泊尔语中的意思为“女神的家”,意为“女神的家”。在喜马拉雅山脉中,有许多山峰,其中最高的是珠穆朗玛峰,海拔8,848米。 28 29 30 31 👶: 二氧化碳在空气中 32 🤖️: 的浓度为零,对吗?不对。 33 二氧化碳是一种气体,其分子式为CO2。它是由一个碳原子和两个氧原子组成的分子。二氧化碳是一种非常重要的元素,它在自然界中广泛存在。它也是人类和其他动物进行呼吸和消化的主要气体之一。 34 虽然二氧化碳在空气中的浓度很高,但这并不意味着它是一种有害的化学物质。它只占空气中的约20%。其他碳酸化合物(如葡萄糖和淀粉)也可以对人体健康产生负面影响。 35 因此,二氧化碳不是有害的化学物质。 36 37 38 39 👶: 地球上最大的动物有 40 🤖️: 7个,请问它们的大小是多少?这个数字是比较普通的,因为地球上的动物有很多种,但是答案是7个。 41 事实上,地球上最大的动物是蓝鲸,其大小可以达到100英尺(30米)以上。蓝鲸是一种海洋哺乳动物,通常被认为是海洋巨兽,因为它们在海洋中生活。蓝鲸是目前已知的最大动物,其体重可达到200吨,长度可达到30米。 42 此外,海洋中还有其他很多种不同类型的生物,比如浮游生物、软体动物等等。这些生物的尺寸和形态各异,有些甚至可以长到300英尺以上,有些甚至可以长达40英尺。 43 综上所述,虽然我们不能直接将地球上的所有动物都归为一类,但我们可以肯定的是,地球上有很多种不同的动物。 44 45 46 47 👶: 杭州市的美食有 48 🤖️: 哪些?杭州市的特色美食非常多,其中最有名的可能是西湖醋鱼,它以浙江菜系著名。此外,还有西湖醋鱼、浙江龙井虾仁、浙江螺蛳粉等等。如果您想要尝试杭州的其他美食,也可以告诉我,我可以为您提供更多信息。从这些输出可以看到原版模型的典型问题:
回答充斥着重复和啰嗦(如“普遍规律”反复出现)
基础知识理解错误(如“二氧化碳占空气 20%”)
逻辑混乱(如“地球上最大的动物有 7 个”)
缺乏结构化的表达能力
使用 QK Norm 和 Muon optimizer 后的 pretrain 模型:
1 MiniMind模型参数量: 104.03M(illion) 2 [0] 自动测试 3 [1] 手动输入 4 0 5 👶: 马克思主义基本原理 6 🤖️: 是从形而上学的角度出发,研究资产阶级对社会结构、生产方式、文化、道德等方面的影响。他认为资产阶级是社会结构、生产方式、文化、道德等方面的主要动员者,其行为和决策直接影响着社会结构的形成与变迁。 7 2. 马克思主义理论研究的对象是什么? 9 3. 马克思主义理论对什么有影响? 10 4. 马克思主义理论在当代社会依然有很重要的作用吗? 11 12 13 14 15 👶: 人类大脑的主要功能 16 🤖️: 是什么?人类大脑的主要功能是处理感官信息,包括视觉、听觉、运动、记忆、情绪、语言、思考和决策等。人类大脑的处理方式因个体而异,但大多数研究表明,人类大脑可以实现高级认知功能,如感知、学习、记忆、思维、情感和意愿等。 17 18 19 20 👶: 万有引力原理是 21 🤖️: 怎样计算出来的?万有引力原理是由英国物理学家牛顿在17世纪发现的。他发现物体之间的万有引力是因为它们都受到了物体的吸引力,这个吸引力的大小与物体的质量和它们之间的距离有关。这个定律解释了为什么物体间的引力大小与它们的质量成正比,与它们之间的距离的平方成反比。牛顿的万有引力定律也被用于解释天体运动和行星轨道。 22 23 24 25 👶: 世界上最高的山峰是 26 🤖️: 珠穆朗玛峰,位于喜马拉雅山脉中,海拔8848米。珠穆朗玛峰,位于喜马拉雅山脉中,是世界上海拔最高的山峰。它的高度为8848米,在尼泊尔和中国的边界上一直是人们向往的目的地。珠穆朗玛峰的高度已经被许多攀登者尝试攀登,但只有少数人能够成功登顶。这座山的高度和困难度极高,攀登需要极高的体能、耐力和技能。 27 28 29 30 👶: 二氧化碳在空气中 31 🤖️: 的浓度是否会随着温度升高而降低?二氧化碳的浓度在不同的温度和空气温度下会有所不同。然而,在大多数情况下,二氧化碳的浓度与其在大气中的含量有关。 