




BERT: 用于语言理解的深度双向Transformer预训练模型
摘要
我们介绍了一种新的语言表示模型,名为BERT,全称为Bidirectional Encoder Representations from Transformers(双向Transformer编码表示)。与最近的语言表示模型(Peters等,2018a;Radford等,2018)不同,**BERT旨在通过在所有层中同时考虑左右上下文,从未标记文本中预训练深度双向表示。**因此,预训练好的BERT模型只需通过一个额外的输出层进行微调,即可创建适用于广泛任务的最先进模型,如问答和语言推理,而无需进行实质性的特定任务架构修改。
BERT在概念上简单且实证上强大。它在十一项自然语言处理任务上取得了新的最先进结果,包括将GLUE分数提升至80.5%(7.7个百分点的绝对提升),MultiNLI准确率提升至86.7%(4.6个百分点的绝对提升),SQuAD v1.1问答测试的F1分数提升至93.2(1.5点的绝对提升)以及SQuAD v2.0测试的F1分数提升至83.1(5.1点的绝对提升)。
1 引言
语言模型预训练已被证明能有效改进许多自然语言处理任务(Dai和Le,2015;Peters等,2018a;Radford等,2018;Howard和Ruder,2018)。这些任务包括句子级任务,如自然语言推理(Bowman等,2015;Williams等,2018)和释义(Dolan和Brockett,2005),这些任务旨在通过整体分析句子来预测句子间的关系;还包括词元级任务,如命名实体识别和问答,这些任务要求模型在词元级别产生细粒度输出(Tjong Kim Sang和De Meulder,2003;Rajpurkar等,2016)。
目前应用预训练语言表示到下游任务的策略有两种:基于特征的方法和微调方法。基于特征的方法,如ELMo(Peters等,2018a),使用包含预训练表示作为额外特征的特定任务架构。微调方法,如生成式预训练Transformer(OpenAI GPT)(Radford等,2018),引入最少的特定任务参数,并通过简单地微调所有预训练参数来训练下游任务。这两种方法在预训练期间共享相同的目标函数,即使用单向语言模型来学习通用语言表示。
我们认为当前技术限制了预训练表示的能力,尤其是对于微调方法而言。主要限制在于标准语言模型是单向的,这限制了在预训练期间可使用的架构选择。例如,在OpenAI GPT中,作者使用了从左到右的架构,即每个词元在Transformer的自注意力层中只能关注前面的词元(Vaswani等,2017)。这种限制对于句子级任务而言是次优的,并且在将基于微调的方法应用于词元级任务(如问答)时可能非常有害,因为在这些任务中,融合两个方向的上下文至关重要。
在本文中,我们通过提出BERT:来自变压器的双向编码器表示来改进基于微调的方法。BERT通过使用受完形填空任务启发的“掩码语言模型”(MLM)预训练目标减轻了前面提到的单向性约束(Taylor, 1953)。掩码语言模型随机屏蔽输入中的一些标记,其目标是仅根据其上下文预测被屏蔽词的原始词汇表id。与左右语言模型预训练不同,MLM目标使表示能够融合左右上下文,这允许我们预训练深度双向transformer。除了掩码语言模型之外,我们还使用了“下一个句子预测”任务来联合预训练文本对表示。本文的贡献如下:
在本文中,我们通过提出BERT(双向Transformer编码表示)改进了基于微调的方法。BERT通过使用受完形填空任务(Taylor,1953)启发的**“掩码语言模型”(MLM)**预训练目标,解除了前述的单向性约束。掩码语言模型随机掩盖输入中的一些词元,其目标是仅基于上下文预测被掩盖词的原始词汇ID。与从左到右的语言模型预训练不同,MLM目标使表示能够融合左右上下文,这使我们能够预训练深度双向Transformer。除掩码语言模型外,我们还使用"下一句预测"任务来联合预训练文本对表示。本文的贡献如下:
• 我们证明了双向预训练对语言表示的重要性。与Radford等(2018)使用单向语言模型进行预训练不同,**BERT使用掩码语言模型来实现预训练的深度双向表示。**这也与Peters等(2018a)形成对比,后者使用独立训练的从左到右和从右到左语言模型的浅层连接。
