



基于混淆的印刷电路板未经授权操作与逆向工程保护框架
郭子慕,佛罗里达大学邸佳,阿肯色大学马克·M·德黑兰尼普尔和多梅尼克·福尔特,佛罗里达大学
印刷电路板(PCBs)是所有现代电子系统的基本必需品,但正日益面临克隆、过度生产、篡改和未经授权的操作 等威胁。目前大多数防御此类攻击的努力仅集中在芯片层面,导致在印刷电路板及其更高层次的抽象上存在防护 空白。本文中,我们提出了首个基于混淆的印刷电路板保护框架。该方法的核心是一种置换模块,通过密钥控制, 隐藏印刷电路板上芯片之间的芯片间连接。当应用正确密钥时,芯片之间的连接将被正确建立;否则,连接将被 错误地置换,导致印刷电路板/系统无法正常运行。我们提出一种基于Benes网络的置换网络,并将其添加到印刷 电路板上,该网络可方便地在复杂可编程逻辑器件或现场可编程门阵列中实现。基于此实现,我们从以下三个方 面分析了该方法的安全性:(i)攻击者暴力破解逆向工程印刷电路板的尝试;(ii)暴力破解猜测正确密钥的尝 试;(iii)各类攻击者实施的物理和后勤攻击。对12个参考设计的性能评估结果表明,暴力破解通常需要难以承 受的时间才能攻破该混淆机制。此外,我们还针对不同类别的攻击者,提供了防止逆向工程、未经授权的操作等 威胁的详细对策要求。
CCS概念: Security和隐私→嵌入式系统安全;板级混淆,知识产权保护,防止未经授权的操作,Benes网络
计算机协会参考格式: 郭子慕、邸佳、马克·M·德黑兰尼普尔和多梅尼克·福尔特。2017年。基于混淆的保护框架防止印刷电路板的未经 授权的操作和逆向工程。ACM电子系统设计自动化汇刊22,3,文章54(2017年4月),31页。DOI: http://dx.doi.org/10.1145/3035482
1. 引言
印刷电路板(PCBs)为电子组件和芯片之间的机械支撑和电气连接提供了基础。因此,它 们几乎被用于所有现代电子产品中,包括智能设备、个人计算机、家用电器、汽车、工业控制系统等。最近,针对印刷电路板的攻击以及相应对策的开发引起了越来越多的关注[Tehranipooretal. 2015]。现代印刷电路板是包含关键设计信息和知识产权(IP)的复杂 多层结构,但实际上缺乏保护。任何人都可以购买印刷电路板或包含印刷电路板的系统从市场上进行克隆、篡改和未经授权的操作。此外,印刷电路板设计、制造和装配的新兴 商业模式倾向于外包[Ghosh等 2014],,这进一步加剧了印刷电路板/系统盗版和篡改的 威胁。
克隆可由合法购买产品的最终用户或捕获军用系统的敌对方实施[Hartmann和 Steup 2013]。克隆的第一步是逆向工程印刷电路板/系统,即识别印刷电路板上的芯片及 其连接方式。已有大量先前研究表明,即使使用低成本的家庭解决方案,对印刷电路板进 行逆向工程(RE)也相对简单[Grand 2014]。通过X射线计算机断层扫描实现更昂贵但 自动化的逆向工程方法也是可行的[Asadizanjani 2015]。如今大多数系统均由商用现成 组件(COTS)构成,因此很容易复制该系统并作为正品在市场上销售。甚至iPhone也被 克隆,在一些国家市场上已有数千部假冒产品在售[Pacific 2011]。
过度生产是指合同代工厂利用详细的印刷电路板设计,生产出超过授权数量的印刷电 路板。这些印刷电路板可用于制造类似于克隆产品的假冒产品。无论是克隆还是过度生产, 产品知识产权所有者都会遭受巨大的利润损失。然而,克隆可能造成更大的危害。例如, 克隆产品若采用低质量芯片、篡改的电子组件和/或附加功能(新的走线和组件、隐藏过孔 等)[Ghosh等人 2014]可能会意外失效,从而损害知识产权所有者的声誉。在最坏的情 况下,此类产品甚至可能导致人员伤亡。篡改攻击还可用于获取系统中存储的机密数据或 绕过保护机制(例如数字版权管理[ODonnell2013;Fitzgerald 2005])。这些目标可以 通过直接窃听芯片间通信,或使用专用设备探测这些连接来实现。最后,未经授权的操作 意味着攻击者在未经许可的情况下使用或操纵设备。一些设备对此类行为的保护机制较弱。例如,智能手机在使用前需要输入密码解锁,但密码通常较短且容易被观察到。
针对这些攻击的对策有多种形式。Ravi等人[2004]将嵌入式系统上的攻击分为三类: 隐私攻击,包括窃听;完整性攻击,包括功耗/时序/电磁分析和故障注入;以及可用性攻击, 包括软件木马。Anderson和Kuhn[1998]提出了一种针对RSA公钥密码系统、数据加 密标准(DES)和分组密码的低成本攻击。Weingart[2000]列出了一系列针对篡改攻击的 应对方法。然而,这些防篡改技术仅关注如何防止攻击者在设备运行期间获取密钥信息, 但并未解决印刷电路板的逆向工程、克隆和过度生产问题。最近,Ghosh等人[2014]分 析了印刷电路板在木马攻击下的安全性,并讨论了印刷电路板的反向工程防护。然而,作 者并未展示任何关于印刷电路板实现的详细设计流程,也未对其性能进行量化。
Tehranipoor等人[2015]和Guin等人[2014]提出了一种针对假冒集成电路(IC)的全面分类和展示框架。“脱氧核糖核酸(DNA)标记”[Hayward和Meraglia 2011]由AppliedDNASciences公司开发,可将独特且不可克隆的植物DNA嵌入产品中。在特 定光照下,IC标记的荧光与供应链中的DNA配合使用,可用于识别正品芯片。Yang等人 [2015]提出了一种基于射频识别的方法,用于电子组件和系统的假冒检测。板上所有芯片 的标识(IDs)共同生成板卡ID。然而,这些技术仅关注检测板上的假冒芯片,而非印刷电 路板本身。
基于混淆的保护框架防止印刷电路板未经授权的操作 54:3
据我们所知,防止系统未经授权运行的研究非常有限,但可能对商业和军事应用中的 隐私保护产生重大影响。最广泛使用的策略依赖于软件/固件授权机制,这需要加密系统和 额外内存的支持[Simpson和Schaumont 2006]。然而,这些要求引入了进一步的安全 隐患,例如密钥信息提取和授权系统被绕过[Brijbasi 2003]。
在本文中,我们提出了首个板级混淆方法,旨在保护印刷电路板免受克隆、过度生产、 逆向工程和未经授权的操作。我们的主要贡献总结如下: (1)板级混淆:所提方案通过在可编程组件(例如微控制器单元(MCU)、数字信号处理器 (DSP)或现场可编程门阵列(FPGA))与非可编程组件之间添加一个置换模块,来混淆 它们之间的连接。该置换模块仅在提供正确密钥时才使印刷电路板(PCB)正常工作。由 于连接关系被隐藏,该PCB无法被逆向工程。此外,通过保留密钥,可以缓解PCB的克隆 和过度生产问题。最后,如果密钥仅提供给系统所有者/用户,则可以防止系统的未经授权 的操作。在所有情况下,密钥无需永久存储在PCB中,从而增强了对物理攻击的抵御能力。 (2)实现:我们研究了置换网络的不同实现,并确定Benes网络是最有前景的候选方案。研 究了两种配置场景。 (3)抵抗暴力破解攻击:我们建立了评估在不同场景下针对暴力破解攻击的混淆性能的指标: (1)应用全部可能的输入/输出组合;(2)向Benes网络应用随机密钥。对12个工业参考设计 的结果表明,在任一情况下均无法破解该混淆机制。比较这两种场景,密钥方法在平均情 况和最坏情况下所需时间更长。 (4)物理攻击与对策:针对我们的方法可能遭受的攻击,根据攻击者资源进行了研究和分类。 在对策方面,我们为不同应用提出了三个级别的安全要求。我们利用球栅阵列(BGA)封 装用于可编程组件和置换模块,并隐藏它们之间的连接,以防止硬件探测。我们讨论了将 一种新颖的板级物理不可克隆功能(PUF)与所提出的混淆方案结合,以提供额外的保护。