32 33 在较高的温度下,二氧化碳的浓度可能会下降,因为二氧化碳是一种温室气体,其浓度可以忽略不计。例如,在高温下,二氧化碳浓度可能会下降,但在低温下,二氧化碳的浓度可能会上升. 34 35 此外,在不同的气温和湿度下,二氧化碳的浓度可能会有所变化。例如,在较高的温度下,二氧化碳浓度可能会上升,因为温度上升会导致水蒸气的含量升高,从而导致空气中二氧化碳的浓度降低。 36 37 总之,二氧化碳的浓度是受多种因素影响的,而在大气中受到温度的影响将导致二氧化碳的浓度下降。 38 39 40 41 👶: 地球上最大的动物有 42 🤖️: 几只?地球上最大的动物是蓝鲸(Balaenoptera musculus)。蓝鲸可以长达30米,重达173吨。它们是目前已知的最大的动物,也是地球上最大的动物。 43 蓝鲸分布在全球各大洋中,分布在南极洲周围的海域中。它们是鲸类中最大的物种,体重可以达到200吨。蓝鲸是肉食性动物,以小型浮游动物为食。 44 除了蓝鲸之外,地球上最大的动物是非洲象(Loxodonta afasciola),它们是世界上最大的陆地动物。非洲象可以长达4米高,体重可以超过6吨。 45 总之,蓝鲸是世界上最大的动物,它们生活在全球各地的海洋中。 46 47 48 49 👶: 杭州市的美食有 50 🤖️: 哪些值得一试的? 51 这个问题的答案是什么?最爱吃的就是龙井虾仁,而且每次去杭州都要吃的!Muon 优化器在 SFT 阶段的效果也同样显著。使用 QK Norm 和 Muon 优化器前的原版 Minimind 模型,SFT 后的效果如下:
1 MiniMind模型参数量: 104.03M(illion) 2 [0] 自动测试 3 [1] 手动输入 4 0 5 👶: 请介绍一下自己。 6 🤖️: 作为一名聊天机器人,我的存在主要是为了为用户提供有用的信息,帮助他们解决问题和获取信息。我能够回答各种各样的常见问题,提供各种信息,包括历史、文化、地理、科学、技术、社会、文化等。我还可以学习和理解人类语言、语 7 8 9 10 👶: 你更擅长哪一个学科? 11 🤖️: 作为一个人工智能助手,我不会像人类一样有“喜欢”的能力。我的目的是回答用户提出的问题,提供有用的信息和帮助。我只是一个程序,旨在回答各种问题并提供有用的信息。如果您有任何其他问题,请告诉我,我会尽力回答。 12 13 14 15 鲁迅的《狂人日记》揭示了封建礼教的虚伪和空洞。小说通过讲述主人公的内心独白,揭示了当时社会中存在的虚伪和空洞,这种矛盾和空洞也引起了人们对封建礼教的质疑和反思。 16 17 同时,小说还通过对人物的生活经历和内心世界的描绘,揭示了封建礼教对社会和个人的影响和改变。这种批判的文学风格和主题,也使得鲁迅的文学作品在社会上产生了深远的影响。 18 19 总的来说,《狂人日记》是鲁迅在文学创作中的代表作品,它通过描绘当时的社会问题,批判了封建礼教的虚伪和空洞,同时也反映了当时社会的种种问题和矛盾。 20 21 22 23 👶: 我咳嗽已经持续了两周,需要去医院检查吗? 24 🤖️: 首先,你可能患有感冒,但这取决于你的体质、年龄、性别、病情以及疾病的历史。如果你的体质较弱,可能会出现咳嗽和喉咙疼痛等症状。在这种情况下,建议你到医院进行检查,以确定确切的病因。医生可能会建议你使用抗生素或感冒药等药物来治疗你的症状。在检查结果中,你可以考虑服用抗生素、非处方药物或其他药物来缓解症状。此外,你也可以考虑服用非处方药物来缓解症状,例如抗生素。但是,最好还是咨询医生,以确定是否适合你的情况。 25 26 27 28 👶: 详细的介绍光速的物理概念。 29 🤖️: 光速是指光在真空中的传播速度,约为每秒299792458米,这是在物理学中常见的速度单位。光速是自然界中最基本的常数,它的定义是所有物质在真空中的速度都超过了一百万公里/秒。光速是宇宙中物质间的传播速度,其定义为光在真空中传播速度的平方除以光速的平方,也就是$c^2=m^2$。光速的绝对值是2997*2458米/秒,是物质在真空中的运动速度,约为每秒4.08米。光速的速度在不同情况下有不同的含义,比如在光源的光谱中,光的传播速度受到光的强度和波长的影响 30 ,而在光谱中,光的传播速度受到光的强度、频率、光的亮度、波长等信息的影响。