
深度学习
 关注
关注
 分享
分享
文章平均质量分 56
荪荪
这个作者很懒,什么都没留下…
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
BiSeNet_text_det表单文本框检测推理部分
【代码】BiSeNet_text_det表单文本框检测推理部分。原创 2025-07-22 09:28:23 · 141 阅读 · 0 评论 -
有关Pytorch代码中的学习率,你了解多少?
前言:在pytorch训练过程中可以通过下面这一句代码来打印当前学习率print(net.optimizer.state_dict()[‘param_groups’][0][‘lr’])1、如何动态调整学习率在使用pytorch进行模型训练时,经常需要随着训练的进行逐渐降低学习率,在pytorch中给出了非常方面的方法: 假设我们定义了一个优化器:import torch import torch.nn as nn optimizer = torch.optim(model.paramete原创 2021-11-16 10:12:21 · 716 阅读 · 0 评论 -
pytorch RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor)
报错:RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same分析原因:cpu和cdua 使用的不一致,比如说你的模型和输入,一个在cpu上,一个在cuda上,导致这样的错误。解决方法:net = Model(cfg).to(device)net.load_state_dict(torch.load(w2))中的device,看输入的img是在原创 2021-09-26 14:51:14 · 743 阅读 · 0 评论 -
TensorRT教程
本教程不适用于CUDA新手TensorRT简单介绍现在TRT出了dynamic shape,重新应用与语音领域,成功一半。(目前在腾讯)闭源部分就是官方提供的库,是TRT的核心部分;开源部分在github上,包含Parser(caffe, onnx)、sample和一些plugin。一、 如何选择TensorRT版本建议使用TensorRT6.0或者TensorRT7.1:(1)GA版本;(2)支持的cuda版本广泛TensorRT6.0支持的cuda版本广泛,cuda9.0,cuda10原创 2021-05-14 09:54:12 · 3335 阅读 · 3 评论 -
TensorRT+CUDA加速优化版CenterNet旋转目标以及水平目标框的检测
前言由于工作项目所需,一直用centerNet做旋转目标检测,在实际产品或者工业应用上落地此检测算法,那么在足够的算力下, 更好优选的方式还是需要c/c++来部署实现。那么CenterNet也带来一个问题,那就是部署不太容易,主要是两个方面:主流实现大多不好支持onnx导出;后处理与传统的检测算法不太一样,比如nms,CenterNet用的实际上是一个3x3的maxpooling。此处还涉及到一点就是,原版的centerNet并可以检测旋转目标,所以此处就涉及到一个角度问题。首选是将cent原创 2021-05-11 09:23:58 · 1582 阅读 · 1 评论 -
对ONNX模型进行BN和卷积层的融合
import onnximport osfrom onnx import optimizer# Preprocessing: load the model contains two transposes.# model_path = os.path.join('resources', 'two_transposes.onnx')# original_model = onnx.load(model_path)original_model = onnx.load("resne18.onnx")#原创 2021-05-07 11:26:03 · 2336 阅读 · 0 评论 -
Pytorch修改指定模块权重的方法,即 torch.Tensor.detach()和Tensor.requires_grad方法的用法
一、detach()那么这个函数有什么作用?假如A网络输出了一个Tensor类型的变量a, a要作为输入传入到B网络中,如果我想通过损失函数反向传播修改B网络的参数,但是不想修改A网络的参数,这个时候就可以使用detcah()方法a = A(input)a = a.detach()b = B(a)loss = criterion(b, target)loss.backward()以下代码就说明了反向传播到y就结束了,没有到达x,所以x的grad属性为Noneimport torch as原创 2021-05-07 11:03:21 · 2308 阅读 · 1 评论 -
并行及分布式框架 -- MPI/NCCL/OPENMP技术
