




本文首先介绍了M-P神经元模型,该模型模拟生物神经元的信息处理过程,通过加权求和与激活函数实现线性分类。文章指出单个神经元具有线性分类能力,但通过组合成网络可获得非线性处理能力,并以逻辑运算为例展示了神经网络如何解决线性不可分问题。文中还讨论了层状神经网络的结构特点,包括前馈型和反馈型网络的区别。损失函数用于量化模型预测误差。通过最小化损失函数来优化模型参数。迭代法是一种逐步逼近最优解的优化方法,它是通过计算机求解的基本方法,研究迭代法将为后文讨论在机器学习领域占有极重要地位的梯度下降法奠定基础。
目录
深度学习是层数很多的神经网络。本文讨论神经网络中的基本问题,包括神经元、神经元组成网络后的非线性处理能力、刻画模型预测能力的损失函数、以及模型求解的基础方法,为后续深入讨论打下基础。
1 神经元模型
人工神经元(简称神经元)是神经网络的基本组成单元,它是对生物神经元的模拟、抽象和简化。现代神经生物学的研究表明,生物神经元是由细胞体、树突和轴突组成的,如下图所示。通常一个神经元包含一个细胞体和一条轴突,但有一个至多个树突。
生物神经元是人脑处理信息的最小单元。树突负责接收来自其他神经元的信息。细胞体负责处理接收的信息,它通过树突收到来自外界的刺激信息并兴奋起来,当兴奋程度超过某个限度时,会被激发并通过轴突输出神经脉冲信息。发送信息的轴突与别的神经元的树突相连,实现信息的单向传递。轴突末端常有分支,连接多个其他神经元的树突,可以将输出的信息分送给多个其他神经元。