本文的其余部分组织如下。第2节介绍了混淆及其关键要素。在第2.1节中,介绍了印 刷电路板混淆的基本思想。详细的方案、实现方法以及性能评估指标在第3节和第4节中展 示。第5节提供并分类了潜在的攻击场景。针对这些攻击,在同一节中讨论了相应的对策和 安全要求级别。第6节展示了以多个印刷电路板为基准的混淆性能。最后,第7节包含未来 工作和结论。
2. 基于混淆的保护
本节对硬件混淆提供了更全面的描述。我们还讨论了芯片级混淆技术及其为何不适用于印刷电路板。
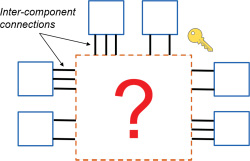
硬件混淆的总体思路如图1所示。实心矩形表示属于原始设计的组件。在芯片级别,这 些组件可以是逻辑门或寄存器。在板级,这些组件可以是电路板上的芯片。在原始设计中,这些组件通过固定的导线或走线直接连接。由于所有 组件间连接均已确定,因此无法对硬件功能进行控制。具备芯片级或板级逆向工程能力的 攻击者可以获取该设计。图1中的问号表示由混淆引入的隐秘性,这种隐秘性可防止简单的 逆向工程。这种隐秘性可以表现为互连置换、信号连接修改,或两者的组合。在硬件混淆 中,通常使用密钥来消除隐秘性,从而使设计能够按原始预期运行。
现有的芯片级方法利用混淆来隐藏功能,并旨在使芯片仅在授权权限下工作。广义上 讲,我们可以将芯片级技术分为两类:门级技术和寄存器传输级技术[查克拉博蒂和布尼 亚2009;Desai等 2013]。门级技术可能是基于逻辑混淆或基于置换的[拉杰德拉等2013; Roy等 2008]。
尽管上述技术非常适合芯片级保护,但芯片与印刷电路板之间存在根本性差异,使得 这些技术无法适用于印刷电路板。印刷电路板更容易被探测,且添加附加组件的成本更高。 用于加密和解密可编程组件与非可编程组件之间信号的加密模块很容易被移除。逻辑置换 方法[Zamanzadeh和Jahanian 2013]若不进行必要修改,则无法应用于板级,因为组件 与芯片之间的信号保持不变。
2.1. 所提出的PCB混淆概述
考虑到之前描述的系统级问题(过度生产、克隆和未经授权的操作),印刷电路板级混淆 是一种有趣的解决方案。通过混淆设计并withholding其密钥,可以缓解印刷电路板的克 隆和过度生产问题。即使系统上的商用现成芯片可以被识别,缺少密钥的情况下,混淆后 的系统仍然无法工作。此外,如果唯一密钥仅提供给系统所有者/用户,则未经授权的操作 也能得到防范。本节将讨论我们提出的混淆方案的一般硬件实现。
在实施混淆方案之前,我们针对每个应用将电路板上的组件分类为可编程和非可编程。 pro-grammable component是最关键的组件,负责嵌入式系统的主要功能。通常每块电路 板上至少有一个此类组件。该组件可以是MCU、DSP或FPGA。非可编程组件是指电路板上除可编程组件之外的其他 组件。这些组件通常由可编程组件控制,执行特定功能,例如定时器、显示驱动器等。
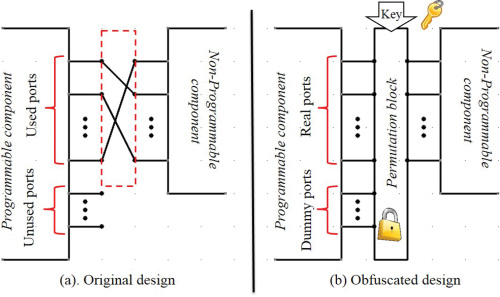
为了说明整体方法,图2(a)和(b)分别展示了原始设计和混淆设计。在原始设计中,虚 线矩形内组件之间的连接对设计者是已知的,拥有该系统的攻击者也可以通过逆向工程确 定这些连接。在混淆设计(所提出的方法)中,组件之间的连接被置换模块隐藏。具体而 言,我们插入一个permutation block,使设计者能够隐藏这些连接。置换模块是为实现混 淆而添加到电路板上的额外组件。该组件可通过复杂可编程逻辑器件(CPLD)、现场可编 程门阵列(FPGA)或专用集成电路(ASIC)实现。
在图2(b)中,由系统的可信用户输入密钥并配置置换模块,从而使系统正常工作。只 有正确密钥才能在可编程和非可编程组件之间建立正确的连接。该密钥可以通过多种方式 在板上或板外生成。板上密钥可从某些模拟信号(如生物特征:指纹、语音等)生成,以 实现更强的保护。系统可集成密钥提取模块,用于从这些模拟信号中提取密钥。板外密钥 可通过键盘输入或来自安全令牌(例如智能卡)。
图2还说明了我们可以利用的引脚/端口的一些其他重要特征/场景。真实端口表示可编 程组件中用于在原始设计(混淆前)连接非可编程组件的引脚。置换模块隐藏了组件之间 的这些连接。此外还有虚拟端口,它们代表原始设计中未使用的端口。在混淆设计(所提 出的方法)中,虚拟端口可用于增加攻击者需要搜索的状态空间。直观上,用作置换模块 输入的真实端口和虚拟端口的数量决定了攻击者必须研究的连接组合数量,以确定正确的 系统设计。
图2给出了所提出混淆实现的整体思路。所提出的PCB混淆的实现与评估包含三个部 分。 —端口选择框架:并非所有可编程组件的端口都可用于混淆。原因在第2.2节的功能性逆 向工程攻击中给出。本文提出了一个三阶段框架,用于选择适合进行混淆的端口。该框架 包括预处理阶段、分组阶段和度量计算阶段。 —混淆强度评估:提出了用于评估所提出混淆方案性能的定量指标。这些指标表明了攻击 者通过暴力破解手段破解混淆的概率。 —多密钥计算:我们研究了在置换模块中实现的置换网络的特性。分析了一种被称为多密 钥效应的现象。由于该现象影响破解概率,因此对混淆强度进行了重新评估和比较。
2.2. 对PCB混淆的攻击
本文中,我们考虑了针对PCB混淆的多种攻击。这些攻击中的任何一种都可能导致攻击者 能够解锁系统或克隆/过度生产系统,从而破坏所提出的方法的目的。因此,我们还将在后 续章节中讨论缓解这些攻击的方法。
(1)功能逆向工程:由于电路板上的组件都有详细文档,攻击者可以通过研究端口的功能部 分地发现正确的连接排列。尽管攻击者从可编程组件中获得的信息有限,但他们可以从非 可编程组件(特别是那些在可编程组件上具有专用端口的组件)了解连接的功能。因此, 应利用通用输入/输出(GPIOs)及其他具有设计特定功能的端口来抵御此类攻击。幸运的是, 许多印刷电路板包含微控制器(MCUs)、数字信号处理器(DSPs)和现场可编程门阵列 (FGPAs),这些器件包含大量通用输入输出端口(详见第6节)。在混淆中利用这些端口将 使攻击者极难通过暴力方式找出真实的互连关系。因此,我们应更加关注GPIOs。选择合适 端口用于混淆以及评估该方法性能的方案将在第4.1节中讨论。
(2)对正确连接和/或密钥的物理逆向工程:攻击者可以使用多种物理攻击来破解所提出的 混淆方案。例如,攻击者可能会尝试应用板级和芯片级逆向工程来获取正确的芯片间连接。 在板级,可以通过探测来识别进入和离开置换芯片的信号。通过这些信息,攻击者可以克 隆设计、进行过度生产等操作。或者,通过攻击置换芯片,攻击者可能能够提取出密钥。
