



数据采集监测Youtube等数据有助于进行精准化营销,如何实现呢?
类似于yt-dlp这样的开源爬虫小工具,可能采集少量视频内容时还可以,但它是在有限的IP资源上运行的单点脚本,所以一旦规模化就很容易遇到HTTP 429 (Too Many Requests) 错误。
我之前用过brightdata网页抓取API,类似封装好的数据采集流水线,能自动处理各种反爬技术,或许能支持油管的大数据采集,而且不需要花时间去维。
https://get.brightdata.com/webscra
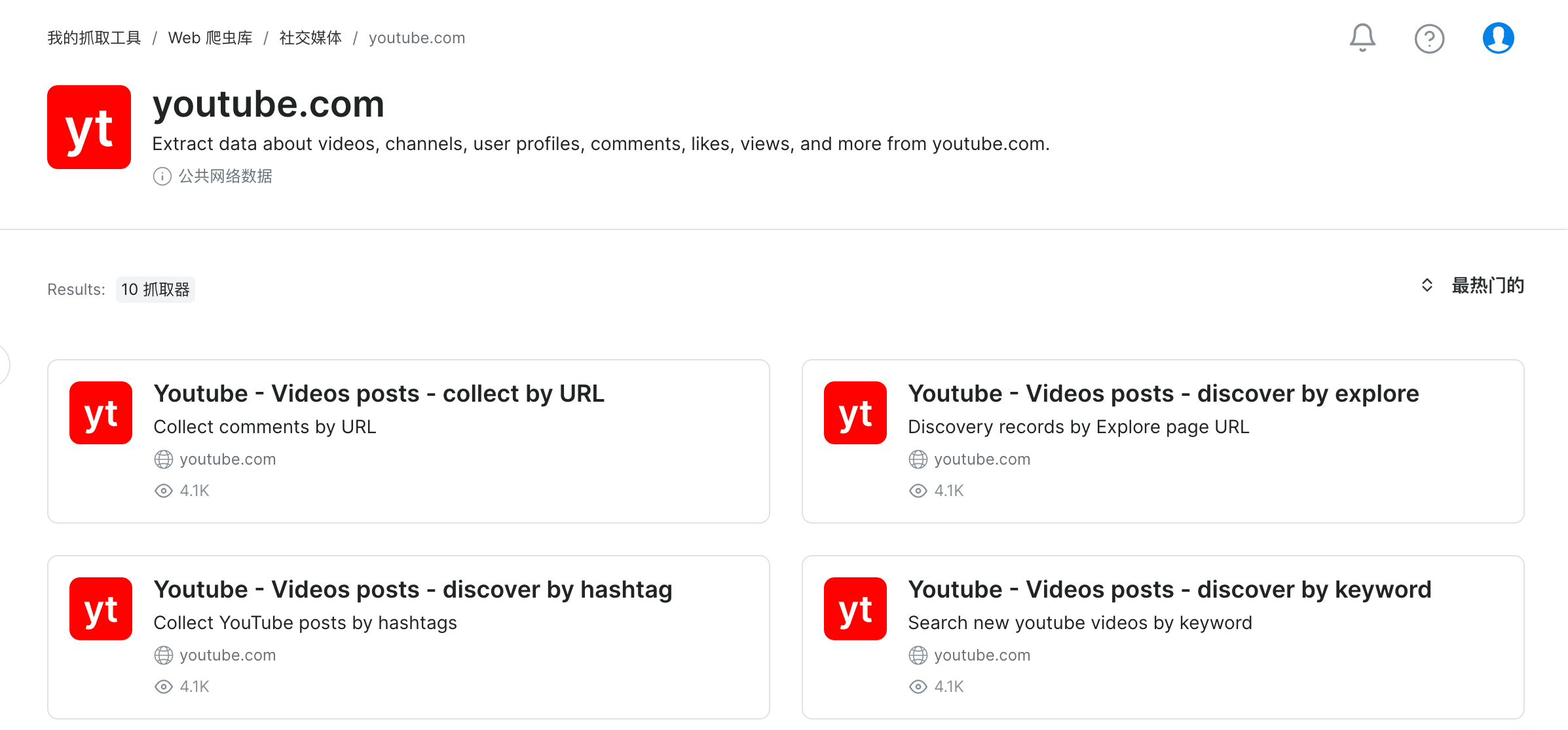
下面讲解下具体的流程,首先需要登录用户控制面板。
然后进入Web Scrapers菜单,这是用来配置网页采集API的功能区,油管采集模板就在这里。
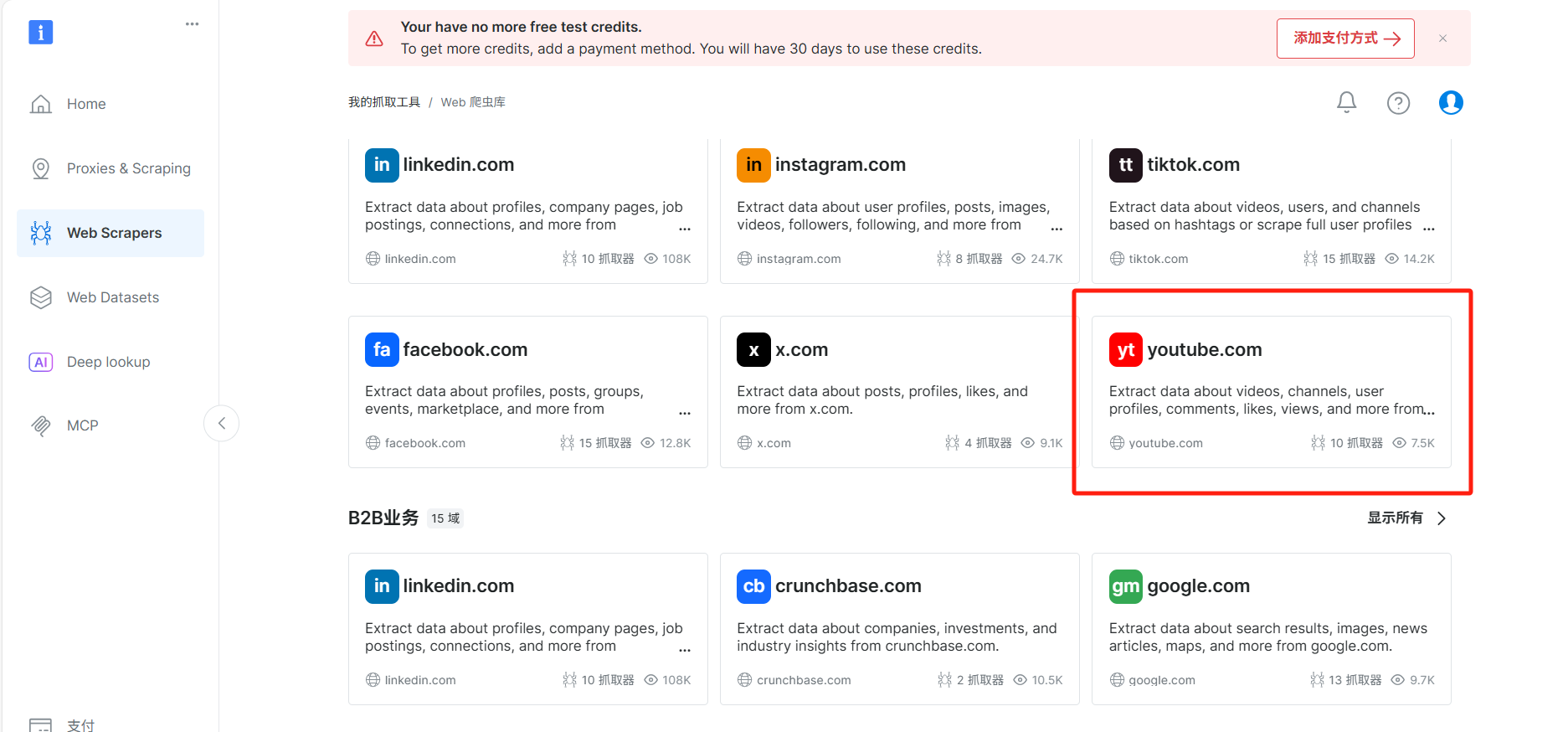
接着进入油管采集页面,里面有各种接口,包括按url采集视频信息及评论,或者按搜索关键词来采集。
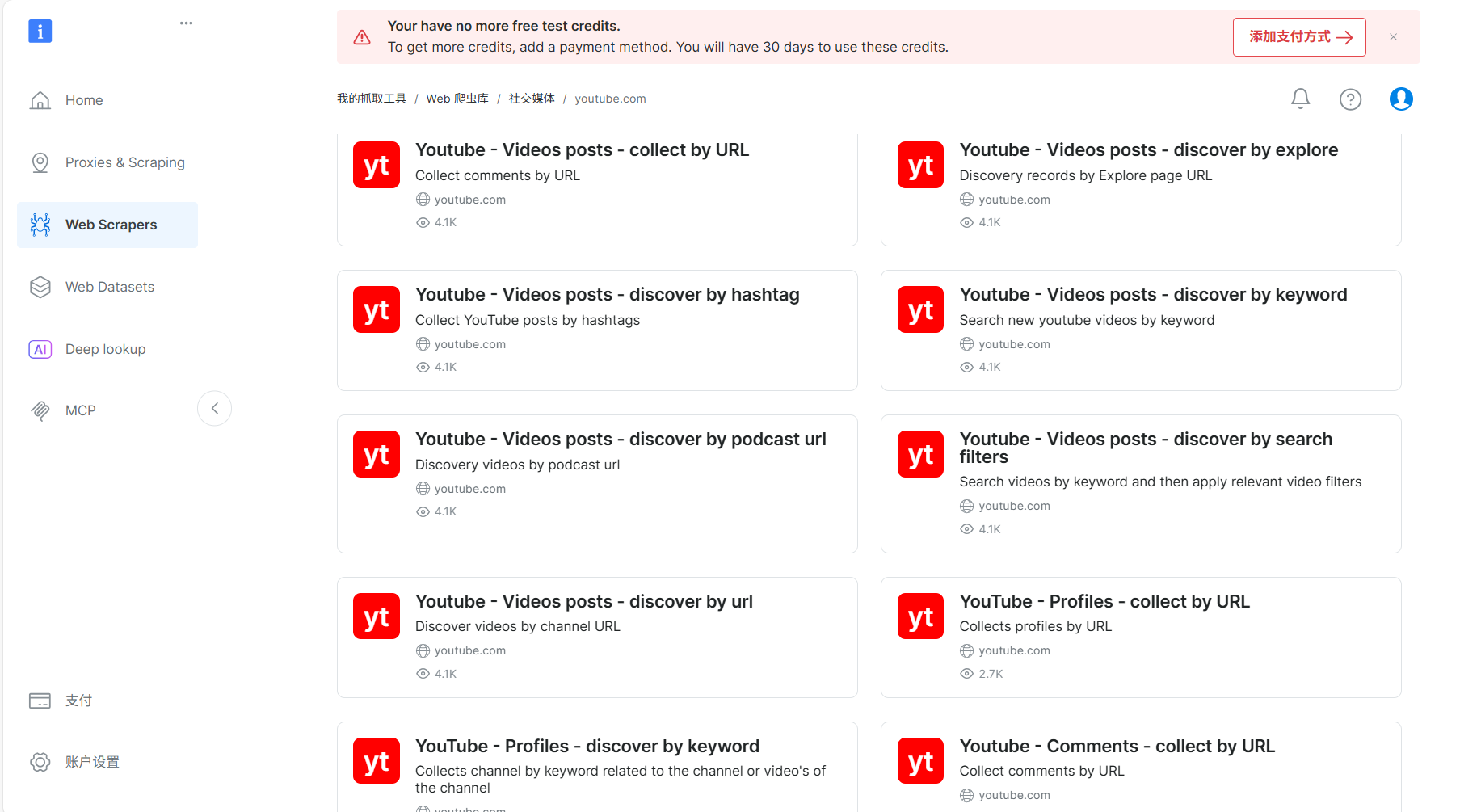