受生物神经元对信息处理过程的启迪,人们提出了很多人工神经元模型,其中影响最大的是1943年心理学家McCulloch和数学家W.Pitts提出的M-P模型,如下图所示。
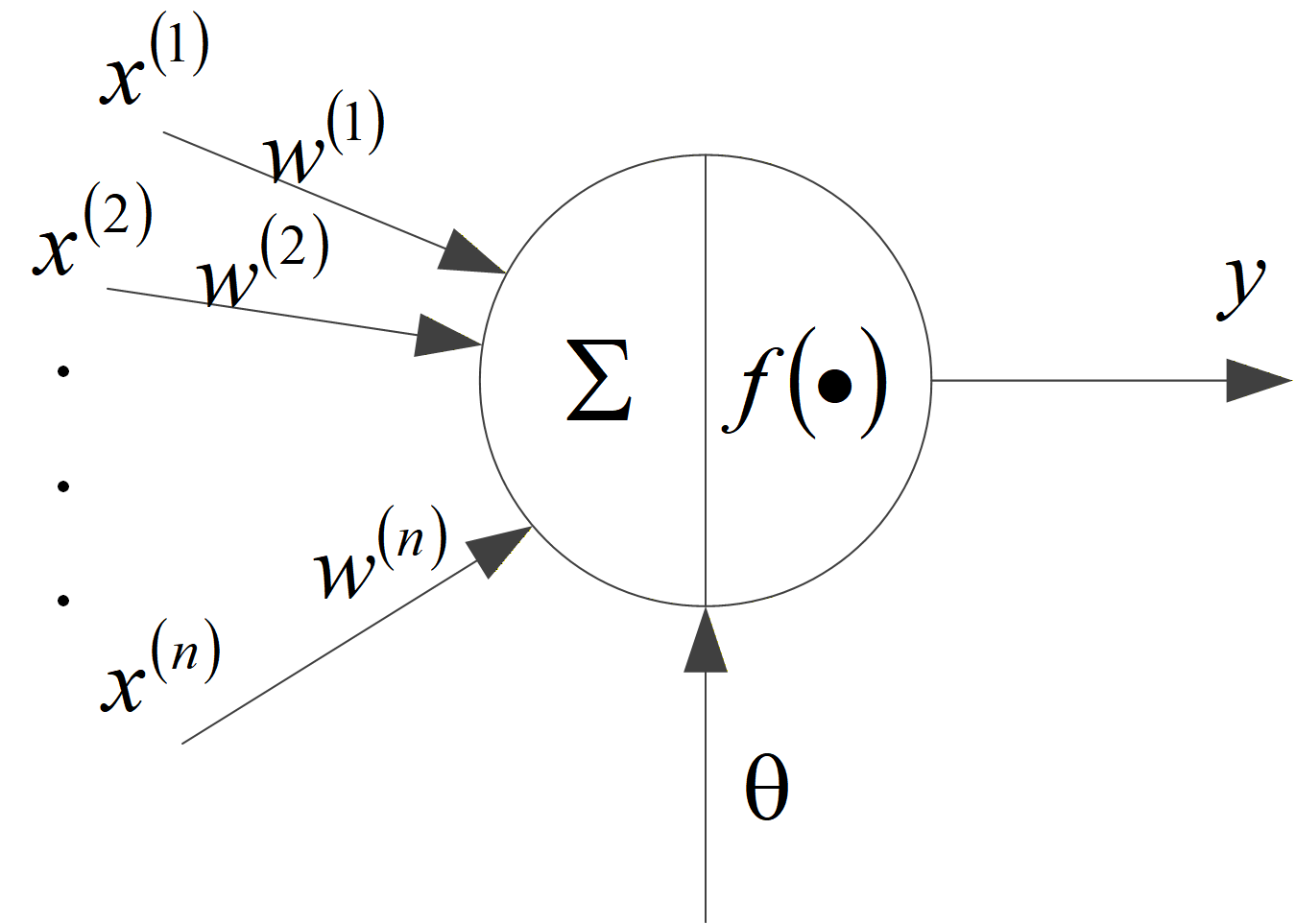
表示来自其他神经元的输入信息,
。
表示输入信息对应的连接系数值。Σ 表示对输入信息进行加权求和。θ 是一个阈值,模拟生物神经元的兴奋“限度”。输入信息经过加权求和后,与阈值进行比较,该信息处理过程是一个对输入信息的线性组合过程:
对输入信息进行线性组合后,再通过一个映射,得到输出:
称为激活函数或转移函数,它一般采用非线性函数。就M-P模型而言,神经元只有兴奋和抑制两种状态,可将它的激活函数
定义为如下图红粗线所示的单位阶跃函数,输出
只有0和1两种信号。
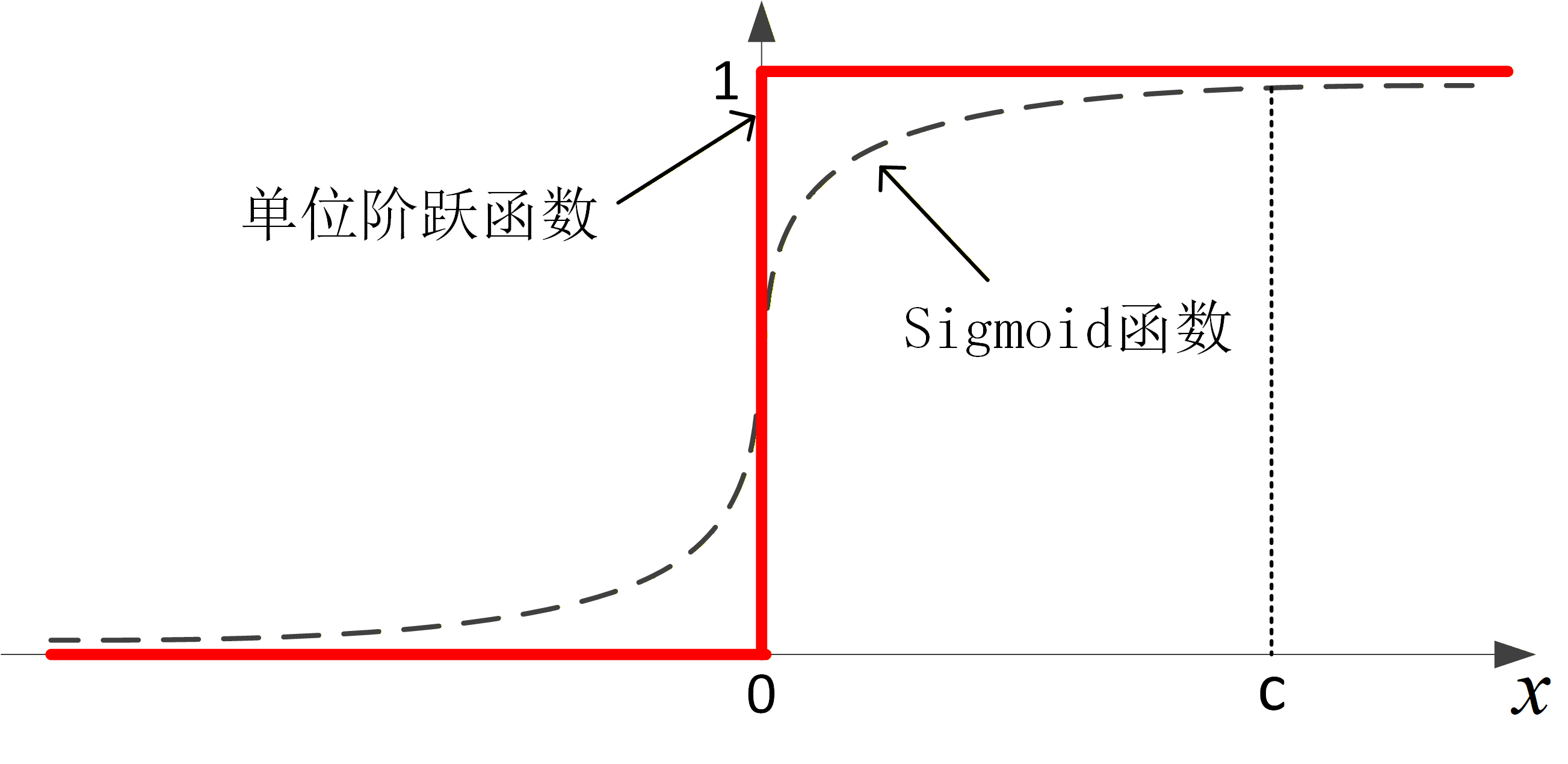
单位阶跃函数通常记为 ,其定义为:
单位阶跃函数不连续,在优化计算时难以处理,于是,常用近似的函数来代替它,例如上图中虚线所示的Sigmoid函数:
Sigmoid函数的形态接近于单位阶跃函数,取值范围是 。
除了M-P模型,还出现了许多其他神经元模型,它们的主要区别在于采用了不同的激活函数 ,除了阶跃函数和Sigmoid函数外,常用的还有ReLU函数、Softplus函数、tanh函数和Softmax函数等。不同的激活函数适用于不同的任务,将在后文结合示例讨论。
如果令M-P模型的线性组合部分等于0,可以得到一个方程:
当输入M-P模型的信息总数为1(即)时,该方程表示直线上的一个点。该点将直线分成两段射线,同一射线上的点经过M-P模型的线性组合部分的输出值都大于0或者都小于0,再经过单位阶段函数