初稿未完成摘要经典并行计算方案介绍。OPENMP技术详细介绍。MPI技术详细介绍。NV集合通信NCCL 技术介绍。MPIMPI(MPI是一个标准,有不同的具体实现,比如MPICH等)是多主机联网协作进行并行计算的工具,当然也可以用于单主机上多核/多CPU的并行计算,不过效率低。它能协调多台主机间的并行计算,因此并行规模上的可伸缩性很强,能在从个人电脑到世界TOP10的超级计算机上使用。缺点是使用进程间通信的方式协调并行计算,这导致并行效率较低、内存开销大、不直观、编程麻烦。OpenMP原创 2020-12-19 11:50:26 · 2276 阅读 · 1 评论 -
实时深度学习的推理加速
作者 Yanchen 毕业于普林斯顿大学机器学习方向,现就职于微软Redmond总部,从事大规模分布式机器学习和企业级AI研发工作。在该篇文章中,作者介绍了实时深度学习的推理加速和持续性训练。引言深度学习变革了许多计算机视觉和自然语言处理(NLP)领域内的任务,它为越来越多的消费者和工业产品提供更强大的智能,并潜在地影响了人们在日常经验和工业实践上的标准流程。从理论上来说,深度学习和其他基于统计机器学习方法的自动化系统十分类似,它们都可以采用两个过程描述。首先,深度神经网络(DNN)模型明确地指向为问题原创 2020-12-18 06:25:38 · 1116 阅读 · 0 评论 -
深度学习训练加速--分布式
一、内部方法网络结构的选择比如 CNN 与 RNN,前者更适合并行架构优化算法的改进:动量、自适应学习率减少参数规模比如使用 GRU 代替 LSTM参数初始化Batch Normalizationmini-batch 的调整二、外部方法GPU 加速数据并行模型并行混合数据并行与模型并行CPU 集群GPU 集群如下图所示(如借用的)这里重点讲解外部加速方法,旨在阐述训练大规模深度学习模型时的分布式计算思想:具体来讲:首先,介绍了分布式计算的基本概念,以及分布式计原创 2020-12-18 06:24:35 · 905 阅读 · 0 评论 -
深度学习模型压缩加速
前言智慧物流是“互联网+”高效物流的重要内容,以智能化技术使物流具有学习、感知、思考、决策等能力,深度学习被大量用于智慧物流。本课程主要分为3个模块:基于深度学习的智慧物流发展状况及应用深度学习模型压缩加速原理和方法深度学习移动端开源框架介绍及部署实例技能进阶:GitHub项目《深度学习500问》深度学习模型压缩加速原理和方法...原创 2020-11-19 14:47:01 · 1342 阅读 · 1 评论 -
移动平台模型裁剪与优化的技术
前言移动平台开发的基础原理与架构设计基础 AI 与移动平台开发核心学习路径掌握核心模型裁剪与优化的工程方法基于优化的TensorFlow Lite的落地案例移动端机器学习移动平台包含的范围移动电话平板电脑可穿戴设备智能手环、智能手环、智能眼镜、智能腰带嵌入式设备:树莓派边缘计算节点边缘计算基本概念在边缘测发起应用就近提供服务更快响应用户实时、智能、安全与隐私本质在本地完成计算而不交给云端处理确保处理稳定,降低云端的工作负载面临的挑战传输带宽硬件性能与原创 2020-11-16 15:41:27 · 854 阅读 · 0 评论 -
行业博文计划
设备巡检方案即app部署模型(安装)输电线路变电站智能管控平台(web端的实现)表计读数在端侧部署原创 2020-11-12 16:50:03 · 385 阅读 · 0 评论 -
深度学习高级主题--深度学习架构之飞桨框架的设计思想与二次开发
目录前言设计思想两种编程模式:静态图和动态图前言本章节主要介绍飞桨深度学习框架的底层设计思想,有了这些思想,或者底层运行逻辑的一些了解,这样使用飞桨更会得心应手,可以帮助用户理解飞桨框架的运作过程,以便于在实际业务需求中,更好地完成模型代码编写、调试以及基于飞桨进行二次开发。设计思想一、框架的运行模式飞桨的底层也就是PaddlePaddle的底层是怎么一个运行的逻辑呢?我们可以认为整个神经网络是一个Program。是什么含义呢?其实,要训练一个模型以及用这个模型去做预测,本质上来说,就是一段原创 2020-11-05 11:30:53 · 1427 阅读 · 1 评论 -
模型资源之二:各领域的开发套件
如果说PaddleHub提供的是AI任务快速运行方案(POC),飞桨的开发套件则是比PaddleHub提供“更丰富的模型调节”和“领域相关的配套工具”,开发者基于这些开发套件可以实现当前应用场景中的最优方案(State of the Art)。为什么这么说呢?经过前文我们已了解到,PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。但是在某些场景下,开发者不仅仅满足于快速运行,而是希望能在开原创 2020-11-04 09:19:18 · 503 阅读 · 0 评论 -
模型资源之三:模型库介绍
目录模型资源之三:模型库(完整源代码)计算机视觉(PaddleCV)自然语言处理(PaddleNLP)语音(PaddleSpeech)推荐系统(PaddleRec)从模型库中筛选自己需要的模型使用飞桨模型库或在其基础上二次研发的优势一个案例掌握Models的使用方法相关参考链接模型资源之三:模型库(完整源代码)飞桨官方模型库Paddle Models是由飞桨官方开发和维护的深度学习开源算法集合,包括代码、数据集和预训练模型。截至1.8版本,模型库发布了超过100个工业级的深度学习前沿算法和超过200个预原创 2020-11-04 08:54:43 · 2346 阅读 · 1 评论 -