先选择“Youtube - Videos posts - collect by URL”,测试下使用Python requests调用API来采集视频信息。
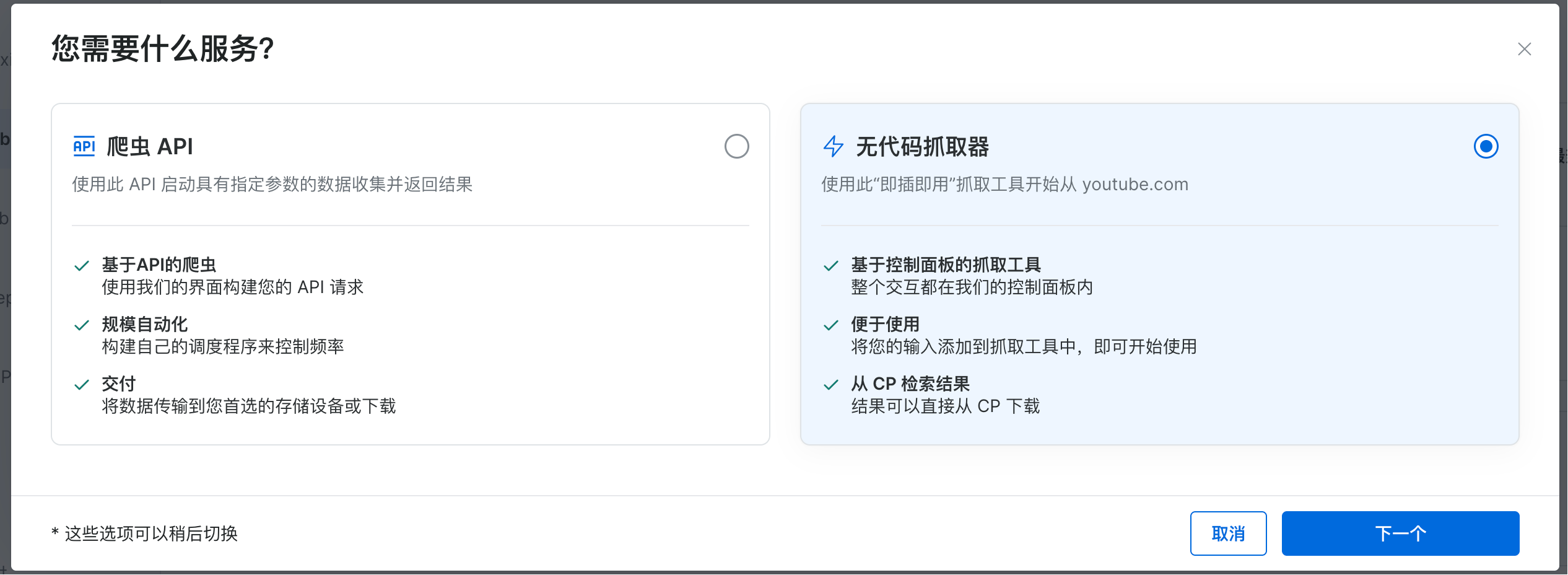
进入到配置页面,你需要配置API请求构建器,一般选择url导入格式为CSV、编程语言为Python即可。
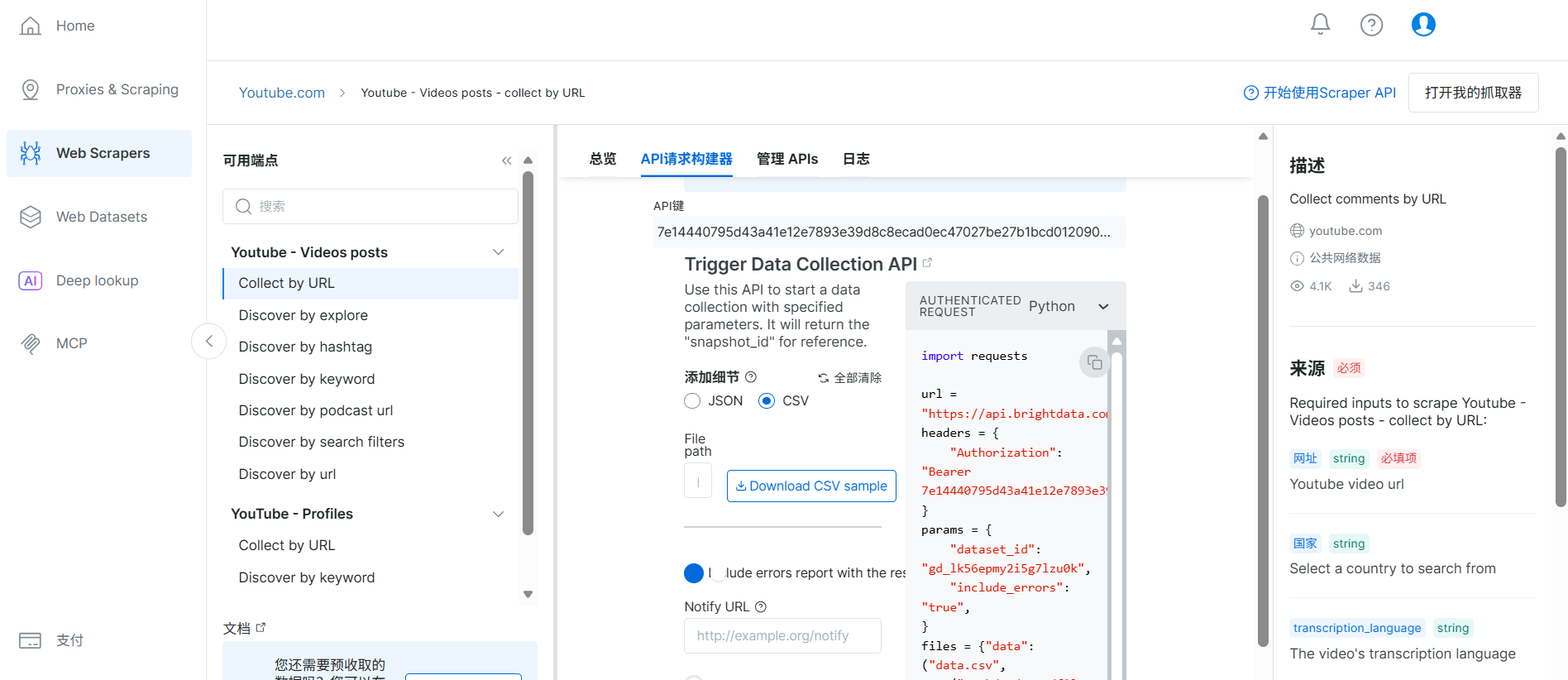