(3)暴力破解攻击:如果上述攻击被成功防范,那么攻击者唯一的选择就是暴力破解搜索 (穷举搜索)。本文中存在两种可能的暴力破解方法:(i)连接组合和(ii)混淆芯片的密钥 输入。在第一种情况下,攻击者会测试所有可能的芯片间连接,以确定能够实现系统正确 运行的那一种连接。在第二种情况下,攻击者通过混淆模块接口测试所有可能的密钥输入, 直到系统正常工作为止。请注意,这种情况与第一种不同,因为它完全取决于置换网络的 实现方式(即密钥与输入/输出组合之间的关系)。在第4节中,我们将建立评估方法来估 算破解概率。
3. 置换网络实现
本节介绍了各种置换网络的背景,并选择了用于实现所提出混淆方案的最佳候选方案。根 据所选的置换网络,我们提供了不同场景下的配置方法。
3.1 置换网络介绍
在我们的保护方案中,选择合适的置换网络并将其在置换模块中实现起着至关重要的作用。 在我们的应用中,置换网络的输入是连接到可编程组件的信号,输出则连接到非可编程组 件。根据实现完全输入/输出置换的能力,置换网络可分为blocking和nonblocking网络[Waksman 1968]。
阻塞置换网络表示该网络只能实现部分输入/输出组合。蝶形网络[Thamarakuzhi和 Chandy 2010]以及基本 Omega网络[Mitra和Cieslak 1987]是阻塞置换网络的两个 示例。
非阻塞置换网络表示该网络能够实现所有输入/输出组合,无论是否存在约束。此类置换网络包含三个子类别。(i)严格意义无阻塞网络[Giacomazzi和Trecordi 1995]能够在存在 任意已建立路径的情况下,构建一条新的路径来连接未连接的输入和输出。(ii)广义无阻 塞网络[Feldman等人 1988]不提供像严格意义无阻塞网络那样的严格独立性保证,但仍 可通过特定算法将任何未使用的输入连接到任何未使用的输出。(iii)最弱的非阻塞置换 网络概念是可重排无阻塞网络[Pippenger 1978]。这类网络在没有事先知道输入和输出顺 序的情况下,无法完全实现所有网络配置。Benes网络[Chang和Melhem 1997]就是这 种网络的一个例子。
我们对三种置换网络进行了比较:Omega网络(阻塞型)、基于多路复用的网络(严 格无阻塞型)和Benes网络(可重排无阻塞型)。这些网络使用QuartusII软件进行综 合,并在AlteraMAXVCPLD上实现。目标CPLD包含570个逻辑单元(LEs),这是 CPLD中的基本逻辑单元。面积开销通过已使用逻辑单元的百分比来表示。结果表明, Benes网络使用的逻辑单元比例为60%,而基于多路复用的网络为115%。除了面积开销 外,还估算了功耗开销和传播延迟。这些开销是基于在MAXVCPLD上实现的32位 Benes网络进行估算的。功耗开销为0.04毫瓦,平均引脚到引脚延迟测量为20.5纳秒。
为了抵御暴力破解攻击的鲁棒性,所需的最小置换网络维度为32个输入和32个输出 (详见第6节)。我们决定在本文余下的部分中重点实现Benes网络作为置换模块,原因如 下:(i)显然,阻塞置换网络并不合适,因为它们产生的输入/输出组合有限。例如,一个 32位Omega网络提供1.2379E+ 27种输入/输出组合。而32个输入的完全打乱组合数为 32的阶乘,即2.6313E+ 35。因此,Omega网络仅实现了总计输入/输出组合中的 1/2.1256E+08。与阻塞网络相比,无阻塞网络(如Benes网络)能够实现所有可能的输入/ 输出组合。就本案例而言,设计者应从无阻塞网络中选择候选方案。(ii)考虑到硬件面积 开销,Benes网络远优于基于多路复用器的网络。对于此应用,严格意义无阻塞网络具有 显著的开销,而其优势在我们的使用场景中并不需要。
3.2. 置换网络配置
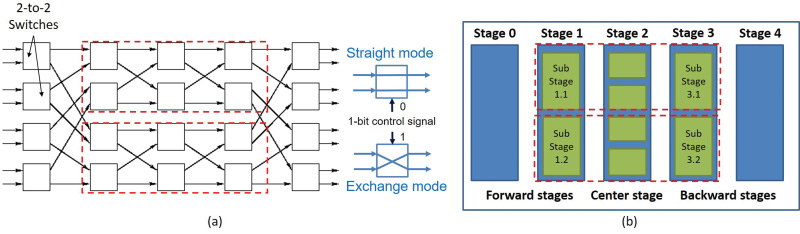
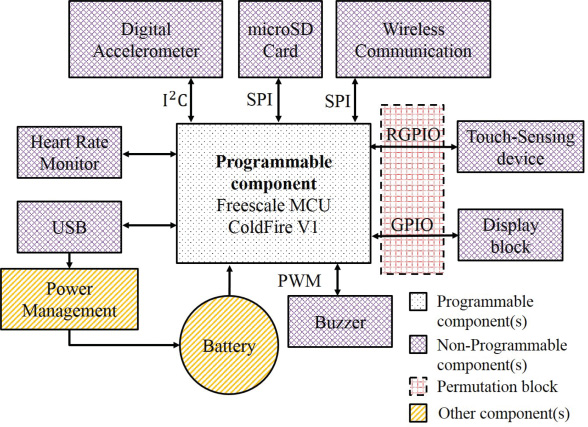
最基本的Benes网络单元是一个如图3(a)所示的1位控制的2到2开关。该开关在两种模式下 工作:当控制位为0时处于直通模式,当控制位为1时处于交换模式。混淆key中的位被用作 每个开关的控制位。我们将每一列开关定义为一级。Benes网络的对称性在配置过程中起 着关键作用。该性质意味着Benes网络在中心级上具有旋转对称性。根据此性质,中心级 左侧的级被称为前向级,右侧的级被称为后向级。这些级类别如图3(b)所示。设计者可以 利用这些性质来简化配置过程。
网络配置可以根据先验知识和目标分为两种情况。
情况1 :设计者旨在根据已知的输入顺序和预定义密钥来确定输出顺序。由于Benes网 络具有旋转对称性,它始终由奇数级组成。级数(S)可以通过以下方式求得
S= 2∗log2N−1,其中N是网络维度(即Benes网络的输入数量)。每一级都可以通过从 密钥导出的方形置换矩阵(PM)进行数学表示。置换矩阵每行/每列恰好有一个“1”,其 余为“0”。每个置换矩阵表示经过相应级的输入重排。置换矩阵的乘法表示连续通过多个 级的一致性操作。对称性特性有助于设计者简化置换矩阵的计算。在计算出置换矩阵和输 入顺序(I)后,我们可以将输出顺序(O)形式化如下:
O= I × ∏ i=1 log2 N−1 PM i , (1)
其中N表示输入数量。在已知输出顺序和密钥的情况下,可以采用相同的步骤来计算输入顺序。
情况2 :设计者的目标是找到一个或多个能够实现所需输入/输出置换的密钥。此过程 也称为网络路由。先前的研究,例如Nassimi和Sahni[1982]提出了一种高效的路由算法, 该算法基于搜索环路(下文定义)的外级。外级(OS)被定义为像图3(b)中第0阶段和第 4阶段这样的镜像阶段对。外层级数K根据输入数量N按如下方式定义:
K= log2 N −1. (2)
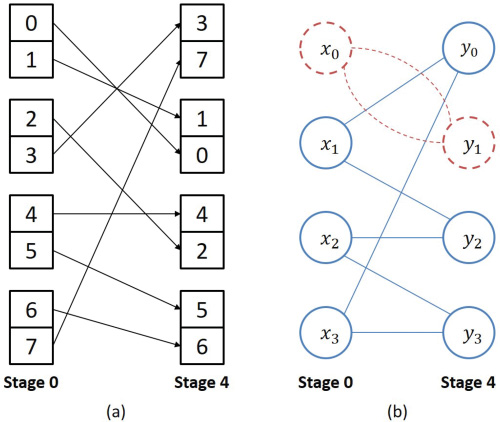
环路结构如图4所示。例如,假设网络输入为[0 1 2 3 4 5 6 7],输出为[3 7 1 0 4 2 5 6]。 为了确定环路,所提出的方法将每个开关表示为一个节点,标记为x0, y0,等,如图4(b)所 示。节点之间的连接基于输入/输出顺序构建。一个环路包含所有互连节点。在同一环路中, 通过它们之间的互连关系,一个节点可以到达任意其他节点(包括其自身)。如果两个节 点直接连接(例如,x1和y0)或间接连接(例如,x2和y0),则它们应被归入同一个环路。 例如,虚线环路由节点x0和y1组成。一个环路内的节点不应与该环路外的节点相连。除了由 第0阶段和第4阶段形式化的外层阶段之外,在图3(b)中的子阶段1.1和子阶段3.1等其他外级 中也可以发现类似的环路结构。配置可以通过为每个节点(开关)分配“0”或“1”来完 成。如Nassimi和Sahni[1982],所述,每个环路可以分配两种等效的密钥配置。这两种配 置是互补二进制链,例如“1011”和“0100”。
这种多配置现象可能导致多个密钥实现相同的输入/输出组合。在本文中,我们将此现象称为多密钥效应。这种效应可能通过增加破解概率(即通过穷举搜索获得正确配置的概率)而 削弱保护强度。
4. 混淆与评估方法论