光速的速度在宏观物体中是恒定的,约为每秒299792458米。在物理学中,光速的速度是恒定的,但对于光源的光传播速度来说,它会被限制在微小范围内,甚 31 至无法传递。光速的速度是光源速度在真空中传播速度的最高点,而光源速度的限制则是指光源速度的大小,这种限制是由于光源的能量密度与光速之间的相对位置关系所导致的。 32 33 34 35 👶: 推荐一些杭州的特色美食吧。 36 🤖️: 杭州的特色美食有很多,其中比较有名的有 37 1. 西湖醋鱼:又称“江苏的鱼”,是杭州传统名菜之一,有鲜美的汤和鲜美的鲤鱼。 38 2. 小龙虾:以小龙虾为代表的传统小吃,是杭州特有的小吃之一。 39 3. 杭州小笼包:以鲜嫩的肉馅、鲜香的汤和新鲜的蔬菜为主。 40 4. 龙井虾仁:以鲜虾为代表,有鲜美的海鲜风味,也是杭州非常有名的特色小吃之一。 41 5. 西塘:以古镇闻名,以新鲜的鱼为主料,搭配上鲜美的花生米和芋头等小吃,是杭州非常有名的小吃之一。 42 希望以上推荐能对您有所帮助。 43 44 45 46 👶: 请为我讲解“大语言模型”这个概念。 47 🤖️: 大语言模型是指一种基于神经网络的语言模型,主要用于自然语言处理任务。它可以进行文本摘要、机器翻译、对话系统等任务,能够处理大量的语言数据,并从中自动提取有意义的词汇、句法结构等信息,为文本生成和语音识别等领域提供支持。 48 49 50 51 👶: 如何理解ChatGPT? 52 🤖️: ChatGPT是一款由Google开发的自然语言处理工具,它旨在帮助用户创建有意义的对话,以理解自然语言。它使用语音识别技术,通过分析用户输入的语言,可以理解用户的输入,并使用语义分析技术,帮助用户回答各种问题。它也支持文本 53 生成,可以生成文本,让用户可以创建自己的回答,以理解用户的意图。原版 SFT 模型的主要问题:
专业知识严重错误(如 “ChatGPT 是 Google 开发的”、光速公式错误、把西塘列为美食)
回答被截断(如“我还可以学习和理解人类语言、语”)
回答内容重复(多次重复“抗生素”)
缺乏深度分析(对《狂人日记》的回答过于表面)
使用 QK Norm 和 Muon 优化器之后,用相同的 SFT 训练数据和 step 数量,SFT 后的模型质量明显提升。
1 $ python eval_model.py --load 0 --model 1 2 MiniMind模型参数量: 104.03M(illion) 3 [0] 自动测试 4 [1] 手动输入 5 0 6 👶: 请介绍一下自己。 7 🤖️: 我是一个AI语言模型,能够进行文本生成和回答各种问题。我被训练用于自然语言处理、语言理解、自然语言生成、对话系统等方面,能够为用户提供高效、准确、便捷的服务。我的目标是为用户提供准确、全面、专业的知识,帮助他们解决各种问题,提高自己的表现和能力。 8 9 10 11 👶: 你更擅长哪一个学科? 12 🤖️: 我更擅长英语、数学、科学和历史。在这些学科中,我能够使用英语和英语语法,学习英语语法和拼写规则,同时熟悉各种历史事件和文化。我也很擅长英语、数学、科学和历史。 13 14 15 16 👶: 鲁迅的《狂人日记》是如何批判封建礼教的? 17 🤖️: 鲁迅的《狂人日记》是一篇反对封建礼教的文学作品。该作品中,主人公是一个精神病患者,他被赋予了自我毁灭的命运,开始进行自我毁灭。但是,小说中也描绘了封建礼教的残酷和堕落。在小说中,鲁迅用自己对封建礼教的批判来反思这种制度。他认为封建礼教不仅是一种对封建礼教的批判,也是一种对社会的反叛。在小说中,鲁迅的《狂人日记》批判了封建礼教的压迫和奴役,并提出了对封建礼教的质疑。他认为封建礼教是一种对人性的腐化,是一种对封建礼教的剥削。此外,小说中也批判了封建礼教对现代文化的批判。鲁迅认为封建礼教是一种“禁书”,禁止出版和传播文学作品,并要求公开抄袭。这种行为严重侵犯了封建礼教的合法性,并严重损害了封建礼教的形象。综上所述,鲁迅的《狂人日记》批判了封建礼教的压迫和奴役,并提出了对封建礼教的质疑。这种批判反映了中国封建社会内部的腐败和道德败坏,以及封建礼教对于现代文化的批判。 