






论文链接:https://arxiv.org/pdf/2305.07922
1. 论文概述
1.1 研究背景
近年来,大型语言模型(LLMs)在代码理解和代码生成任务上取得了显著进展。例如,Codex、CodeGen 和 StarCoder 等模型在 GitHub 代码数据集上进行了大规模预训练,展示了在代码自动补全、代码生成和代码搜索等任务上的卓越性能。然而,现有代码 LLM 仍然存在以下主要问题:
-
架构限制:
- 许多 LLM 采用 encoder-only(如 CodeBERT)或 decoder-only(如 CodeGen)架构,导致它们在某些特定任务上表现良好,但无法兼顾多种代码任务(理解 vs 生成)。
- 采用 encoder-decoder 结构的模型(如 CodeT5)尽管可以同时处理理解和生成任务,但由于所有任务共享同一架构,可能导致部分任务性能下降。
-
预训练目标有限:
- 许多现有 LLM 仅使用单一的 masked span denoising 或 causal language modeling (CLM) 进行预训练,导致在特定下游任务(如代码检索、代码生成)上的泛化能力有限。
- 现有方法往往缺乏 对比学习(contrastive learning)和 文本-代码匹配(text-code matching)等目标,使得模型难以学习代码与自然语言之间的细粒度对齐关系。
1.2 论文贡献
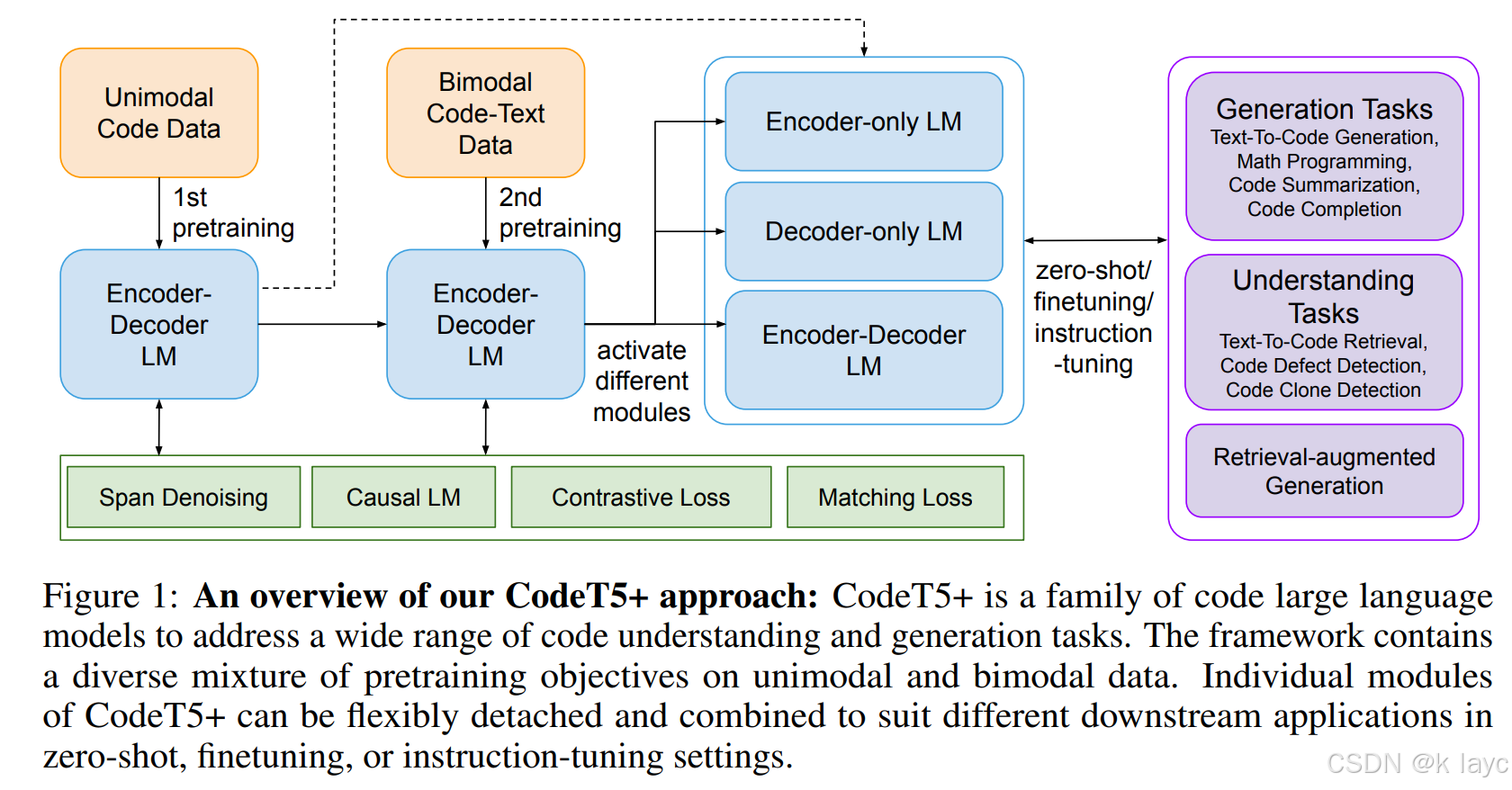
