







 该专栏为热销专栏榜 第4名
该专栏为热销专栏榜 第4名一、本文介绍
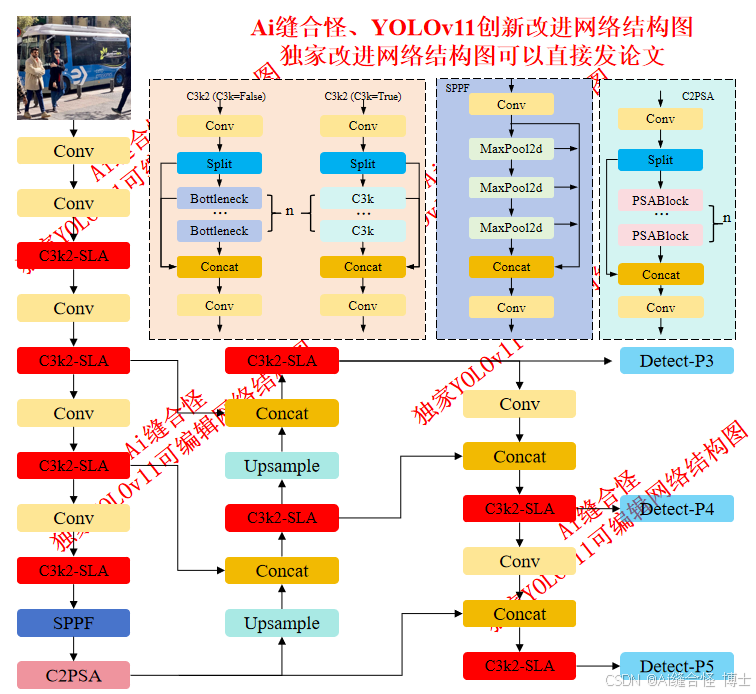
🔥本文给大家介绍利用SLAB模块通过简化线性注意力(SLA)和渐进式重新参数化批量归一化(PRepBN)改进YOLOv11,提高了计算效率和精度。SLA减少了计算复杂度,提升了推理速度,PRepBN则通过逐步替换LayerNorm为BatchNorm,降低了推理延迟。SLAB模块使YOLOv11在保持高精度的同时,提升了推理效率,适用于实时目标检测、图像分类、图像分割。
展示部分YOLOv11改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov11n_C3k2_SLA.yaml
专栏改进目录:YOLOv11改进专栏包含卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、C2PSA/C3k2二次创新改进、全网独家创新等创新点改进
全新YOLOv11-发论文改进专栏链接:全新YOLOv11创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进1: yolov11n_SLAttention.yaml
🚀 创新改进2: yolov11n_C3k2_SLA.yaml
二、SLAB 模块介绍

摘要:transformer架构已成为自然语言处理和计算机视觉任务的基础架构。然而,高昂的计算成本使其在资源受限设备上的部署面临巨大挑战。本文针对高效transformer中的计算瓶颈模块——归一化层和注意力模块展开研究。虽然LayerNorm是transformer架构中的常用技术,但由于推理阶段需要进行统计计算,其计算效率并不理想。但若直接用更高效的批量归一化(BatchNorm)替代LayerNorm,往往会导致性能下降甚至训练崩溃。为解决这一问题,我们提出了一种名为PRepBN的新方法,通过逐步用重参数化批量归一化(BatchNorm)替代训练阶段的LayerNorm。此外,我们还开发了简化的线性注意力(SLA)模块,该模块结构简洁却能实现优异性能。大量图像分类和目标检测实验验证了本方法的有效性:例如,我们的SLAB-Swin模型在ImageNet-1K数据集上以16.2毫秒延迟获得83.6%的top-1准确率,比Flatten-Swin模型低2.4毫秒且准确率仅高

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









