





在神经网络的世界里,矩阵运算如同隐藏在背后的强大引擎,推动着整个网络的高效运行。
从输入数据的处理到权重的更新,从前向传播到反向传播,矩阵运算贯穿了神经网络的每一个环节。
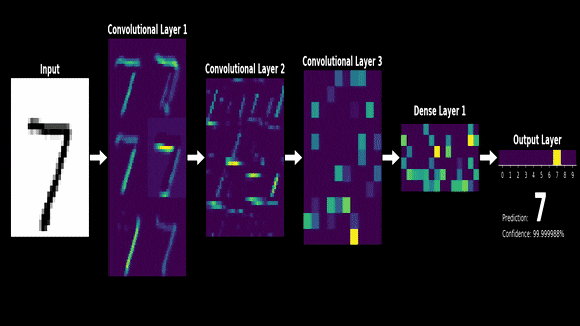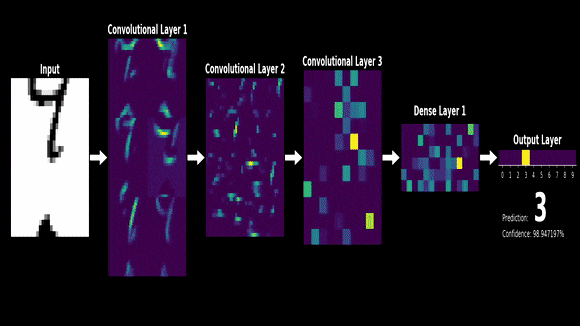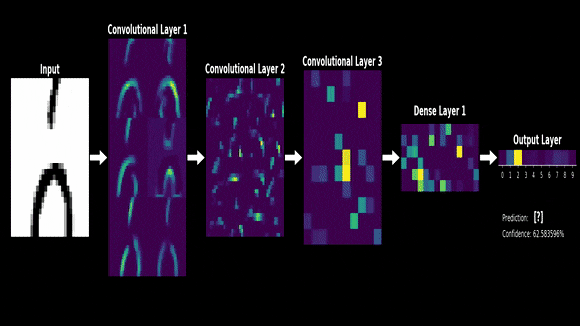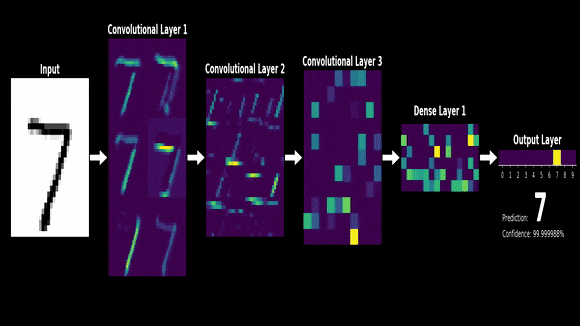
今天,就让我们走进神经网络的基石,一起探索矩阵运算的魅力。
一、神经网络中的矩阵表示
神经网络作为一种强大的计算模型,在人工智能和机器学习领域扮演着至关重要的角色。
其核心机制在于神经元之间的连接以及信息的传递。