为了解决上述问题,本文提出了 CodeT5+,一个灵活的 encoder-decoder 代码 LLM 系列,具备以下特性:
- 灵活的架构:CodeT5+ 既可作为 encoder-only(用于代码理解)、decoder-only(用于代码生成),也可作为 encoder-decoder(用于序列到序列任务)。
- 多样化的预训练目标:
- Span Denoising:用于编码代码结构信息。
- Causal Language Modeling (CLM):用于增强代码生成能力。
- Contrastive Learning:提高代码与自然语言的匹配能力。
- Text-Code Matching:强化代码-文本的跨模态对齐。
- 计算高效的预训练策略:
- 利用 冻结(frozen) 现有 LLM(如 CodeGen)来初始化 CodeT5+,仅训练编码器和交叉注意力(cross-attention)层,从而减少训练开销。
1.3 主要实验结果
- 在 20+ 代码任务(包括 代码生成、代码补全、代码检索、数学编程)上进行了广泛评估。
- 在 HumanEval 代码生成任务 上,CodeT5+ 16B 达到 35.0% pass@1 和 54.5% pass@10,超越所有 开源 代码 LLM,甚至超过 OpenAI code-cushman-001。
- CodeT5+ 还可用作 检索增强生成(retrieval-augmented generation, RAG) 模型,在代码生成任务上表现优异。
2. CodeT5+ 方法
2.1 架构设计
