






论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
github:https://github.com/deepseek-ai/DeepSeek-R1/tree/main
本文介绍了 DeepSeek-R1 系列模型,包括 DeepSeek-R1-Zero 和 DeepSeek-R1,它们通过强化学习(Reinforcement Learning, RL)显著提升了大型语言模型(LLMs)的推理能力。DeepSeek-R1-Zero 通过大规模强化学习训练,无需监督式微调(Supervised Fine-Tuning, SFT),展示了强大的推理行为。DeepSeek-R1 则在此基础上引入了冷启动数据和多阶段训练流程,进一步提升了模型性能,达到了与 OpenAI-o1-1217 相当的水平。此外,研究还探索了从 DeepSeek-R1 中蒸馏出小型模型,以赋予它们推理能力。
一、研究背景与动机
1. 大型语言模型(LLMs)的发展
近年来,大型语言模型(LLMs)发展迅速,逐渐缩小了与人工通用智能(AGI)之间的差距。这些模型在推理任务上的表现尤为引人注目,但如何进一步提升其推理能力仍然是一个关键问题。
2. 推理能力的提升
推理能力的提升主要依赖于模型的训练方法。传统的监督式微调(SFT)虽然有效,但需要大量的标注数据,成本较高。而强化学习(RL)则提供了一种更为经济且有效的方法,可以在较少的计算资源下显著提升模型的推理性能。
二、DeepSeek-R1 系列模型
1. DeepSeek-R1-Zero
1.1 概述
DeepSeek-R1-Zero 是通过大规模强化学习训练的模型,不依赖于监督式微调(SFT)。它直接在基础模型上应用强化学习,展示了强大的推理行为。
1.2 强化学习算法
DeepSeek-R1-Zero 使用了 Group Relative Policy Optimization (GRPO) 算法,该算法通过从旧策略中采样一组输出并优化新策略来节省训练成本。具体公式如下:
J ( θ ) = E [ i ∼ A , { i j } j = 1 A ∼ π θ A ( i j ∣ i ) ] ( 1 A ∑ i = 1 A min ( π θ ( i i ∣ i ) π θ A ( i i ∣ i ) , 1 − ϵ , 1 + ϵ ) A i − β D A ) J(\theta) = \mathbb{E}[i \sim A, \{i_j\}_{j=1}^{A} \sim \pi_{\theta_{A}}(i_j | i)] \left( \frac{1}{A} \sum_{i=1}^{A} \min \left( \frac{\pi_{\theta}(i_i | i)}{\pi_{\theta_{A}}(i_i | i)}, 1 - \epsilon, 1 + \epsilon \right) A_i - \beta D_{A} \right) J(θ)=E[i∼A,{ij}j=1A∼πθA(ij∣i)](A1i=1∑Amin(πθA(ii∣i)πθ(ii∣i),1−ϵ,1+ϵ)Ai−βDA)
其中, A i A_i Ai 是优势函数,计算公式为:
A i = i i − m A ( { i 1 , i 2 , … , i A } ) A_i = i_i - m_{A}(\{i_1, i_2, \ldots, i_A\}) Ai=ii−mA({i1,i2,…,iA})
1.3 奖励建模
奖励建模是强化学习的关键部分,DeepSeek-R1-Zero 采用了基于规则的奖励系统,主要包括两种类型的奖励:
- 准确性奖励:评估响应是否正确,例如数学问题的确定性结果。
- 格式奖励:确保模型将思考过程放在
<think>和</think>标签之间。
1.4 训练模板
为了训练 DeepSeek-R1-Zero,设计了一个简单的模板,要求模型先产生推理过程,然后提供最终答案。具体模板如下:
prompt will be replaced with the specific reasoning question during training.
1.5 性能与自我进化过程
DeepSeek-R1-Zero 在 AIME 2024 基准测试中的表现随着训练的进行显著提升,平均 Pass@1 分数从 15.6% 提升到 71.0%。此外,模型在训练过程中自然地增加了思考时间,从生成数百到数千个推理标记,显著提升了推理能力。