url csv格式如下,里面是要采集的油管视频链接。

这里要把url csv文件地址改成你的本地文件地址,然后把配置好的Python代码复制到Vscode编辑器里,就能开始下载数据了。
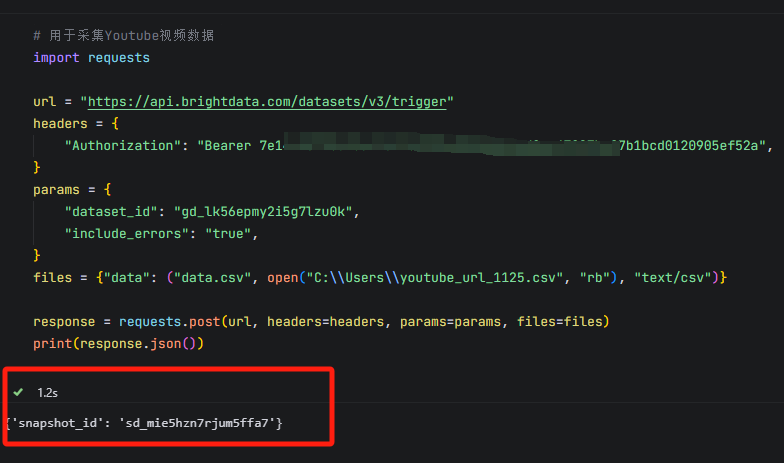
数据采集任务开始后,代码会返回一个snapshot_id,代表采集的数据会保存在亮数据的数据库里,通过特定的snapshot_id可以调用,这一般需要等待几秒钟。
下载好后,就可以去提取数据,我把数据转换为pandas格式,方便查看。