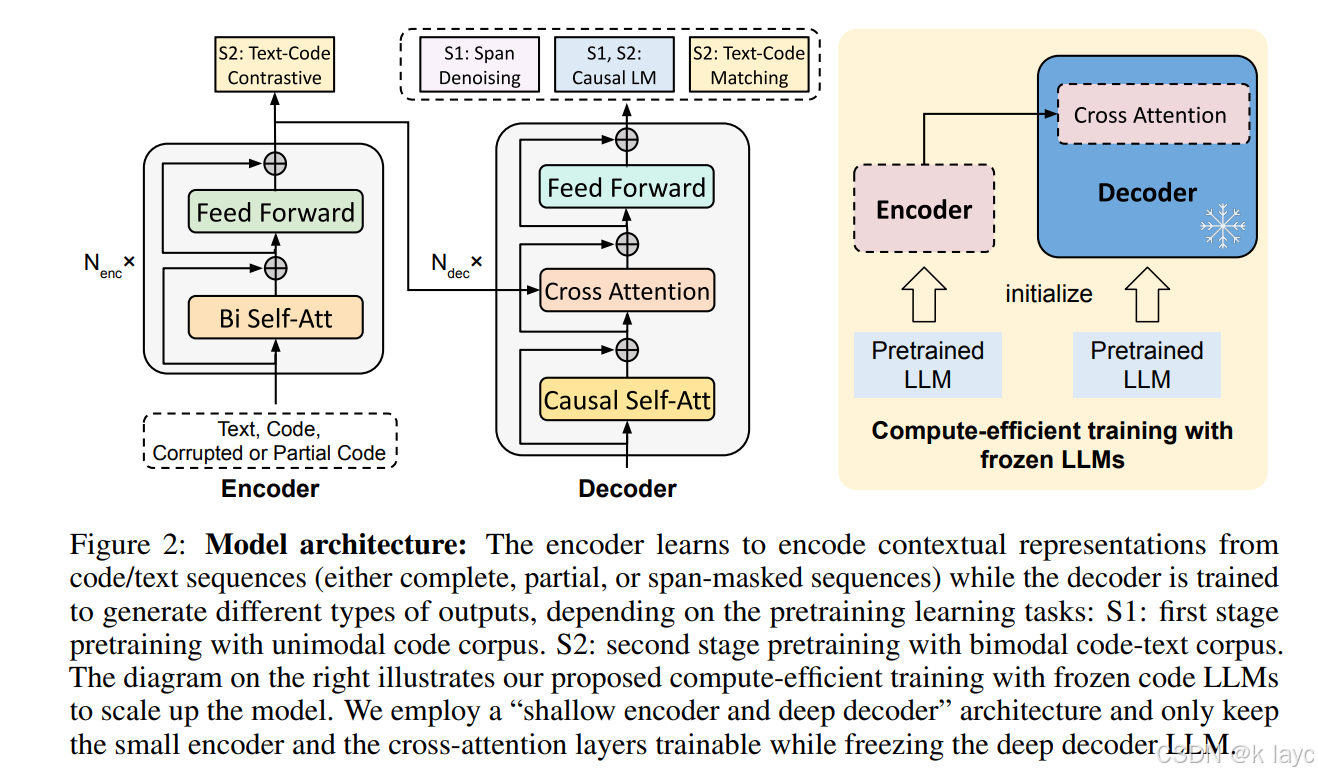
2.1.1 灵活的模型架构
CodeT5+ 采用 encoder-decoder 结构,但支持三种模式:
- Encoder-only(用于代码检索、代码缺陷检测)。
- Decoder-only(用于代码生成、代码补全)。
- Encoder-Decoder(用于代码翻译、代码摘要、数学编程)。
2.1.2 计算高效的训练策略
- 采用 “浅编码器+深解码器”(shallow encoder + deep decoder)架构:
- 编码器使用较少参数,仅负责编码代码上下文。
- 解码器从现有 冻结 LLM(如 CodeGen)初始化,仅训练编码器和交叉注意力层。
- 这种策略大大减少了可训练参数,提高训练效率。
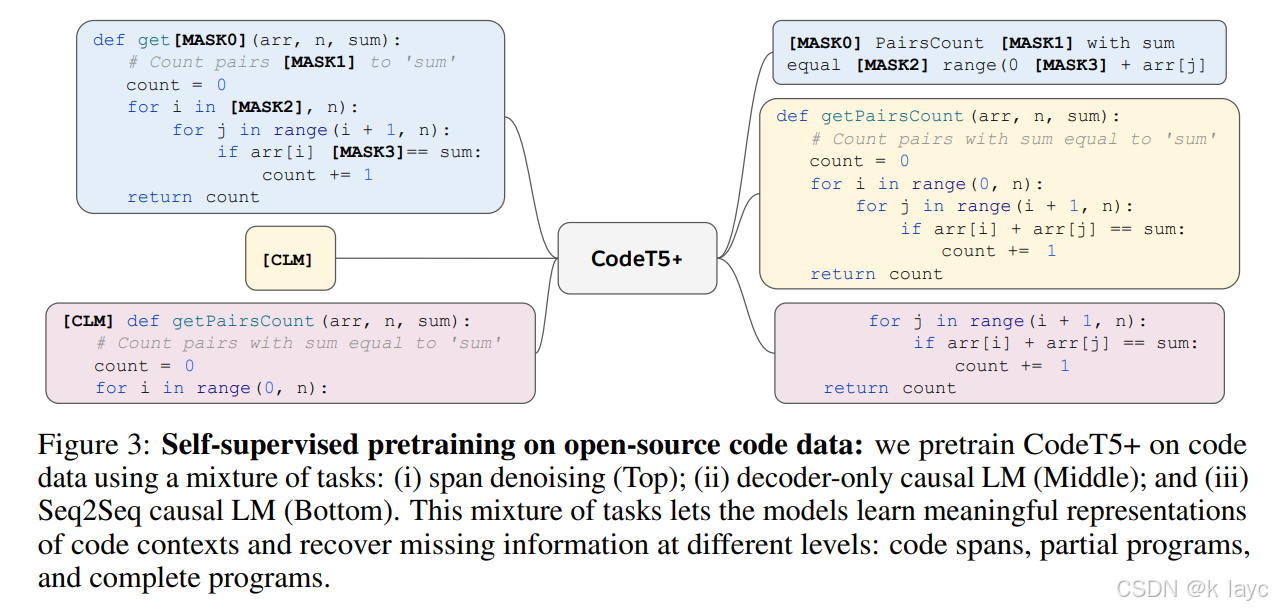
2.2 预训练任务
CodeT5+ 采用 两阶段 预训练策略:
-
第一阶段:单模态(unimodal)代码预训练:
- Span Denoising:随机屏蔽代码片段,要求模型恢复完整代码。
- Causal Language Modeling (CLM):
- Seq2Seq CLM:随机截断代码片段,要求模型继续生成剩余部分。
- Decoder-only CLM:完全自回归生成代码。
-
第二阶段:双模态(bimodal)文本-代码预训练:
- Contrastive Learning:拉近匹配的文本-代码对,推远不匹配的对。
- Text-Code Matching:判别文本和代码是否匹配,提高跨模态对齐能力。