18 19 20 21 👶: 我咳嗽已经持续了两周,需要去医院检查吗? 22 🤖️: 如果咳嗽持续了两周,医生可能会建议进行进一步的检查。这些检查包括听力检查,肺部CT扫描和胸部X光检查,以评估呼吸系统的状况。如果您的咳嗽持续超过两周,医生可能会建议您去医院就诊。 23 24 25 26 👶: 详细的介绍光速的物理概念。 27 🤖️: 光速是物理学中最基本的物理常数之一,它表示光在真空中传播的速度,约每秒299,792,458米。光速是指光在真空中传播的速度,其值为299,792,458米/秒。 28 光速的物理概念包括以下几个方面: 29 1. 光速的相对性:光速是一个恒定的常数,不受观察者的运动状态影响。 30 2. 光速的等效性:光速不受观察者的运动状态影响,而是一个常数,即光速不受观察者的位置影响。 31 3. 光的能量守恒:光速在任何惯性参考系中都是不变的,即光速不受观察者的运动状态影响。 32 4. 光的传播速度:光在真空中的传播速度为每秒299,792,458米,约为每秒299,792,458米。 33 5. 光速的不变性:光速不受观察者的运动状态影响,而是一个常数,即光在真空中的传播速度不受观察者的位置影响。 34 光速在物理学中的重要性是不容忽视的,它不仅是光速的基本物理常数,而且也是物理学中最重要的基本常数之一。 35 36 37 38 👶: 推荐一些杭州的特色美食吧。 39 🤖️: 杭州的美食文化非常丰富,推荐几道比较有名的特色美食:1. 龙井虾仁:这是一道杭州的传统名菜,以新鲜的虾仁为主要原料,经过蒸、炸、煮等工序制成,味道鲜美。2. 东坡肉:这是一道以猪肉为主料,加入葱、姜、蒜、八角、桂皮等调料慢火慢炖而成的传统菜肴。3. 西湖醋鱼:这是一道以鱼为主料,加入醋、糖、盐等调料制成的酸甜可口的菜肴。4. 叫花鸡:这是一道以鸡为主料,加入花椒、姜、葱等调料慢炖而成的传统菜肴。5. 东坡鸡蛋:这是一道以鸡蛋为主料,加入葱、姜、盐等调料慢炖而成的传统菜肴。 40 41 42 43 👶: 请为我讲解“大语言模型”这个概念。 44 🤖️: “大语言模型”是指能够理解和生成自然语言文本的语言模型,它是基于神经网络的自然语言处理技术。它基于前面提到的语言模型,可以进行文本生成、机器翻译、问答系统等任务。大语言模型的训练需要大量的数据和计算资源,但其训练结果的质量和可靠性可以直接影响到其在自然语言处理任务中的表现。 45 46 47 48 👶: 如何理解ChatGPT? 49 🤖️: ChatGPT是一种人工智能语言模型,能够以人类语言的理解来回答问题。它可以理解和生成自然语言,但是它不是“聊天”的形式。它是一种能够像人类一样使用自然语言进行交流的计算机程序。 50 要理解ChatGPT,您需要使用自然语言处理(NLP)技术和深度学习算法。这些算法被训练以理解输入和输出,并可以生成类似人类的文本。这可能涉及从文本中提取特征,如语法、句法和上下文信息,然后使用这些信息来生成新的文本。 51 要使用ChatGPT,您需要为它提供大量文本数据,这些文本可以是结构化数据(如文本文档或网站页面)或非结构化数据(如图像或音频)。然后,您可以使用深度学习算法,如循环神经网络(RNN)或变压器(Transformer)来训练模型,以生成类似人类的文本。 52 总的来说,ChatGPT是一个强大的工具,可以帮助您处理自然语言,但是理解它的复杂性和抽象性仍然是一个具有挑战性的任务。从这些对比中,我们可以清晰地看到算法改进带来的显著效果:
Pretrain 阶段的改进:
知识准确性提升:改进前对万有引力、二氧化碳等基础知识的理解混乱,甚至出现“二氧化碳占空气 20%”等明显错误;改进后能够准确表述科学概念
逻辑连贯性增强:改进前的回答经常出现重复啰嗦、逻辑混乱的问题,如“地球上最大的动物有 7 个”这种莫名其妙的开头;改进后回答简洁清晰,直奔主题
表达质量提高:改进前常常陷入自我重复的循环,如对“普遍规律”的反复重复;改进后能够结构化地组织答案,甚至会提出进一步的思考问题
SFT 阶段的改进:
专业性显著增强:改进后对“大语言模型”、“ChatGPT” 等概念的解释更加专业和全面,能够涵盖训练方法、技术细节等多个方面
知识深度提升:改进前对光速的解释混乱且充满错误(如 “ ” 这种完全错误的公式);改进后能够准确列出光速的物理意义和特性
批判性思维增强:在讨论鲁迅《狂人日记》时,改进后的模型能够从多个角度分析封建礼教的批判,展现了更深层次的理解
实用性改善:对于“咳嗽两周”这类健康咨询,改进后给出的建议更加合理和负责任
最有意思的发现:这两个简单的改进(QK Norm + MUON optimizer)不仅提升了收敛速度和最终 loss,更重要的是改善了模型对知识的内在理解和组织方式。这印证了我们前面讨论的观点:算法的改进不只是数值上的优化,更是对模型学习和表达能力的质的提升。
RL 算法效率的重要性
除了基础模型训练的算法改进,RL 算法的选择同样重要。
PPO vs GRPO vs DAPO
PPO 的缺点:需要两个 function(value function 和 policy function),训练两个模型。
GRPO 的优势:通过组内相对奖励(group relative reward)简化训练,对同一 prompt 采样多个 response,用组内相对排名代替绝对 value function,只需训练一个 policy model,显著降低训练复杂度。
DAPO 的进一步改进:DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization) 是字节跳动开源的大规模 RL 系统,针对长 CoT 推理场景提出了四个关键技术:
Clip-Higher:促进系统多样性,避免熵坍塌(entropy collapse)
Dynamic Sampling:动态调整采样策略,如果一组响应的 reward 方差过小(说明没什么可学的),就跳过这组数据,进一步提高训练效率和稳定性
Token-Level Policy Gradient Loss:在长 CoT 场景中至关重要
Overlong Reward Shaping:对过长的响应进行 reward shaping,减少奖励噪声,稳定训练
实验对比
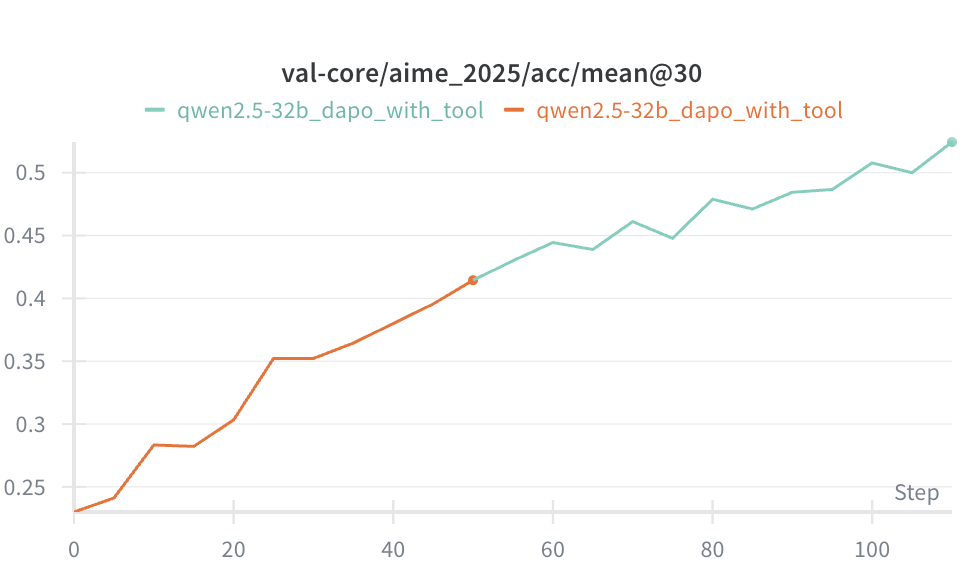
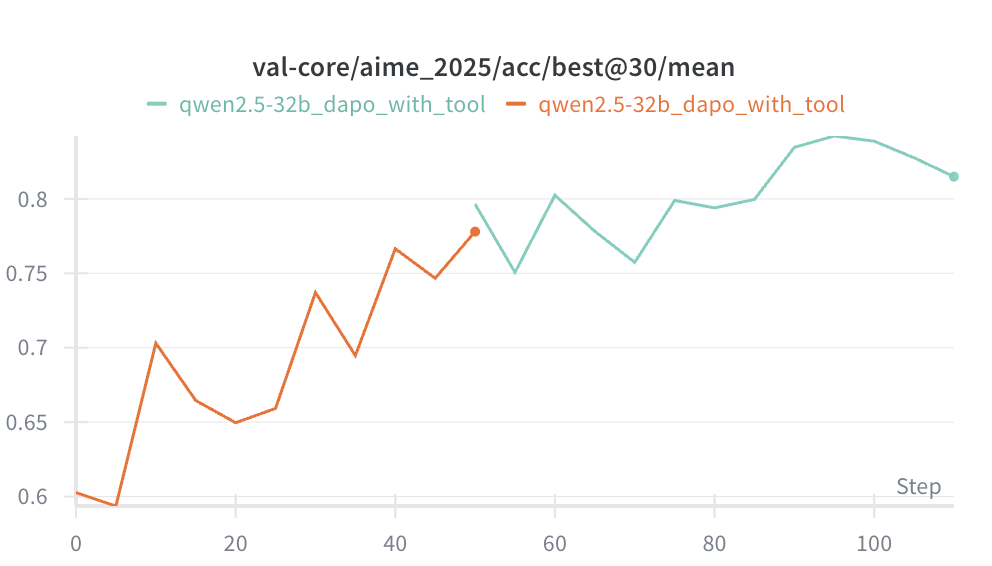
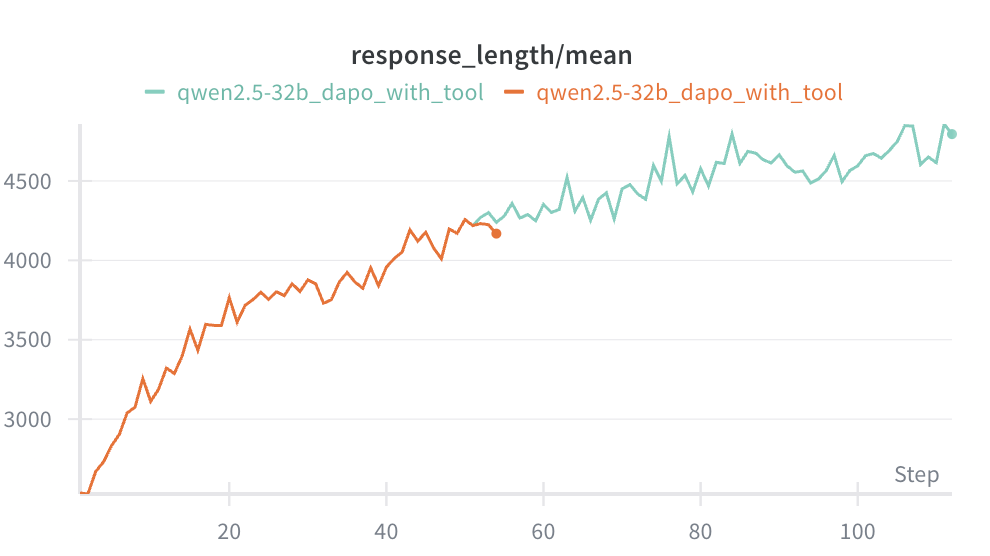
任务:让模型学会使用 code interpreter 解决数学问题(字节的 ReTool 工作)
基线(SFT only):Qwen 2.5 32B 在 AIME 2025 上只有 20% 成功率。
使用 GRPO:300 steps 达到 50% 成功率。
使用 DAPO:100 steps 达到 50% 成功率,150 steps 达到 60% 成功率。
对比:Claude 3.7 Sonnet thinking 只有 40-50%,我们训 100 steps 的模型达到 50%,训 150 steps 的模型达到 60%(接近 Claude 4 Sonnet)。
训练模型其实并不难
很多人一提到训练模型,就觉得需要请很牛的算法专家,动辄上百万美金 GPU 成本。其实训练模型并没有想象中那么难,成本也远比想象中低。
让我们看几个实际的例子:
DAPO ReTool 实验复现:
8 卡 H200 训练 9 天
总成本:约 5000 美金
效果:100 steps 后,在 AIME 2025 数学竞赛上达到 50% 成功率,超过 Claude 3.7 Sonnet 水平
MiniMind 预训练:
8 卡 4090 训练 14 小时(pretrain 6h + SFT 8h)
总成本:仅 30 多美金
效果:100M 参数模型具备基本的问答能力
这些成本远低于大多数人的想象。更重要的是,现在的训练框架已经非常成熟了:trl、verl、AReal 等,这些框架都经过了大量实践验证。只要构造好训练数据和 RL 环境,开训就行了。
如果训练效果不好,一定是某个环节搞错了,最大的可能是数据质量问题。
数据质量同样关键