从数学的角度来看,这些连接和信息传递(如数据、权重和偏置)过程可以通过矩阵和向量的运算来高效地表示和计算。
矩阵运算不仅简化了神经网络的计算过程,还提高了计算效率。
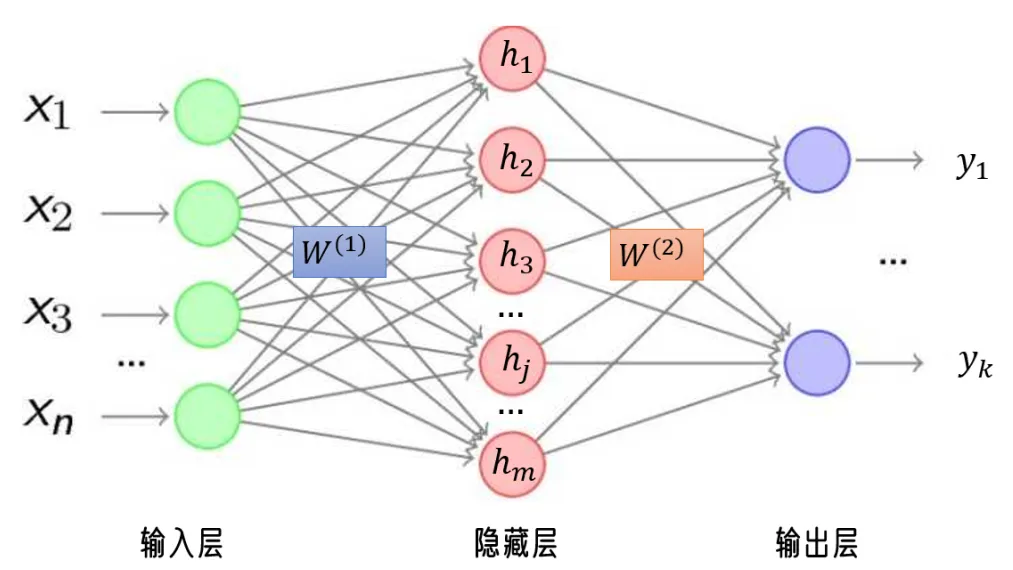
假设我们有一个简单的神经网络,包含一个输入层、一个隐藏层和一个输出层。
-
输入层有 nnn 个神经元,隐藏层有 mmm 个神经元,输出层有 kkk 个神经元。
-
输入向量 x\mathbf{x}x 是一个 nnn-维向量,表示输入数据。
-
隐藏层的权重矩阵 W(1)\mathbf{W}^{(1)}W(1) 是一个 m×nm \times nm×n 的矩阵,表示输入层到隐藏层的连接权重。隐藏层的输出向量 h\mathbf{h}h 是一个 mmm-维向量,表示隐藏层的输出。
-
输出层的权重矩阵 W(2)\mathbf{W}^{(2)}W(2) 是一个 k×mk \times mk×m 的矩阵,表示隐藏层到输出层的连接权重。输出层的输出向量 y\mathbf{y}y 是一个 kkk-维向量,表示最终的输出结果。
二、矩阵乘法在神经网络中的应用
矩阵乘法是神经网络中最重要的运算之一。
它不仅用于前向传播,还用于反向传播中的梯度计算。