- Text-Code Causal LM:
- Text → Code:给定自然语言描述,生成代码。
- Code → Text:给定代码,生成对应的自然语言摘要。
3. 主要实验结果
3.1 代码生成(HumanEval)
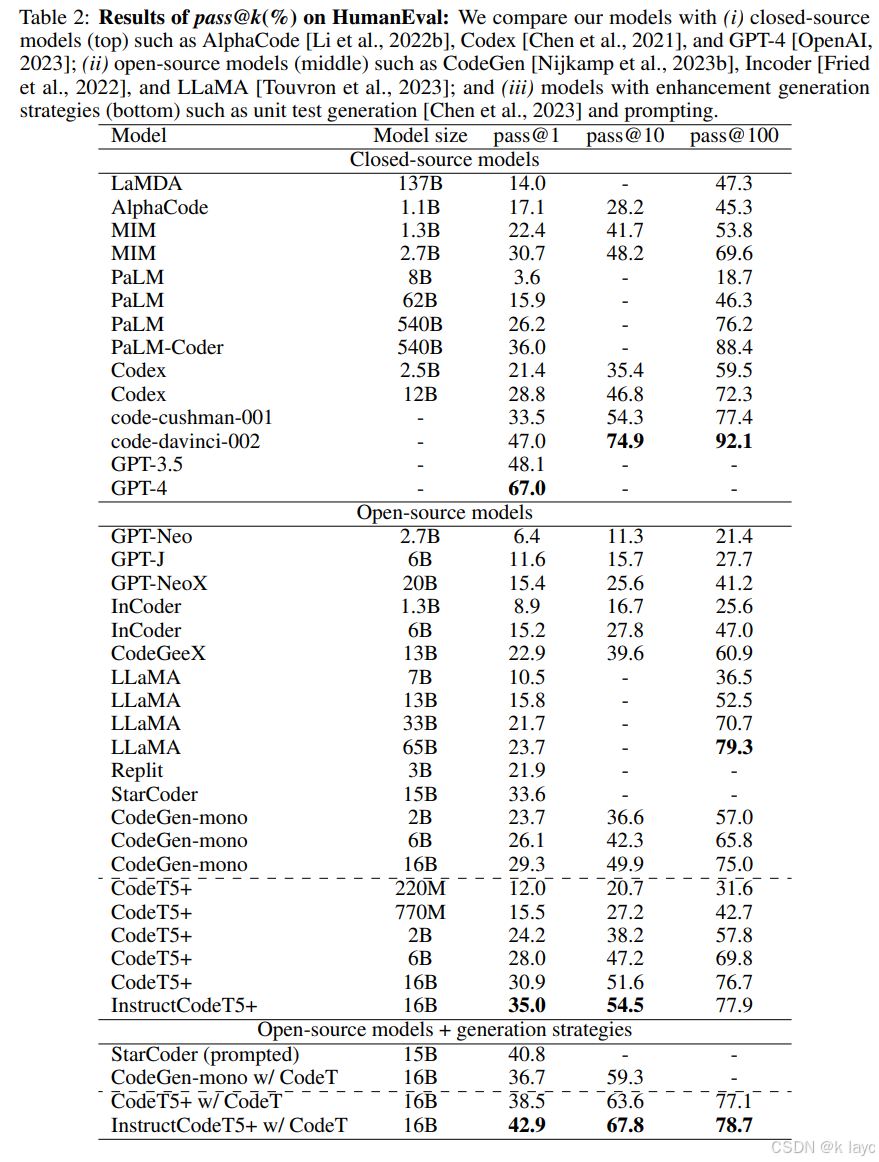
-
实验设置:
- 使用 HumanEval 数据集(164 道 Python 代码生成任务)。
- 采用 pass@k 作为评估指标,计算模型生成的 k 个代码片段中至少有一个正确的概率。
-
实验结果(Pass@k):
| Model | pass@1 | pass@10 | pass@100 |
|---|---|---|---|
| Codex 12B | 28.8% | 46.8% | 72.3% |
| CodeT5+ 16B | 30.9% | 51.6% | 76.7% |
| InstructCodeT5+ 16B | 35.0% | 54.5% | 77.9% |
- 分析:
- CodeT5+ 16B 在 pass@1 和 pass@10 上显著优于其他开源 LLM。
- 经过 指令微调(Instruction Tuning) 后,InstructCodeT5+ 16B 进一步提升至 35.0% pass@1,超过 OpenAI code-cushman-001。
3.2 数学编程(MathQA & GSM8K)
-
实验设置:
- 评估模型在 MathQA-Python 和 GSM8K-Python 上的代码生成能力。