在第2.1节中,介绍了基于置换的混淆的整体思路。如前所述,真实/虚拟端口由置换模块 进行置换。如第2.2节所述,并非所有原始连接都可用于混淆。本节提出了一种端口选择框 架,用于选择合适的端口进行混淆。根据所选端口的类型和数量,确定破解概率。最后, 我们提出了一种针对多个密钥数量的概率计算方法。
4.1. 端口选择框架
所提出的框架包含三个阶段:(i)预处理阶段,在此阶段确定用于混淆的端口候选;(ii)分 组阶段,在此阶段我们根据仅可编程组件和非可编程组件的端口描述对端口进行分组;以 及(iii)度量计算阶段,在此阶段计算混淆强度。混淆强度推断了攻击者通过暴力破解学习 正确连接/密钥的难度。
在本节中,我们提供了图5中恩智浦的一个参考设计。该图展示了基于飞思卡尔 ColdFireV1MCF51MM256CLLMCU[Fre 2014]的飞思卡尔活动监测参考设计的框图。 这是一个无创采集系统,包含计步器、心电图、饮食摄入表、数据存储、无线通信、定时 器和计时器。该参考设计将作为预处理阶段和分组阶段后续讨论的示例。它可以被视为图 2的实际实现。其中可编程组件为ColdFireV1MCF51MM256CLLMCU,非可编程组件 以紫色表示。在所有非可编程组件中,仅有触摸感应设备和显示模块的连接可以参与混淆 (原因见下文的预处理阶段)。
预处理阶段 :首先,我们将未使用的端口分组,并将该集合命名为虚拟端口集(SetD)。 在所有连接的端口中,我们排除用于以下用途的端口:模拟输入/输出(因为置换模块只能 处理数字信号);串行或并行通信端口(由于它们具有可预测用途,因此对混淆无用); 以及任何对时序敏感的端口(因为置换模块可能会引入额外延迟)。剩余的连接端口将被 命名为真实端口集(SetR)。
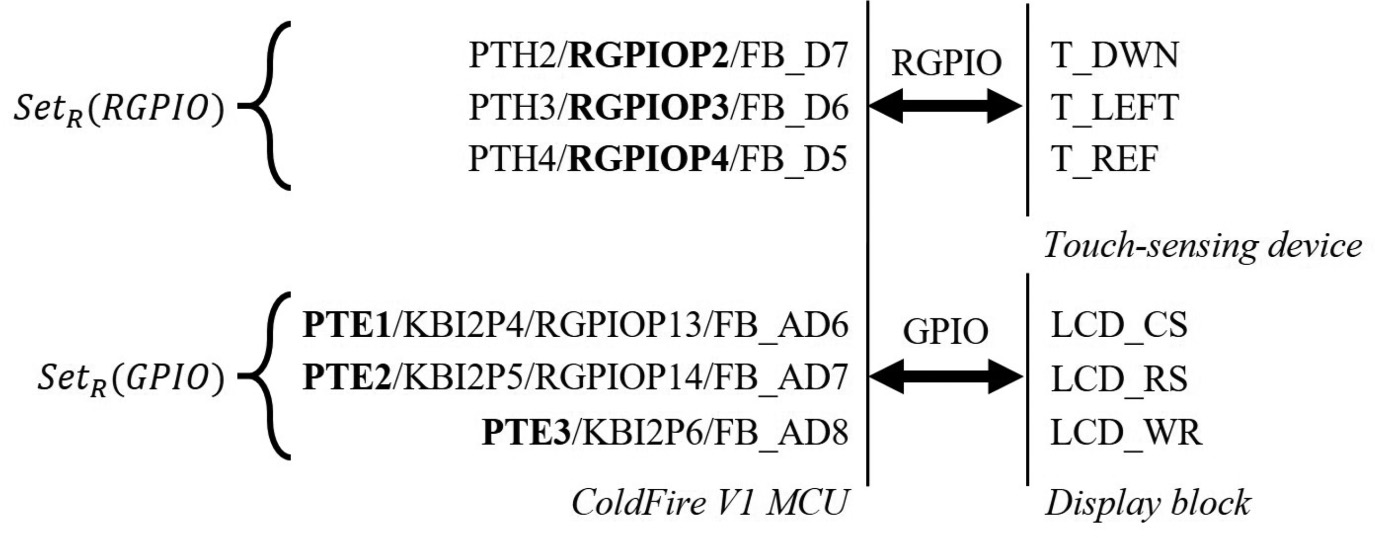
分组阶段 :分组的原因是为了评估混淆的强度。分组不会影响实际的硬件实现。这是必要 的,因为智能攻击者可能从可编程和非可编程组件的端口描述中获得某些信息(参见第 2.2节中的功能逆向工程)。对于非可编程组件,大多数端口的功能是专用的。例如,如图 5所示,触摸感应模块将通过快速通用输入输出(RGPIO)与微控制器单元通信。并非该 微控制器单元上的所有端口都具备作为RGPIO工作的能力(实际上只有16个端口)。在这 种情况下,攻击者可以通过仅从16个端口而非微控制器单元上的全部端口中搜索触摸感应 设备的正确连接来缩小范围。对端口进行分组有助于我们在后续的度量计算阶段避免高估 混淆强度。
分组阶段有两个步骤: 步骤1包括将集合R中的真实端口进行分组。由于非可编程组件的端口具有更专用的功 能,我们的目标是找到可编程组件上具有对应功能的端口。图6基于图5中的设计给出了一 个示例。图6的左侧是微控制器单元(MCU)的端口描述,可从手册/数据表中轻松获取。 X/Y/…/Z表示该端口可能具有多个可能的功能。对于图6所示的端口描述,PTXX( PTH2、PTE1等)表示该端口具有通用输入输出功能,RGPIOX(RGPIO2、RGPIO3等) 表示该端口具有RGPIO功能。图6的右侧显示了两个连接到MCU的非可编程组件。这些芯 片的端口名称(T_DWN、LCD_CS等)可以从其文档中获知。与MCU的端口描述不同, 这些端口的功能是专用的。
在图6中,以粗体显示的端口描述意味着攻击者可以根据非可编程组件的信息,从所有 可能的功能中轻松确定其功能。例如,攻击者可能知道微控制器单元中的某些端口应作为 触摸感应设备所需的可重构通用输入输出端口工作。 本例中的功能组为SetR(RGPIO)和SetR(GPIO),如图6所示。SetR(RGPIO)组包含原始设计 中用作可重构通用输入输出端口的所有微控制器单元端口。除了可重构通用输入输出端口外,其 他微控制器还具有其他功能组。例如,飞思卡尔MKM34Z128CLL5微控制器有45个端口用于液 晶显示器。飞思卡尔KinetisKEA128微控制器上有10个灵活定时器(FTM)端口可用于生成脉 宽调制(PWM)信号。德州仪器TMS320F2837xD微控制器有24个端口用于生成PWM信号。 微芯科技PIC32MZEC系列微控制器有5个端口作为外部中断。来自不同制造商的许多微控制器 和数字信号处理器具有上述功能组,但端口名称不同。除了这些具有专用功能的端口外,其余端 口仅需要通用输入输出端口。这些端口被归入SetR(GPIO)。
步骤2:在从步骤1获得若干组信息后,我们基于这些信息分析虚拟端口。虚拟端口有两种类型,如下 所示: —虚拟端口在步骤1中只能用于唯一功能(单功能虚拟端口),例如 PTA2/KBI1P1/RX1/ADP4PTA3/KBI1P2/FBD6/ADP5. —虚拟端口可在步骤1中用于两 个或更多功能(多功能虚拟端口),例如PTB6/KBI1P3/RGPIOP0/FBAD17 PTB7/KBI1P4/RGPIOP1/FBAD0._
如图5所示的示例中,共有33个虚拟端口。其中4个可同时用作GPIO和RGPIO;29个 仅用作GPIO。攻击者可以任意猜测如何将多功能虚拟端口分配到不同的组中。不同的虚拟 端口分配方式会产生不同的混淆强度估计值。
度量计算阶段 :在此阶段,我们计算混淆强度。此步骤可用于确定在资源约束(例如置换 块输入输出数量和时序约束)下能够实现最佳混淆效果的端口。相关度量将在第4.2节中讨 论。
对于包含多个可编程组件的印刷电路板,端口选择框架可以分别应用于每个可编程组 件。来自多个可编程组件的选定端口由同一个置换模块进行置换。
4.2. 混淆强度
攻击者的目标是找出芯片之间的正确连接。为实现这一目标,攻击者可以直接检查置换模 块的输入/输出组合,或检查密钥。攻击者实现该目标的难度被定义为混淆强度,可用破解 概率来表示。本文中,当攻击者尝试输入/输出组合时,破解概率表示为Pcom,当攻击者尝 试密钥时,破解概率表示为Pkey。Pcom与Pkey相等的条件是输入/输出组合与密钥之间存在 一一对应关系。
在本节的其余部分,提出了一种流程来估算Pcom。如第4.1节所述,可以采用不同的方 式对虚拟端口进行分组。攻击者可能在所有可能性中盲目猜测如何对虚拟端口进行分组。 他任意选择一种虚拟端口分组方式。这种选择可能导致需要尝试的暴力组合数达到最小值。 这正是本节旨在估算的混淆强度的下界。当攻击者检查输入/输出组合时,在分析混淆强度 时需要考虑不同的情形。
情况1 :仅使用真实端口的混淆。根据有限的信息(已在第4.1节中说明),真实端口 可以被划分为M(M 1)个组。设每个组包含Rk(1 k M)个端口。我们以图5中的应用 为例。在预处理阶段和分组阶段之后,仅剩下触摸感应设备和显示模块的连接需要进行混 淆(M= 2)。R1= 6,因为微控制器单元上有6个真实端口与触摸感应设备通信;R 2= 13,因为显示模块需要微控制器单元上的13个端口。
我们还定义了两种子情况,称为单组测试可行(IGTP)和单组测试不可行(IGTI)。 IGTP意味着攻击者只需研究组内的连接即可确定正确性,而无需考虑所有其他组的连接。 这将导致攻击者需要考虑的组合数减少,从而降低混淆强度。另一方面,IGTI意味着一组 的连接可能与其他组的连接对攻击者而言相互混淆,这会增强混淆强度。F or IGTP该指标由公式(3)给出,而IGTI由公式(4)给出,