后,同一射线上的点经过M-P模型的输出都为1或者都为0。如果将1或0看成两段射线上的点的标签,那么上面方程表示的点可以看成是直线的上的一个分界点,它的两边的点分属于不同的两个类别。
同理,当输入M-P模型的信息总数为2(即)时,该方程表示平面上的一条直线,它将平面划分为两个半平面,这两个半平面上的点分别属于两个不同的类别。当输入M-P模型的信息总数为3(即
)时,该方程表示三维空间中的一个平面,它将三维空间划分为两半,其中的点分属于两个不同的类别。当输入M-P模型的信息总数大于3(即
)时,该方程表示高维空间中的一个超平面,它同样起到了划分高维空间的作用。
因此,M-P模型的神经元具有线性分类的能力,属于线性模型。虽然线性分类能力可以用来完成一些简单的任务,但是非线性分类能力才是人们更看重的,人们发现这可以通过将神经元组合成网络来实现。
2 神经网络
在讨论神经网络的非线性分类能力之前,先说明一下神经元的一般画法如下图所示。神经元由输入层和输出层组成。输入层负责接收信息,并将信息传给输出层。输出层负责加权求和、产生激励信息并输出。
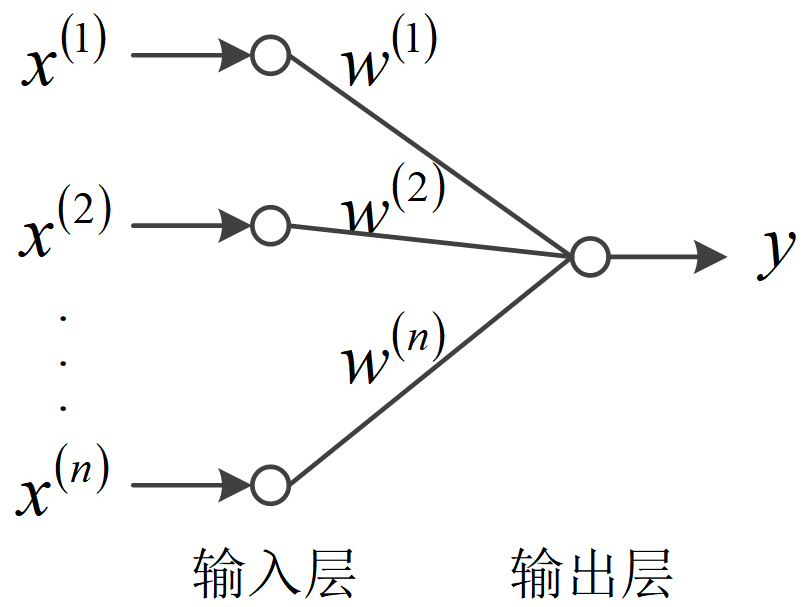
为了与传统表示方法保持一致,将神经元的线性组合部分写成如下形式。它与原形式只是加减阈值的区别,实际上可以通过相应改变阈值的正负号来得到相同的内容。
用神经网络来模拟逻辑代数的与、或、非以及异或运算来说明神经网络的非线性分类能力。
与运算的真值表如下所示。
