



总结几种观点:
首先说明现状
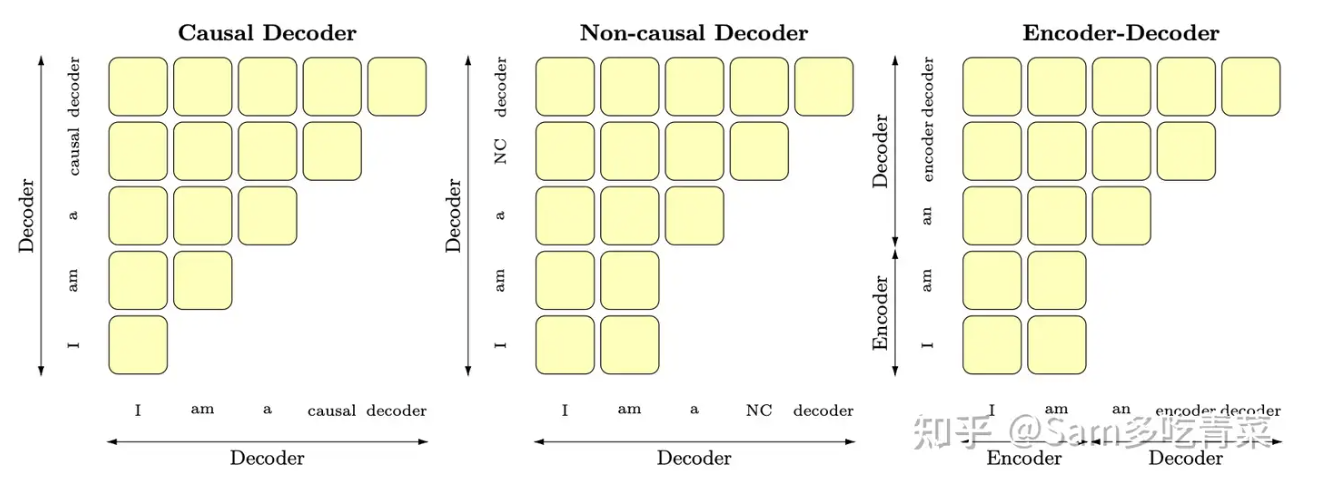
以BERT为代表的encoder-only、以T5和BART+为代表的encoder-decoder、以GPT为代表的decoder-only,还有以UNILM+为代表的PrefixLM(相比于GPT只改了attention mask+,前缀部分是双向,后面要生成的部分是单向的causal mask+),可以用这张图辅助记忆:
然后说明要比较的对象
首先淘汰掉BERT这种encoder-only,因为它用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调;相比之下decoder-only的模型用next token prediction预训练,兼顾理解和生成,在各种下游任务上的zero-shot和few-shot泛化性能都很好。我们需要讨论的是,为啥引入了一部分双向attention*的encoder-decoder和Prefix-LM没有被大部分大模型工作采用?(它们也能兼顾理解和生成,泛化性能也不错)
各种角度的思路
流水并行是千卡以上分布式训练中最重要的特性
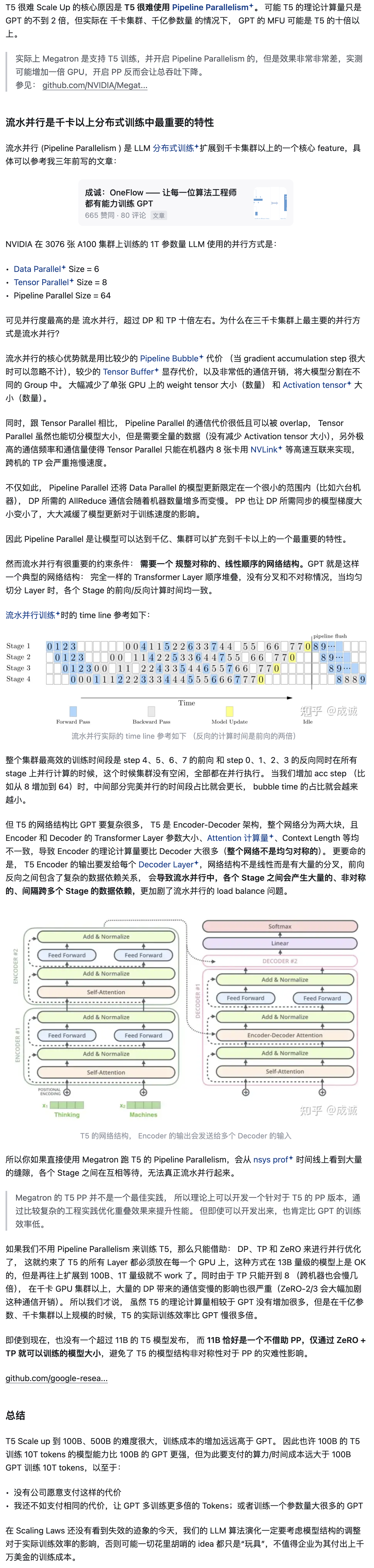
T5 的网络结构比 GPT 要复杂很多, T5 是 Encoder-Decoder 架构,整个网络分为两大块,且 Encoder 和 Decoder 的 Transformer Layer 参数大小、Attention 计算量、Context Length 等均不一致,导致 Encoder 的理论计算量要比 Decoder 大很多(整个网络不是均匀对称的)。 更要命的是, T5 Encoder 的输出要发给每个 Decoder Layer,网络结构不是线性而是有大量的分叉,前向反向之间包含了复杂的数据依赖关系, 会导致流水并行中,各个 Stage 之间会产生大量的、非对称的、间隔跨多个 Stage 的数据依赖,更加剧了流水并行的 load balance 问题。即使到现在,也没有一个超过 11B 的 T5 模型发布, 而 11B 恰好是一个不借助 PP,仅通过 ZeRO + TP 就可以训练的模型大小,避免了 T5 的模型结构非对称性对于 PP 的灾难性影响。
Decoder-only是满秩的
矩阵的秩(Rank of a matrix)是一个基本的线性代数概念,表示的是矩阵中行向量或列向量的最大线性无关组的大小。下三角矩阵的秩取决于其对角线元素,如果对角线上的所有元素都不为0,那么这个下三角矩阵是满秩的
Decoder-only架构的Attention矩阵是一个下三角阵,注意三角阵的行列式等于它对角线元素之积,由于softmax的存在,对角线必然都是正数,所以它的行列式必然是正数,即Decoder-only架构的Attention矩阵一定是满秩的!满秩意味着理论上有更强的表达能力。
节选自 @苏剑林 老师的博客 https://spaces.ac.cn/archives/9529
Causal Attention(就是decoder-only的单向attention)具有隐式的位置编码+功能
多位大佬强调了一个很容易被忽视的属性,causal attention(就是decoder-only的单向attention)具有隐式的位置编码+功能(Transformer Language Models without Positional Encodings Still LearnPositional Information),打破了transformer的位置不变性,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱,
Decoder only的架构泛化性能更好
ICML 22的What language modearchitecture and pretraining objective works best for zero-shot generalization?. 在最大5B参数量、170B token数据量的规模下做了一些列实验,发现用next token prediction预训练的decoderonly模型在各种下游任务上zero-shot泛化性能最好
附录:博客截屏
知乎Sam聊算法总结

转载自 https://www.zhihu.com/question/588325646/answer/3357252612?utm_campaign=shareopn&utm_medium=social&utm_psn=1857554106606026753&utm_source=wechat_session
流水线并行的难度
为什么现在的LLM都是Decoder-only的架构?
https://spaces.ac.cn/archives/9529




















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









