





在机器学习中,线性回归是最基础、最经典的模型之一。它简单易懂,却又强大无比,被广泛应用于各种预测场景。

但很多初学者可能会被线性回归的核心公式吓到,那些复杂的符号和数学推导让人望而却步。
别担心,今天我们就来手把手拆解线性回归的核心公式,从零开始,一步步揭开它的神秘面纱。
一、什么是线性回归?
我们先来讲一个小故事,假如你是一位房地产经纪人,客户问你:
“我有一套100平方米的房子,大概能卖多少钱?”。
这时,你应该如何回答呢?总不能凭空猜测吧。

这时候,线性回归就能派上大用场啦!
通过分析历史房价数据,找出房屋面积与房价之间的线性关系,你就能预测出100平方米房子的大致价格了。
线性回归不仅在房地产领域大显身手,还在金融、医疗、市场营销等众多领域发挥着重要作用。
比如,银行可以用它预测贷款违约率,医生可以用它预测患者的康复时间,电商运营人员可以用它预测销售额。
1.1 线性回归的定义
线性回归是一种通过建立线性关系来预测目标变量的方法。
简单来说,就是找到一条直线,让这条直线尽可能地“贴合”数据点。
比如,我们用散点图表示房屋面积(自变量)与房价(因变量)的关系。
线性回归的目标就是找到一条直线,让这条直线与散点的距离尽可能小。
1.2 关键术语解释
🕵️ 因变量(目标变量):我们要预测的变量,比如房价。
🕵️ 自变量(特征变量):用来预测因变量的变量,比如房屋面积。
🕵️ 拟合直线:线性回归找到的那条“最佳”直线,用来表示自变量与因变量之间的关系。