| 与运算 | |||||||||||||||
|
如果把看成横坐标,把
看成纵坐标,那么与运算的四种运算可以看成平面上的四个点,如下图所示。
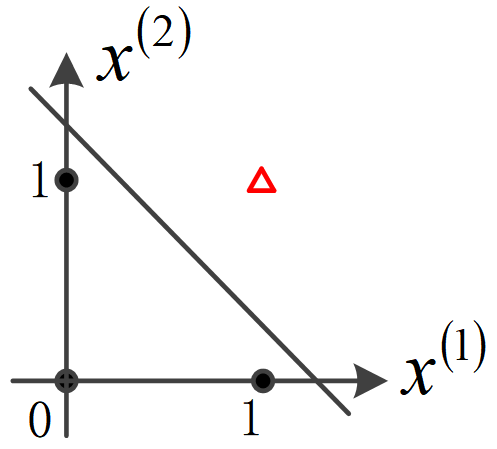
图中,取值1的点用红三角表示,取值0的点用黑点表示。显然这四个点可以用图中所示的直线来按类分开,这条直线可以起到模拟与运算的作用。上节讨论过神经元可以做到线性分类,因此可以设计如下的神经元来代表图中的直线:
它是将一个两输入的神经元的连接系数都设为1,将阈值系数设为-1.5,将该神经元画出来如下图所示。
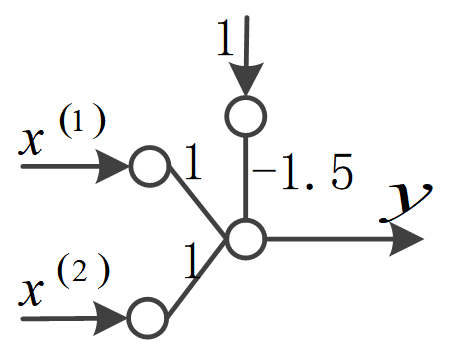
因此,该神经元可以模拟逻辑代数中的与运算。例如,当输入取值0和1时:
读者可以验算其他三组输入时的输出是否正确。
实际上,逻辑代数的与、或、非三个基本运算都是线性可分的,因此都可以用神经元来模拟,如下图所示。
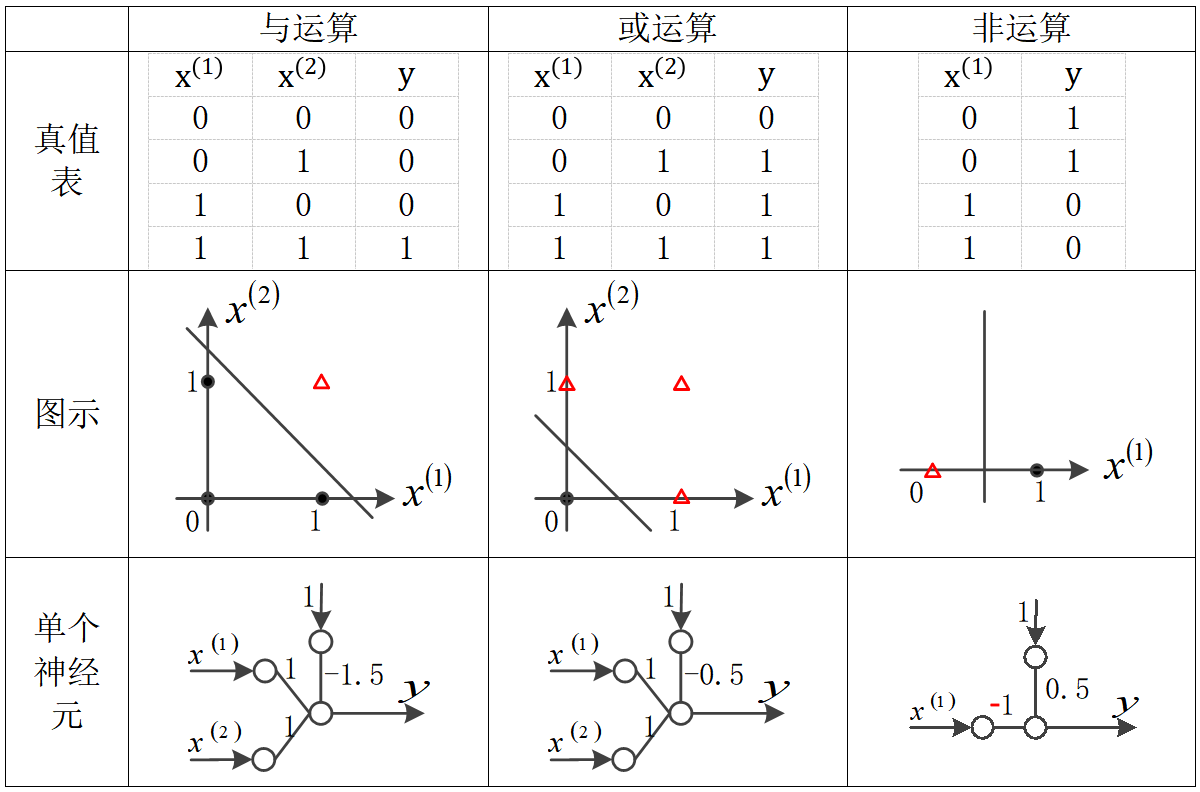
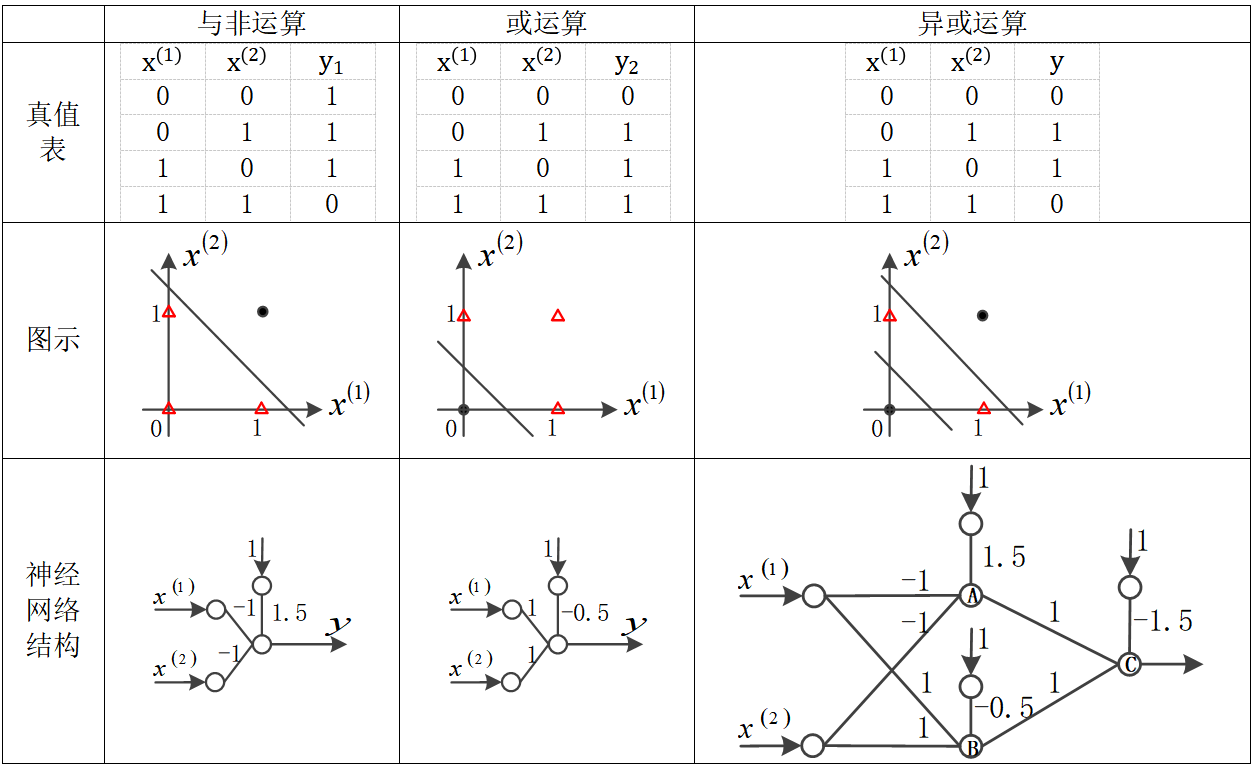
异或运算的真值表、图示如下图最右栏所示,显然它是线性不可分的,因此无法用一个神经元来模拟。此时,可以用三个分别模拟与非运算、或运算和与运算的神经元相互连接起来实现模拟,如下图最右栏最下格所示,其中神经元A模拟了与非运算,神经元B模拟了或运算,神经元C模拟了与运算。神经元A和B都接收输入和