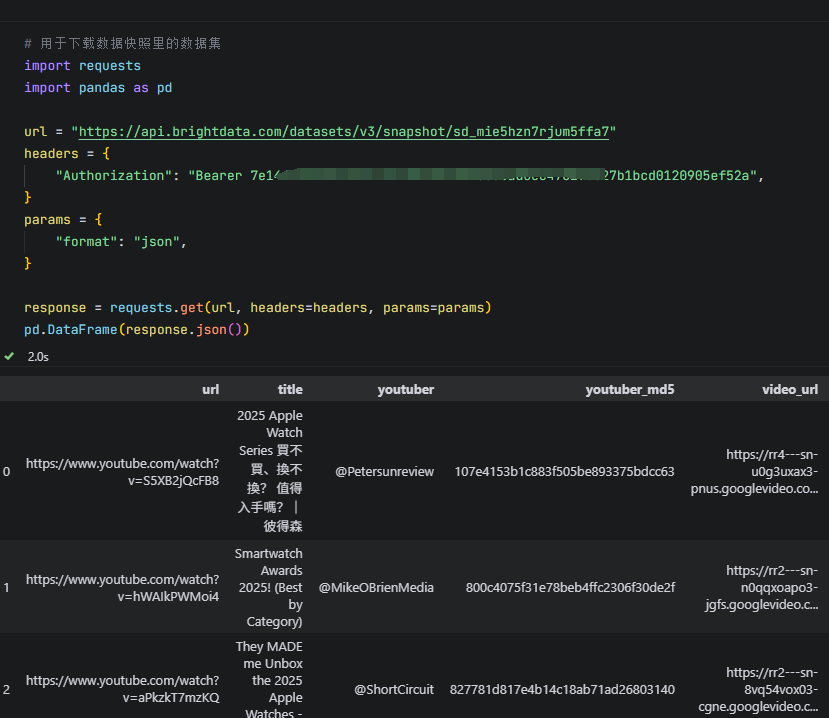
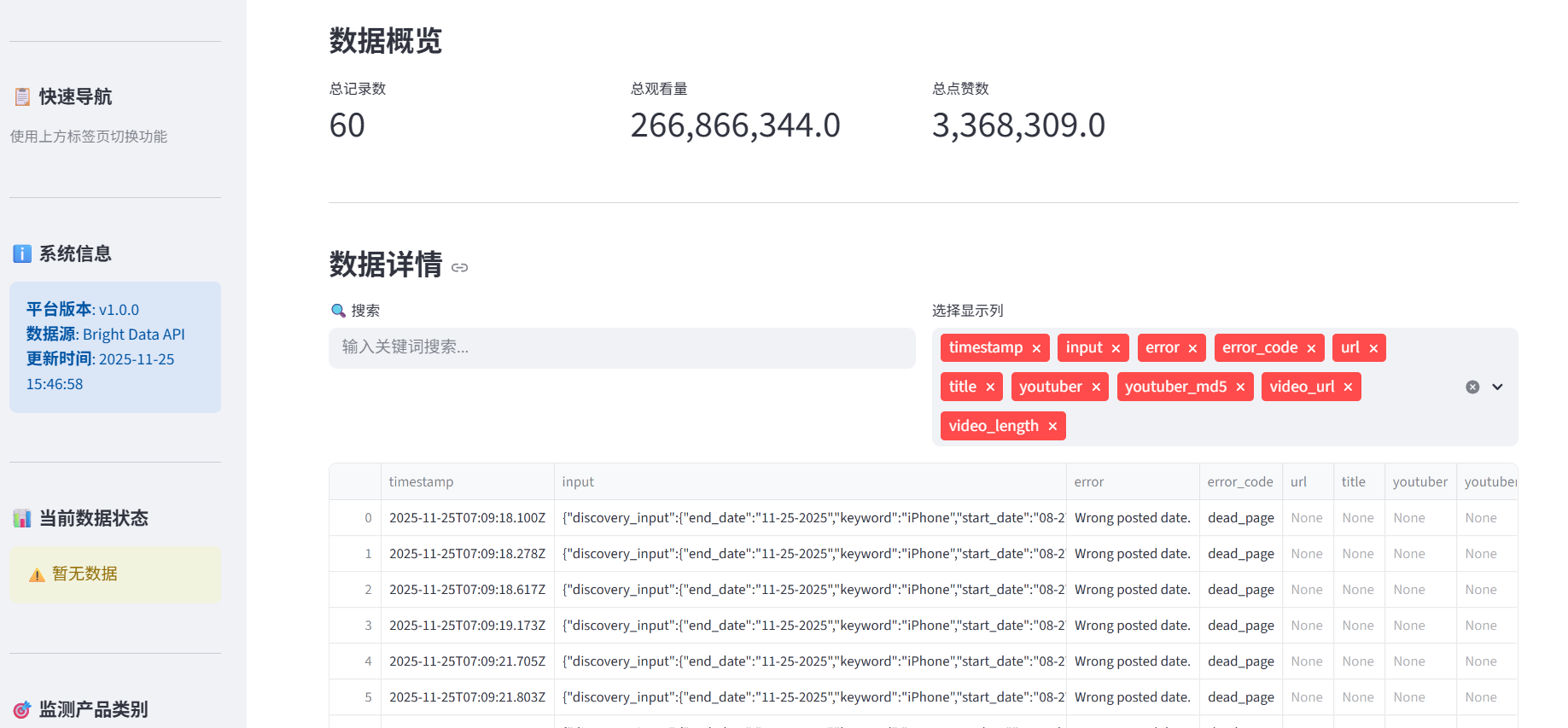
这样咱们就成功采集了3条油管视频的数据详情,包括url、title、youtuber、video_length、views等43个详细字段。
还可以通过Youtube - Comments - collect by URL来下载视频的评论数据,调用方法和上面类似。