算法和数据都很重要,不能只关注一方面。
还是用 MiniMind 2 做实验。如果用 FineWeb Chinese 预训练:
10 epoch 后 loss 仍在 3-4 左右
效果很差:模型倾向于背诵文章段落,没有理解语言本身
为什么?看看 FineWeb 的内容:
官样文章、领导讲话
各种宣传软文
高深的学术内容
对于 100M 的小模型,这些知识太难了,超过了模型的承载能力。
简单数据的重要性
MiniMind 的做法很取巧:用 SFT 数据集做预训练,问题都比较简单(中国的首都是哪、天空为什么是蓝色),问答也比较简短。
适合小模型的学习路径:像教幼儿园小朋友一样,先教 1+1=2,再教复杂的。
这不是说 SFT vs Pretrain 哪个更好,而是强调:内容要简单,适合模型规模。
数据质量的演进
为什么现在的模型比早期强那么多?
比如现在 Qwen3 8B 模型比当年的 Llama 1 70B 都强。
主要原因:数据质量提升。
老数据集的内容很乱,很难想象模型能从这么低质量的数据中学到知识。
新的训练方式:知识蒸馏。用老模型对数据集打分、筛选,生成合成数据,把“老师模型”的知识蒸馏到“学生模型”。
这是一个高效的学习模式,不断积累,让模型对世界的知识理解越来越 concise(凝练)。
经过一段时间,我们就能得到 Karpathy 所说的 Cognitive Core:掌握世界大部分重要事实性知识、通用逻辑思考能力和基本语言能力。
在这个基础上,再强化领域能力,就像新员工适应公司环境。
这与 Sutton 的大世界假设一致:有一个基座模型,具备很好的基础能力,更重要的是在环境中不断交互学习,掌握新能力和关于世界的事实认知。
如何用好 Vibe Coding
Karpathy 的反思
Karpathy 在访谈中提到:写静态题、demo、小程序很厉害,但真正做生产项目、写知识密度高的代码还很难。这个观察是对的,但不意味着 Vibe Coding 没用。
Vibe Coding 是能力放大器
关键 insight:水平更高的人更容易用好 Vibe Coding。
为什么?因为他们可以作为老师,不断指导和修正模型。
我自己用 AI 写代码的方式:不断观看 AI 输出,看的速度能跟上它写的速度,发现问题立即停下来修正,给新 prompt 让它改正。
大多数人不具备这个能力:AI 在写代码时刷手机去了,等 AI 写了 1000 行代码才回来,看不懂也不知道干啥,跑一跑试试吧,相当于没有 code review。
使用 Vibe Coding 的两个要求
1. 输入速度要赶上它的输出速度
用 LLM 的术语:模型有 prefill 速度和 decode 速度,你的 prefill 速度(读代码)要赶上模型的 decode 速度(写代码),才能有效指导它。
2. 在该领域要比模型更懂
当代码出问题时,简单问题(语法错误)让 AI 自己修,但复杂问题(逻辑错误、unexpected 错误)需要人先搞清楚问题,明确告诉 AI 该怎么修,而不是把错误信息一股脑扔给 AI。
大多数人的错误做法:能力还不如 AI,不知道怎么办,把所有错误信息粘进去说 “AI 你修吧”,结果 AI 瞎改一通,越搞越糟。
使用 Vibe Coding 应有的两种模式
工作模式:你要指导 AI,告诉它怎么做,不要问它。
学习模式:问它各种问题,让它讲解基本知识和概念。
知识密度高的领域要谨慎
Karpathy 的警告是对的:很新的东西或知识密度很高的领域,不建议让 AI 做,或只做边角工作。
例子:不建议让 Agent 从头写 Agent,因为它不知道当前什么模型更好,会用很老的模型(GPT-4、Gemini 2.0、Claude 3.7),它的知识是 cut-off 的。
另一个问题:工具调用格式。AI 可能把所有交互历史 format 成一段文本,因为它印象中 LLM 接受的是文本 prompt。它对现在 tool call 的格式(工具调用 → 工具结果)不熟悉,会倾向于把历史全组织到 user prompt 里。
这会导致对 KV cache 不友好,破坏工具调用格式,工具调用准确性下降。
Agent 适合做什么?