,它们的输出都输入到神经元C,神经元C的输出为最终模拟结果。这三个神经元组成了一个神经网络来完成线性不可分的模拟异或运算任务,它相当于在平面上划了两条直线,两条直线所夹部分为一个类别,其余部分为一个类别。读者可以验算一下模拟是否正确。
从该例子可见,把神经元相互连接而成神经网络可以获得非常重要的非线性处理能力。
理论上,可以通过将神经元的输出连接到另外神经元的输入而形成任意结构的神经网络。目前,复杂神经网络的结构设计还没有完全有效的理论指导,不同结构的神经网络在功用方面的差别还没有完备的理论可以用来进行分析。当前,复杂神经网络的结构设计,主要还是靠经验指导和试验摸索。目前,人们摸索较多且得到广泛应用的是所谓层状结构的神经网络,如下图所示。
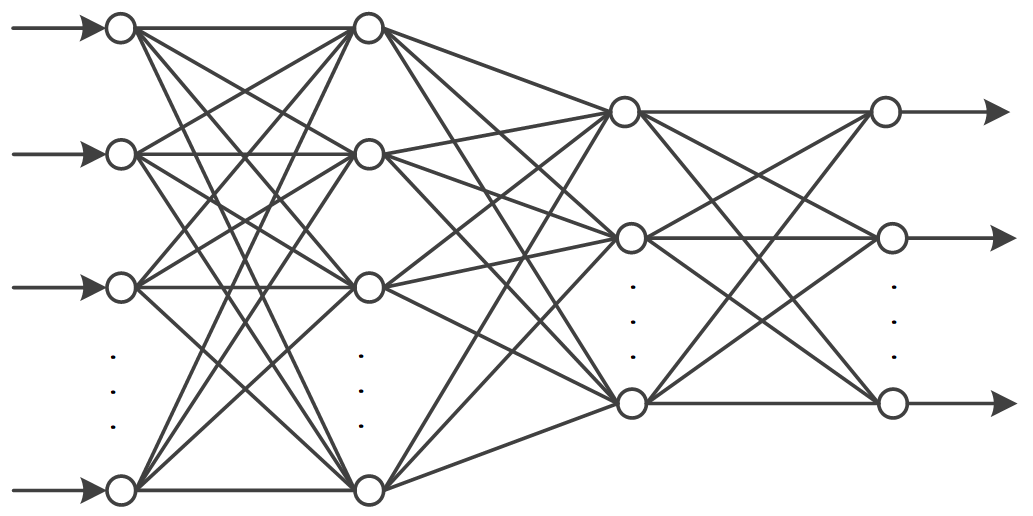
层状结构由输入层、隐层和输出层构成,其中可以有多个隐层。
层状结构神经网络的层数按实际层次的数量来计算,如前述模拟异或运算的神经网络为3层神经网络。神经网络的第一层为输入层,不具备信息处理能力,其他层为隐层,具有信息处理能力,最后的隐层也称为输出层。
从信息处理方向来看,神经网络分为前馈型和反馈型两类。前馈型网络的信息处理方向是从输入层到输出层逐层前向传递。输入层只接收信息,隐层和输出层具有处理信息的能力。相邻层之间的节点是全连接关系,同层节点、跨层节点之间没有连接关系。有些特别设计的前馈神经网络会在个别同层节点之间或者个别跨层节点之间引入连接关系,如深度学习中的残差网络。
反馈型网络中存在信息处理反向传递,即存在从前面层到后面层的反向连接。反向传递会使得信息处理过程变得非常复杂,难以控制。