矩阵乘法的高效性使得神经网络能够在大规模数据上进行快速计算。
2.1 前向传播中的矩阵乘法
在前向传播过程中,输入数据通过每一层的权重矩阵和激活函数逐步传递到输出层。
每一层的计算都可以表示为矩阵乘法和向量加法的形式。
例如,从输入层到隐藏层的计算可以表示为:
z(1)=W(1)x+b(1)
z^{(1)} = W^{(1)}x + b^{(1)}
z(1)=W(1)x+b(1)
a(1)=f(z(1))
a^{(1)} = f(z^{(1)})
a(1)=f(z(1))
从隐藏层到输出层的计算可以表示为:
z(2)=W(2)a(1)+b(2)
z^{(2)} = W^{(2)}a^{(1)} + b^{(2)}
z(2)=W(2)a(1)+b(2)
a(2)=f(z(2))
a^{(2)} = f(z^{(2)})
a(2)=f(z(2))
2.2 反向传播中的矩阵乘法
在反向传播过程中,梯度计算也依赖于矩阵乘法。
假设损失函数为 ,我们需要计算损失函数对每个权重的梯度。
根据链式法则,损失函数对权重矩阵 W(2)W^{(2)}W(2) 的梯度可以表示为:
∂L∂W(2)=∂L∂z(2)⋅∂z(2)∂W(2) \frac{\partial \mathcal{L}}{\partial W^{(2)}} = \frac{\partial \mathcal{L}}{\partial z^{(2)}} \cdot \frac{\partial z^{(2)}}{\partial W^{(2)}} ∂W(2)∂L=∂z(2)∂L⋅∂W(2)∂z(2)
式中,∂L∂z(2)\frac{\partial \mathcal{L}}{\partial z^{(2)}}∂z(2)∂L 是损失函数对输出层输入的梯度,维度为 k×1k \times 1k×1;∂z(2)∂W(2)\frac{\partial z^{(2)}}{\partial W^{(2)}}∂W(2)∂z(2) 是输出层输入对权重矩阵的导数,维度为 k×mk \times mk×m。
因此,损失函数对权重矩阵 W(2)W^{(2)}W(2) 的梯度可以通过矩阵乘法得到:
∂L∂W(2)=∂L∂z(2)⋅(a(1))T \frac{\partial \mathcal{L}}{\partial W^{(2)}} = \frac{\partial \mathcal{L}}{\partial z^{(2)}} \cdot (a^{(1)})^T ∂W(2)∂L=∂z(2)∂L⋅(a(1))T
类似地,损失函数对权重矩阵 W(1)W^{(1)}W(1) 的梯度可以通过矩阵乘法得到:
∂L∂W(1)=∂L∂z(1)⋅(x)T \frac{\partial \mathcal{L}}{\partial W^{(1)}} = \frac{\partial \mathcal{L}}{\partial z^{(1)}} \cdot (x)^T ∂W(1)∂L=∂z(1)∂L⋅(x)T
三、矩阵运算的优化技巧
矩阵运算是神经网络中最耗时的部分之一,尤其是在处理大规模数据和深度网络时。
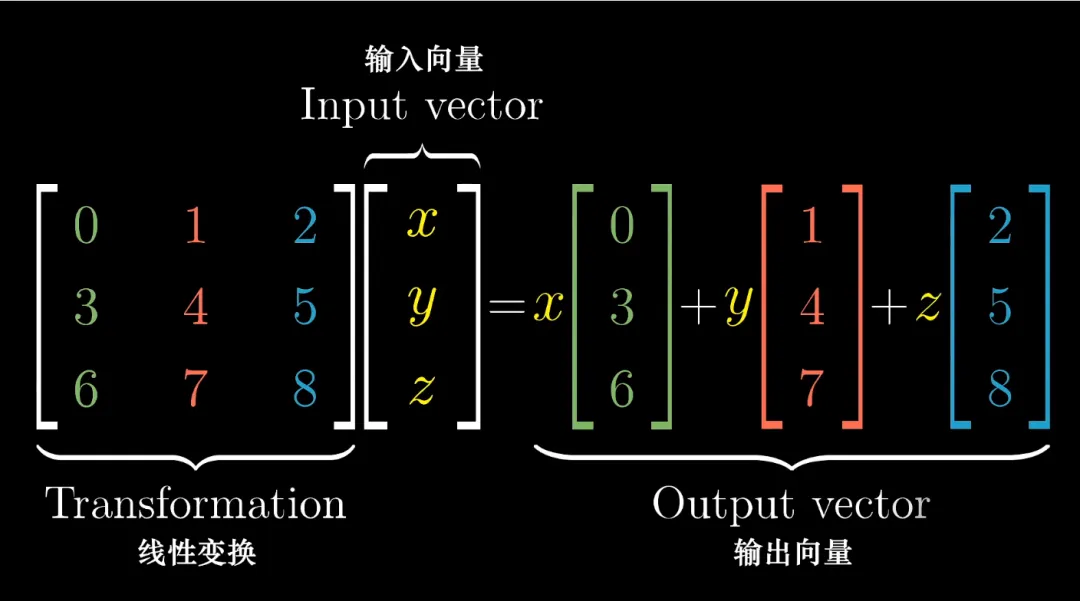
因此,优化矩阵运算对于提高神经网络的效率至关重要。以下是一些常见的优化技巧:
3.1 矩阵的转置
矩阵的转置是矩阵运算中常用的操作之一。在神经网络中,矩阵的转置通常用于计算梯度。

