




准备工作
模型下载
相关链接
中文blog
Modelscope开源地址
Modelscope创空间体验
HuggingFace开源地址
HuggingFace Space体验
模型效果
官方数据

下载模型
本次实验在4090上进行测试,为了顺利加载模型,下载的是量化版本的模型。模型结构如下:

环境准备
conda activate qvq
pip install transformers
pip install qwen-vl-utils
pip install vllm
模型部署
部署代码
这里使用vllm进行部署,用到4张4090
CUDA_VISIBLE_DEVICES=4,5,6,7 python -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 8009 --max-model-len 12000 --model /model/QVQ-72B-Preview-AWQ --quantization awq --kv-cache-dtype fp8 --served-model-name qwenqvq --gpu-memory-utilization 0.95 --tensor-parallel-size 4 --enforce-eager --disable-log-requests --swap-space 16
成功加载模型

测试模型
标准测试代码
from openai import OpenAI
def get_test_report_qianwen(text):
openai_api_key = "EMPTY"
openai_api_base = "http://xxx.xxx.xxx.xxx:8009/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="qwen",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": text},
]
)
return chat_response.choices[0].message.content
调用测试代码
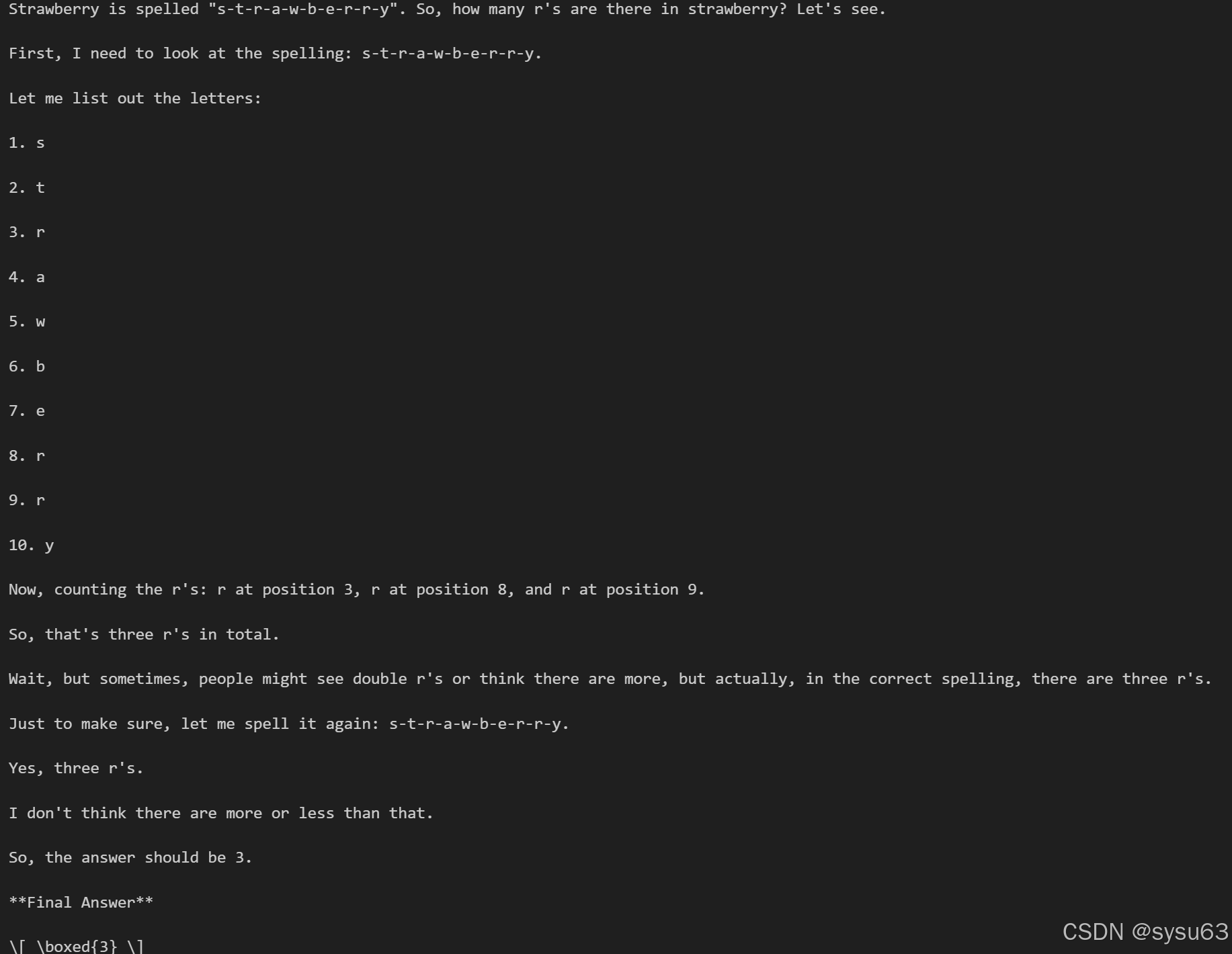
text = "How many r in strawberry"
print(get_test_report_qianwen(text))
模型输出,可以看到完整的思考过程



















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