神经网络模型的难点除了神经网络的结构设计问题外,还有它的参数值(每个神经元的连接系数和阈值系数的值)的确定问题。上述模拟异或运算的示例中,神经网络仅由三个神经元构成,共9个参数,因此可以通过人工“试”出来。这里要说明的是,模拟示例中的参数值不是唯一的。
但是随着神经网络的发展,参数越来越多,仅靠人工“试”就成了不可能完成的任务。实际上,无法自动确定参数,是长时间困扰神经网络发展的拦路虎,该问题直到以梯度下降优化算法为基础的反向传播学习算法发明后才得以解决,从而为深度学习的大发展奠定了基础。本文的后续两篇文章将深入讨论通过样本训练来确定神经网络参数的方法。
3 损失函数
上面通过模拟逻辑运算来说明了神经网络的非线性处理能力,这里仍然利用它来说明损失函数的概念。下图给出了四个用来模拟与运算的M-P神经元,它们分别会出现0个或多个错误,例如,对第1个神经元来说,当输入0,1时,会输出错误的1;对第2个神经元来说,当输入0,1和1,0时,都会输出错误的1。
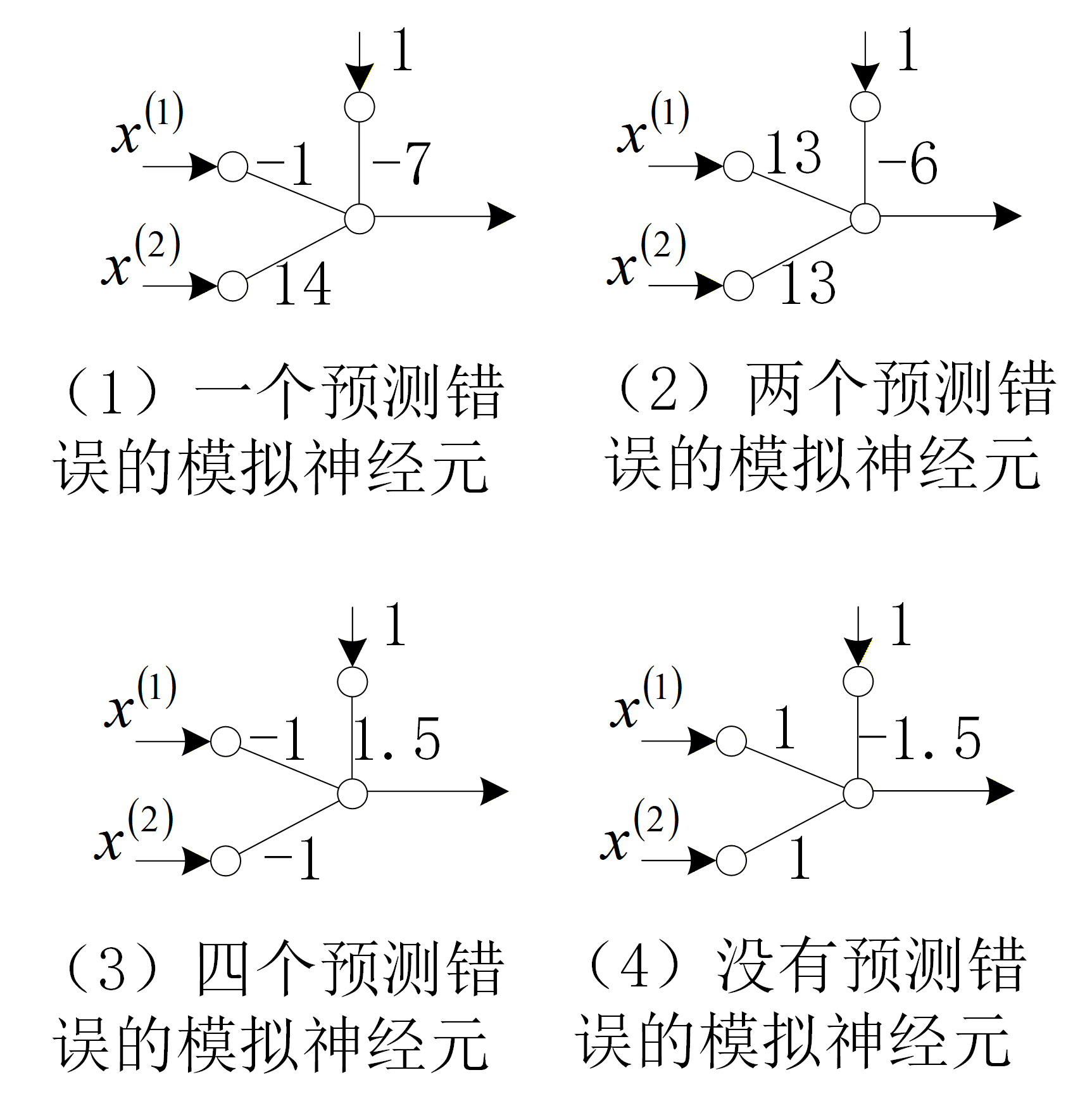
直观认为第4个神经元模拟的最“好”,第1个次之,第3个最“差”。如何用数量来描述这种“好”和“差”的程度呢?显然,可以用每个模型对输入样本出错的次数之和来衡量。定义一个函数用来记录所有的4个样本预测出错的次数:
式中,表示样本集合,
和
分别表示第
个样本的标签值和预测值,
表示指示函数(indicator function),即
时值为1,否则为0。
