





在机器学习中,朴素贝叶斯分类器(Naive Bayes Classifier)是一个简单而强大的算法,广泛应用于各种分类任务,如垃圾邮件检测、情感分析和医学诊断等。
尽管其名字中带有“朴素”二字,但其背后的原理却蕴含了深刻的统计学思想。
接下来,我们将详细讲解朴素贝叶斯的数学原理,以及核心公式的推导,帮助大家深入了解这一经典算法。
一、概率图模型
在讲解朴素贝叶斯之前,我们先来了解一下概率图模型(Probabilistic Graphical Model,PGM)。它是一种使用图结构来描述多元随机变量之间条件独立关系的概率模型。
最常见的是将随机变量表示为节点,将变量之间的依赖关系表示为边,从而形成一个图结构。
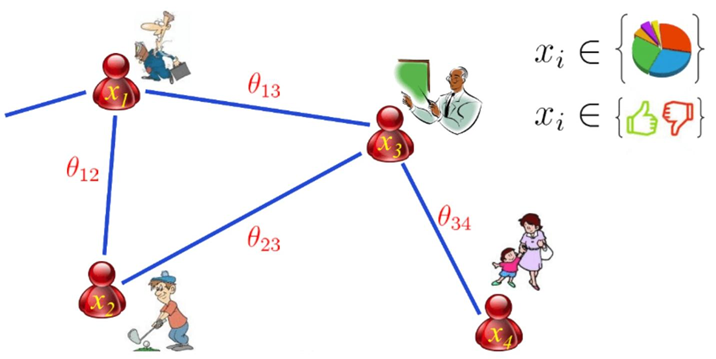
由此,概率图模型可以分为两类:
-
有向图模型 (如贝叶斯网络):表示因果关系;
-
无向图模型 (如马尔可夫随机场):表示相互作用关系。
而我们今天讲的朴素贝叶斯分类器就是概率图模型中最简单的一种形式:有向图模型。它通过贝叶斯定理和特征独立性假设来构建分类模型。
二、朴素贝叶斯
贝叶斯定理是朴素贝叶斯分类器的核心思想,它描述了在已知某些条件下,事件发生的概率。
💫贝叶斯定理的公式如下:
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
其中:
▪️ P ( A ∣ B ) P(A|B) P(A∣B) 是在事件 B B B 发生的条件下,事件 A A A 发生的概率,称为后验概率。
▪️ P ( B ∣ A ) P(B|A) P(B∣A) 是在事件 A A A 发生的条件下,事件 B B B 发生的概率,称为似然概率。
▪️ P ( A ) P(A) P(A) 是事件 A A A 发生的先验概率。
▪️ P ( B ) P(B) P(B) 是事件 B B B 发生的边缘概率。
在朴素贝叶斯分类器中,我们需要关注的是:如何根据特征 x x x 来预测类别 y y y,即计算计算贝叶斯定理中的后验概率 P ( y ∣ x ) P(y|x) P(y∣x)。
朴素贝叶斯分类器的另一个核心假设就是特征之间相互独立。
假设我们有一个数据集 D D D,其中每个样本 x x x 包含 n n n 个特征 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn,类别标签为 y y y。
朴素贝叶斯分类器假设这些特征之间相互独立,即:
P ( x ∣ y ) = P ( x 1 , x 2 , … , x n ∣ y ) = ∏ i = 1 n P ( x i ∣ y ) P(\mathbf{x}|y) = P(x_1, x_2, \ldots, x_n|y) = \prod_{i=1}^n P(x_i|y) P(x∣y)=P(x1,x2,…,x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