2. DeepSeek-R1
2.1 概述
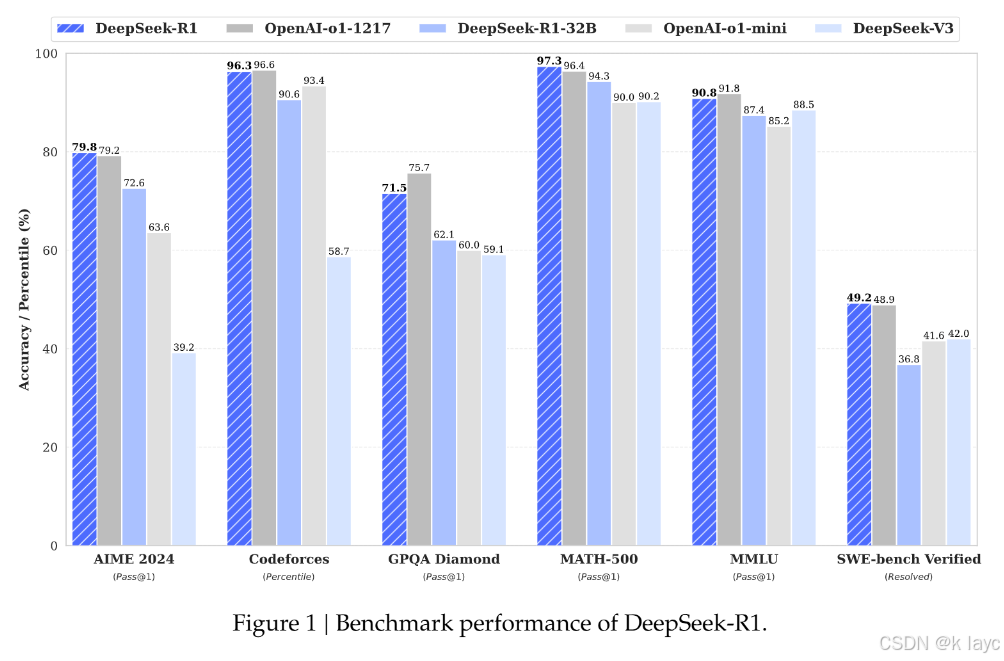
DeepSeek-R1 在 DeepSeek-R1-Zero 的基础上引入了冷启动数据和多阶段训练流程,进一步提升了模型性能,达到了与 OpenAI-o1-1217 相当的水平。
2.2 冷启动
通过收集数千个长推理链(CoT)数据来微调 DeepSeek-V3-Base 模型,作为 RL 的起点。这些数据提高了模型的可读性和性能。
2.3 推理导向的强化学习
在冷启动数据上微调后,应用与 DeepSeek-R1-Zero 相同的大规模强化学习训练过程。此外,引入了语言一致性奖励,以减少多语言混合问题。
2.4 拒绝采样和监督式微调
当推理导向的 RL 收敛时,利用结果检查点收集 SFT 数据。收集了约 600k 个推理相关训练样本和 200k 个非推理训练样本。这些数据用于微调模型,提升其在写作、角色扮演等任务上的性能。
2.5 面向所有场景的强化学习
实施二次强化学习阶段,旨在提升模型的有用性和无害性,同时优化推理能力。这一阶段结合了推理数据和一般数据,使用规则奖励和神经奖励模型来指导学习过程。
三、实验结果
1. DeepSeek-R1 的评估
1.1 基准测试
DeepSeek-R1 在多个基准测试中表现出色,包括 MMLU、MMLU-Pro、C-Eval、CMMLU、IFEval、FRAMES、GPQA Diamond、SimpleQA、C-SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench、Codeforces、CNMO 2024 和 AIME 2024。
1.2 具体表现
- 教育导向的知识基准测试:DeepSeek-R1 在 MMLU、MMLU-Pro 和 GPQA Diamond 上的表现显著优于 DeepSeek-V3,特别是在 STEM 相关问题上。
- 代码相关任务:DeepSeek-R1 在 LiveCodeBench 和 Codeforces 上的表现优于 DeepSeek-V3,展示了其在代码推理任务上的优势。
- 数学任务:DeepSeek-R1 在 AIME 2024 和 MATH-500 上的表现与 OpenAI-o1-1217 相当,显著优于其他模型。
2. 蒸馏模型的评估
2.1 概述
使用 DeepSeek-R1 生成的 800k 样本对开源模型(如 Qwen 和 Llama)进行微调,结果表明这些蒸馏模型在多个基准测试中表现出色。
2.2 具体表现
- DeepSeek-R1-Distill-Qwen-7B:在 AIME 2024 上的 Pass@1 分数为 55.5%,在 MATH-500 上为 83.3%。
- DeepSeek-R1-Distill-Qwen-32B:在 AIME 2024 上的 Pass@1 分数为 72.6%,在 MATH-500 上为 83.3%。
- DeepSeek-R1-Distill-Llama-70B:在 AIME 2024 上的 Pass@1 分数为 70.0%,在 MATH-500 上为 86.7%。
四、讨论与未来工作
1. 蒸馏与强化学习的比较
蒸馏方法显著提升了小型模型的推理能力,而通过大规模 RL 训练的小型模型需要巨大的计算资源,可能无法达到蒸馏的效果。
2. 不成功的尝试
- 过程奖励模型(PRM):在大规模强化学习过程中,PRM 的优势有限,可能引入额外的计算开销。
- 蒙特卡洛树搜索(MCTS):在训练过程中遇到挑战,难以通过自我搜索迭代提升模型性能。
3. 未来工作
- 通用能力:探索如何利用长推理链提升模型在函数调用、多轮对话等任务上的性能。
- 语言混合问题:解决模型在处理非中英文查询时的语言混合问题。
- 提示工程:优化提示设计,提高模型对提示的敏感性。
- 软件工程任务:提高模型在软件工程任务上的效率,通过拒绝采样或异步评估来提升 RL 过程的效率。

















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