显然上面定义的样本集上的函数刻画了模型出错的次数。该函数取值越小,表明模型的预测能力越强,因此,可以把求得该函数的最小值作为优化模型的目标。该函数称为损失函数(loss function)或代价函数(cost function)。
损失函数并不唯一,就本节示例的模型而言,下面利用求绝对值的损失函数可以起到相同的作用:
或者利用求平方的损失函数:
损失函数体现了模型优化的目标,设计出一个“好”的损失函数将会有利于进行对模型的优化工作。
有关损失函数更详细的内容将在后续文章中逐步讨论。这里先介绍几个最常见的损失函数。
上面式子中的表示标签的真实值和预测值的差值的绝对值,称为残差,也称为绝对误差(Absolute Loss)。
残差平方称为误差平方(Squared Loss)。误差平方对后续求导等计算比较方便,因此常采用所有样本的误差平方和(Sum of Squared Error, SSE)作为损失函数来评价模型。
还经常采用均方误差(Mean of Squared Error, MSE)作为损失函数,它是误差平方和除以样本总数得到。
4 迭代法
在求解机器学习模型(含深度学习模型)时,梯度下降法是最通用的最优化方法。本节先讨论梯度下降法的基础:迭代法。
迭代法(iteration)是现代计算机求解问题的一种基本形式。迭代法是一种算法,更是一种思想,它不像传统数学解析方法那样一步到位得到精确解,而是步步为营,逐次推进,逐步接近。迭代法又称辗转法或逐次逼近法。
迭代法的核心是建立迭代关系式。迭代关系式指明了前进的方式,只有正确的迭代关系式才能取得正确解。
来看一个示例。假设在空池塘中放入一颗水藻,该类水藻会每周长出三颗新的水藻,问十周后,池塘中有多少颗水藻?
