







 本文深入探讨了移动机器人在SLAM(Simultaneous Localization and Mapping)中里程计积分的重要性,解析了不同积分方法如欧拉法与龙格库塔法(RK2)在精度上的差异。通过对比分析,阐述了pro1里程计模型如何实现更精确的位置估计,以及其与圆弧模型的关系。此外,还介绍了diego标定方法在里程计积分中的应用。
本文深入探讨了移动机器人在SLAM(Simultaneous Localization and Mapping)中里程计积分的重要性,解析了不同积分方法如欧拉法与龙格库塔法(RK2)在精度上的差异。通过对比分析,阐述了pro1里程计模型如何实现更精确的位置估计,以及其与圆弧模型的关系。此外,还介绍了diego标定方法在里程计积分中的应用。
转载添加链接描述
对于移动机器人来讲,由两个矩阵特别重要
//from base_link to global odom
ca -sa 0
sa ca 0
0 0 1
//from odom to base link
ca sa 0
-sa ca 0
0 0 1
//两个相乘为单位矩阵,所以就是互逆
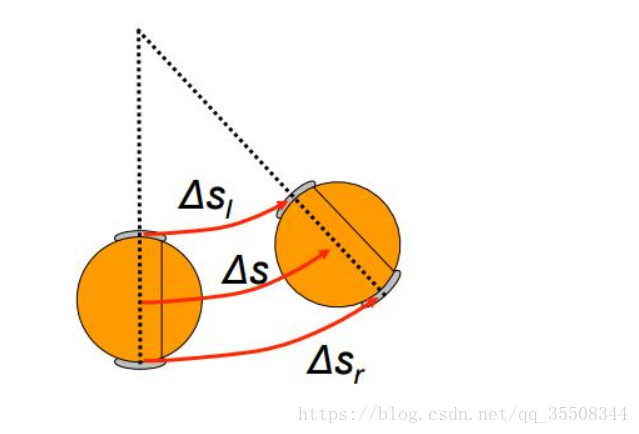
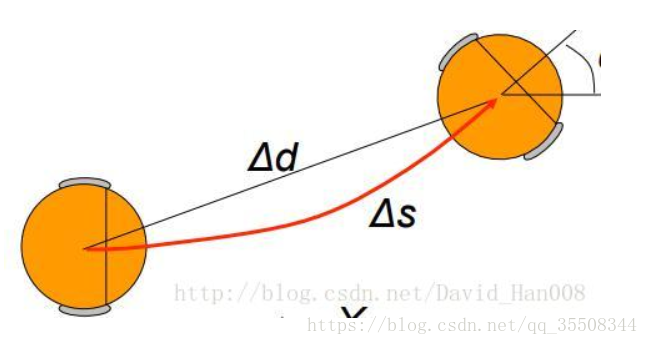
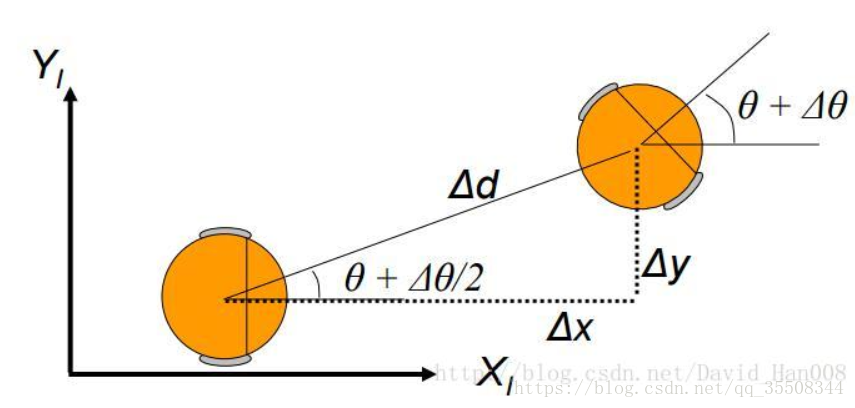
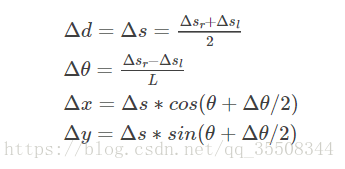
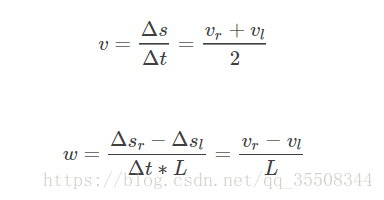
如上,在里程计积分时,
有的地方 * cos(theta ) (属于欧拉法)
有的地方 * cos(theta + 1/2 △) (属于龙格库塔法 rk2),理论上精度更高一点
模型
旷世slam
圆形轨迹
pro1里程计积分
pro1的里程计模型本质上相当于rk2, 使用位置环计算位移和角速度,delta_dis/delta_theta 求出半径,然后计算在前一个位置位移的x,y, 再积分(后一个位置做向前一个位置半径的垂线,再前一个位置x,y坐标分解)
切线,割线,圆弧模型通俗理解
标定
diego 标定
本质上标定的里程计积分中的delta x ,delta theta,

















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









