







 该专栏为热销专栏榜 第4名
该专栏为热销专栏榜 第4名一、本文介绍
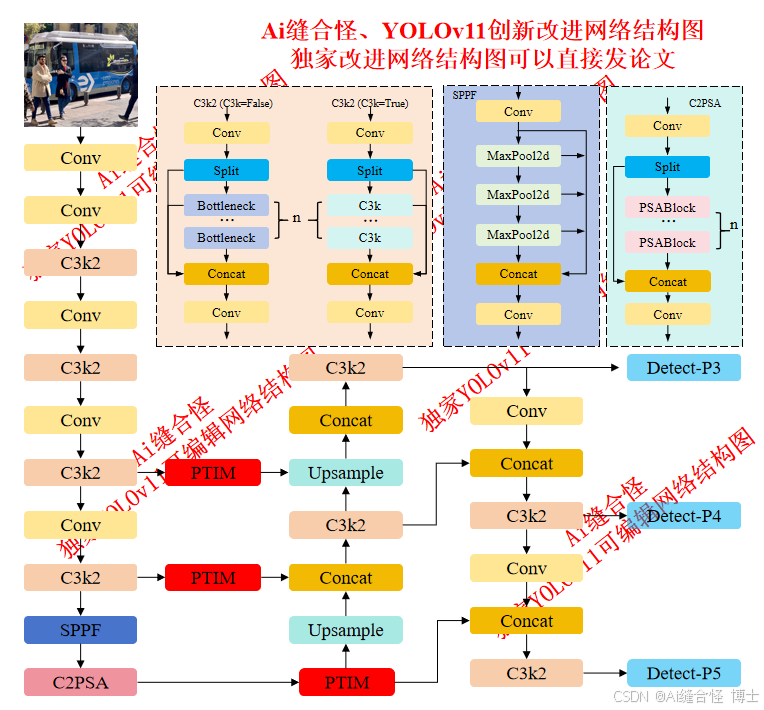
🔥本文给大家介绍利用PTIM模块改进YOLOv11网络模型。PTIM增强了长程依赖建模和全局上下文信息的捕捉,使得YOLOv11在复杂背景和小目标检测中表现更为精准。PTIM通过在高度、宽度和通道维度上进行标记交互,提升了目标与背景的区分能力,特别是在目标和背景对比不明显的情况下。同时,它保持了计算效率,避免了Transformer方法的高计算开销,确保了实时检测任务中的高效性。PTIM的引入使YOLOv11在小目标检测和复杂场景中的精度大幅提高,同时减少了误报和漏报。
展示部分YOLOv11改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov11n_PTIM.yaml
专栏改进目录:YOLOv11改进专栏包含卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、C2PSA/C3k2二次创新改进、全网独家创新等创新点改进
全新YOLOv11-发论文改进专栏链接:全新YOLOv11创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进3: yolov11n_C3k2_PTIM.yaml
二、PTIM模块介绍

摘要:红外小目标检测(IRSTD)面临诸多挑战,包括远距离、弱特征和小尺度等难题。虽然基于卷积神经网络(CNN)的方法已取得进展,但其固有的局部化倾向限制了全局解析能力。而基于Transformer的方法虽能捕捉长距离依赖关系,却因二次复杂度导致计算效率低下。为突破这些瓶颈,本文提出了一种新型多层感知器(MLP)融合网络——MLP-Net,专为IRSTD设计。该架构融合CNN与MLP的优势,既能从局部特征中提取全局语义信息,又显著提升了特征表征质量。我们还开发了并行标记交互混频器(PTIM),通过在MLP的高度、宽度和通道维度上引入方向特定的交互信息,动态增强长距离依赖建模能力。此外,我们设计了上下文选择融合模块(CSFM),实现从粗到细的高级语义与细节信息逐步聚合。该模块整合不同层级的互补特性,有效提升检测精度。最终,针对NUAA-SIRST、NUDT-SIRST和IRSTD-1K三大基准测试的全面实验表明,所提出的MLP-Net检测性能

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