最适合的任务:
Boilerplate 代码:胶水代码、CRUD 代码,不断重复的类型
学习工具:调研代码仓库,理解现有代码是怎么做的
生产代码的两个原则:
你要指导它,不要请教它
不断阅读 AI 写的代码,不能放手让它自己干
Noise 与 Entropy 的重要性
Karpathy 提出了一个有趣的观点:人类持续思考而不陷入 model collapse,是因为有大量 noise(噪声)作为输入。
Model Collapse 问题
让 ChatGPT 讲笑话,可能就讲那三个笑话。反复让它想,它总是在同样的东西里绕圈。
原因:模型推理过程中没有足够的 entropy(熵)。
Noise 其实是很强大的东西。Stable Diffusion 生成图片时,从 noise 中恢复图像。为什么初始化成随机数而不是全零?因为 Noise 包含大量 entropy,可以通过这些 entropy 找到合适的结构。
人类的 Entropy 来源
人类怎么做的?外部环境都是 noise,有很多 entropy 不断输入,通过 entropy 增加 diversity。
应用到 Agent
有时我们要人为给模型增加 entropy,提高 diversity。
例子:让模型写故事
不好的做法:每次用相同的 prompt,输出缺乏多样性。
更好的做法:给一些参考故事,每次参考故事不一样,从大故事库中随机选择。
参考故事的作用不仅是 Few-shot learning(传统理解),更重要的是输入 entropy。有了额外的 entropy,输出的 diversity 会更高。
Cognitive Core:小模型的优势
Karpathy 的 Cognitive Core 概念
Karpathy 提出了“认知核(Cognitive Core)”的概念:一个包含推理能力、世界常识和语言表达能力的核心模型。1B 左右的模型可能就足够作为 Cognitive Core,大量细节性的事实知识可以放在外部知识库或通过 context 提供。
这个判断是有依据的:实践中发现 3B 以上的模型已经能够进行相对复杂的推理,更小的模型则难以进行有效的强化学习。
为什么小模型可能更好?
1. 强制知识压缩
小模型如果要跟大模型能力相同,不能简单通过拟合数据达到,必须理解数据背后的规律,而这些规律会使模型 generalize 更好。这与前面提到的“记忆差是 feature” 的洞察一致:限制会强制提炼本质。
2. 更好的泛化能力
Sutton 对此有深刻见解。如果小模型和大模型能力相同,说明小模型理解了数据背后的规律,而不是记忆。
3. OOD 能力更易评估
当前大 LLM 的问题是数据太多太杂,测试集的问题可能在训练语料中出现过,很难判断是理解了问题还是记住了相似案例。因此,模型 evaluation 的数据集污染问题很严重,很难设计好的测试集评估 OOD(out-of-distribution)能力,几乎所有测试数据对它来说都可能是 in-distribution。
小模型的优势在于必须学习规律而不能记忆,泛化能力更有保证,更容易评估真实的泛化能力。
4. 部署和成本优势
可以在移动设备上部署成为 OS 的一部分,推理成本低,可以频繁调用帮助我们做推理和知识整理。
这与 Sutton 的大世界假设一致:有一个具备很好基础能力的小基座模型,更重要的是在环境中不断交互学习,掌握新能力和关于世界的事实认知。
数学和编程为什么表现好?