模型资源之一:预训练模型应用工具 PaddleHub
目录PaddleHub使用预训练模型和Finetune的工具预训练模型的应用背景多任务学习与迁移学习自监督学习快速使用PaddleHub通过Python代码调用方式 使用PaddleHub通过命令行调用方式 使用PaddleHubPaddleHub提供的预训练模型使用自己的数据Fine-tune PaddleHub预训练模型PaddleHub使用预训练模型和Finetune的工具十行代码能干什么? 相信多数人的答案是可以写个“Hello world”,或者做个简易计算器,本章将告诉你另一个答案,还可以实原创 2020-11-04 06:17:45 · 1636 阅读 · 1 评论 -
深度学习高级主题--首场
目录一、为什么要精通深度学习的高级内容二、高级内容包含哪些武器1. 模型资源2. 设计思想与二次研发3. 工业部署4. 飞桨全流程研发工具5. 行业应用与项目案例三、飞桨开源组件使用场景概览1、 框架和全流程工具2、模型资源一、为什么要精通深度学习的高级内容在前面章节中,我们首先学习了神经网络模型的基本知识和使用飞桨编写深度学习模型的方法,再学习了计算机视觉、自然语言处理和推荐系统的模型实现方法。至此,读者完全可胜任各个领域的建模任务。但在人工智能的战场上取得胜利并不容易,我们还将面临如下挑战:需原创 2020-11-03 16:16:12 · 1344 阅读 · 0 评论 -
RCNN系列算法优化策略与工业质检案例
目录前言两阶段检测进阶模型介绍两阶段检测进阶模型优化策略工业应用:铝压件质检总结前言两阶段检测进阶模型介绍两阶段检测进阶模型优化策略工业应用:铝压件质检总结原创 2020-10-25 17:42:53 · 1181 阅读 · 0 评论 -
RCNN系列目标检测算法详解
目录前言一、两阶段检测算法发展历程R-CNN 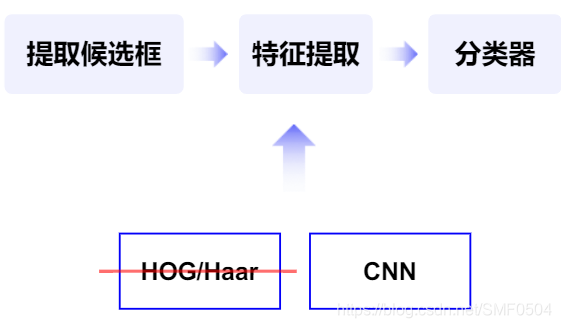Fast R-CNNFaster R-CNN原创 2020-10-25 17:09:24 · 2123 阅读 · 0 评论 -
YOLO系列目标检测算法详解
目录前言YOLO发展历程总结前言YOLO发展历程FPPS 帧每秒总结YOLO发展史YOLO(v1):首个单阶段目标检测深度学习模型,将目标检测当作一个单一的回归任务,基于锚框学习“形变”系数YOLOv2:全卷积网络结构、Kmeans聚类anchors,多尺度训练YOLOv3:新骨干网络DarkNet53,多尺度预测YOLOv3检测原理网络:输出特征图H,W维为网格锚框:9个锚框,每个尺度3个预测框:输出特征图C上为预测框信息,5+class_numPaddleD原创 2020-10-24 15:52:16 · 5601 阅读 · 1 评论 -
ubuntu 16.04 用户输入密码后循环重复登陆导致进不去桌面的方法以及tty的U盘挂载实现数据拷贝(英伟达显卡)
由于昨天我的服务器突然显示不显示了,几经排查,是显卡出了问题,谢天谢地,幸亏只是显卡问题,要是硬盘坏了,数据丢失,也真是一个大麻烦,之后就重新换了一个显卡,安装了一个1080ti显卡。总算进入了window系统。由于服务器是双系统,今儿进入ubuntu16.04系统,准备模型转换,悲剧又来了“用户输入密码后循环重复登陆导致进不去桌面”,想到昨天显卡问题,今儿应该就是显卡驱动的问题了吧,果不其然。下面就写写解决方案吧。步骤:在登陆界面按 ctrl+alt+f1进入tty控制台,输入用户名与密码。以下原创 2020-10-23 12:18:26 · 1100 阅读 · 0 评论 -
AnchorFree系列算法详解
目录Anchor-Based方法回顾Anchor Free系列方法简介PaddleDetection实战演练目标检测总结Anchor-Based方法回顾Anchor Free系列方法简介PaddleDetection实战演练目标检测总结原创 2020-10-23 00:04:12 · 21771 阅读 · 3 评论 -
YOLO系列优化策略与电力巡检案例
目录前言无人电力巡检低成本部署方案项目背景方案选择项目难点方案选择解决方案实际案例PP-YOLO优化深度解析YOLOv3及优化模型PP-YOLO深度解析PP-YOLO模型结构目标检测模型优化方法PP-YOLO精度提升历程-1YOLOv3-DarkNet53优化Image MixupLabel SmoothSynchronized Batch NormPP-YOLO精度提升历程-2ResNet-DDeformable ConvPP-YOLO精度提升历程-3Drop BlockExponential Movin原创 2020-10-21 16:48:10 · 3106 阅读 · 6 评论 -