该问题可以用数学方法来直接计算。这里来看看如何用迭代法求解。
第1周的水藻数量:1;
第2周的水藻数量:;
第3周的水藻数量:;
…
可以归纳出从当前周水藻数量到下一周水藻数量的迭代关系式。设上周水藻数量为,从上周到本周水藻将增加的数量为
,本周的水藻数量为
,那么在一次迭代中:
迭代开始时,水藻的数量为1,为迭代法的初始条件。
迭代次数为9(不包括第一周),为迭代过程的控制条件。
该示例实现的代码见代码3-1,迭代过程共循环9次,用while语句来循环实现迭代,一般用一轮循环来实现一次迭代。读者可以自己尝试改用for语句方式来实现迭代。
代码 3-1 迭代法应用示例1
x = 1 # 初始条件:第一周水藻数量 times = 1 # 迭代次数 while times < 10: # 迭代过程 y = 3 * x x = x + y times += 1 print("第%d周的水藻数量:%d" % (times, x)) #>>> 第2周的水藻数量:4 #>>> 第3周的水藻数量:16 #>>> 第4周的水藻数量:64 #>>> 第5周的水藻数量:256 #>>> 第6周的水藻数量:1024 #>>> 第7周的水藻数量:4096 #>>> 第8周的水藻数量:16384 #>>> 第9周的水藻数量:65536 #>>> 第10周的水藻数量:262144
迭代法是求解机器学习问题的基本方法,有着广泛的应用,本小节先用解方程的例子来说明它在数值计算领域的应用,为后续讨论梯度下降法打下基础。
用迭代法求解方程,有个常用的迭代关系式建立方法。假设每次迭代都得到一个新的值,将每次迭代得到的
值依序排列就可得到数列
。设
为数列初值。迭代关系式建立方法是先将方程
变换为
,然后得到迭代关系式:
例如用迭代法求下列方程时的迭代关系为:
迭代的结束条件是实际应用时需要考虑的问题,在该例中没有明确的结束条件。在无法预估时,可采用控制总的迭代次数的办法。也可以根据数列的变化情况来判断,如将
的值小于某个较小的阈值作为结束的标准。还可以将两种办法结合使用。
用迭代法求解方程的示例代码如代码3-2所示。该示例采用控制总的迭代次数作为结束的条件。这里将初始值设为0,读者可以设为其他值来观察一下迭代过程,要注意的是,不同的初始值可能会导致数列不收敛。
代码3-2 迭代法应用示例2
import math x = 0 # 初始条件 for i in range(100): # 控制总的迭代次数 x = (6 - x**3 - (math.e**x)/2.0)/5.0 print(str(i)+":"+str(x)) #>>> 0:1.1 #>>> 1:0.6333833976053566 #>>> 2:0.9607831386993697 #>>> 3:0.7612451427547097 #>>> 4:0.8976785421774022 #>>> ... #>>> 26:0.8459280589817704 #>>> 27:0.8459178119620006 #>>> 28:0.8459245992200859 #>>> 29:0.8459201035986089 #>>> 30:0.8459230813336305
运行结果显示从28次迭代开始,收敛于0.84592。
第1行导入了math库,并在第4行使用了它的指数函数。
math库包含丰富的数学函数,如果内置函数库不够用时,可以到math库中去找合适的数学函数。
代码 3-3给出了更常用的采用阈值来控制迭代结束的示例,如果相邻两次迭代的差值小于指定的delta,则通过break语句退出迭代。
代码3-3 迭代法应用示例3
x = 0 # 初始条件 delta = 0.00001 # 控制退出条件 times = 0 # 用来显示迭代次数 while True: # 条件为True,如果没有别的退出手段,while循环将会无限进行下去 x_old = x x = (6 - x**3 - (math.e**x)/2.0)/5.0 print(str(times)+":"+str(x)) times += 1 if abs(x - x_old) < delta: break # 如果符合退出条件,则直接退出循环 #>>> 0:1.1 #>>> 1:0.6333833976053566 #>>> 2:0.9607831386993697 #>>> 3:0.7612451427547097 #>>> 4:0.8976785421774022 #>>> 5:0.8099353339786866 #>>> ... #>>> 26:0.8459280589817704 #>>> 27:0.8459178119620006 #>>> 28:0.8459245992200859
运行结果显示在第28次循环退出迭代。

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