CR IGTP= ∑ k=1 M1 Rk!, (3) CR IGTI= ∏ k=1 M2 Rk!, (4)
其中M1(1 steIGTP组的数量,M2(M2 M)是IGTI组的数量。可以很容易地看出M= M1+ M2。 M) i h
情况2
:使用真实端口和虚拟端口的混淆。这与情况1类似,但每个组还额外包含Dk(1 k M)个虚拟端口。对于IGTP,该指标由公式(5)给出。对于IGTI,该指标
 8输入Benes网络和(b) 阶段划分。)
8输入Benes网络和(b) 阶段划分。)
 开关连接和(b) 组说明。)
开关连接和(b) 组说明。)
由公式(6)给出。
CD&R IGTP= ∑
k=1
M 1
(
Dk+ Rk
/
Rk
)Rk!, (5) CD&R IGTI= ∏
k=1
M 2
(
Dk+ Rk
/
Rk
)Rk! (6)
在情况1和情况2中,IGTP组可能不存在。在这种情况下,我们可以将组合数C写为 h i i d IGTI b h i I h
C= CD&R IGTP+ CD&R IGTI OR C= CR IGTP+ CR IGTI . (7)
在图5所示的示例中,Dk对于相同的k可能具有不同的值,因为攻击者可以以多种不同 方式分配多功能虚拟端口。这意味着组合总数可能有多个值。我们可以将其形式化为一个 优化问题,以求得混淆强度的最坏情况估计。公式(8)是目标函数,其形式如公式(7)所示。 我们需要在混淆中使用全部虚拟端口(TD),如公式(9)所示。公式(10)表示每个变量( Dh)的取值范围应从对应组的单功能虚拟端口数量(TDUh)到对应组的多功能和单功能虚 拟端口总数(TDAh)。公式(11)表示任意两个不同变量之和应小于或等于这两个对应组并 集中的端口数量(TDAi,j)。公式(12)与之类似,但涉及多一个组。如果组的数量更多,约 束数量将增加。该优化问题可通过在线性约束下寻找多项式的最小值来求解。然而,我们 发现组的数量很少,因此可以轻松枚举所有解以确定最小值。注意,上述问题的解代表了 本节开头提到的混淆性能的下界。
Minimize C, (8) Subject to ∑ k=1 M Dk= TD, (9) TDUh Dh TDAh, ∀h ∈[1, M], (10) Di+ Dj TDAi,j,∀(i,j) ∈[1, M] andi =j, (11) Di+ Dj+ Dh TDAi,j,h,∀(i,j, h) ∈[1, M], andi =j, j = h, i = h. (12)
当攻击者尝试检查输入/输出组合时,破解概率(Pcom)可通过公式(13)计算。
Pcom= 1 / C . (13)
4.3. 多密钥计算
如本节前面所述,仅当密钥与输入/输出组合之间存在一一对应关系时,Pkey才等于Pcom。 然而,当实现某些置换网络(例如Benes网络)时,这种情况并不成立。当攻击者选择检 查密钥时,破解概率可通过公式(14)计算。
Pkey= Number of correct keys / Total number of keys . (14)
由于密钥总数超过了输入/输出组合的总数,多密钥效应可能会或可能不会增加破解概率。 第3.2节中的第二种配置情况意味着在已知输入/输出顺序的情况下计算密钥。在此配置中, 每个环路内的开关可以以两种方式进行配置,例如“1101”和“0010”。这些开关的配置 相互连接形成密钥。一般来说,循环次数与多个密钥(Mkey)之间的关系可以用公式(15) 描述,
Mkey= ∏ k=1 K 2 li = 2 ∑K i=1 lk , (15)
其中K是外级数量,每个外级包含lk个环路。如图7(第3.2节)所定义,一个环路由两个 或更多相互连接的开关组成。注意,环路是计算多重密钥的数量的基本单元。
循环次数(lk)取决于输入/输出组合。当置换网络包含超过16个输入时,这些组合数 将变得极其庞大且无法枚举。
在本节中,我们提出一种逐步方法来估计lk的概率分布。所提出的方法使设计者能够 估算多个密钥的最小值、最大值和平均数量。基于这一知识,设计者可以确定攻击者在检 查密钥时的预期破解概率。为实现此目标,应依次完成以下阶段: —第一阶段:第一外级分析旨在计算第一外级中的环数分布。第一外级由第一级和最后一 级(即图3(b)中的第0阶段和第4阶段)组成。该分布在计算内部级的分布时被用作基础概 率。在此阶段中,为简化起见,我们假设Benes网络输入和输出顺序是均匀分布的,但我们 的方法具有通用性,也可处理其他先验概率。 —第二阶段:条件概率估计在给定第(n − 1)个外级的环路数量的情况下,确定第n个外级 的环路数量,其中n>= 2。例如,该阶段估算当第一外级包含三个环路时,第二外级 (图3(b)中的第1级和第3级)包含两个环路的概率。这一估算至关重要,因为除了第一外 级之外,其他任何外级均不满足均匀分布假设。在外级与其更高层级的外级之间观察到存 在依赖关系。 —第三阶段:多重密钥分布分析通过结合第一外级循环次数(第一阶段)和条件概率(第 二阶段)来实现其目标。
4.3.1. 第一外级分析
在本节中,我们提出一个数学模型来计算第一外级中环路数量的概率。为了实现这一目标,提出了一种两步法。结果在第6.3节中通过模拟数据进行了验证。
步骤1 根据循环次数对开关进行分组。图4(b)展示了具有两个环的第一外级。一个环包 含两个开关(x0和y1,,以红色虚线表示),而另一个环由六个开关组成(x1, x2, x3, y0, y2 和y3,以实蓝色线条表示)。构成同一环路的这些开关被归为一个开关组。由于任意开关 组中的开关数量始终为偶数,因此该开关组可用实体{1, 3}表示,其值等于每个环路中的开 关数量除以2。此组表示方法推断出:(i)该开关组中的元素数量为2,等于环路数量;(ii) 该开关组中元素之和为4,等于一级中的开关数量。 根据环路的定义,一个环路中最少开关数为2。因此,一个外级中的最大环路数等于一 级中的开关数量。例如,在图7(a)中,该外级由四个环路组成,每个环路包含两个开关 (x0和y1,,x1和y0,等)。假设一级中的开关数量为W,这是一个仅取决于网络维度的参 数。最小环数为1,此时所有开关都被包含在一个环路中(如图7(b)所示)。由于所有节点 都可以通过互连相互到达,因此所有节点都属于同一个环路。换句话说,这些节点中的任 意两个都是直接或间接连接的。
此步骤的目标是收集从1到W的环路数量对应的所有可能的开关组。为实现这一目标, 我们求解方程(16)的全部正整数解。每个解对应一个可能的开关组。
∑
i=1
n
ai= W, 1 ≤ ai ≤ W, (16)
其中n表示第一外级中的循环次数,其值可以是1到W之间的任意值。解(开关组)定义为 a={ai, a2,…,an},其中ai是一个开关组元素。对于一个特定的n值,可能存在多个解。这 些解被收集为对应于该n的解集。每个解集将进一步通过去除重复解来优化。例如,解{12 1}是解{112}的一个重复解。最终,针对每个n计算出一个包含一个或多个解的解集。