• 我们表明**预训练表示减少了对许多精心设计的特定任务架构的需求。**BERT是第一个在大量句子级和词元级任务上达到最先进性能的基于微调的表示模型,其表现优于许多特定任务架构。
• BERT提升了十一项NLP任务的最先进水平。代码和预训练模型可在 https://github.com/google-research/bert 获取。
2 相关工作
预训练通用语言表示有着悠久的历史,本节将简要回顾最广泛使用的方法。
2.1 无监督基于特征的方法
学习广泛适用的词表示几十年来一直是活跃的研究领域,包括非神经网络方法(Brown等,1992;Ando和Zhang,2005;Blitzer等,2006)和神经网络方法(Mikolov等,2013;Pennington等,2014)。预训练词嵌入是现代NLP系统不可或缺的部分,与从头开始学习的嵌入相比,它提供了显著的改进(Turian等,2010)。为了预训练词嵌入向量,研究人员使用了从左到右的语言建模目标(Mnih和Hinton,2009),以及区分左右上下文中正确词和错误词的目标(Mikolov等,2013)。
这些方法已经被扩展到更粗粒度的应用,如句子嵌入(Kiros等,2015;Logeswaran和Lee,2018)或段落嵌入(Le和Mikolov,2014)。为了训练句子表示,先前的研究采用了各种目标,包括对候选下一句进行排序(Jernite等,2017;Logeswaran和Lee,2018),基于前一句表示从左到右生成下一句的词(Kiros等,2015),或基于去噪自编码器的目标(Hill等,2016)。
ELMo及其前身(Peters等,2017,2018a)沿着不同维度推广了传统词嵌入研究。它们从从左到右和从右到左的语言模型中提取上下文敏感特征。每个词元的上下文表示是从左到右和从右到左表示的连接。当将上下文词嵌入与现有的特定任务架构集成时,ELMo提升了几个主要NLP基准测试的最先进水平(Peters等,2018a),包括问答(Rajpurkar等,2016)、情感分析(Socher等,2013)和命名实体识别(Tjong Kim Sang和De Meulder,2003)。Melamud等(2016)提出通过预测单个词的任务来学习上下文表示,该任务使用LSTM从左右上下文预测单词。与ELMo类似,他们的模型是基于特征的,而非深度双向的。Fedus等(2018)表明,完形填空任务可用于提高文本生成模型的鲁棒性。
2.2 无监督微调方法
与基于特征的方法一样,该方向的最早工作仅从未标记文本中预训练词嵌入参数(Collobert和Weston,2008)。
更近期,产生上下文词元表示的句子或文档编码器已从未标记文本中预训练,并为监督下游任务进行微调(Dai和Le,2015;Howard和Ruder,2018;Radford等,2018)。这些方法的优势在于只需从头学习很少的参数。至少部分由于这一优势,OpenAI GPT(Radford等,2018)在GLUE基准(Wang等,2018a)的许多句子级任务上取得了当时最先进的结果。从左到右的语言建模和自编码器目标已被用于预训练此类模型(Howard和Ruder,2018;Radford等,2018;Dai和Le,2015)。
2.3 从监督数据中进行迁移学习
研究还表明,从具有大型数据集的监督任务进行有效迁移的可能性,例如自然语言推理(Conneau等,2017)和机器翻译(McCann等,2017)。计算机视觉研究也证明了从大型预训练模型进行迁移学习的重要性,其中一个有效的方法是微调通过ImageNet预训练的模型(Deng等,2009;Yosinski等,2014)。
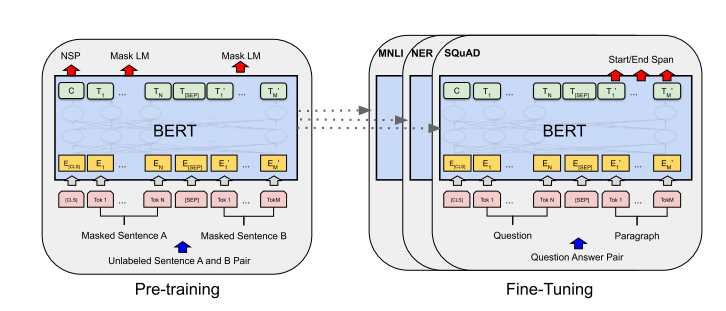
**图1:BERT的整体预训练和微调过程。**除了输出层外,在预训练和微调中使用相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,所有参数都会被微调。[CLS]是添加在每个输入示例前面的特殊符号,[SEP]是特殊的分隔符标记(例如,用于分隔问题/答案)。
3 BERT