例如,在反向传播过程中,我们需要计算损失函数对权重矩阵的梯度,这通常涉及到矩阵的转置运算。
假设我们有一个矩阵 A\mathbf{A}A,其转置矩阵 AT\mathbf{A}^TAT 是将 A\mathbf{A}A 的行和列互换得到的矩阵。
在神经网络中,矩阵的转置运算可以用于优化梯度计算。例如,损失函数对权重矩阵 W(2)\mathbf{W}^{(2)}W(2) 的梯度可以表示为:
∂L∂W(2)=∂L∂z(2)⋅hT \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(2)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{z}^{(2)}} \cdot \mathbf{h}^T ∂W(2)∂L=∂z(2)∂L⋅hT
式中,hT\mathbf{h}^ThT 是隐藏层输出向量的转置。
3.2 矩阵的 “逆”
矩阵的逆是矩阵运算中的另一个重要概念。在神经网络中,矩阵的逆通常用于优化算法。
例如,在线性回归中,我们可以通过计算矩阵的逆来求解最优权重。
假设我们有一个矩阵 A\mathbf{A}A,其逆矩阵 A−1\mathbf{A}^{-1}A−1 是满足以下条件的矩阵:
A⋅A−1=I \mathbf{A} \cdot \mathbf{A}^{-1} = \mathbf{I} A⋅A−1=I
式中,I\mathbf{I}I 是单位矩阵。

在最小二乘法中,我们也可以通过计算矩阵的逆来求解最优权重。
假设我们有一个设计矩阵 X\mathbf{X}X 和目标向量 y\mathbf{y}y,最优权重 w\mathbf{w}w 可以表示为:
w=(XTX)−1XTy \mathbf{w} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} w=(XTX)−1XTy
其中,(XTX)−1(\mathbf{X}^T\mathbf{X})^{-1}(XTX)−1 是矩阵 XTX\mathbf{X}^T\mathbf{X}XTX 的逆矩阵。
3.3 矩阵的分解
矩阵的分解是矩阵运算中的一个重要技巧。在神经网络中,矩阵的分解通常用于优化矩阵运算。
例如,奇异值分解(SVD)可以用于优化矩阵乘法运算。
假设我们有一个矩阵 A\mathbf{A}A,其奇异值分解可以表示为:
A=UΣVT \mathbf{A} = \mathbf{U}\mathbf{\Sigma}\mathbf{V}^T A=UΣVT
式中,U\mathbf{U}U 和 V\mathbf{V}V 是正交矩阵,Σ\mathbf{\Sigma}Σ 是对角矩阵。

在神经网络中,矩阵的分解还可以用于优化矩阵乘法运算。
例如,通过奇异值分解,我们可以将矩阵乘法运算分解为多个简单的矩阵运算,从而提高计算效率。
假设我们有一个矩阵 A\mathbf{A}A 和一个矩阵 B\mathbf{B}B,其乘积可以表示为:
AB=(UΣVT)B=U(Σ(VTB)) \mathbf{AB} = (\mathbf{U}\mathbf{\Sigma}\mathbf{V}^T)\mathbf{B} = \mathbf{U}(\mathbf{\Sigma}(\mathbf{V}^T\mathbf{B})) AB=(UΣVT)B=U(Σ(VTB))
通过这种方式,我们可以将复杂的矩阵乘法运算分解为多个简单的矩阵运算,从而提高计算效率。
在神经网络中,数据通常以向量的形式输入网络,而权重则以矩阵的形式存储。当输入数据通过网络时,每个神经元的输出可以通过输入向量与权重矩阵的乘法运算来计算。
这种矩阵乘法操作不仅简化了计算过程,还大大提高了计算效率,使得神经网络能够在大规模数据集上进行高效的训练和推理。
注:本文中未声明的图片均来源于互联网


















 2406
2406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