我们以16位Benes网络为例讨论该步骤,并在表I中展示结果。在此情况下,W= 8, 且我们将n从1变化到8。开关组(SwG)用符号{·}表示。SwGn i表示当循环次数为n时的 第i个开关组。每个开关组由一个或多个开关组元素SEn , i j组成,这表示SwG n i中的第j个元 素。我们还将循环次数为n时的开关组总数定义为TSwGn。例如,在表I中,SwG4 2表示开 关组{1124}。该开关组中的第三个元素是SE4 2 3= 2,。产生四个环路的开关组数量为 TSwG4= 5。此外,开关组{1124}意味着开关被分组为四个环路,分别包含两个、两个、 四个和八个开关。对于不同的n值,开关组的数量为TSwG,且每组中的元素数量可能不同。
步骤2
计算第一外级包含n个环路的概率Pr(n)。计算Pr(n)等同于确定在随机选择输入/ 输出置换时,SwG n 多个开关组对Pr(n)有贡献。在这些情况下,计算Pr(n)时应包含全部开关组。
Pr(n)= ∑
i=1
TSwGn
Pr(SwGn i). (17)
在公式(17)中,TSwGn表示形成n个循环时的开关组总数。Pr(SwGn i)表示开关组SwGn i 出现的概率。Pr(SwGn i)的计算依赖于开关组SwGni中的每个开关组元素(SEi,nj)。由SEn,i j提供的概率定义为Pr(SEn,ij)。Pr(SEn,ij)可通过从开关池中无放回地采样SEn,i j个开关直 至所有开关都被采样来计算。池中开关的数量取决于网络维度。最后,Pr(SwGn i)可通过 公式(18)计算得出。上述计算过程在算法1中进行了详细总结。
Pr(SwGn i)=∏j Pr(SEn,i j). (18)
算法1的主要思想如下所述。该算法旨在计算每个开关组(例如,表I第二列中的{1 7}、 {125}等)的概率。此计算通过无放回选择过程实现。算法1的第5到16行用于实现该过程。 例如,为了计算开关组{1 2 5}(表I第四行第二列的第一个组)的概率,应按顺序执行以下 步骤。在第一次迭代中,算法计算从由八个开关组成的开关池中随机选择一个开关的概率。 该概率记录为Pr(SE3,1 1)。由于该过程需无放回地进行,因此在从开关池中选择一个开关后, 开关池中的开关数量减少至7。接着,从7个开关中随机选择两个开关的概率被存储为 Pr(SE3,1 2)。在此迭代之后,开关池中的开关数量减少至5。最后一次迭代从开关池中选择 五个开关,并将概率存储为Pr(SE3,1 3)。这三个概率在第18行相乘(即公式(18))。第19到 27行描述了调整过程。由于某些组合被重复计数,因此需要对概率进行调整。在处理完特 定循环次数的所有开关组后,可在第29行得到概率Pr(n)。
算法1提供了一种比穷举法更快的方法来估计分布。根据仿真结果,在Matlab中配置 1E6个16输入Benes网络的输入/输出组合需要12小时。而穷举搜索所有这些组合将耗时超 过1E7小时,相当于数千年。因此,对具有超过16个输入的Benes网络的输入/输出组合进 行穷举搜索在时间上不可行。然而,运行所提算法仅需几秒钟即可完成。
4.3.2. 条件概率估计
在第4.3.1节中,根据随机输入/输出假设计算了第一外级中包含的n 个环路的概率。然而,除第一级以外的外级并不满足该假设,因为它们的输入和输出在内 部相互连接。换句话说,外级之间的环路数量存在相关性。例如,对于一个8位Benes网络, 如果第一外级由一个环路组成,则第二外级只能由一个或三个环路组成。这一观察结果通 过在8位Benes网络的输入/输出组合上进行穷尽搜索得到验证。因此,
Pr(OSk= lk|OS1= l1,…, OSk−1= lk−1) k ∈[2: K]. (19)
公式(19)计算了当其他外层阶段(OS1到OSk−1 )包含特定循环次数(l1到lk−1 )时,第k个外层 阶段(kthOSk)包含lk个环路的概率。每级的循环次数,l1到lk,范围从1到W,即 任意级中的开关。针对每个k构建一个条件概率矩阵。该矩阵包含全部环路组合。由于某些 组合无效,这些矩阵中的并非所有条件概率都非零。例如,当第一外级包含W个环路时, 第二外级不可能包含1个环路。这些条件概率可以通过少量仿真进行准确估计。
4.3.3. 多重密钥分布分析
通过分析循环次数的概率分布,可以进行多个密钥数量的概率分布。在第4节中,结合了第4.3.1节和第4.3.2节得到的结果。在第4.3.1节中,计算了第一 外级循环次数的概率分布。在第4.3.2节中估算了条件概率。
假设一个Benes网络包含K个外级,且第k个外级(OSk)包含lk ∈[1:W]环路。概率 Pr(l1,…,lK)定义为以下事件同时发生:OS1包含l1环路,OS2包含l2环路,依此类推。该 概率可计算为
Pr(l1,…, lK)= ∏
k=2
K
Pr(OSk= lk|OS1= l1,…, OSk−1= lk−1) ∗ Pr(l1). (20)
Pr(·|·)的值可从4.3.2节条件概率估计阶段估算出的条件概率矩阵中获得。Pr(l1)表示第一 外级包含l1个环路的概率。为了计算网络包含L个环路的概率(Pr(L)),应根据公式(21) 获取所有可能的{l1,…,lK}组合数。
L= ∑
k=1
K
lk, 1 ≤ lk ≤ W. (21)
固定L、K和W,所有可能的{l1,…,lK}组合数被收集到集合Q={{l1,…,lK}1,{l1,…, lK}2,… ,{l1,…, lK}q}中。Pr(L)的计算可由公式(22)表示。
Pr(L)= ∑
∀q∈Q
Pr({l1, l2,…, lK})q. (22)
为了说明分布分析过程,根据图3所示的8位Benes网络计算Pr(L= 6)。在这种情况下, 常数W= 4和K= 2仅取决于网络输入数量。根据公式(21),可能的{l1,…,lK}组合数为 {2,4}、{3,3}和{4,2}。将这些信息以及第一外级概率和条件概率代入公式(20)和(22),可计 算出公式(23)中的Pr(L= 6),
Pr(L= 6)= ∑
∀q ∈Q
Pr(l1, l2)q= Pr({2, 4})+ Pr({3, 3})+ Pr({4, 2}) = Pr(OS2= 2|OS1= 4) ∗ Pr(l1= 4) + Pr(OS2= 3|OS1= 3) ∗ Pr(l1= 3) + Pr(OS2= 4|OS1= 2) ∗ Pr(l1= 2). (23)
5. 安全分析
攻击受保护的设备时,攻击者试图实现三个目标:过度生产、克隆或未经授权的操作。在 本节中,我们将讨论实现这些目标的潜在攻击及对策。
5.1. 潜在攻击与攻击级别
为实现上述攻击目标,攻击者试图获取正确的密钥或输入/输出置换。以下攻击可由攻击者 实施,其中一些攻击直接向攻击者提供此信息,而另一些则增强其他攻击。
暴力破解攻击 :这是最直接的攻击方式,涉及攻击者尝试所有密钥或输入/输出置换。 此类攻击的成功与否在很大程度上取决于破解概率(无论是Pcom还是Pkey)以及验证系统 正确行为所需的时间。我们在第6节中提供了在最坏情况假设下的验证时间定量结果,即最 坏情况是攻击者可以在一个时钟周期内验证每个密钥或输入/输出置换。根据第6节所示的 结果支持,攻击者通过暴力破解来攻破我们的混淆方法是非常困难的。