我们在本节介绍BERT及其详细实现。我们的框架包含两个步骤:预训练和微调。**在预训练过程中,模型通过不同的预训练任务在未标记数据上进行训练。对于微调,BERT模型首先使用预训练参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。**每个下游任务都有单独的微调模型,尽管它们都使用相同的预训练参数进行初始化。图1中的问答示例将作为本节的持续示例。
BERT的一个显著特点是其跨不同任务的统一架构。预训练架构与最终下游架构之间的差异最小。
模型架构
BERT的模型架构是一个多层双向Transformer编码器,基于Vaswani等(2017)描述的原始实现,并在tensor2tensor库中发布。¹ 由于Transformer的使用已经变得普遍,且我们的实现与原始实现几乎相同,我们将省略模型架构的详尽背景描述,读者可参考Vaswani等(2017)以及"The Annotated Transformer"²等优秀指南。
[!NOTE]
结构
每一层 Transformer 编码器由以下模块组成:
多头自注意力机制(Multi-Head Self-Attention)
- 每个词元可以通过注意力机制关注序列中所有其他词元(双向自注意力)。
- 多个注意力头用于捕获不同的关系和上下文信息。
残差连接 + 层归一化(Residual Connection + Layer Normalization)
- 残差连接:将子层的输入直接加到其输出上,缓解梯度消失问题。
- 层归一化:对每个词元的特征进行标准化,提升训练稳定性。
前馈网络 (Feed-Forward Network, FFN)
- 包括两个全连接层:
- 第一层扩展隐藏层维度为 4×hidden_size4 \times hidden\_size4×hidden_size。
- 第二层将维度还原为 hidden_sizehidden\_sizehidden_size。
- 激活函数通常使用 GELU(Gaussian Error Linear Unit)。
在本研究中,我们将层数(即Transformer块)表示为L,隐藏层大小为H,自注意力头数为A。³ 我们主要报告两种模型大小的结果:
- BERTBASE(L=12,H=768,A=12,总参数=110M)
- BERTLARGE(L=24,H=1024,A=16,总参数=340M)
选择BERTBASE与OpenAI GPT具有相同的模型大小是为了比较目的。然而,关键区别在于BERT Transformer使用双向自注意力,而GPT Transformer使用有约束的自注意力,即每个词元只能关注其左侧的上下文。⁴
[!IMPORTANT]
网络结构上可以参考上一个文章。双向注意力还是单向注意力使用掩码实现。
[!NOTE]
双向自注意力与受约束的自注意力
- 限制的单向多头注意力
- 单向注意力限制每个词元只能关注其 左侧的上下文(前文)。
- 每个词元无法访问其 右侧的上下文(后文),以避免信息泄漏。
- 这种机制特别适合文本生成任务,例如 GPT,生成当前词时不能提前看到后续词。
实现步骤
- 输入序列:
["I", "love", "coding"]- 每个词元 ( Q ) 的查询向量只能与其 左侧词元的键向量 ( K ) 计算相关性。
- 通过注意力掩码(Mask)屏蔽掉右侧的词元,使右侧的注意力分数为负无穷(在 softmax 中归一化为 0)。
计算示例
假设输入序列长度为 3,注意力分数矩阵 ( QK^T ) 为:
[q1⋅k1q1⋅k2q1⋅k3q2⋅k1q2⋅k2q2⋅k3q3⋅k1q3⋅k2q3⋅k3] \begin{bmatrix} q_1 \cdot k_1 & q_1 \cdot k_2 & q_1 \cdot k_3 \\ q_2 \cdot k_1 & q_2 \cdot k_2 & q_2 \cdot k_3 \\ q_3 \cdot k_1 & q_3 \cdot k_2 & q_3 \cdot k_3 \\ \end{bmatrix} q1⋅k1q2⋅k1q3⋅k1q1⋅k2q2⋅k2q3⋅k2q1⋅k3q2⋅k3q3⋅k3 添加掩码后:
[q1⋅k1−∞−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6342
6342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