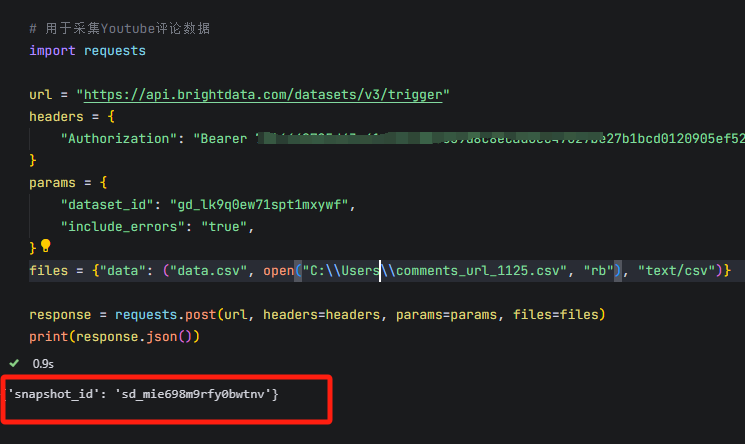
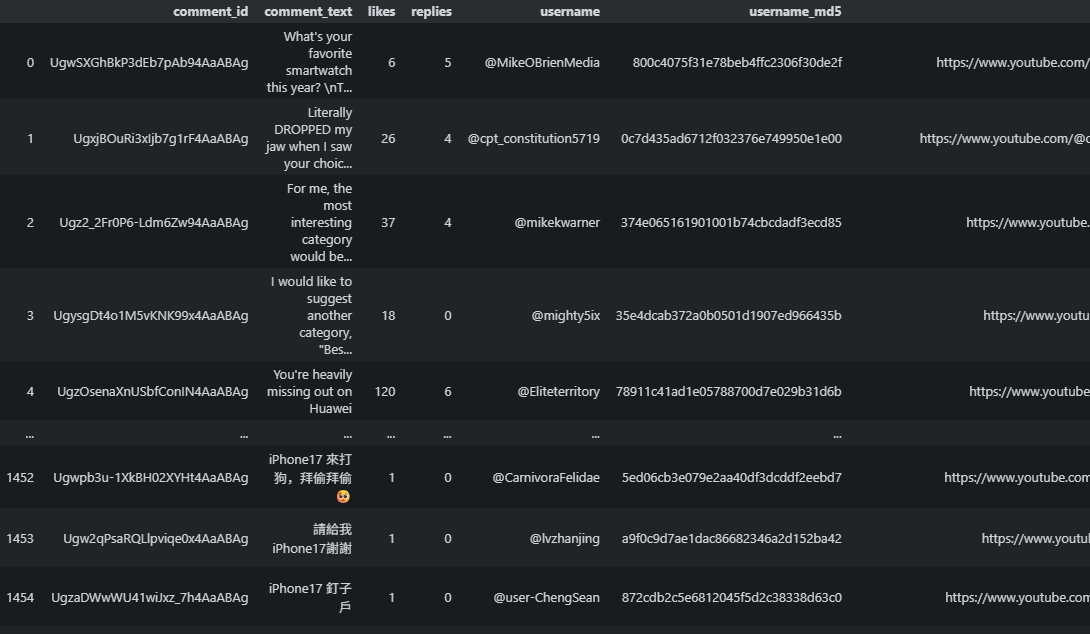
评论数据包含comment_id、comment_text、likes、replies等13个字段,非常详细。
同理,也可以按照关键词搜索来采集Youtube视频数据,比如我们搜索smart phone、smart watch、wireless headphones这三个关键词,结果会返回指定数量和内容的视频信息。