另外,线性回归还有一些基本假设,这些假设保证了模型的有效性:
-
独立性:每个数据点之间是独立的,没有相互影响。
-
线性关系:自变量与因变量之间存在线性关系。
-
同方差性:误差项的方差是恒定的。
-
正态分布:误差项服从正态分布。
这些假设听起来有点抽象,但其实很好理解。
比如,独立性就好比你抛硬币,每次抛的结果都是独立的,不会受到之前抛的结果影响。线性关系就好比你走路,走得越远,离起点的距离就越远,这是一个线性的关系。
二、LR核心公式拆解
线性回归的核心公式是这样的:
y=β0+β1x1+β2x2+⋯+βnxn+ϵy = \beta_0 + \beta_1x_1 + \beta_2x_2 + \cdots + \beta_nx_n + \epsilony=β0+β1x1+β2x2+⋯+βnxn+ϵ
看起来有点复杂,别急,我们逐项解释一下:
-
yyy 是我们要预测的因变量,比如房价。
-
β0\beta_0β0 是截距,也就是当所有自变量都为0时,因变量的值。
-
β1,β2,…,βn\beta_1, \beta_2, \ldots, \beta_nβ1,β2,…,βn 是系数,表示每个自变量对因变量的影响程度。
-
x1,x2,…,xnx_1, x_2, \ldots, x_nx1,x2,…,xn 是自变量,比如房屋面积、房间数量等。
-
ϵ\epsilonϵ 是误差项,表示模型无法解释的部分。
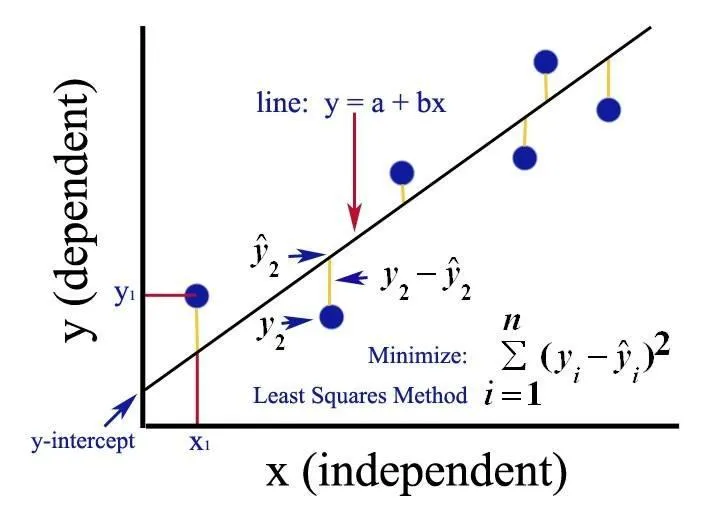
线性回归的目标是找到一条最佳拟合直线,让这条直线与数据点的距离尽可能小。这里用到的方法叫最小二乘法,它的基本思想是:最小化误差平方和。
假设我们有一组数据点 (xi,yi)(x_i, y_i)(xi,yi),拟合直线的预测值为 y^i\hat{y}_iy^i,那么误差就是 yi−y^iy_i - \hat{y}_iyi−y^i。最小二乘法的目标是让所有误差的平方和最小,即:
min∑i=1n(yi−y^i)2\min \sum_{i=1}^{n}(y_i - \hat{y}_i)^2mini=1∑n(yi−y^i)2
我们用一个简单的例子来说明。假设我们只有两个数据点:(1, 2) 和 (2, 3)。我们尝试用一条直线 y=β0+β1y = \beta_0 + \beta_1y=β0+β1 来拟合它们。通过计算误差平方和,我们可以找到最优的 β0\beta_0β0 和 β1\beta_1β1。
三、LR数学公式推导
接下来,我将详细推导线性回归的核心公式,特别是最小二乘法的推导过程。
这个过程会涉及一些数学知识,但我会尽量讲解得通俗易懂。
3.1 问题、误差定义
假设我们有一组数据点 (xi,yi)(x_i, y_i)(xi,yi),其中 xix_ixi 是自变量(特征),yiy_iyi 是因变量(目标值)。我们的目标是找到一个线性模型:
y=β0+β1xy = \beta_0 + \beta_1xy=β0+β1x
使得这个模型能够尽可能好地拟合数据。
为了衡量模型拟合的好坏,我们需要定义一个误差函数。误差函数通常选择误差平方和(SSE,Sum of Squared Errors),即:
SSE=∑i=1n(yi−y^i)2SSE = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2SSE=i=1∑n(yi−y^i)2
其中,y^i\hat{y}_iy^i 是模型的预测值,即:
y^i=β0+β1xi\hat{y}_i = \beta_0 + \beta_1x_iy^i=β0+β1xi
因此,误差平方和可以写成:
SSE=∑i=1n(yi−(β0+β1xi))2SSE = \sum_{i=1}^{n}(y_i - (\beta_0 + \beta_1x_i))^2SSE=i=1∑n(yi−(β0+β1xi))2
3.2 最小化SSE
为了找到最优的 β0\beta_0β0 和 β1\beta_1β1,我们需要最小化误差平方和 SSE。
这是一个优化问题,可以通过求导并令导数为零来解决。
1、对 β0\beta_0β0 求导:
∂SSE∂β0=∂∂β0∑i=1n(yi−β0−β1xi)2\frac{\partial SSE}{\partial \beta_0} = \frac{\partial}{\partial \beta_0} \sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i)^2∂β0∂SSE=∂β0∂i=1∑n(yi−β0−β1xi)2
逐项求导:
∂∂β0(yi−β0−β1xi)2=−2(yi−β0−β1xi)\frac{\partial}{\partial \beta_0}(y_i - \beta_0 - \beta_1x_i)^2 = -2(y_i - \beta_0 - \beta_1x_i)∂β0∂(yi−β0−β1xi)2=−2(yi−β0−β1xi)
因此:
∂SSE∂β0=−2∑i=1n(yi−β0−β1xi)\frac{\partial SSE}{\partial \beta_0} = -2 \sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i)∂β0∂SSE=−2i=1∑n(yi−β0−β1xi)
令导数为零:
−2∑i=1n(yi−β0−β1xi)=0-2 \sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i) = 0−2i=1∑n(yi−β0−β1xi)=0
简化得:
∑i=1n(yi−β0−β1xi)=0\sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i) = 0i=1∑n(yi−β0−β1xi)=0
2、对 β1\beta_1β1 求导:
∂SSE∂β1=∂∂β1∑i=1n(yi−β0−β1xi)2\frac{\partial SSE}{\partial \beta_1} = \frac{\partial}{\partial \beta_1} \sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i)^2∂β1∂SSE=∂β1∂i=1∑n(yi−β0−β1xi)2
逐项求导:
∂∂β1(yi−β0−β1xi)2=−2xi(yi−β0−β1xi)\frac{\partial}{\partial \beta_1}(y_i - \beta_0 - \beta_1x_i)^2 = -2x_i(y_i - \beta_0 - \beta_1x_i)∂β1∂(yi−β0−β1xi)2=−2xi(yi−β0−β1xi)
因此:
∂SSE∂β1=−2∑i=1nxi(yi−β0−β1xi)\frac{\partial SSE}{\partial \beta_1} = -2 \sum_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1x_i)∂β1∂SSE=−2i=1∑nxi(yi−β0−β1xi)