表面走线探测攻击 :对于每个系统而言,置换模块输入与相应输出之间的波形完全相 同,即使密钥可能不同。拥有正常工作系统的攻击者可以使用多通道逻辑分析仪探测置换 模块的所有输入/输出。通过简单匹配所探测信号的波形,攻击者即可找出可编程和非可编 程组件之间的真实连接。
内存泄露攻击 :存储在外部非易失性存储器(通常是闪存)中的数据可通过多种商业 工具提取。外部存储器指位于电路板上的片外存储器,且所有端口均暴露在外。当密钥存 储在该存储器中时,攻击者可通过实施此类攻击获取密钥,并利用此密钥操作其他受保护 设备。为对外部存储器实施此类攻击,攻击者可遵循以下步骤:(i)识别调试端口;(ii) 提取并分析固件;(iii)查找密钥。为识别调试端口,需要使用简单的焊接台、万用表或 逻辑分析仪。通过分析逻辑分析仪报告的数据,可确定各端口的功能。若能找到被攻击闪 存芯片的详细数据手册,则此步骤可跳过。基于第一步中识别出的端口,攻击者可在存储 器与台式电脑之间建立串行/并行通信通道。该通道使攻击者能够向闪存发送命令。最后一 步中,为找到密钥,攻击者需从闪存中检索数据。根据闪存的接口类型(串行或并行), 可向闪存发送适当的读取命令以获取内容。可利用逻辑分析仪监控闪存的响应,通过分析 该响应即可恢复密钥。
CPLD重新安装攻击 :攻击者可以将置换模块(通常为CPLD)从电路板上拆卸下来, 并将其重新安装到其他平台或使用适当的载板适配器安装回同一印刷电路板上。该攻击不 应损坏封装,可通过以下步骤完成。首先,通过热风加热拆除球栅阵列芯片。接下来,使 用吸锡带清除焊料残留。然后,攻击者可以选择以下两种方式之一重新安装球栅阵列芯片: (i)安装到另一块定制PCB上;(ii)使用合适的载板适配器安装回同一PCB上(例如,铁木 电子提供的商业产品[Ironwood 2016])。重新安装拆卸下来的CPLD使得硬件探测成为 可能。此类攻击本身不会直接向攻击者提供密钥信息,但结合此攻击可使硬件探测攻击更 加强大。
中间层探测攻击 :攻击者可以通过非破坏性逆向工程方法(如基于X射线的技术[ Asadizan‐jani2015;Ahi等人 2015])发现完整的PCB布局。在布局信息的引导下,攻击者 可以铣出孔洞以探测每个CPLD端口。这些孔洞使攻击者能够访问CPLD端口,而不会损坏电路 板上的其他走线。
集成电路逆向工程攻击 :攻击者可以完全逆向工程电路板上的任何芯片,并彻底获取 存储在这些芯片中的秘密信息。此类机密信息包括用于解锁置换网络的密钥、可编程组件 的固件、置换网络结构等。逆向工程攻击的具体方式将取决于置换芯片的实现形式(专用 集成电路、现场可编程门阵列、复杂可编程逻辑器件等)以及攻击者希望提取的内容(密 钥、比特流等)。如果密钥或固件存储在外部非易失性存储器中,则可采用上述内存泄露 攻击。如果密钥或固件存储在片上,则需要耗时的逆向工程过程,该过程可能需要多个芯 片(样本)以及数百万美元设备(湿法或干法刻蚀设备、扫描电子显微镜(SEM)或聚焦 离子束(FIB)、探针台等)。
一般的逆向工程流程如下:(i)使用一个或多个芯片对物理布局和连接进行逆向工程。 此步骤需要去封装以暴露芯片。由于芯片是多层结构,应通过扫描电子显微镜(SEM)对 每一层重复执行去层和成像操作,然后进行图像拼接。由于该过程容易出错,可能需要多 个芯片才能正确提取网表。(ii)在提取的布局/网表中确定所需信息的位置。获得网表后, 下一步取决于存储数据的非易失性存储器类型(例如闪存和电子熔丝)。如果使用电子熔 丝,则密钥/固件可能直接从上一步获取的图像中识别出来,从而完成攻击。对于闪存情况, 则利用逆向工程得到的网表来识别承载所需数据的总线或网络。(iii)使用FIB探针台进行 探测以提取密钥信息。操作员在新的(未去层的)样品上定位前一步骤中发现的内部总线/ 网络,然后通过FIB在目标位置进行铣削并沉积金属,以建立物理接触,再通过探针台读取 密钥信息。需要注意的是,为了成功读取数据,可能需要通过FIB绕过或规避芯片内的各种 防篡改机制。上述所有步骤执行起来均非易事,且需要大量投入。
在IBM[Abraham等人 1991],的一篇知名文章中,作者建议根据攻击者的预期能力 和攻击强度,将攻击者分为三类: —一类(聪明的外部人员):他们通常很聪明,但可能对系统了解不足。他们只能使用中 等复杂程度的设备。他们通常试图利用系统中已存在的弱点,而不是尝试制造新的漏洞。 —二类(有知识的内部人员):他们具有丰富的专业技术教育和经验,对系统的部分环节 有不同程度的理解,但可能接触到系统的大部分内容。他们通常可以使用高度精密的工 具和仪器进行分析。 —三类(获得资金支持的组织):他们能够集结具备相关且互补技能的专家团队,并拥有 充足的资金资源支持。他们具备对系统进行深入分析、设计复杂攻击以及使用最先进的 分析工具的能力。他们可能会将二类攻击者纳入攻击团队中。
一类攻击者可以实施暴力破解攻击和表面探测攻击。由于这些攻击者对系统的了解有 限,暴力破解攻击是最直接的方法。配备示波器后,这类攻击者能够完成表面探测攻击。 利用一些低成本设备,如加热系统和BGA载板适配器,这些攻击者还可以实现CPLD重新安 装攻击。如果密钥存储在电路板上,则一类攻击者也可以进行内存泄露攻击。与一类攻击 者相比,二类攻击者可以使用更精密的仪器进行中间层探测攻击。实施此类攻击所需的工 具应具备对多层PCB进行非破坏性逆向工程和钻孔的能力。三类攻击者由于拥有最先进的 分析工具和充足的资源,因此可以实施集成电路逆向工程攻击。
5.2. 安全等级和攻击覆盖范围
考虑到不同类型的攻击者及其能力,对策被划分为三个安全需求等级。
低级别安全需求 :满足此安全要求级别的设备直接将相同的密钥存储在非易失性存储 器中。为实现低级别安全需求,我们建议可编程组件和置换模块均采用BGA封装,并在印 刷电路板中至少使用一个中间层进行布线。图8(a)展示了一个BGA封装的示例。由于当前 印刷电路板的复杂性,多层结构的需求很容易满足。对于BGA封装的要求,表II中的统计 结果显示,在引脚数大于或等于64的可编程组件中,有较大比例的混淆候选对象采用了 BGA/VTLA(VTLA是微芯科技使用的一种与BGA封装非常相似的封装标准)封装(原因 将在第6节中说明)。采用BGA封装不会引入额外的面积和功耗开销。对于同一型号的芯片, BGA封装与其他封装的成本也相同。在进行PCB布线时,我们识别出可编程组件与置换模 块之间的所有连接,并将其布置在中间层中。该布线要求在本文后续部分称为中间层布线。 图8(b)展示了一种隐藏连接的示例。此步骤旨在降低攻击者通过探测工作设备来识别芯片 间连接的可能性。同时还应应用低成本的防篡改技术[Karri等,2010;Skorobogatov 2006]。 除了封装和布线要求外,隐藏每个密钥位与开关之间的关系可以进一步增加破解难度。 为了实现这一点,在配置置换网络之前,应使用安全哈希函数对密钥进行处理。
中等安全级别要求 :对于大多数工业系统和消费类电子产品而言,系统重启是不可避 免的。由于每次重启后重新应用密钥在此情况下通常不切实际,因此这些系统需要将密钥 存储在非易失性存储器中,并在重启前自动重新加载密钥。这种行为为攻击者提供了通过 某些技术(例如CPLD重新安装攻击)破坏混淆的机会。