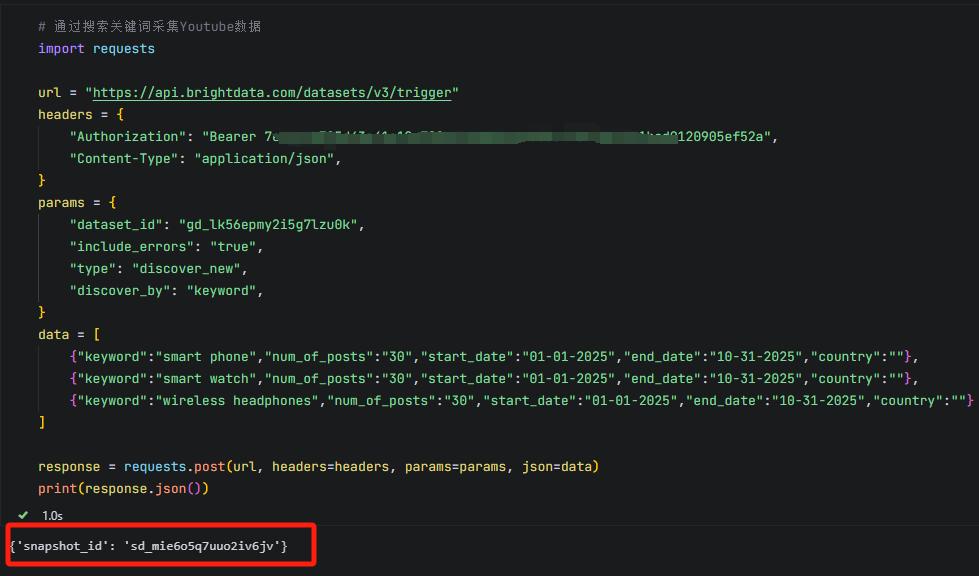

通过以上几个案例,你会发现API把爬虫的复杂过程打包成一个黑盒子,你只需要提交url或者关键词,它就会给你返回数据,不需要担心任何IP限制、人机验证等反爬机制。
如果觉得写代码比较麻烦,你可以尝试将以上的采集API封装到web应用里,通过可视化的界面来采集、分析Youtube数据。
以下是我基于streamlit搭建的应用,所有功能都可以正常使用,且流畅度不错。
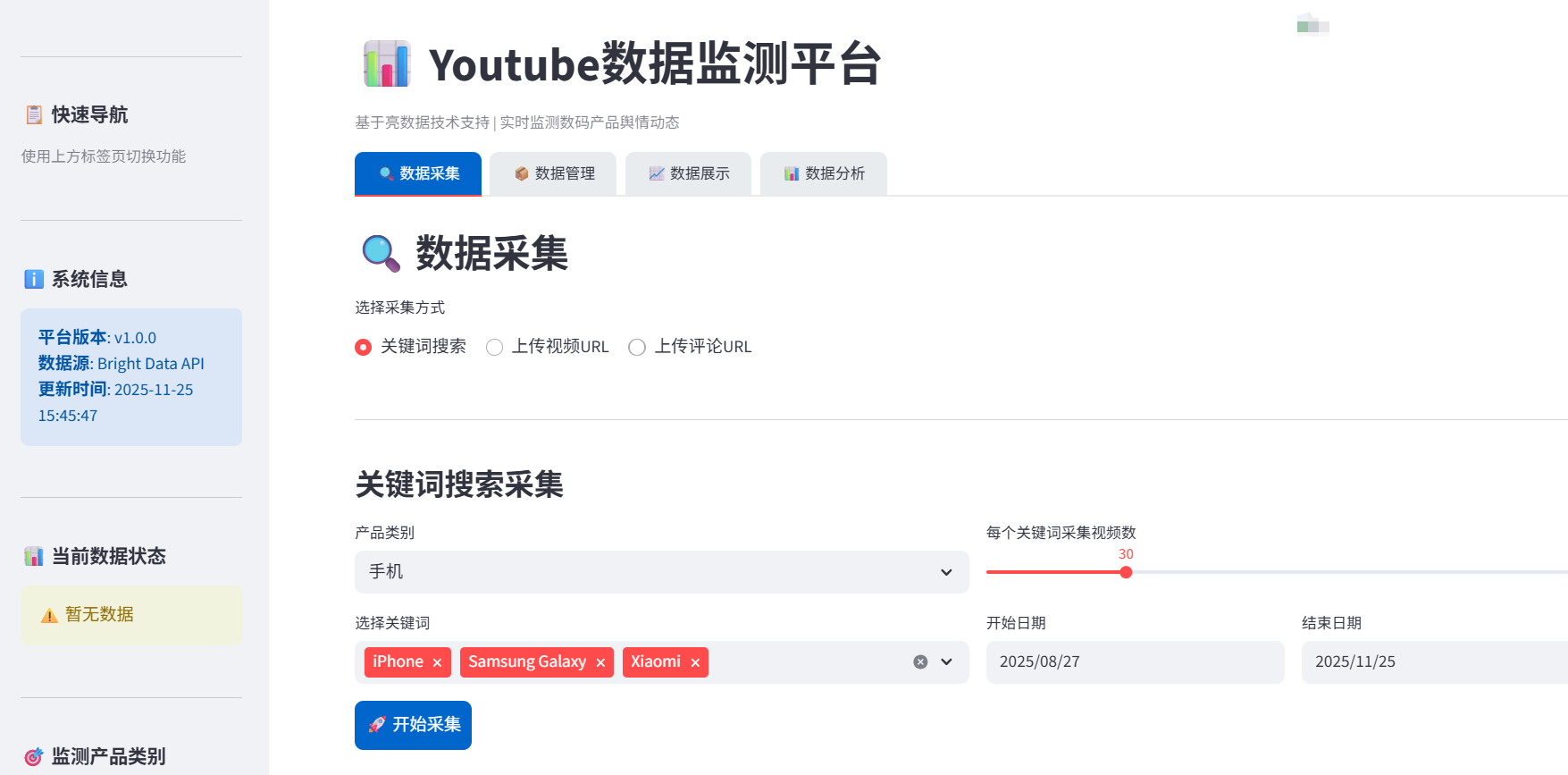