ubuntu下使用conda安装pytorch最新版本
说明其实这个很简单,为啥还记录一下呢,主要也是遇到一些坑,用于以后或者其他朋友避免走这些坑吧在这之前,已经安装cuda10.2和cudnn7.6.5以及Anconada,同时进入默认是base环境下1.创建虚拟环境conda create -n pytorch_env python=3.7.0如图所示:2.激活虚拟环境conda activate pytorch_env输入以上命令之后,终端命令行前会出现(pytorch_env)字标,说明已经进入此环境下3.安装pytorchpi原创 2020-09-28 10:21:35 · 906 阅读 · 0 评论 -
window版本YOLO-Fastest从Darknet源码编译、测试
摘要此darknet版本包含yolov2,yolov4,yolo-fastest,后续添加其他一、准备工作环境:window10,cuda10.0. cudnn7.6, cmake.opencv3.4.0(opencv4.4.0也是一样的)源码:二、安装1、模型编译、测试和训练1.1、draknet编译1)打开cmake,选择Yolo-Fastest文件夹为source code路径,Yolo-Fastest文件夹为目标文件夹;然后点击configure,再选择opencv.exe解压缩后的原创 2020-09-16 17:09:24 · 1846 阅读 · 0 评论 -
yolov3代码函数解析yolo_eval()
代码:def yolo_eval(yolo_outputs, anchors, num_classes, image_shape, max_boxes=20, score_threshold=.6, iou_threshold=.5): """Evaluate YOLO model on given input and retu原创 2020-08-21 15:23:53 · 1533 阅读 · 0 评论 -
视频分析服务器安装
0. 前言 linux系统下安装,这里是ubuntu系统1. 安装显卡驱动sudo apt-get purge nvidia*sudo add-apt-repository ppa:graphics-drivers/ppasudo apt-get update sudo apt-get install nvidia-driver-430 nvidia-settingsreboot2.安装数据库mysqlsudo apt-get install libmysqlclient-devsu原创 2020-08-15 09:30:59 · 629 阅读 · 0 评论 -
Python PIL Image “OSError: image file is truncated (41 bytes not processed)“问题解决
前言:由于,最近项目所需,要一个pytorch版本的模型,用在服务器上,在调试pytorch1.2训练yolov4训练自己的数据报错,后续也将一一上传这个yolov4的代码,并讲解一下怎么训练自己的数据,现在在优化代码,优化之后,将上传分享给大家!问题:OSError: image file is truncated (41 bytes not processed)解决方法:在主文件里设置:from PIL import ImageFileImageFile.LOAD_TRUNCATED_IM原创 2020-08-05 16:37:29 · 1748 阅读 · 0 评论 -
window10下安装pytorch1.2.0+cuda10.0
前言:由于window10系统为了兼顾tensorflow2.0与tensorflow1.13.1,安装的是cuda10.0,cuda10.0支持pytorch1.2.0,不支持pytorch1.4以上的,所以就有了这篇文章。由于在线下载真的是超级超级慢,下载不下来,真是坑啊,所以就离线安装cuda10.0下的pytorch1.2.0了准备资料:pytorch1.2.0下载:torch+torchvision安装依赖库:pip install mkl cmake...原创 2020-07-29 19:39:17 · 3064 阅读 · 3 评论 -
ubuntu16.04安装Docker及NVIDIA Container Toolkit流程
一、ubuntu16.04安装Docker1.由于apt官方库里的docker版本可能比较旧,所以先卸载可能存在的旧版本$ sudo apt-get remove docker docker-engine docker-ce docker.io2.选择国内的云服务商,这里选择阿里云为例curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -3.安装所需依赖的包sudo原创 2020-05-14 08:37:47 · 2567 阅读 · 2 评论 -
Atlas 200 DK 系列 --高级篇--模型转换