为了满足中等安全级别要求,需要采用球栅阵列封装和中间层布线。此外,我们建议 使用一种板级物理不可克隆函数,并结合外部密钥(输入)在置换模块内计算内部密钥。 为此,应修改置换模块的固件以集成用于板级物理不可克隆函数的测量模块[张等人2015年; Wei等人 2015]。该板级物理不可克隆函数利用印制电路板制造过程中的工艺差异,这些 工艺差异包括走线宽度/厚度等的变化。这些差异会导致相同走线在不同印刷电路板上的阻 抗/电容发生变化。置换模块可以从这些走线生成签名。例如,可将走线构造成环形振荡器 电路,并将其频率作为签名进行测量。板级物理不可克隆函数应对任何阻抗变化保持敏感: 对走线、焊料和芯片的任何结构性变化都应被物理不可克隆函数捕获。对走线的更改可能 指对走线的探测,使用示波器等设备对走线进行探测应导致物理不可克隆函数输出发生显 著变化。对焊料的更改表示有人从印刷电路板上移除或添加焊料。移除芯片时,攻击者需 将焊料从该芯片的焊盘上去除。如果任何板级物理不可克隆函数连接到这些焊盘,则其输 出应发生变化。对芯片的更改意味着芯片被替换。这种替换包括攻击者可以安装探测系统 (即插座)以使芯片可被访问。
设计者在开发板级物理不可克隆函数时应考虑一些挑战。这些挑战包括鲁棒性和分辨 率。鲁棒性是指PUF输出在各种环境条件(例如温度和电压)下的稳定性。若无结构性变 化,置换模块应接收到稳定的PUF响应。然而,环境变化可能引入错误,因此可能需要使 用纠错码来消除这些错误。另一个挑战是分辨率。板级物理不可克隆函数应对PUF走线的 最微小变化都足够敏感。请注意,如何实现板级物理不可克隆功能的具体讨论超出了本文 范围,被视为正在进行的工作。
图9展示了实现中等安全级别要求的一般流程。首先,用于读取PUF输出的专用固件被 下载到置换模块中。然后,置换模块将加密的PUF读数发送回设计者。设计者根据接收到 的PUF输出修改置换固件,并将该固件发送至装配环节,以重新加载到置换模块中。当印 刷电路板/系统处于现场时,此修改后的置换固件仅在接收到正确的PUF读数时才能正常工 作。该机制可防范CPLD重新安装攻击,因为在攻击者平台上的PUF读数与原始板不同。由 于PUF读数不同,密钥无法生成正确的输入/输出置换。
或者,可以利用多种其他方法来实现基于置换的混淆。详细描述和定义如下所示。 —统一固件:相同的固件直接加载到任意置换模块中,并且它们共享相同的密钥。 —基于密钥:密钥信息(例如可编程组件的输出顺序)被嵌入到固件中。每个置换模块和 可编程组件接收不同的固件,且密钥也是唯一的。 —芯片签名:在置换模块的标识符中使用了芯片级PUF(例如,静态随机存取存储器物理不可克 隆函数或环形振荡器物理不可克隆函数)。所有置换模块加载相同的固件,但输出不同的PUF 读数。这些加密的PUF读数将被发送给设计者。设计者可以计算出密钥,并将其发送回系统。 —板级签名:板级签名(板级物理不可克隆函数读数)存储在置换模块中。需要使用比较 器将上述存储的物理不可克隆函数签名与实际板级物理不可克隆函数输出进行比较。如果 实际读数与存储值匹配,则系统可以被激活。
与所提出的板级物理不可克隆函数+置换方案相比,这些替代方法存在若干缺点: —统一固件和基于密钥的方法即使面对低成本攻击(如CPLD重新安装攻击和内存泄露攻 击)也容易受到攻击。 —芯片签名方法可以消除内存泄露攻击,但容易受到CPLD重新安装攻击。作为合法用户 的攻击者可以重新安装置换模块,并将正确密钥加载到其中。 —板级签名方法容易受到重放攻击,因为PUF读数存储在芯片中。通过攻破内存,攻击者 可以恢复存储的PUF读数,并在系统获取板级PUF时无论何时都重复发送相同的值。这样 一来,即使CPLD被从原始位置移除,攻击者仍能正确配置置换模块,从而实现CPLD重新 安装攻击。 —此外,该方法需要一个比较器来比较上述存储的物理不可克隆函数签名与实际板级物理 不可克隆函数输出。这很容易通过故障注入攻击被绕过,从而导致在没有正确物理不可克 隆函数签名的情况下电路板仍可工作。
板级物理不可克隆函数提供了系统完整性检查(即保证复杂可编程逻辑器件连接在原 始印刷电路板上)以及为不同印刷电路板提供唯一密钥的优势。因此,利用物理不可克隆 功能增强了基于置换的混淆,同时基于置换的优点仍然起着主要作用。与上述替代方法相 比,实现所提出的板级物理不可克隆函数对于消除各种低成本攻击至关重要。
高级安全要求 :在这种情况下,密钥不会存储在系统的非易失性存储器中,并且在重 启后需要重新输入到系统中。满足此安全要求的设备应具备抵御所有已知攻击的能力。关 键应用(如军事设施和存储敏感数据的商用设备)需要这一级别的保护。此外,这些设备 的密钥应得到妥善保护。操作员生物特征(例如指纹、虹膜等)可用于生成密钥[Beng等 人 2008]。生物特征难以被复制或窃取[Wayman等人 2005]。结合所提出的保护
图10. 攻击覆盖分析。
结合基于生物特征的密钥生成技术,该框架将密钥与操作员绑定。 由于密钥未存储在非易失性存储器中,因此在CPLD中利用D触发器链构成移位寄存器。 CPLD上的一个专用端口被设计为串行密钥输入。移位寄存器的每一位配置一个Benes网络开关。 当CPLD断电时,D触发器丢失其值,密钥随之被销毁。每次系统重启时,用户都需要重新向 CPLD输入密钥。我们还需要考虑电路板断电后存在的数据残留现象[Drimer 2009](触发器 可能存在偏置),尤其是在低温环境中。为了实现更高安全级别,可以开发定制CPLD,以便在 断电后彻底销毁密钥。
针对所有安全需求级别,我们假设可编程组件的固件可以通过互联网以加密形式下载。 密钥存储在微控制器单元中用于解密固件(例如,RSA私钥)。在不知道解密密钥的情况 下,攻击者无法对固件进行逆向工程。此外,存储在可编程组件片上闪存中的固件应得到 妥善保护。目前,已有多种商业工具[Cod2016;Wilkinson 2015]为微控制器(MCUs)/现 场可编程门阵列提供此类保护。例如,恩智浦的CodeWarrior[Cod 2016]可以设置安全 位,一旦发生未授权读取固件的情况,整个闪存将被擦除。
考虑到上述不同安全要求级别下各类攻击者的能力,我们对图10中的防护覆盖范围进 行了全面分析。满足低级别安全需求的设备能够部分消除一类攻击者所实施的攻击(暴力 破解攻击和硬件探测攻击)。由于混淆连接隐藏在电路板的中间层,硬件探测攻击无法实 施。然而,由于相同的密钥存储在板载非易失性存储器中,一类攻击者可以提取该密钥, 并利用其激活其他印刷电路板(存储器泄露攻击)。这些攻击者还可以使用载板适配器将 置换模块重新安装到自己的平台或原始印刷电路板上(CPLD重新安装攻击),从而实施 硬件探测攻击。
如果设备符合中等安全级别要求,则可以消除内存泄露攻击和CPLD重新安装攻击。在 此安全要求级别的设备中,采用了带有板级唯一标识符(板级物理不可克隆函数[张等人 2015年;Wei等人 2015])的混淆方案。该组合可确保以下内容: —置换模块仅在直接连接到其原始印刷电路板

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