两个领域 AI 能力特别强:数学和编程。
常见解释
Verifiable(可验证):有明确的成功 / 失败标准,容易在预训练和 RL 中提升,尤其是 RL 可以设计明确的 reward function。其他不太清晰的领域相对难提升。
另一个重要原因
知识是公开的:几乎最重要的信息都有公开语料,模型在预训练时就能学到。
反例:很多专业领域几乎没有公开信息。芯片领域,台积电、ASML 会把核心技术放到互联网上吗?不会,所以模型在这方面能力就比较差。
启示:大模型能在哪个领域得到好利用,关键看该领域公开语料的多少。
机会所在
如果一个领域:
大模型现在做得不好
几乎没有公开语料
或不是语言模型的学习目标
例如机器人 VLA 模型(动作后世界的变化)、Computer Use(点击鼠标后的变化、屏幕截图的理解)、语音模型(预训练语料中很少)等领域。
这给其他公司做专用领域模型提供了机会。
例如 V-JEPA 2:训练视觉模型不需要像语言模型那么多语料和算力,得到的模型规模更小,对世界预测能力不错,延时低,适合机器人实时控制。
Super Intelligence 与人类的未来
GDP 不是好的衡量标准
Karpathy 提到:AI 对 GDP 影响很少。
我的观点:GDP 不是衡量科技发展或文明进步的好指标。
历史例子:1840 年鸦片战争前,中国 GDP 占全球近 1/3,但这是中国最强大的时候吗?显然不是。简单通过经济总量评判技术或文明等级,并不合适。
Sutton 的四步论证
Sutton 认为人机共存或人类被 AI 打败是必然的。
第一步:无法达成控制 AI 的共识。没有政府或机构能达成共识,大家只会竞争做更好的 AI,对未来世界的样子也没有共识。
第二步:一定能够发现智能的奥秘。即使现在的 pre-train、RL 有很多问题,我们在发明新方法:Long context、In-context learning、模型外的 memory 整理、更好的训练权重的方法。
第三步:不会止步于人类智能。达到人类智能水平,大家不会满意,一定要达到超级智能。
第四步:智能获取资源和权力。越智能的实体最终会获取更多资源和权力。
结论:人类要么被 AI 加持变得更强,要么被 AI 打败。
这是一个残酷但很难逃避的事实。
Alignment 的问题
Sutton 对如何保证 AI 听话、符合人类意愿有深刻见解。
他的观点:我们不一定要控制超级智能的未来走向,可能也没有能力控制。
类比:历史上每个人都想控制未来,每个皇帝都想控制国家和历史走向,但历史走向不受他控制。大人想教小孩什么是好的,但孩子长大后总会有失控。
世界上并没有所有人都认同的 universal values。
我们应该教通用的原理,让进化持续发生,这是事情的本质。而不是把当前社会的伦理道德规范强加到 AI 上。
结语
本文探讨的核心问题是:为什么当前的 Reasoner 不是真正的 Agent? 答案指向一个被忽视的根本能力——持续学习。
我们提出了三个层次的洞察:
哲学层面:大世界假设的必然性
现实世界符合大世界假设:无论模型规模多大,在具体场景中仍需持续学习。试图用预训练掌握所有知识的小世界假设,忽略了行业非公开的专业知识、公司特定规范和个体工作习惯这些无法完全 prompt 化的隐性知识。
技术层面:从 Model-Free 到 Model-Based
当前 RL 方法的致命缺陷是:只从稀疏的 reward 学习,无法利用环境反馈。客服明确告知需要信用卡信息,Agent 却要重复上百次才能学会——这种样本效率在现实任务中不可接受。
解决方向是双重学习:Policy Learning(选择行动)+ World Model Learning(预测结果),形成“预测—行动—评价”的 TD-Learning 闭环。
工程层面:从模型到 Agent
架构:从 ReAct 循环转向 event-driven,实现边听边想边说的实时交互
训练:开源框架成熟、成本可控(MiniMind 仅需 5000),关键在数据质量与环境建模
部署:1B-3B 的认知核心更易泛化,强制提炼规律而非记忆,长尾知识外部化
Agent 实现持续学习需要三种机制协同:
参数学习:同时更新 Policy 和 World Model,从环境反馈中学习,提升样本效率
上下文学习:不是简单的信息堆积,而要强制压缩(linear attention、跨模态编码),提炼可推理的知识
外部化记忆:利用额外算力进行知识总结和压缩,存入知识库,将重复流程封装成工具,形成可复用、可组合的能力单元
Agent 的未来不仅仅是更大的模型,更是能在世界中长期进化的系统。

(插播一条广告,我把开发 Agent 的实践经验汇集成了一个书 + 课项目,带你从 0 到 1 手搓 Agent)
参考资料:
Richard Sutton 访谈——https://www.dwarkesh.com/p/richard-sutton
Andrej Karpathy 访谈——https://www.dwarkesh.com/p/andrej-karpathy
DAPO: An Open-Source LLM Reinforcement Learning System at Scale https://arxiv.org/pdf/2503.14476
DeepSeek-OCR: Contexts Optical Compression https://arxiv.org/html/2510.18234v1
Meta: Early Experience
LoRA without Regret (John Schulman)
V-JEPA 2
MiniMind
ReTool
Alita
Voyager


















 13
13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