一、模型转换工具的介绍与操作演示–模型转换OMG介绍Atlas200DK平台中提供了模型转换工具(OMG)。可以将caffe、Tensorflow等开源框架模型转换成Atlas200DK支持的模型,从而能够更方便快捷地把其他平台地模型放到Atlas200DK平台进行调试并拓展相关业务1)OMG的功能介绍2)OMG命令使用及命令参数解析3)Mind Studio模型转换实际操作4)OMG与...原创 2020-03-20 09:34:01 · 8445 阅读 · 3 评论 -
海思AI芯片(35xx):板端运行报错
问题,如下图所示:[Level]:Error,[Func]:SAMPLE_COMM_SVP_SysInit [Line]:41 [Info]:Error(0xa0018012):HI_MPI_VB_SetConf failed![Level]:Error,[Func]:SAMPLE_COMM_SVP_CheckSysInit [Line]:75 [Info]:Svp mpi init fail...原创 2020-03-12 15:28:15 · 3119 阅读 · 14 评论 -
海思AI芯片(35xx):linux下make交叉编译报错
linux下make编译报错如下图所示:问题1:/bin/sh: 1: syntax error: “(” unexpecd(或者/bin/sh: [[: not found 这种莫名奇妙的错误)原因分析:是linux将sh指向了dash而不是bash解决方法:在终端输入:ls -l /bin/sh # 提示如上图所示sudo dpkg -dpkg-reconfigure ...原创 2020-03-12 09:15:08 · 940 阅读 · 0 评论 -
海思AI芯片(35xx):yolov3的darknet模型转caffemodel模型
解决办法:加sudo权限:sudo python解决办法:sudo python3原因在于:原创 2020-03-11 09:09:10 · 1555 阅读 · 1 评论 -
ubuntu darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.
报错如上图所示0 CUDA Error: unknown errordarknet: ./src/cuda.c:36: check_error: Assertion `0’ failed.解决方法:加sudo权限:即加一个sudo【编译的时候,用的root权限的原因吧】...原创 2020-03-10 14:09:56 · 1571 阅读 · 1 评论 -
daknet版本yolov3训练报错:Corrupt JPEG data问题
解决思路:判断数据有问题,网上搜索,说是opencv读取图片有问题,改代码。我尝试重新制作其他数据集,读取训练没有这样的问题,说明这是我数据本身的问题。我就用python重新inread读取数据,然后将读取失败的图片数据名称保存下来,读取成功的数据再保存到对应的文件家中,最后就搞定了,废话少说了,就直接上代码吧。#!/usr/bin/env python# -*- coding: ut...原创 2020-03-02 13:10:54 · 3820 阅读 · 1 评论 -
ubuntu16.04下安装darknet(opencv3.2+cuda8.0)
一、安装相关依赖 1、cuda8.0+cudnn安装 2、opencv3.2安装二、下载darknet源码git clone https://github.com/pjreddie/darknetcd darknet三、修改Makefile文件gedit Makefile四、编译make五、测试1、下载预训练好的模型放到darkent目录下wget https:...原创 2020-01-16 15:17:06 · 1290 阅读 · 0 评论 -
caffe安装 Ubuntu16.04 cuda 8.0 cudnn 7.6.4
第一部分,准备材料(NVIDIA官网下载):显卡驱动àNVIDIA-Linux-x86_64-367.44.runCuda8.0àcuda_8.0.27_linux.run网址:https://developer.nvidia.com/cuda-downloadsCudnnàcudnn-7.0-linux-x64-v4.0-prod.tgz网址:https://developer.nv...原创 2020-01-02 15:35:08 · 711 阅读 · 0 评论 -
caffe深度模式的组成模块:Blobs,Layers,and Nets
1.blob(caffe中的数据操作基本单位)Blobs封装了运行时的数据信息,提供了CPU和GPU的同步。图片数据:Blob可以表示为(NCH*W)这样一个4D数组其中:N表示图片的数量;C表示图片的通道数;H和W分别表示图片的高度和宽度。在模型中设定的参数,也是用Blob来表示和运算。它的维度会根据参数的类型不同而不同。Blob是用以存储数据的4维数组,例如对于数据:Numbe...原创 2020-01-02 11:45:11 · 675 阅读 · 0 评论