令导数为零:
−2∑i=1nxi(yi−β0−β1xi)=0-2 \sum_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1x_i) = 0−2i=1∑nxi(yi−β0−β1xi)=0
简化得:
∑i=1nxi(yi−β0−β1xi)=0\sum_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1x_i) = 0i=1∑nxi(yi−β0−β1xi)=0
3.3 求解方程组
现在我们得到了两个方程:
- ∑i=1n(yi−β0−β1xi)=0\sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_i) = 0∑i=1n(yi−β0−β1xi)=0
- ∑i=1nxi(yi−β0−β1xi)=0\sum_{i=1}^{n}x_i(y_i - \beta_0 - \beta_1x_i) = 0∑i=1nxi(yi−β0−β1xi)=0
我们可以通过一些代数变换来解这两个方程。
方程1:
∑i=1nyi−∑i=1nβ0−∑i=1nβ1xi=0\sum_{i=1}^{n}y_i - \sum_{i=1}^{n}\beta_0 - \sum_{i=1}^{n}\beta_1x_i = 0i=1∑nyi−i=1∑nβ0−i=1∑nβ1xi=0
因为 β0\beta_0β0 和 β1\beta_1β1 是常数,所以:
∑i=1nyi−nβ0−β1∑i=1nxi=0\sum_{i=1}^{n}y_i - n\beta_0 - \beta_1 \sum_{i=1}^{n}x_i = 0i=1∑nyi−nβ0−β1i=1∑nxi=0
解得:
β0=1n∑i=1nyi−β11n∑i=1nxi\beta_0 = \frac{1}{n} \sum_{i=1}^{n}y_i - \beta_1 \frac{1}{n} \sum_{i=1}^{n}x_iβ0=n1i=1∑nyi−β1n1i=1∑nxi
记 yˉ=1n∑i=1nyi\bar{y} = \frac{1}{n} \sum_{i=1}^{n}y_iyˉ=n1∑i=1nyi 和 xˉ=1n∑i=1nxi\bar{x} = \frac{1}{n} \sum_{i=1}^{n}x_ixˉ=n1∑i=1nxi,则:
β0=yˉ−β1xˉ\beta_0 = \bar{y} - \beta_1 \bar{x}β0=yˉ−β1xˉ
方程2:
∑i=1nxiyi−β0∑i=1nxi−β1∑i=1nxi2=0\sum_{i=1}^{n}x_iy_i - \beta_0 \sum_{i=1}^{n}x_i - \beta_1 \sum_{i=1}^{n}x_i^2 = 0i=1∑nxiyi−β0i=1∑nxi−β1i=1∑nxi2=0
将 β0=yˉ−β1xˉ\beta_0 = \bar{y} - \beta_1 \bar{x}β0=yˉ−β1xˉ 代入:
∑i=1nxiyi−(yˉ−β1xˉ)∑i=1nxi−β1∑i=1nxi2=0\sum_{i=1}^{n}x_iy_i - (\bar{y} - \beta_1 \bar{x}) \sum_{i=1}^{n}x_i - \beta_1 \sum_{i=1}^{n}x_i^2 = 0i=1∑nxiyi−(yˉ−β1xˉ)i=1∑nxi−β1i=1∑nxi2=0
整理得:
∑i=1nxiyi−yˉ∑i=1nxi+β1xˉ∑i=1nxi−β1∑i=1nxi2=0\sum_{i=1}^{n}x_iy_i - \bar{y} \sum_{i=1}^{n}x_i + \beta_1 \bar{x} \sum_{i=1}^{n}x_i - \beta_1 \sum_{i=1}^{n}x_i^2 = 0i=1∑nxiyi−yˉi=1∑nxi+β1xˉi=1∑nxi−β1i=1∑nxi2=0
提取 β1\beta_1β1:
∑i=1nxiyi−yˉ∑i=1nxi=β1(∑i=1nxi2−xˉ∑i=1nxi)\sum_{i=1}^{n}x_iy_i - \bar{y} \sum_{i=1}^{n}x_i = \beta_1 \left( \sum_{i=1}^{n}x_i^2 - \bar{x} \sum_{i=1}^{n}x_i \right)i=1∑nxiyi−yˉi=1∑nxi=β1(i=1∑nxi2−xˉi=1∑nxi)
解得:
β1=∑i=1nxiyi−yˉ∑i=1nxi∑i=1nxi2−xˉ∑i=1nxi\beta_1 = \frac{\sum_{i=1}^{n}x_iy_i - \bar{y} \sum_{i=1}^{n}x_i}{\sum_{i=1}^{n}x_i^2 - \bar{x} \sum_{i=1}^{n}x_i}β1=∑i=1nxi2−xˉ∑i=1nxi∑i=1nxiyi−yˉ∑i=1nxi
进一步简化:
β1=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2\beta_1 = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n}(x_i - \bar{x})^2}β1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
3.4 最终结果
通过上述推导,我们得到了线性回归模型的系数 β0\beta_0β0 和 β1\beta_1β1:
β1=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2\beta_1 = \frac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n}(x_i - \bar{x})^2}β1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
β0=yˉ−β1xˉ\beta_0 = \bar{y} - \beta_1 \bar{x}β0=yˉ−β1xˉ
- β1\beta_1β1:表示 $$ 每增加一个单位,yyy的平均变化量。
- β0\beta_0β0:表示当 x=0x = 0x=0 时,yyy的值。
通过最小二乘法,我们找到了最优的 β0\beta_0β0 和 β1\beta_1β1,使得误差平方和最小,从而得到了最佳拟合直线。
今天,我们深入剖析了线性回归模型的核心公式,从零开始逐步拆解,让每一个细节都清晰可见。
我们不仅掌握了线性回归的基本概念,还深入理解了其核心公式以及最小二乘法的原理。
相信通过这一过程,你对线性回归有了更加透彻的认识。
注:本文中未声明的图片均来源于互联网

















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