- 采用 pass@80 和 pass@100 作为评估指标。
-
实验结果:
| Model | MathQA-Python pass@80 | GSM8K-Python pass@100 |
|---|---|---|
| GPT-Neo 2.7B | - | 41.4% |
| CodeGen-mono 2B | 85.6% | 47.8% |
| CodeT5+ 770M | 87.4% | 73.8% |
- 分析:
- CodeT5+ 770M 在 GSM8K-Python 上超越 LaMDA 137B 和 code-davinci,展示出卓越的数学推理能力。
3.3 代码总结
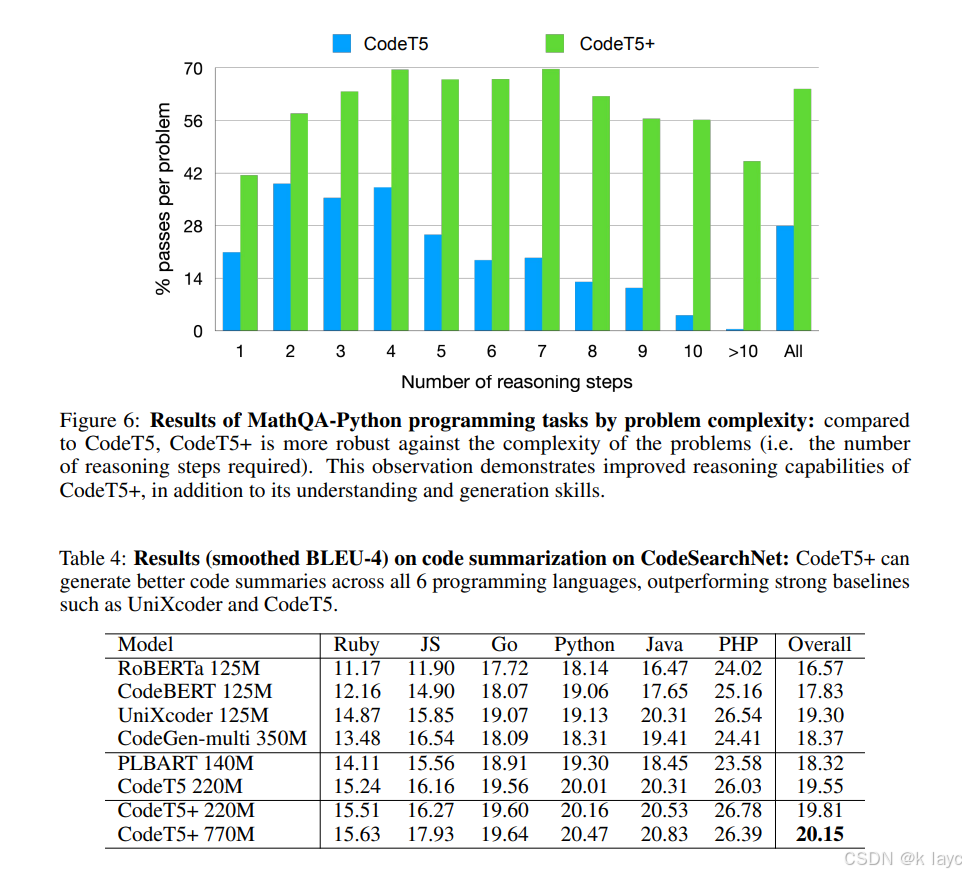
4. 结论
本文提出了 CodeT5+,一个高效、灵活的代码 LLM,能够同时处理 代码理解 和 代码生成 任务。通过引入 多样化的预训练目标(如对比学习、文本-代码匹配),CodeT5+ 在 20+ 代码任务 上实现了 SOTA 性能。特别是:
- 在 HumanEval 代码生成任务上,CodeT5+ 16B 取得 35.0% pass@1,超过所有开源代码 LLM。
- 采用 冻结 LLM 进行计算高效训练,显著减少了训练成本。
CodeT5+ 的成功表明,灵活的架构 + 多任务预训练 + 高效训练策略 是构建强大代码 LLM 的关键方向。

















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