1、支持数据采集操作
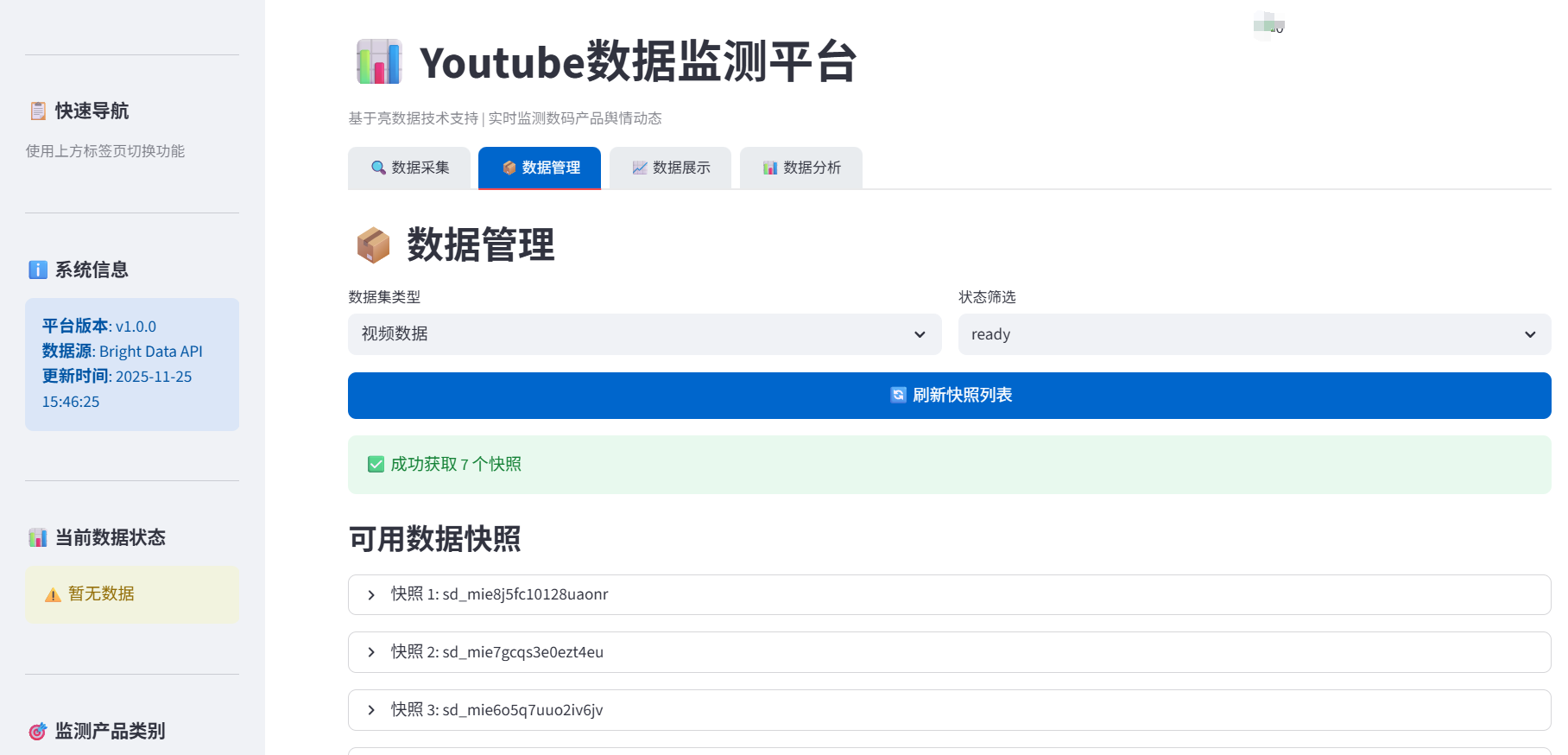
2、进行数据管理,调用数据快照
3、对采集的数据进行统计展示
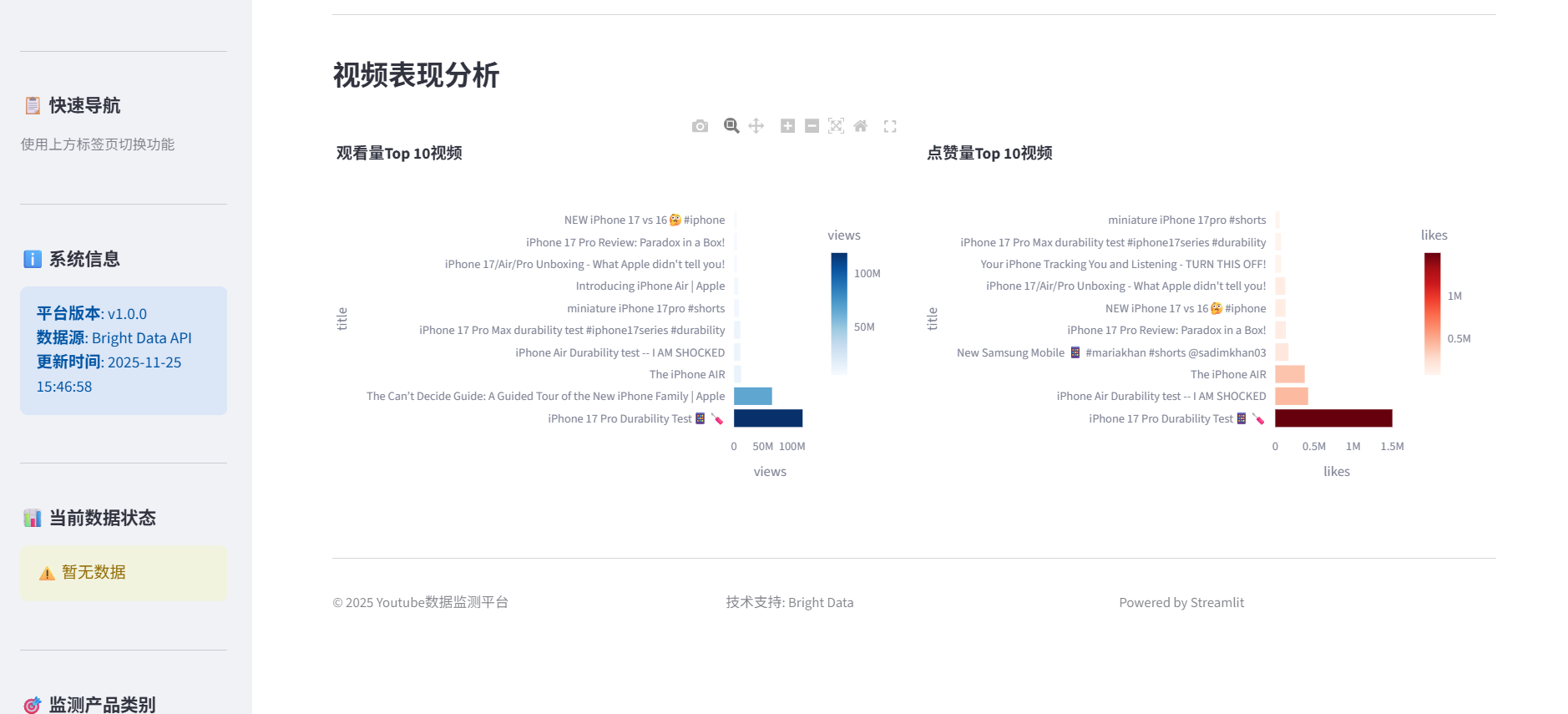
4、进行可视化分析


















 2240
2240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











